Spesso, quando scriviamo una procedura memorizzata, vogliamo che si comporti in modi diversi in base all'input dell'utente. Diamo un'occhiata al seguente esempio:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Questa procedura memorizzata, che ho creato nel database AdventureWorks2017, ha due parametri:@CustomerID e @SortOrder. Il primo parametro, @CustomerID, influisce sulle righe da restituire. Se un ID cliente specifico viene passato alla stored procedure, restituisce tutti gli ordini (primi 10) per questo cliente. In caso contrario, se è NULL, la stored procedure restituisce tutti gli ordini (primi 10), indipendentemente dal cliente. Il secondo parametro, @SortOrder, determina come verranno ordinati i dati, per OrderDate o SalesOrderID. Si noti che verranno restituite solo le prime 10 righe in base all'ordinamento.
Pertanto, gli utenti possono influenzare il comportamento della query in due modi:quali righe restituire e come ordinarle. Per essere più precisi, ci sono 4 comportamenti diversi per questa query:
- Restituisce le prime 10 righe per tutti i clienti ordinati per OrderDate (il comportamento predefinito)
- Restituisce le prime 10 righe per un cliente specifico ordinate per OrderDate
- Restituisce le prime 10 righe per tutti i clienti ordinati per SalesOrderID
- Restituisce le prime 10 righe per un cliente specifico ordinate per SalesOrderID
Testiamo la stored procedure con tutte e 4 le opzioni ed esaminiamo il piano di esecuzione e le statistiche IO.
Restituisci le prime 10 righe per tutti i clienti ordinati per OrderDate
Di seguito è riportato il codice per eseguire la stored procedure:
EXECUTE Sales.GetOrders; GO
Ecco il piano di esecuzione:
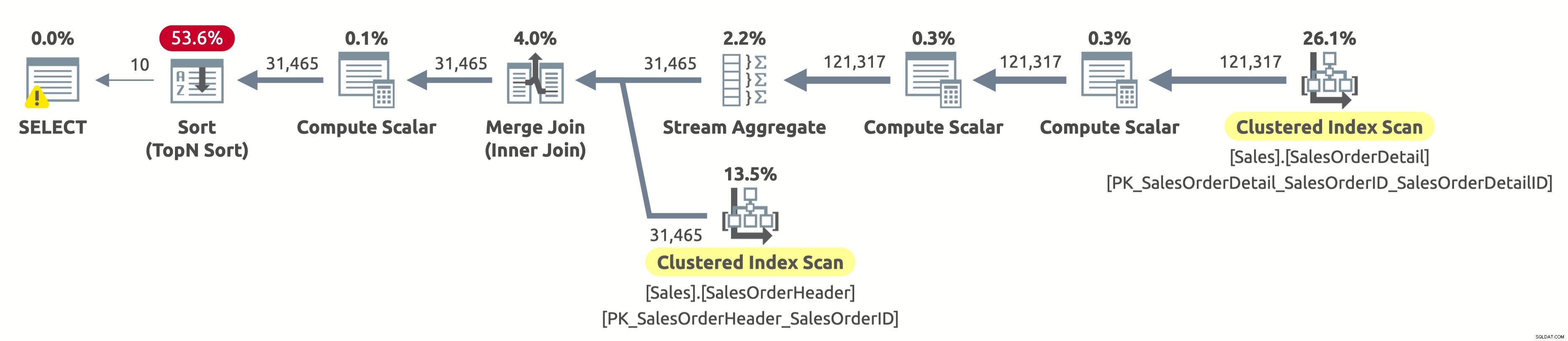
Dal momento che non abbiamo filtrato per cliente, dobbiamo scansionare l'intera tabella. L'ottimizzatore ha scelto di eseguire la scansione di entrambe le tabelle utilizzando gli indici su SalesOrderID, il che ha consentito un efficiente Stream Aggregate e un efficiente Merge Join.
Se controlli le proprietà dell'operatore Clustered Index Scan nella tabella Sales.SalesOrderHeader, troverai il seguente predicato:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[ @CustomerID] O [@CustomerID] È NULL. Il Query Processor deve valutare questo predicato per ogni riga della tabella, il che non è molto efficiente perché restituirà sempre true.
