Questo articolo è la terza puntata di una serie sulle complessità NULL. Nella parte 1 ho trattato il significato del marker NULL e come si comporta nei confronti. Nella parte 2 ho descritto le incongruenze del trattamento NULL in diversi elementi del linguaggio. Questo mese descrivo le potenti funzionalità di gestione NULL standard che devono ancora arrivare a T-SQL e le soluzioni alternative attualmente utilizzate dalle persone.
Continuerò a utilizzare il database di esempio TSQLV5 come il mese scorso in alcuni dei miei esempi. Puoi trovare lo script che crea e popola questo database qui e il suo diagramma ER qui.
Predicato DISTINCT
Nella parte 1 della serie ho spiegato come si comportano i NULL nei confronti e le complessità attorno alla logica dei predicati a tre valori utilizzata da SQL e T-SQL. Considera il seguente predicato:
X =YSe un predicando è NULL, anche quando entrambi sono NULL, il risultato di questo predicato è il valore logico SCONOSCIUTO. Ad eccezione degli operatori IS NULL e IS NOT NULL, lo stesso vale per tutti gli altri operatori, inclusi diversi da (<>):
X <> YSpesso in pratica si desidera che i valori NULL si comportino come valori non NULL a scopo di confronto. Questo è particolarmente vero quando li usi per rappresentare mancante ma non applicabile valori. Lo standard ha una soluzione per questa esigenza sotto forma di una funzionalità chiamata predicato DISTINCT, che utilizza la forma seguente:
Invece di usare la semantica di uguaglianza o disuguaglianza, questo predicato usa la semantica basata sulla distinzione quando si confrontano i predicandi. In alternativa a un operatore di uguaglianza (=), dovresti utilizzare il seguente modulo per ottenere un VERO quando i due predicandi sono gli stessi, anche quando entrambi sono NULL, e un FALSO quando non lo sono, anche quando uno è NULL e il altro non lo è:
X NON È DISTINTO DA YIn alternativa a un diverso da operatore (<>), dovresti utilizzare il seguente modulo per ottenere un VERO quando i due predicandi sono diversi, incluso quando uno è NULL e l'altro no, e un FALSO quando sono uguali, incluso quando entrambi sono NULL:
X È DISTINTO DA YApplichiamo il predicato DISTINCT agli esempi che abbiamo usato nella Parte 1 della serie. Ricordiamo che era necessario scrivere una query che, dato un parametro di input @dt, restituisca gli ordini che sono stati spediti alla data di input se non è NULL, o che non sono stati spediti affatto se l'input è NULL. Secondo lo standard, dovresti utilizzare il codice seguente con il predicato DISTINCT per gestire questa esigenza:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Per ora, ricorda dalla parte 1 che puoi utilizzare una combinazione del predicato EXISTS e dell'operatore INTERSECT come soluzione SARGable in T-SQL, in questo modo:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Per restituire gli ordini che sono stati spediti in una data diversa (distinta dalla) data di input @dt, dovresti utilizzare la seguente query:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
La soluzione alternativa che funziona in T-SQL utilizza una combinazione del predicato EXISTS e dell'operatore EXCEPT, in questo modo:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Nella parte 1 ho anche discusso gli scenari in cui è necessario unire tabelle e applicare la semantica basata sulla distinzione nel predicato di join. Nei miei esempi ho usato tabelle chiamate T1 e T2, con colonne di join NULLable chiamate k1, k2 e k3 su entrambi i lati. Secondo lo standard, utilizzeresti il seguente codice per gestire un tale join:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Per ora, in modo simile alle precedenti attività di filtraggio, puoi utilizzare una combinazione del predicato EXISTS e dell'operatore INTERSECT nella clausola ON del join per emulare il predicato distinto in T-SQL, in questo modo:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Se utilizzato in un filtro, questo modulo è SARGable e, se utilizzato nei join, questo modulo può potenzialmente basarsi sull'ordine dell'indice.
Se desideri vedere il predicato DISTINCT aggiunto a T-SQL, puoi votarlo qui.
