Questa domanda è stata postata su #sqlhelp da Jake Manske ed è stata portata alla mia attenzione da Erik Darling.
Non ricordo di aver mai avuto problemi di prestazioni con sys.partitions . Il mio pensiero iniziale (echeggiato da Joey D'Antoni) era che un filtro sulla data_compression colonna dovrebbe evitare la scansione ridondante e ridurre di circa la metà il tempo di esecuzione delle query. Tuttavia, questo predicato non viene respinto e il motivo per cui richiede un po' di spacchettamento.
Perché sys.partitions è lento?
Se guardi la definizione di sys.partitions , è fondamentalmente ciò che Jake ha descritto:un UNION ALL di tutte le partizioni columnstore e rowstore, con TRE riferimenti espliciti a sys.sysrowsets (fonte abbreviata qui):
CREATE VIEW sys.partitions AS
WITH partitions_columnstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 1 -- Consider only columnstore base indexes
),
partitions_rowstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 0 -- Ignore columnstore base indexes and orphaned rows.
)
SELECT ...cols...
from partitions_rowstore p OUTER APPLY OpenRowset(TABLE ALUCOUNT, p.partition_id, 0, 0, p.object_id) ct
union all
SELECT ...cols...
FROM partitions_columnstore as P1
LEFT JOIN
(SELECT ...cols...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
------- *** ^^^^^^^^^^^^^^ ***
) ...