Abbiamo ancora bisogno di ordinare tutti i dati per OrderDate per restituire le prime 10 righe. Se fosse presente un indice su OrderDate, l'ottimizzatore lo avrebbe probabilmente utilizzato per scansionare solo le prime 10 righe da Sales.SalesOrderHeader, ma non esiste un tale indice, quindi il piano sembra a posto considerando gli indici disponibili.
Ecco l'output delle statistiche IO:
- Tabella 'SalesOrderHeader'. Conteggio scansioni 1, letture logiche 689
- Tabella 'SalesOrderDetail'. Conteggio scansioni 1, letture logiche 1248
Se stai chiedendo perché c'è un avviso sull'operatore SELECT, allora è un avviso di concessione eccessiva. In questo caso, non è perché c'è un problema nel piano di esecuzione, ma piuttosto perché il Query Processor ha richiesto 1.024 KB (che è il minimo per impostazione predefinita) e ha utilizzato solo 16 KB.
A volte pianificare la memorizzazione nella cache non è una buona idea
Successivamente, vogliamo testare lo scenario di restituzione delle prime 10 righe per un cliente specifico ordinato per OrderDate. Di seguito il codice:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Il piano di esecuzione è esattamente lo stesso di prima. Questa volta, il piano è molto inefficiente perché esegue la scansione di entrambe le tabelle solo per restituire 3 ordini. Esistono modi molto migliori per eseguire questa query.
Il motivo, in questo caso, è la memorizzazione nella cache del piano. Il piano di esecuzione è stato generato nella prima esecuzione in base ai valori dei parametri in quella specifica esecuzione, un metodo noto come sniffing dei parametri. Quel piano è stato archiviato nella cache del piano per il riutilizzo e, d'ora in poi, ogni chiamata a questa procedura memorizzata riutilizzerà lo stesso piano.
Questo è un esempio in cui la memorizzazione nella cache dei piani non è una buona idea. A causa della natura di questa stored procedure, che ha 4 comportamenti diversi, ci aspettiamo di ottenere un piano diverso per ogni comportamento. Ma siamo bloccati con un unico piano, che va bene solo per una delle 4 opzioni, in base all'opzione utilizzata nella prima esecuzione.
