Questa è la seconda parte di una serie sulle soluzioni alla sfida del generatore di serie numeriche. Il mese scorso ho trattato soluzioni che generano le righe al volo utilizzando un costruttore di valori di tabella con righe basate su costanti. Non c'erano operazioni di I/O coinvolte in queste soluzioni. Questo mese mi concentro sulle soluzioni che interrogano una tabella di base fisica che precompili con le righe. Per questo motivo, oltre a riportare il profilo temporale delle soluzioni come ho fatto il mese scorso, riporterò anche il profilo di I/O delle nuove soluzioni. Grazie ancora ad Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 e Ed Wagner per aver condiviso idee e commenti.
La soluzione più veloce finora
Innanzitutto, come rapido promemoria, esaminiamo la soluzione più veloce dell'articolo del mese scorso, implementata come TVF in linea chiamata dbo.GetNumsAlanCharlieItzikBatch.
Farò i miei test in tempdb, abilitando le statistiche IO e TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
La soluzione più veloce del mese scorso applica un join con una tabella fittizia con un indice columnstore per ottenere l'elaborazione batch. Ecco il codice per creare la tabella fittizia:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Ed ecco il codice con la definizione della funzione dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Il mese scorso ho utilizzato il codice seguente per testare le prestazioni della funzione con 100 milioni di righe, dopo aver abilitato i risultati di Elimina dopo l'esecuzione in SSMS per sopprimere la restituzione delle righe di output:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche temporali che ho ottenuto per questa esecuzione:
Tempo CPU =16031 ms, tempo trascorso =17172 ms.Joe Obbish ha correttamente notato che questo test potrebbe non rispecchiare alcuni scenari della vita reale, nel senso che una grossa fetta del tempo di esecuzione è dovuta ad attese di I/O di rete asincrone (tipo di attesa ASYNC_NETWORK_IO). È possibile osservare le attese più elevate esaminando la pagina delle proprietà del nodo radice del piano di query effettivo o eseguire una sessione di eventi estesa con informazioni sull'attesa. Il fatto che si abiliti Elimina risultati dopo l'esecuzione in SSMS non impedisce a SQL Server di inviare le righe dei risultati a SSMS; impedisce semplicemente a SSMS di stamparli. La domanda è:quanto è probabile che restituirai al cliente set di risultati di grandi dimensioni in scenari di vita reale anche quando utilizzi la funzione per produrre una serie di numeri di grandi dimensioni? Forse più spesso scrivi i risultati della query in una tabella o usi il risultato della funzione come parte di una query che alla fine produce un piccolo set di risultati. Devi capirlo. Puoi scrivere il set di risultati in una tabella temporanea usando l'istruzione SELECT INTO, oppure puoi usare il trucco di Alan Burstein con un'istruzione SELECT di assegnazione, che assegna il valore della colonna del risultato a una variabile.
Ecco come modificare l'ultimo test per utilizzare l'opzione di assegnazione delle variabili:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ecco le statistiche temporali che ho ottenuto per questo test:
Tempo CPU =8641 ms, tempo trascorso =8645 ms.Questa volta le informazioni di attesa non hanno attese di I/O di rete asincrone e puoi vedere il calo significativo del tempo di esecuzione.
Testare di nuovo la funzione, questa volta aggiungendo l'ordine:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Ho ottenuto le seguenti statistiche sulle prestazioni per questa esecuzione:
Tempo CPU =9360 ms, tempo trascorso =9551 ms.Ricordiamo che non è necessario un operatore di ordinamento nel piano per questa query poiché la colonna n si basa su un'espressione che preserva l'ordine rispetto alla colonna rownum. Questo grazie al costante trucco di piegatura di Charli, di cui ho parlato il mese scorso. I piani per entrambe le query, quella senza ordinazione e quella con ordinazione, sono gli stessi, quindi le prestazioni tendono a essere simili.
La figura 1 riassume i numeri delle prestazioni che ho ottenuto per le soluzioni del mese scorso, solo che questa volta utilizzando l'assegnazione di variabili nei test invece di scartare i risultati dopo l'esecuzione.