Se dopo aver letto questa sezione ti senti ancora un po' a disagio riguardo al predicato DISTINCT, non sei solo. Forse questo predicato è molto migliore di qualsiasi soluzione alternativa esistente attualmente in T-SQL, ma è un po' prolissa e un po' confusa. Usa una forma negativa per applicare ciò che nella nostra mente è un confronto positivo e viceversa. Ebbene, nessuno ha detto che tutti i suggerimenti standard siano perfetti. Come ha notato Charlie in uno dei suoi commenti alla Parte 1, il seguente modulo semplificato funzionerebbe meglio:
È conciso e molto più intuitivo. Invece di X NON È DISTINTO DA Y, useresti:
X È YE invece di X È DISTINTO DA Y, useresti:
X NON È YQuesto operatore proposto è in realtà allineato con gli operatori IS NULL e IS NOT NULL già esistenti.
Applicato alla nostra attività di query, per restituire gli ordini che sono stati spediti alla data di input (o che non sono stati spediti se l'input è NULL) dovresti utilizzare il seguente codice:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Per restituire gli ordini che sono stati spediti in una data diversa dalla data inserita, devi utilizzare il seguente codice:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Se Microsoft decidesse mai di aggiungere il predicato distinto, sarebbe utile se supportassero sia la forma dettagliata standard, sia questa forma non standard ma più concisa e più intuitiva. Curiosamente, il processore di query di SQL Server supporta già un operatore di confronto interno IS, che utilizza la stessa semantica dell'operatore IS desiderato che ho descritto qui. Puoi trovare dettagli su questo operatore nell'articolo di Paul White Piani di query non documentati:Confronti di uguaglianza (cerca "IS invece di EQ"). Quello che manca è esporlo esternamente come parte di T-SQL.
Clausola di trattamento NULL (IGNORE NULLS | RESPECT NULLS)
Quando si utilizzano le funzioni della finestra di offset LAG, LEAD, FIRST_VALUE e LAST_VALUE, a volte è necessario controllare il comportamento del trattamento NULL. Per impostazione predefinita, queste funzioni restituiscono il risultato dell'espressione richiesta nella posizione richiesta, indipendentemente dal fatto che il risultato dell'espressione sia un valore effettivo o un NULL. Tuttavia, a volte si desidera continuare a spostarsi nella direzione pertinente (indietro per LAG e LAST_VALUE, avanti per LEAD e FIRST_VALUE) e restituire il primo valore non NULL se presente e NULL in caso contrario. Lo standard ti dà il controllo su questo comportamento utilizzando una clausola di trattamento NULL con la seguente sintassi:
funzione_offset(Il default nel caso in cui non sia specificata la clausola di trattamento NULL è l'opzione RESPECT NULLS, ovvero restituire quanto presente nella posizione richiesta anche se NULL. Sfortunatamente, questa clausola non è ancora disponibile in T-SQL. Fornirò esempi per la sintassi standard utilizzando le funzioni LAG e FIRST_VALUE, nonché soluzioni alternative che funzionano in T-SQL. Puoi utilizzare tecniche simili se hai bisogno di tale funzionalità con LEAD e LAST_VALUE.
Come dati di esempio userò una tabella chiamata T4 che crei e popola usando il seguente codice:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Esiste un'attività comune che prevede la restituzione dell'ultimo rilevante valore. Un NULL in col1 indica nessuna modifica nel valore, mentre un valore diverso da NULL indica un nuovo valore rilevante. È necessario restituire l'ultimo valore col1 non NULL in base all'ordinamento degli ID. Utilizzando la clausola di trattamento NULL standard, gestiresti l'attività in questo modo:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Ecco l'output previsto da questa query:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
C'è una soluzione in T-SQL, ma coinvolge due livelli di funzioni della finestra e un'espressione di tabella.
Nel primo passaggio, usi la funzione della finestra MAX per calcolare una colonna chiamata grp che contiene il valore id massimo fino ad ora quando col1 non è NULL, in questo modo:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Questo codice genera il seguente output:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Come puoi vedere, viene creato un valore grp univoco ogni volta che c'è una modifica nel valore col1.
Nel secondo passaggio si definisce un CTE in base alla query del primo passaggio. Quindi, nella query esterna restituisci il valore massimo di col1 finora, all'interno di ciascuna partizione definita da grp. Questo è l'ultimo valore col1 non NULL. Ecco il codice completo della soluzione:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Chiaramente, è molto più codice e lavoro rispetto al semplice dire IGNORE_NULLS.