Disabilitiamo la memorizzazione nella cache dei piani per questa procedura memorizzata, solo in modo da poter vedere il miglior piano che l'ottimizzatore può elaborare per ciascuno degli altri 3 comportamenti. Lo faremo aggiungendo WITH RECOMPILE al comando ESEGUI.
Restituisci le prime 10 righe per un cliente specifico ordinate per data ordine
Di seguito è riportato il codice per restituire le prime 10 righe per un cliente specifico ordinate per OrderDate:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Quello che segue è il piano di esecuzione:
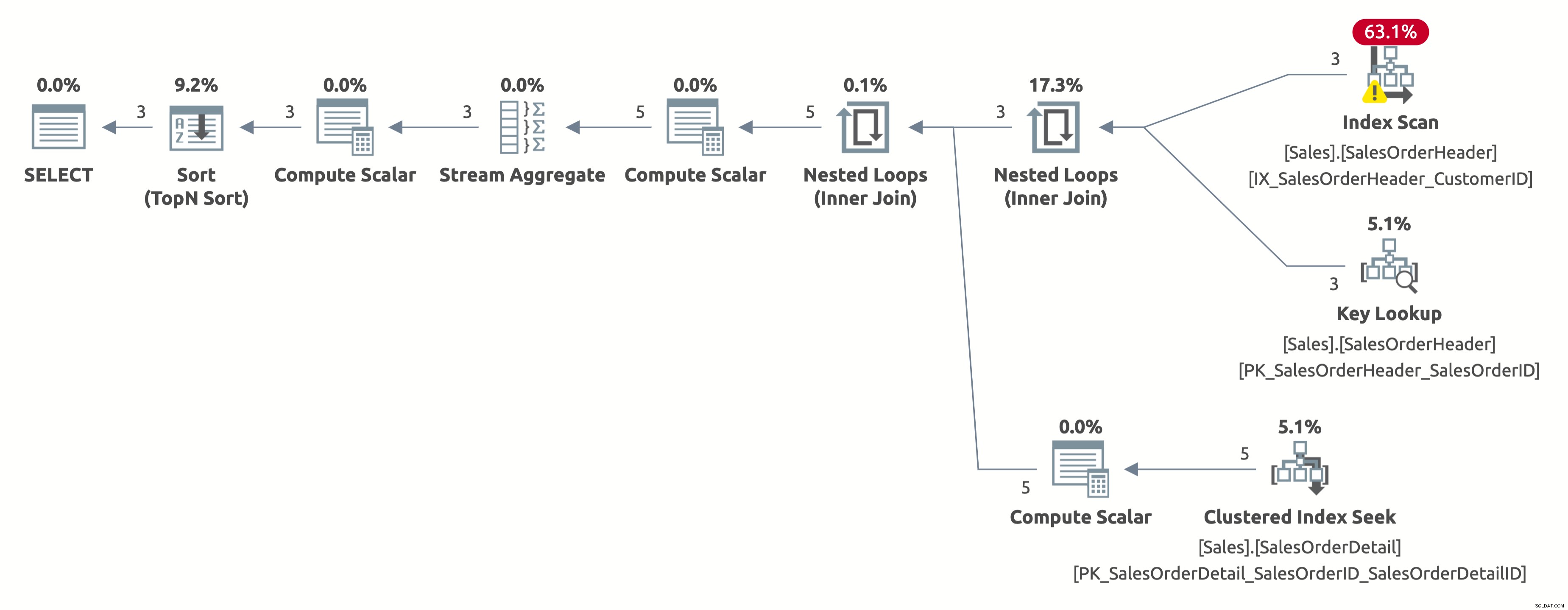
Questa volta, otteniamo un piano migliore, che utilizza un indice su CustomerID. L'ottimizzatore stima correttamente 2,6 righe per ID cliente =11006 (il numero effettivo è 3). Ma si noti che esegue una scansione dell'indice anziché una ricerca dell'indice. Non può eseguire una ricerca di indice perché deve valutare il seguente predicato per ogni riga della tabella:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID ] OPPURE [@IDCliente] È NULL.
Ecco l'output delle statistiche IO:
- Tabella 'SalesOrderDetail'. Conteggio scansioni 3, letture logiche 9
- Tabella 'SalesOrderHeader'. Conteggio scansioni 1, letture logiche 66
Restituisci le prime 10 righe per tutti i clienti ordinati per SalesOrderID
Di seguito è riportato il codice per restituire le prime 10 righe per tutti i clienti ordinati per SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Quello che segue è il piano di esecuzione:
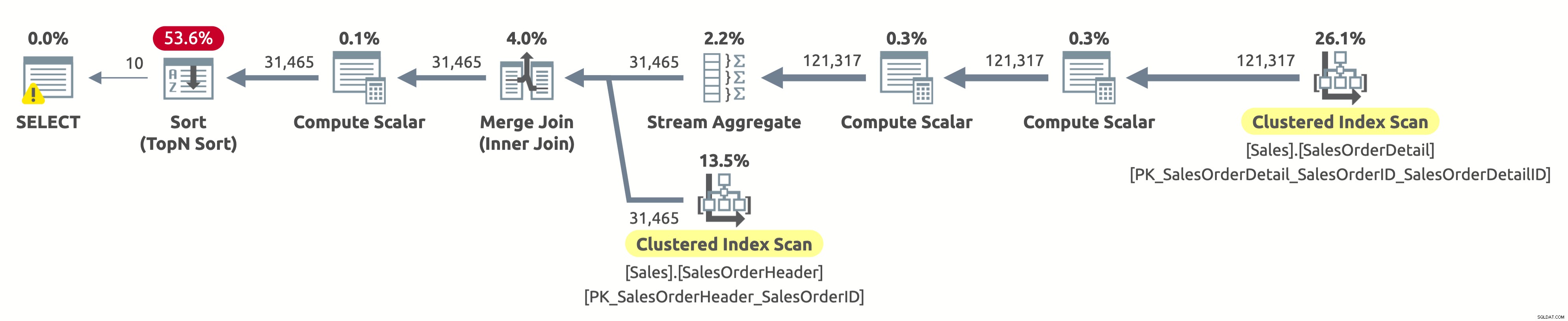
Ehi, questo è lo stesso piano di esecuzione della prima opzione. Ma questa volta qualcosa non va. Sappiamo già che gli indici cluster su entrambe le tabelle sono ordinati per SalesOrderID. Sappiamo anche che il piano esegue la scansione di entrambi nell'ordine logico per mantenere l'ordinamento (la proprietà Ordered è impostata su True). L'operatore Merge Join conserva anche l'ordinamento. Poiché ora stiamo chiedendo di ordinare il risultato per SalesOrderID, ed è già ordinato in questo modo, perché dobbiamo pagare per un costoso operatore di ordinamento?