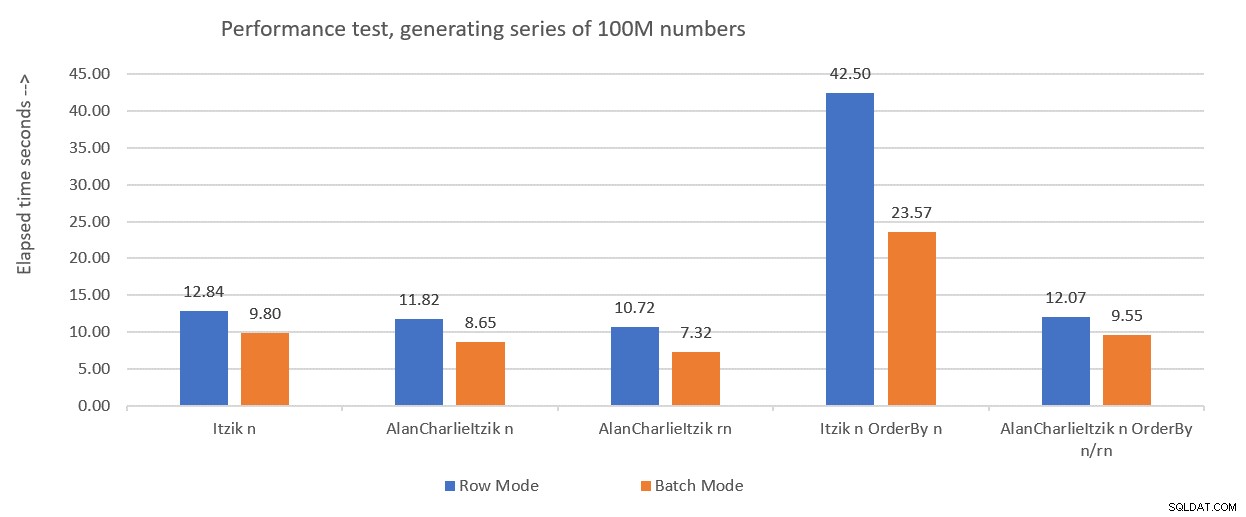 Figura 1:Sintesi delle prestazioni finora con assegnazione variabile
Figura 1:Sintesi delle prestazioni finora con assegnazione variabile
Userò la tecnica di assegnazione delle variabili per testare il resto delle soluzioni che presenterò in questo articolo. Assicurati di adattare i tuoi test per riflettere al meglio la tua situazione di vita reale, utilizzando l'assegnazione variabile, SELECT INTO, Scarta i risultati dopo l'esecuzione o qualsiasi altra tecnica.
Suggerimento per forzare i piani seriali senza MAXDOP 1
Prima di presentare nuove soluzioni, volevo solo coprire un piccolo consiglio. Ricordiamo che alcune delle soluzioni funzionano meglio quando si utilizza un piano seriale. Il modo più ovvio per forzarlo è con un suggerimento per la query MAXDOP 1. E questa è la strada giusta da percorrere se a volte vorrai abilitare il parallelismo ea volte no. Tuttavia, cosa succede se si desidera sempre forzare un piano seriale quando si utilizza la funzione, anche se in uno scenario meno probabile?
C'è un trucco per raggiungere questo obiettivo. L'uso di una UDF scalare non inlineabile nella query è un inibitore del parallelismo. Uno degli inibitori di inlining UDF scalari sta invocando una funzione intrinseca che dipende dal tempo, come SYSDATETIME. Quindi ecco un esempio per una UDF scalare non inlineabile:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Un'altra opzione consiste nel definire una UDF con solo una costante come valore restituito e utilizzare l'opzione INLINE =OFF nella sua intestazione. Ma questa opzione è disponibile solo a partire da SQL Server 2019, che ha introdotto l'inlining UDF scalare. Con la funzione suggerita sopra, puoi crearla come con le versioni precedenti di SQL Server.
Quindi, modifica la definizione della funzione dbo.GetNumsAlanCharlieItzikBatch per avere una chiamata fittizia a dbo.MySYSDATETIME (definisci una colonna basata su di essa ma non fare riferimento alla colonna nella query restituita), in questo modo:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Ora puoi rieseguire il test delle prestazioni senza specificare MAXDOP 1 e ottenere comunque un piano seriale:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
È importante sottolineare, tuttavia, che qualsiasi query che utilizza questa funzione riceverà ora un piano seriale. Se c'è qualche possibilità che la funzione venga utilizzata in query che beneficeranno di piani paralleli, è meglio non usare questo trucco e quando hai bisogno di un piano seriale, usa semplicemente MAXDOP 1.