Un'altra esigenza comune è restituire il primo valore rilevante. Nel nostro caso, supponiamo di dover restituire il primo valore col1 non NULL finora basato sull'ordinamento degli ID. Utilizzando la clausola di trattamento NULL standard, gestiresti l'attività con la funzione FIRST_VALUE e l'opzione IGNORE NULLS, in questo modo:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Ecco l'output previsto da questa query:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
La soluzione alternativa in T-SQL utilizza una tecnica simile a quella utilizzata per l'ultimo valore non NULL, solo che invece di un approccio double-MAX si utilizza la funzione FIRST_VALUE sopra una funzione MIN.
Nel primo passaggio, usi la funzione della finestra MIN per calcolare una colonna chiamata grp che contiene il valore id minimo finora quando col1 non è NULL, in questo modo:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Questo codice genera il seguente output:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Se sono presenti NULL prima del primo valore rilevante, si ottengono due gruppi:il primo con NULL come valore grp e il secondo con il primo id non NULL come valore grp.
Nel secondo passaggio inserisci il codice del primo passaggio in un'espressione di tabella. Quindi nella query esterna usi la funzione FIRST_VALUE, partizionata da grp, per raccogliere il primo valore rilevante (non NULL) se presente, e NULL in caso contrario, in questo modo:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Ancora una volta, è molto codice e lavoro rispetto al semplice utilizzo dell'opzione IGNORE_NULLS.
Se ritieni che questa funzionalità possa esserti utile, puoi votare per la sua inclusione in T-SQL qui.
ORDINA PER NULL PRIMA | ULTIMI NULL
Quando ordini i dati, sia per scopi di presentazione, finestre, filtri TOP/OFFSET-FETCH o per qualsiasi altro scopo, c'è la domanda su come dovrebbero comportarsi i NULL in questo contesto? Lo standard SQL afferma che i NULL devono essere ordinati prima o dopo i non NULL e lasciano all'implementazione la determinazione in un modo o nell'altro. Tuttavia, qualunque cosa scelga il fornitore, deve essere coerente. In T-SQL, i NULL vengono ordinati per primi (prima dei non NULL) quando si utilizza l'ordine crescente. Considera la seguente query come esempio:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Questa query genera il seguente output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
L'output mostra che gli ordini non spediti, che hanno una data di spedizione NULL, ordinano prima degli ordini spediti, che hanno una data di spedizione applicabile esistente.
Ma cosa succede se hai bisogno di NULL per ordinare per ultimi quando usi l'ordine crescente? Lo standard SQL ISO/IEC supporta una clausola che si applica a un'espressione di ordinamento che controlla se i NULL ordinano per primo o per ultimo. La sintassi di questa clausola è:
Per gestire la nostra esigenza, restituendo gli ordini ordinati in base alle date di spedizione, in ordine crescente, ma con gli ordini non spediti restituiti per ultimi, e quindi in base ai loro ID ordine come spareggio, dovresti utilizzare il seguente codice:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Sfortunatamente, questa clausola di ordinazione NULLS non è disponibile in T-SQL.
Una soluzione alternativa comune utilizzata dalle persone in T-SQL consiste nel far precedere l'espressione di ordinamento con un'espressione CASE che restituisce una costante con un valore di ordinamento inferiore per valori non NULL rispetto a NULL, in questo modo (chiameremo questa soluzione Query 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Questa query genera l'output desiderato con i NULL visualizzati per ultimi:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Esiste un indice di copertura definito nella tabella Sales.Orders, con la colonna data di spedizione come chiave. Tuttavia, analogamente al modo in cui una colonna di filtro manipolata impedisce la SARGability del filtro e la possibilità di applicare una ricerca di un indice, una colonna di ordinamento manipolato impedisce la possibilità di fare affidamento sull'ordinamento degli indici per supportare la clausola ORDER BY della query. Pertanto, SQL Server genera un piano per la query 1 con un operatore di ordinamento esplicito, come mostrato nella Figura 1.