Bene, se controlli l'operatore Ordina, noterai che ordina i dati in base a Espr1004. E, se controlli l'operatore Calcola scalare a destra dell'operatore Ordina, scoprirai che Espr1004 è il seguente:

Non è una bella vista, lo so. Questa è l'espressione che abbiamo nella clausola ORDER BY della nostra query. Il problema è che l'ottimizzatore non può valutare questa espressione in fase di compilazione, quindi deve calcolarla per ogni riga in fase di esecuzione e quindi ordinare l'intero set di record in base a quello.
L'output delle statistiche IO è proprio come nella prima esecuzione:
- Tabella 'SalesOrderHeader'. Conteggio scansioni 1, letture logiche 689
- Tabella 'SalesOrderDetail'. Conteggio scansioni 1, letture logiche 1248
Restituisci le prime 10 righe per un cliente specifico ordinate per SalesOrderID
Di seguito è riportato il codice per restituire le prime 10 righe per un cliente specifico ordinate per SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Il piano di esecuzione è lo stesso della seconda opzione (restituisci le prime 10 righe per un cliente specifico ordinate per OrderDate). Il piano presenta gli stessi due problemi, di cui abbiamo già parlato. Il primo problema è eseguire una scansione dell'indice anziché una ricerca dell'indice a causa dell'espressione nella clausola WHERE. Il secondo problema è eseguire un ordinamento costoso a causa dell'espressione nella clausola ORDER BY.
Allora, cosa dovremmo fare?
Ricordiamoci innanzitutto di cosa abbiamo a che fare. Abbiamo parametri, che determinano la struttura della query. Per ogni combinazione di valori di parametro, otteniamo una struttura di query diversa. Nel caso del parametro @CustomerID, i due diversi comportamenti sono NULL o NOT NULL e influiscono sulla clausola WHERE. Nel caso del parametro @SortOrder, sono possibili due valori e influiscono sulla clausola ORDER BY. Il risultato sono 4 possibili strutture di query e vorremmo ottenere un piano diverso per ciascuna.
Allora abbiamo due problemi distinti. Il primo è la memorizzazione nella cache dei piani. Esiste un solo piano per la stored procedure e verrà generato in base ai valori dei parametri nella prima esecuzione. Il secondo problema è che anche quando viene generato un nuovo piano, non è efficiente perché l'ottimizzatore non può valutare le espressioni "dinamiche" nella clausola WHERE e nella clausola ORDER BY in fase di compilazione.
Possiamo provare a risolvere questi problemi in diversi modi:
- Usa una serie di istruzioni IF-ELSE
- Suddivide la procedura in stored procedure separate
- Usa OPZIONE (RICIMPILA)
- Genera la query in modo dinamico
Utilizzare una serie di dichiarazioni IF-ELSE
L'idea è semplice:invece delle espressioni "dinamiche" nella clausola WHERE e nella clausola ORDER BY, possiamo dividere l'esecuzione in 4 rami usando le istruzioni IF-ELSE, un ramo per ogni possibile comportamento.
Ad esempio, quello che segue è il codice per il primo ramo:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Questo approccio può aiutare a generare piani migliori, ma presenta alcune limitazioni.
Innanzitutto, la procedura memorizzata diventa piuttosto lunga ed è più difficile da scrivere, leggere e gestire. E questo è quando abbiamo solo due parametri. Se avessimo 3 parametri, avremmo 8 rami. Immagina di dover aggiungere una colonna alla clausola SELECT. Dovresti aggiungere la colonna in 8 query diverse. Diventa un incubo di manutenzione, con un alto rischio di errore umano.