Soluzione di Joe Obbish
La soluzione di Joe è piuttosto creativa. Ecco la sua descrizione della soluzione:
“Ho optato per la creazione di un indice columnstore cluster (CCI) con 134.217.728 righe di numeri interi sequenziali. La funzione fa riferimento alla tabella fino a 32 volte per ottenere tutte le righe necessarie per il set di risultati. Ho scelto un CCI perché i dati si comprimeranno bene (meno di 3 byte per riga), ottieni la modalità batch "gratuitamente" e l'esperienza precedente suggerisce che leggere i numeri sequenziali da un CCI sarà più veloce che generarli con qualche altro metodo. "Come accennato in precedenza, Joe ha anche notato che il mio test delle prestazioni originale è stato notevolmente distorto a causa delle attese di I/O di rete asincrone generate dalla trasmissione delle righe a SSMS. Quindi tutti i test che eseguirò qui utilizzeranno l'idea di Alan con l'assegnazione delle variabili. Assicurati di adattare i tuoi test in base a ciò che rispecchia maggiormente la tua situazione di vita reale.
Ecco il codice utilizzato da Joe per creare la tabella dbo.GetNumsObbishTable e popolarla con 134.217.728 righe:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Ci sono voluti 1:04 minuti per completare questo codice sulla mia macchina.
Puoi controllare l'utilizzo dello spazio di questa tabella eseguendo il codice seguente:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Ho circa 350 MB di spazio utilizzato. Rispetto alle altre soluzioni che presenterò in questo articolo, questa utilizza molto più spazio.
Nell'architettura columnstore di SQL Server, un gruppo di righe è limitato a 2^20 =1.048.576 righe. Puoi controllare quanti gruppi di righe sono stati creati per questa tabella utilizzando il codice seguente:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Ho 128 gruppi di righe.
Ecco il codice con la definizione della funzione dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
Le 32 singole query generano i sottointervalli disgiunti di 134.217.728 interi che, una volta unificati, producono l'intervallo ininterrotto completo da 1 a 4.294.967.296. La cosa davvero intelligente di questa soluzione sono i predicati del filtro WHERE utilizzati dalle singole query. Ricordiamo che quando SQL Server elabora un TVF inline, applica prima l'incorporamento dei parametri, sostituendo i parametri con le costanti di input. SQL Server può quindi ottimizzare le query che producono intervalli secondari che non si intersecano con l'intervallo di input. Ad esempio, quando si richiede l'intervallo di input da 1 a 100.000.000, solo la prima query è rilevante e tutto il resto viene ottimizzato. Il piano quindi in questo caso comporterà un riferimento a una sola istanza della tabella. È davvero fantastico!
Testiamo le prestazioni della funzione con l'intervallo da 1 a 100.000.000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Il piano per questa query è mostrato nella Figura 2.
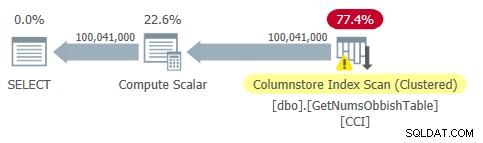 Figura 2:piano per dbo.GetNumsObbish, 100 milioni di righe, non ordinate
Figura 2:piano per dbo.GetNumsObbish, 100 milioni di righe, non ordinate
Osserva che in questo piano è necessario un solo riferimento al CCI della tabella.
Ho ottenuto le seguenti statistiche temporali per questa esecuzione:
È piuttosto impressionante e di gran lunga più veloce di qualsiasi altra cosa che ho testato.
Ecco le statistiche di I/O che ho ottenuto per questa esecuzione:
Tabella 'GetNumsObbishTable'. Conteggio scansioni 1, letture logiche 0, letture fisiche 0, letture del page server 0, letture read-ahead 0, letture del page server read-ahead 0, letture logiche lob 32928 , lob fisico legge 0, il server della pagina lob legge 0, il read-ahead lob legge 0, il server della pagina lob legge 0.Tabella 'GetNumsObbishTable'. Il segmento legge 96 , segmento saltato 32.
Il profilo I/O di questa soluzione è uno dei suoi aspetti negativi rispetto alle altre, poiché in questa esecuzione vengono eseguite oltre 30.000 letture logiche lob.