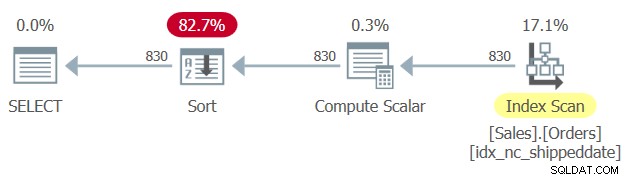 Figura 1:piano per la query 1
Figura 1:piano per la query 1
A volte la dimensione dei dati non è così grande perché l'ordinamento esplicito sia un problema. Ma a volte lo è. Con l'ordinamento esplicito la scalabilità della query diventa extralineare (paghi di più per riga più righe hai) e il tempo di risposta (tempo necessario per la restituzione della prima riga) viene ritardato.
C'è un trucco che puoi usare per evitare l'ordinamento esplicito in questo caso con una soluzione che viene ottimizzata utilizzando un operatore Merge Join Concatenation che preserva l'ordine. È possibile trovare una copertura dettagliata di questa tecnica impiegata in diversi scenari in SQL Server:evitare un ordinamento con la concatenazione di join di unione. Il primo passaggio della soluzione unifica i risultati di due query:una query che restituisce le righe in cui la colonna di ordinamento non è NULL con una colonna di risultati (la chiameremo sortcol) basata su una costante con un valore di ordinamento, ad esempio 0, e un'altra query che restituisce le righe con i NULL, con sortcol impostato su una costante con un valore di ordinamento superiore rispetto alla prima query, ad esempio 1. Nel secondo passaggio, quindi, definisci un'espressione di tabella basata sul codice del primo passaggio, quindi nella query esterna ordinate le righe dall'espressione della tabella prima per sortcol e poi per gli elementi di ordinamento rimanenti. Ecco il codice completo della soluzione che implementa questa tecnica (chiameremo questa soluzione Query 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Il piano per questa query è mostrato nella Figura 2.
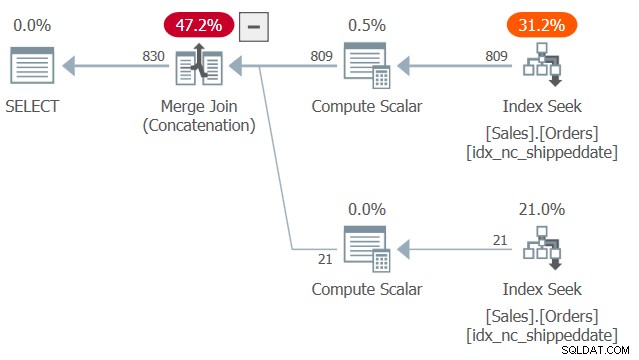 Figura 2:piano per la query 2
Figura 2:piano per la query 2
Notare due ricerche e scansioni dell'intervallo ordinato nell'indice di copertura idx_nc_shippeddate, una che estrae le righe in cui datadi spedizione non è NULL e un'altra che estrae righe in cui data di spedizione è NULL. Quindi, in modo simile al modo in cui l'algoritmo Merge Join funziona in un join, l'algoritmo Merge Join (Concatenation) unifica le righe dai due lati ordinati in modo simile a una cerniera e conserva l'ordine acquisito per supportare le esigenze di ordinamento della presentazione della query. Non sto dicendo che questa tecnica sia sempre più veloce della soluzione più tipica con l'espressione CASE, che utilizza l'ordinamento esplicito. Tuttavia, il primo ha un ridimensionamento lineare e il secondo ha un ridimensionamento n log n. Quindi il primo tenderà a fare meglio con un numero elevato di righe e il secondo con numeri piccoli.
Ovviamente è bene avere una soluzione per questa esigenza comune, ma sarebbe molto meglio se T-SQL aggiungesse il supporto per la clausola di ordinazione NULL standard in futuro.
Conclusione
Lo standard SQL ISO/IEC ha un bel po' di funzionalità di gestione NULL che devono ancora arrivare a T-SQL. In questo articolo ne ho trattati alcuni:il predicato DISTINCT, la clausola di trattamento NULL e il controllo se i NULL ordinano per primo o per ultimo. Ho anche fornito soluzioni alternative per queste funzionalità supportate in T-SQL, ma sono ovviamente ingombranti. Il mese prossimo continuerò la discussione trattando il vincolo univoco standard, come differisce dall'implementazione di T-SQL e le soluzioni alternative che possono essere implementate in T-SQL.