In secondo luogo, abbiamo ancora il problema della memorizzazione nella cache del piano e dello sniffing dei parametri in una certa misura. Questo perché nella prima esecuzione, l'ottimizzatore genererà un piano per tutte e 4 le query in base ai valori dei parametri in tale esecuzione. Diciamo che la prima esecuzione utilizzerà i valori predefiniti per i parametri. In particolare, il valore di @CustomerID sarà NULL. Tutte le query verranno ottimizzate in base a tale valore, inclusa la query con la clausola WHERE (SalesOrders.CustomerID =@CustomerID). L'ottimizzatore stima 0 righe per queste query. Ora, supponiamo che la seconda esecuzione utilizzerà un valore non null per @CustomerID. Verrà utilizzato il piano memorizzato nella cache, che stima 0 righe, anche se il cliente potrebbe avere molti ordini nella tabella.
Dividi la procedura in stored procedure separate
Invece di 4 branch all'interno della stessa stored procedure, possiamo creare 4 stored procedure separate, ciascuna con i parametri rilevanti e la query corrispondente. Quindi, possiamo riscrivere l'applicazione per decidere quale stored procedure eseguire in base ai comportamenti desiderati. Oppure, se vogliamo che sia trasparente per l'applicazione, possiamo riscrivere la stored procedure originale per decidere quale procedura eseguire in base ai valori dei parametri. Utilizzeremo le stesse istruzioni IF-ELSE, ma invece di eseguire una query in ogni ramo, eseguiremo una stored procedure separata.
Il vantaggio è che risolviamo il problema della memorizzazione nella cache del piano perché ogni procedura memorizzata ora ha il proprio piano e il piano per ciascuna procedura memorizzata verrà generato nella sua prima esecuzione in base allo sniffing dei parametri.
Ma abbiamo ancora il problema di manutenzione. Alcune persone potrebbero dire che ora è anche peggio, perché abbiamo bisogno di mantenere più stored procedure. Anche in questo caso, se aumentiamo il numero di parametri a 3, ci ritroveremo con 8 procedure memorizzate distinte.
Usa OPZIONE (RICIMPILA)
OPTION (RICIMPILA) funziona come per magia. Devi solo pronunciare le parole (o aggiungerle alla query) e la magia accade. In realtà, risolve così tanti problemi perché compila la query in fase di esecuzione e lo fa per ogni esecuzione.
Ma devi stare attento perché sai cosa si dice:"Da un grande potere derivano grandi responsabilità". Se utilizzi OPTION (RICIMPILA) in una query eseguita molto spesso su un sistema OLTP occupato, potresti uccidere il sistema perché il server deve compilare e generare un nuovo piano in ogni esecuzione, utilizzando molte risorse della CPU. Questo è davvero pericoloso. Tuttavia, se la query viene eseguita solo una volta ogni tanto, diciamo una volta ogni pochi minuti, probabilmente è sicuro. Ma verifica sempre l'impatto nel tuo ambiente specifico.