Per vedere che quando attraversi più sottointervalli di 134.217.728 interi il piano comporterà più riferimenti alla tabella, interroga la funzione con l'intervallo da 1 a 400.000.000, ad esempio:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Il piano per questa esecuzione è mostrato nella Figura 3.
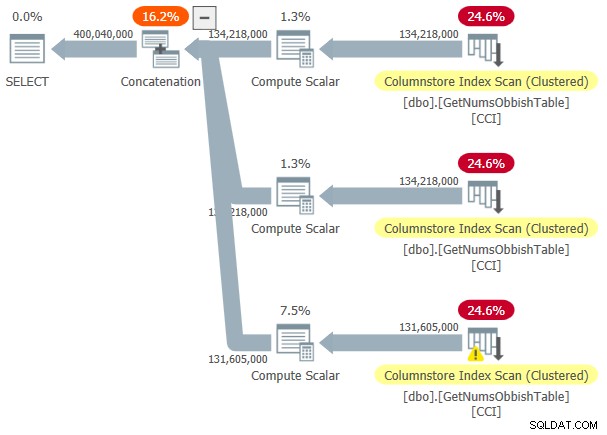 Figura 3:piano per dbo.GetNumsObbish, 400 milioni di righe, non ordinate
Figura 3:piano per dbo.GetNumsObbish, 400 milioni di righe, non ordinate
L'intervallo richiesto ha superato tre sottointervalli di 134.217.728 interi, quindi il piano mostra tre riferimenti al CCI della tabella.
Ecco le statistiche temporali che ho ottenuto per questa esecuzione:
Tempo CPU =20610 ms, tempo trascorso =20628 ms.Ed ecco le sue statistiche I/O:
Tabella 'GetNumsObbishTable'. Conteggio scansioni 3, letture logiche 0, letture fisiche 0, letture del page server 0, letture read-ahead 0, letture del page server read-ahead 0, letture logiche lob 131026 , lob fisico legge 0, il server della pagina lob legge 0, il read-ahead lob legge 0, il server della pagina lob legge 0.Tabella 'GetNumsObbishTable'. Il segmento legge 382 , segmento saltato 2.
Questa volta l'esecuzione della query ha prodotto oltre 130.000 letture logiche lob.
Se riesci a sopportare i costi di I/O e non hai bisogno di elaborare le serie numeriche in modo ordinato, questa è un'ottima soluzione. Tuttavia, se è necessario elaborare le serie in ordine, questa soluzione risulterà in un operatore di ordinamento nel piano. Ecco un test che richiede il risultato ordinato:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Il piano per questa esecuzione è mostrato nella Figura 4.
 Figura 4:piano per dbo.GetNumsObbish, 100 milioni di righe, ordinate
Figura 4:piano per dbo.GetNumsObbish, 100 milioni di righe, ordinate
Ecco le statistiche temporali che ho ottenuto per questa esecuzione:
Tempo CPU =44516 ms, tempo trascorso =34836 ms.Come puoi vedere, le prestazioni sono diminuite notevolmente con il tempo di esecuzione che è aumentato di un ordine di grandezza a causa dell'ordinamento esplicito.
Ecco le statistiche di I/O che ho ottenuto per questa esecuzione:
Tabella 'GetNumsObbishTable'. Conteggio scansioni 4, letture logiche 0, letture fisiche 0, letture del page server 0, letture read-ahead 0, letture del page server read-ahead 0, letture logiche lob 32928 , lob fisico legge 0, il server della pagina lob legge 0, il read-ahead lob legge 0, il server della pagina lob legge 0.Tabella 'GetNumsObbishTable'. Il segmento legge 96 , segmento saltato 32.
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture del page server 0, letture read-ahead 0, letture read-ahead del server delle pagine 0, letture logiche lob 0, letture fisiche lob 0, letture del server delle pagine lob 0, letture lob- avanti legge 0, il server di pagina lob read-ahead legge 0.
Osservare che un Worktable è apparso nell'output di STATISTICS IO. Questo perché un ordinamento può potenzialmente riversarsi su tempdb, nel qual caso utilizzerebbe un tavolo di lavoro. Questa esecuzione non è stata versata, quindi i numeri sono tutti zeri in questa voce.
Soluzione di John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 ha pubblicato una soluzione che è semplicemente bellissima nella sua semplicità. Inoltre, include idee e suggerimenti dalle altre soluzioni di Dave, Joe, Alan, Charlie e me stesso.