Questo punto di vista sembra combinato, probabilmente a causa di problemi di compatibilità con le versioni precedenti. Potrebbe sicuramente essere riscritto per essere più efficiente, in particolare per fare riferimento solo a sys.sysrowsets e TABLE ALUCOUNT oggetti una volta. Ma non c'è molto che tu o io possiamo fare al riguardo in questo momento.
La colonna cmprlevel proviene da sys.sysrowsets (un prefisso alias sul riferimento di colonna sarebbe stato utile). Spereresti che un predicato contro una colonna si verifichi logicamente prima di qualsiasi OUTER APPLY e potrebbe impedire una delle scansioni, ma non è quello che succede. Esecuzione della seguente semplice query:
SELECT * FROM sys.partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Fornisce il seguente piano quando sono presenti indici columnstore nei database (fare clic per ingrandire):
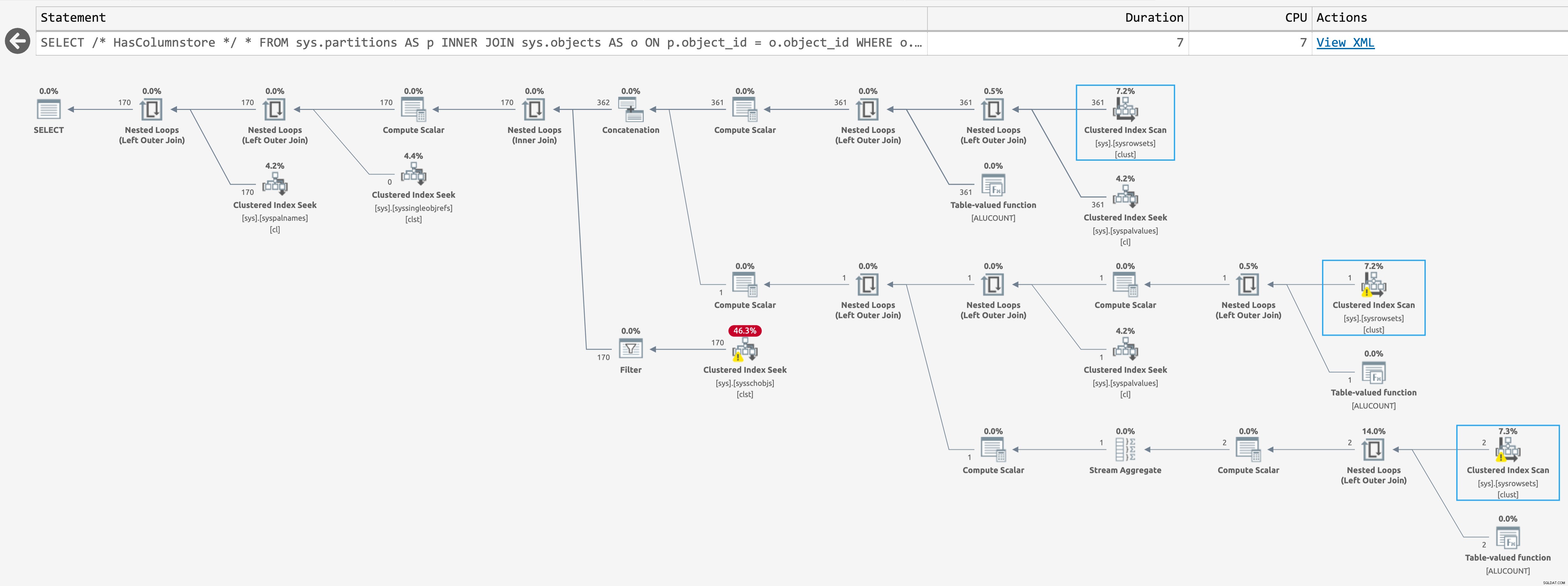 Piano per sys.partitions, con indici columnstore presenti
Piano per sys.partitions, con indici columnstore presenti
E il seguente piano quando non ci sono (clicca per ingrandire):
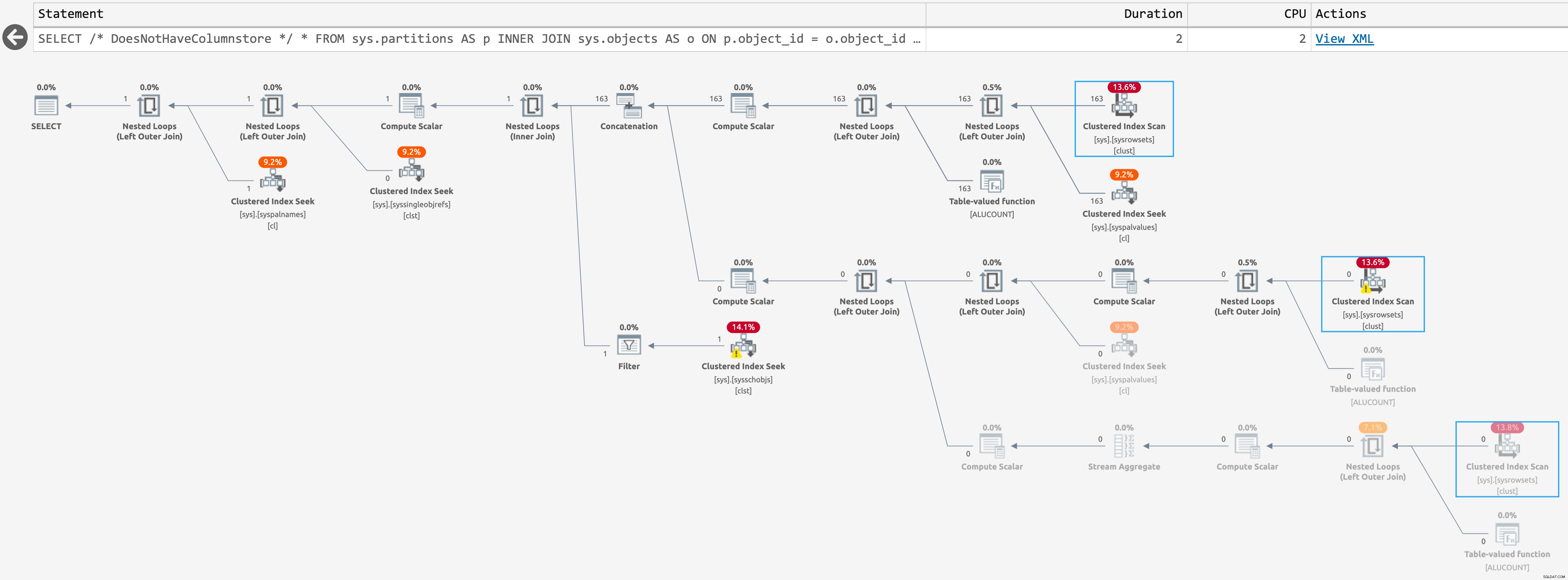 Pianifica per sys.partitions, senza indici columnstore presenti
Pianifica per sys.partitions, senza indici columnstore presenti
Si tratta dello stesso piano stimato, ma SentryOne Plan Explorer è in grado di evidenziare quando un'operazione viene saltata in fase di esecuzione. Ciò accade per la terza scansione nell'ultimo caso, ma non so che ci sia un modo per ridurre ulteriormente il conteggio delle scansioni di runtime; la seconda scansione avviene anche quando la query restituisce zero righe.