Nel nostro caso, supponendo che possiamo tranquillamente usare OPTION (RICIMPILA), tutto ciò che dobbiamo fare è aggiungere le parole magiche alla fine della nostra query, come mostrato di seguito:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Ora, vediamo la magia in azione. Ad esempio, il seguente è il piano per il secondo comportamento:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
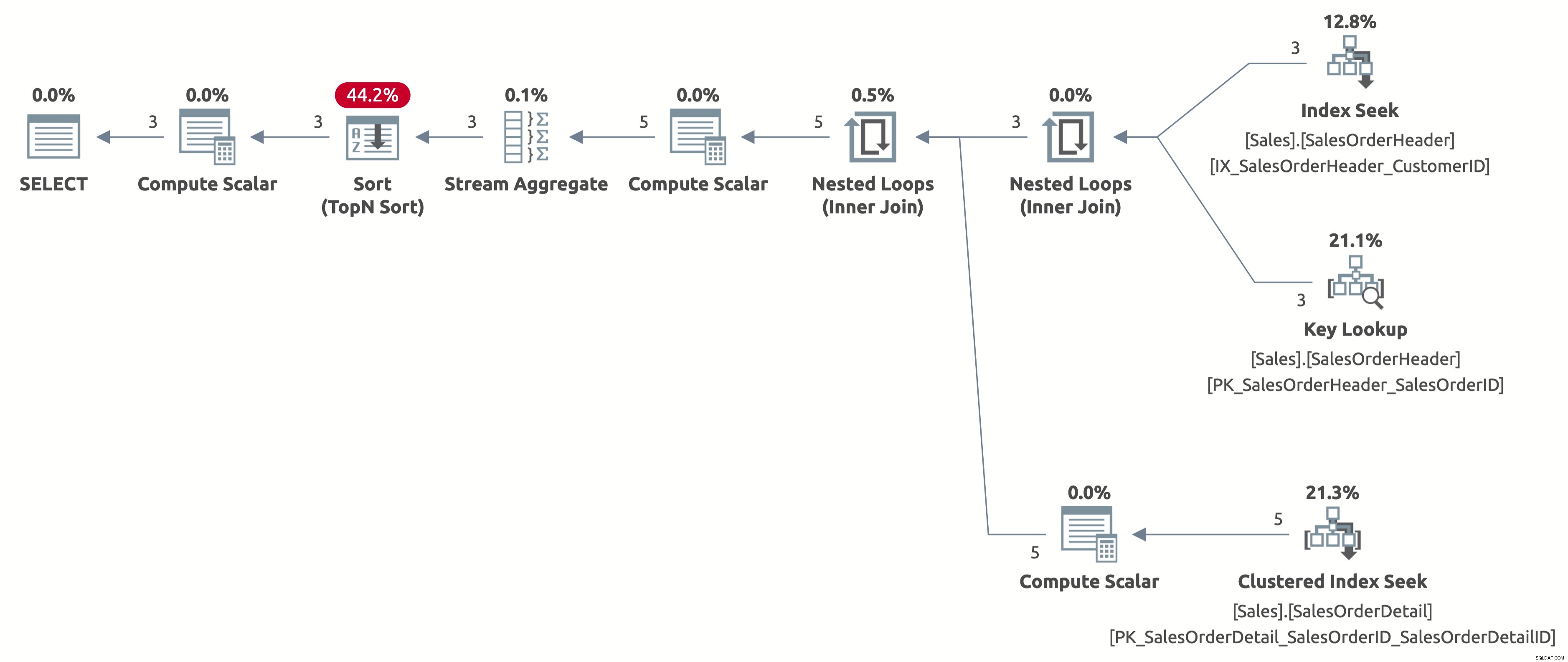
Ora otteniamo una ricerca dell'indice efficiente con una stima corretta di 2,6 righe. Abbiamo ancora bisogno di ordinare per OrderDate, ma ora l'ordinamento è direttamente per Order Date e non dobbiamo più calcolare l'espressione CASE nella clausola ORDER BY. Questo è il miglior piano possibile per questo comportamento di query in base agli indici disponibili.
Ecco l'output delle statistiche IO:
- Tabella 'SalesOrderDetail'. Conteggio scansioni 3, letture logiche 9
- Tabella 'SalesOrderHeader'. Conteggio scansioni 1, letture logiche 11
Il motivo per cui OPTION (RICIMPILA) è così efficiente in questo caso è che risolve esattamente i due problemi che abbiamo qui. Ricorda che il primo problema è la memorizzazione nella cache del piano. OPTION (RICIMPILA) elimina del tutto questo problema perché ricompila la query ogni volta. Il secondo problema è l'incapacità dell'ottimizzatore di valutare l'espressione complessa nella clausola WHERE e nella clausola ORDER BY in fase di compilazione. Poiché OPTION (RICIMPILA) si verifica in fase di esecuzione, risolve il problema. Perché in fase di esecuzione, l'ottimizzatore ha molte più informazioni rispetto al tempo di compilazione e fa la differenza.