Come con la soluzione di Joe, John ha deciso di utilizzare un CCI per ottenere un elevato livello di compressione e un'elaborazione batch "gratuita". Solo John ha deciso di riempire la tabella con 4B righe con un contrassegno NULL fittizio in una colonna di bit e fare in modo che la funzione ROW_NUMBER generi i numeri. Poiché i valori archiviati sono tutti uguali, con la compressione dei valori ripetuti è necessario molto meno spazio, con conseguenti I/O significativamente inferiori rispetto alla soluzione di Joe. La compressione Columnstore gestisce molto bene i valori ripetuti poiché può rappresentare ciascuna di queste sezioni consecutive all'interno del segmento di colonna di un gruppo di righe solo una volta insieme al conteggio delle occorrenze ripetute consecutivamente. Poiché tutte le righe hanno lo stesso valore (l'indicatore NULL), in teoria è necessaria solo una occorrenza per gruppo di righe. Con 4B righe, dovresti finire con 4.096 gruppi di righe. Ciascuno dovrebbe avere un singolo segmento di colonne, con requisiti di utilizzo dello spazio molto ridotti.
Ecco il codice per creare e popolare la tabella, implementata come CCI con compressione archivistica:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Il principale svantaggio di questa soluzione è il tempo necessario per popolare questa tabella. Ci sono voluti 12:32 minuti per completare questo codice sulla mia macchina quando consentiva il parallelismo e 15:17 minuti quando forzavo un piano seriale.
Tieni presente che potresti lavorare sull'ottimizzazione del carico di dati. Ad esempio, John ha testato una soluzione che caricava le righe utilizzando 32 connessioni simultanee con OSTRESS.EXE, ciascuna con 128 round di inserimenti di 2^20 righe (dimensione massima del gruppo di righe). Questa soluzione ha ridotto il tempo di caricamento di John a un terzo. Ecco il codice utilizzato da John:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"CON L0 AS (SELECT CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) COME D(b)), L1 AS (SELECT A.b FROM L0 COME CROSS JOIN L0 AS B), L2 AS (SELECT A.b FROM L1 COME CROSS JOIN L1 AS B), nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Tuttavia, il tempo di caricamento è in minuti. La buona notizia è che devi eseguire questo caricamento dei dati solo una volta.
La grande novità è il poco spazio necessario al tavolo. Utilizza il codice seguente per verificare l'utilizzo dello spazio:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Ho 1,64 MB. È incredibile considerando il fatto che la tabella ha 4B righe!
Utilizza il codice seguente per verificare quanti gruppi di righe sono stati creati:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Come previsto, il numero di gruppi di righe è 4.096.
La definizione della funzione dbo.GetNumsJohn2DaveObbishAlanCharlieItzik diventa quindi piuttosto semplice:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Come puoi vedere, una semplice query sulla tabella utilizza la funzione ROW_NUMBER per calcolare i numeri di riga di base (colonna rownum), quindi la query esterna utilizza le stesse espressioni di dbo.GetNumsAlanCharlieItzikBatch per calcolare rn, op e n. Anche qui, sia rn che n mantengono l'ordine rispetto a rownum.
Testiamo le prestazioni della funzione:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Ho ottenuto il piano mostrato nella Figura 5 per questa esecuzione.
 Figura 5:piano per dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figura 5:piano per dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Ecco le statistiche temporali che ho ottenuto per questo test:
Tempo CPU =7593 ms, tempo trascorso =7590 ms.
Come puoi vedere, il tempo di esecuzione non è veloce come con la soluzione di Joe, ma è comunque più veloce di tutte le altre soluzioni che ho testato.
Ecco le statistiche di I/O che ho ottenuto per questo test:
Tabella 'NullBits4B'. Il segmento legge 96 , segmento saltato 0
Osserva che i requisiti di I/O sono notevolmente inferiori rispetto alla soluzione di Joe.
L'altro vantaggio di questa soluzione è che quando devi elaborare le serie di numeri ordinate, non paghi alcun extra. Questo perché non risulterà in un'operazione di ordinamento esplicita nel piano, indipendentemente dal fatto che tu ordini il risultato per rn o n.
Ecco un test per dimostrarlo:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Ottieni lo stesso piano mostrato in precedenza nella Figura 5.