Ora, vediamo cosa succede quando proviamo il terzo comportamento:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
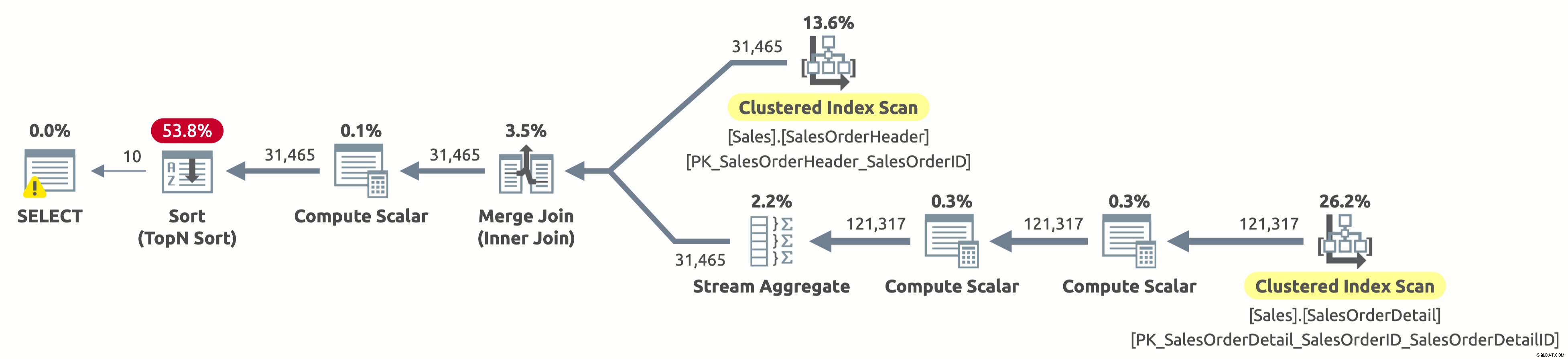
Houston abbiamo un problema. Il piano esegue comunque la scansione completa di entrambe le tabelle e quindi ordina tutto, invece di analizzare solo le prime 10 righe da Sales.SalesOrderHeader ed evitare del tutto l'ordinamento. Cosa è successo?
Questo è un "caso" interessante e ha a che fare con l'espressione CASE nella clausola ORDER BY. L'espressione CASE valuta un elenco di condizioni e restituisce una delle espressioni di risultato. Ma le espressioni dei risultati potrebbero avere tipi di dati diversi. Quindi, quale sarebbe il tipo di dati dell'intera espressione CASE? L'espressione CASE restituisce sempre il tipo di dati con la precedenza più alta. Nel nostro caso, la colonna OrderDate ha il tipo di dati DATETIME, mentre la colonna SalesOrderID ha il tipo di dati INT. Il tipo di dati DATETIME ha una precedenza più alta, quindi l'espressione CASE restituisce sempre DATETIME.
Ciò significa che se vogliamo ordinare per SalesOrderID, l'espressione CASE deve prima convertire implicitamente il valore di SalesOrderID in DATETIME per ogni riga prima di ordinarla. Vedi l'operatore Calcola scalare a destra dell'operatore Ordina nel piano sopra? È esattamente quello che fa.
Questo è di per sé un problema e dimostra quanto possa essere pericoloso mescolare diversi tipi di dati in un'unica espressione CASE.
Possiamo aggirare questo problema riscrivendo la clausola ORDER BY in altri modi, ma renderebbe il codice ancora più brutto e difficile da leggere e mantenere. Quindi, non andrò in quella direzione.
Proviamo invece il metodo successivo...
Genera la query in modo dinamico
Poiché il nostro obiettivo è generare 4 diverse strutture di query all'interno di una singola query, l'SQL dinamico può essere molto utile in questo caso. L'idea è quella di creare la query in modo dinamico in base ai valori dei parametri. In questo modo, possiamo costruire le 4 diverse strutture di query in un unico codice, senza dover mantenere 4 copie della query. Ogni struttura di query verrà compilata una volta, alla prima esecuzione, e otterrà il miglior piano perché non contiene espressioni complesse.
Questa soluzione è molto simile alla soluzione con le stored procedure multiple, ma invece di mantenere 8 stored procedure per 3 parametri, manteniamo solo un singolo codice che costruisce la query in modo dinamico.
Lo so, anche l'SQL dinamico è brutto e talvolta può essere piuttosto difficile da mantenere, ma penso che sia comunque più facile che mantenere più stored procedure e non si ridimensiona in modo esponenziale all'aumentare del numero di parametri.