Ecco le statistiche sul tempo che ho ottenuto per questo test;
Tempo CPU =7578 ms, tempo trascorso =7582 ms.Ed ecco le statistiche di I/O:
Tabella 'NullBits4B'. Conteggio scansioni 1, letture logiche 0, letture fisiche 0, letture del page server 0, letture read-ahead 0, letture del page server read-ahead 0, letture logiche lob 194 , lob fisico legge 0, il server della pagina lob legge 0, il read-ahead lob legge 0, il server della pagina lob legge 0.Tabella 'NullBits4B'. Il segmento legge 96 , segmento saltato 0.
Sono sostanzialmente gli stessi del test senza l'ordinazione.
Soluzione 2 di John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
La soluzione di John è veloce e semplice. È fantastico. L'unico aspetto negativo è il tempo di caricamento. A volte questo non sarà un problema poiché il caricamento avviene solo una volta. Ma se si tratta di un problema, puoi popolare la tabella con 102.400 righe invece di 4B righe e utilizzare un cross join tra due istanze della tabella e un filtro TOP per generare il massimo desiderato di 4B righe. Si noti che per ottenere 4B righe sarebbe sufficiente popolare la tabella con 65.536 righe e quindi applicare un cross join; tuttavia, per ottenere che i dati vengano compressi immediatamente, anziché essere caricati in un archivio delta basato su rowstore, è necessario caricare la tabella con un minimo di 102.400 righe.