Quello che segue è il codice:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Si noti che utilizzo ancora un parametro interno per l'ID cliente ed eseguo il codice dinamico utilizzando sys.sp_executesql per passare il valore del parametro. Questo è importante per due ragioni. Innanzitutto, per evitare compilazioni multiple della stessa struttura di query per valori diversi di @CustomerID. In secondo luogo, per evitare SQL injection.
Se provi a eseguire la procedura memorizzata ora utilizzando valori di parametro diversi, vedrai che ogni comportamento di query o struttura di query ottiene il miglior piano di esecuzione e ciascuno dei 4 piani viene compilato solo una volta.
Ad esempio, il seguente è il piano per il terzo comportamento:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
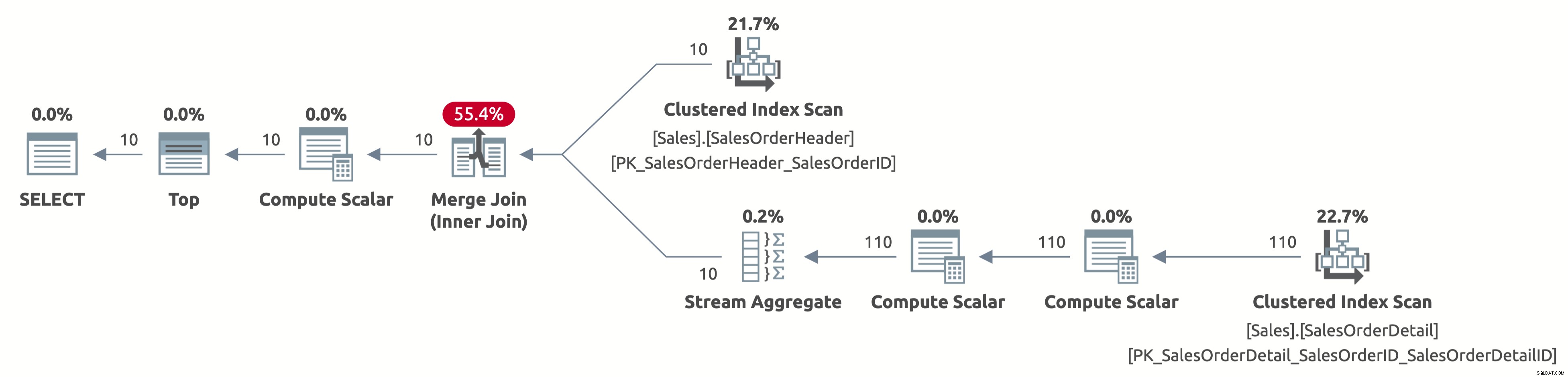
Ora analizziamo solo le prime 10 righe della tabella Sales.SalesOrderHeader e analizziamo anche solo le prime 110 righe della tabella Sales.SalesOrderDetail. Inoltre, non esiste un operatore di ordinamento perché i dati sono già ordinati per SalesOrderID.
Ecco l'output delle statistiche IO:
- Tabella 'SalesOrderDetail'. Conteggio scansioni 1, letture logiche 4
- Tabella 'SalesOrderHeader'. Conteggio scansioni 1, letture logiche 3
Conclusione
Quando usi i parametri per modificare la struttura della query, non usare espressioni complesse all'interno della query per derivare il comportamento previsto. Nella maggior parte dei casi, ciò porterà a prestazioni scadenti e per buoni motivi. Il primo motivo è che il piano verrà generato in base alla prima esecuzione, quindi tutte le esecuzioni successive riutilizzeranno lo stesso piano, che è appropriato solo per una struttura di query. Il secondo motivo è che l'ottimizzatore è limitato nella sua capacità di valutare quelle espressioni complesse in fase di compilazione.
Esistono diversi modi per superare questi problemi e li abbiamo esaminati in questo articolo. Nella maggior parte dei casi, il metodo migliore sarebbe creare la query in modo dinamico in base ai valori dei parametri. In questo modo, ogni struttura di query verrà compilata una volta con il miglior piano possibile.
Quando crei la query utilizzando SQL dinamico, assicurati di utilizzare i parametri ove appropriato e verifica che il tuo codice sia sicuro.