Ecco il codice per creare e popolare la tabella:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Il tempo di caricamento è trascurabile:43 ms sulla mia macchina.
Controlla la dimensione della tabella su disco:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Ho 56 KB di spazio necessario per i dati.
Controlla il numero di rowgroup, il loro stato (compresso o aperto) e la loro dimensione:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Ho ottenuto il seguente output:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Qui è necessario solo un gruppo di righe; è compresso e la dimensione è di 293 byte trascurabili.
Se si popola la tabella con una riga in meno (102.399), si ottiene un archivio delta aperto non compresso basato su rowstore. In tal caso sp_spaceused riporta una dimensione dei dati su disco superiore a 1 MB e sys.column_store_row_groups riporta le seguenti informazioni:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Quindi assicurati di popolare la tabella con 102.400 righe!
Ecco la definizione della funzione dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
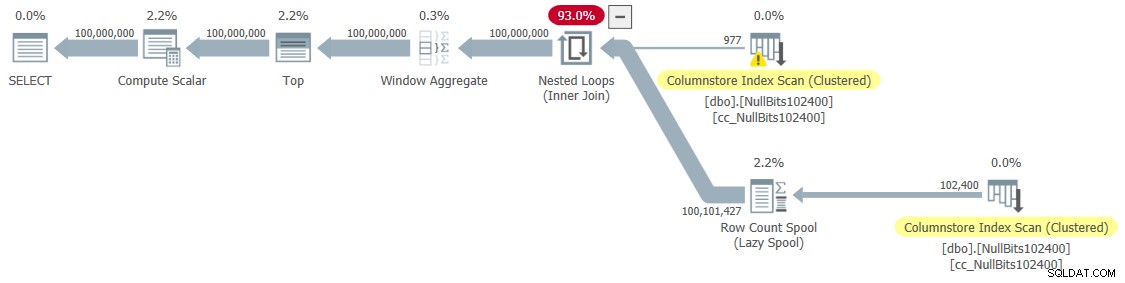 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
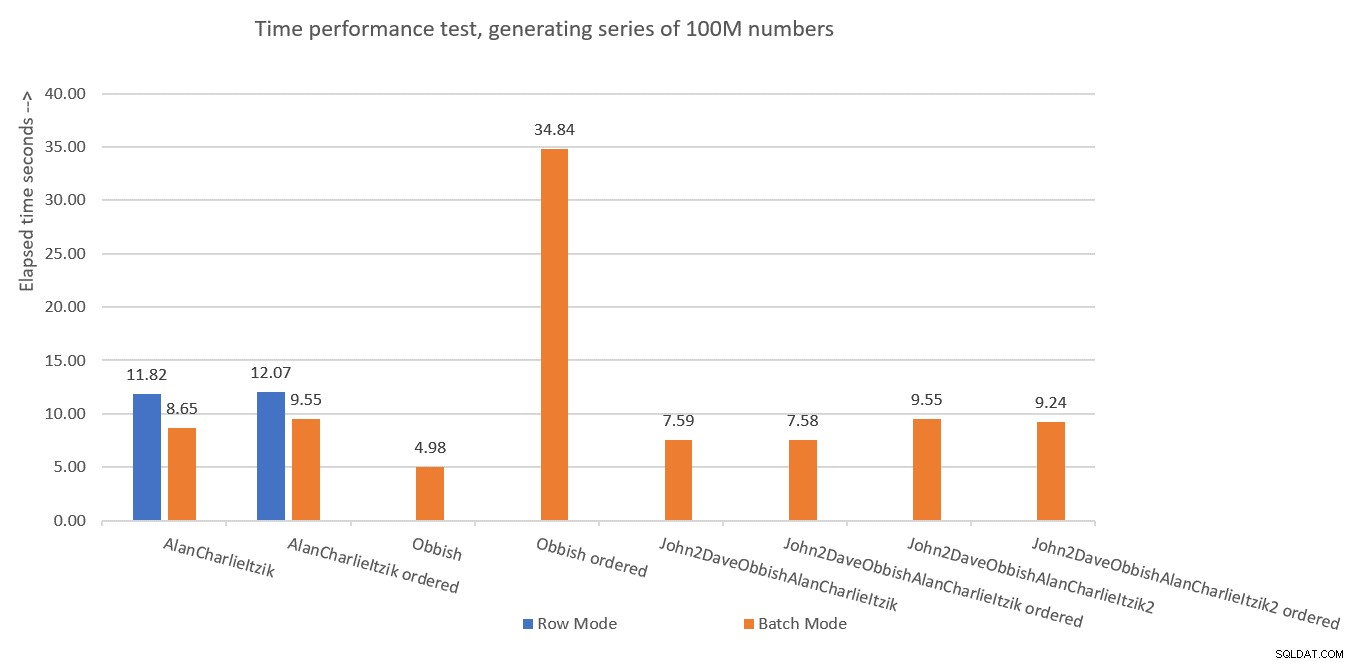 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
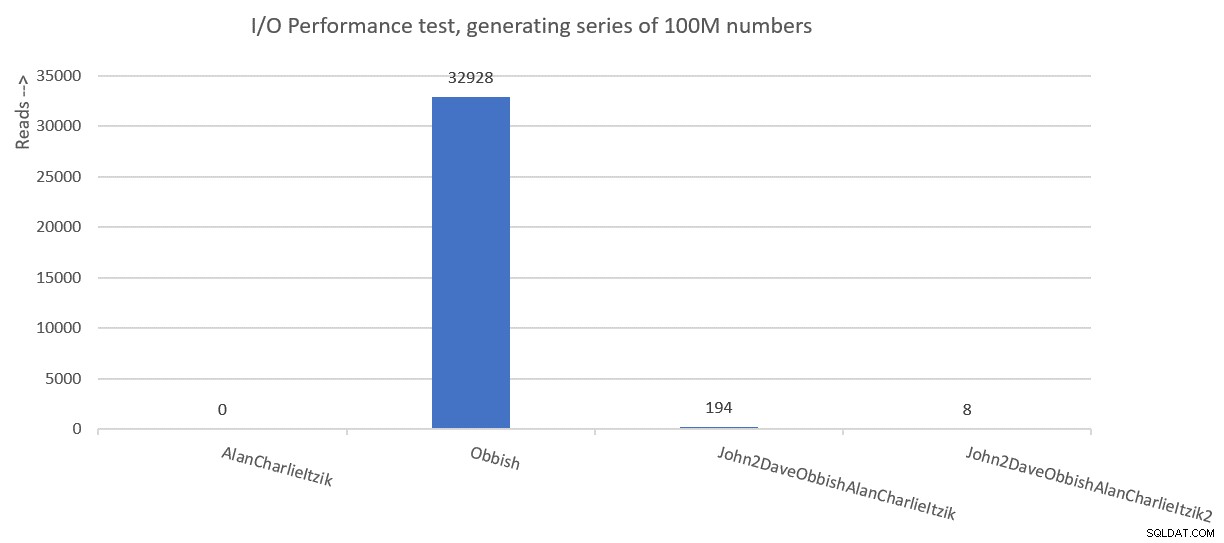 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Il mese prossimo continuerò a esplorare soluzioni aggiuntive.