Nel caso di Jake, ha molto di oggetti, quindi eseguire questa scansione anche due volte è evidente, doloroso e una volta di troppo. E onestamente non so se TABLE ALUCOUNT , una chiamata di loopback interna e non documentata, deve anche scansionare più volte alcuni di questi oggetti più grandi.
Guardando indietro alla fonte, mi chiedevo se ci fosse qualche altro predicato che potesse essere passato alla vista che potesse forzare la forma del piano, ma davvero non penso che ci sia qualcosa che potrebbe avere un impatto.
Funzionerà un'altra vista?
Potremmo, tuttavia, provare una visione completamente diversa. Ho cercato altre viste che contenevano riferimenti a entrambi sys.sysrowsets e ALUCOUNT e ce ne sono molti che compaiono nell'elenco, ma solo due sono promettenti:sys.internal_partitions e sys.system_internals_partitions .
sys.internal_partitions
Ho provato sys.internal_partitions primo:
SELECT * FROM sys.internal_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Ma il piano non era molto migliore (clicca per ingrandire):
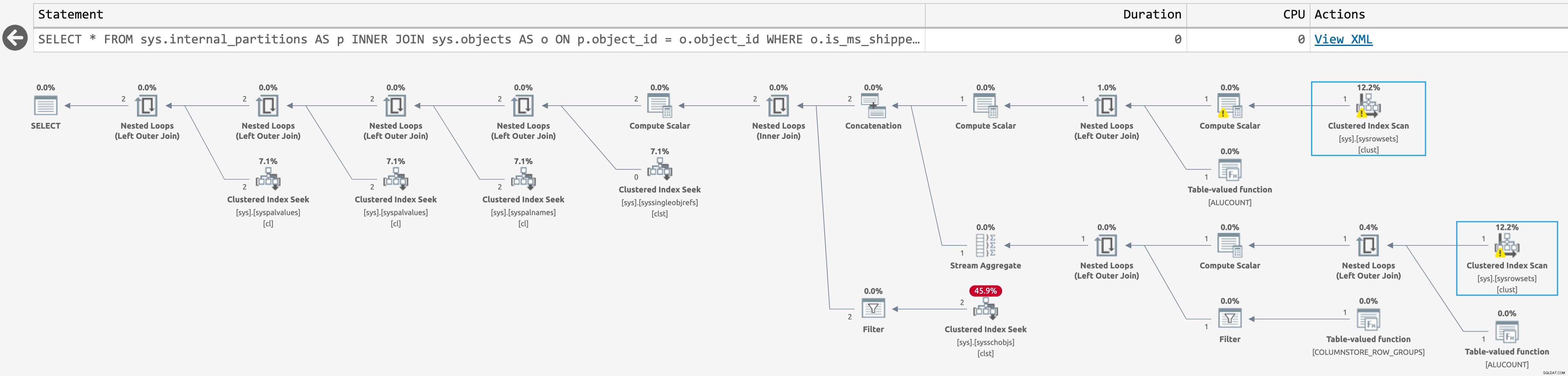 Pianifica per sys.internal_partitions
Pianifica per sys.internal_partitions
Ci sono solo due scansioni su sys.sysrowsets questa volta, ma le scansioni sono comunque irrilevanti perché la query non si avvicina alla produzione delle righe che ci interessano. Vediamo solo righe per oggetti relativi al columnstore (come afferma la documentazione).
sys.system_internals_partitions
Proviamo sys.system_internals_partitions . Sono un po 'diffidente su questo, perché non è supportato (vedi l'avviso qui), ma abbi pazienza un momento:
SELECT * FROM sys.system_internals_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Nel database con gli indici columnstore, viene eseguita una scansione su sys.sysschobjs , ma ora solo uno scansiona contro sys.sysrowsets (clicca per ingrandire):
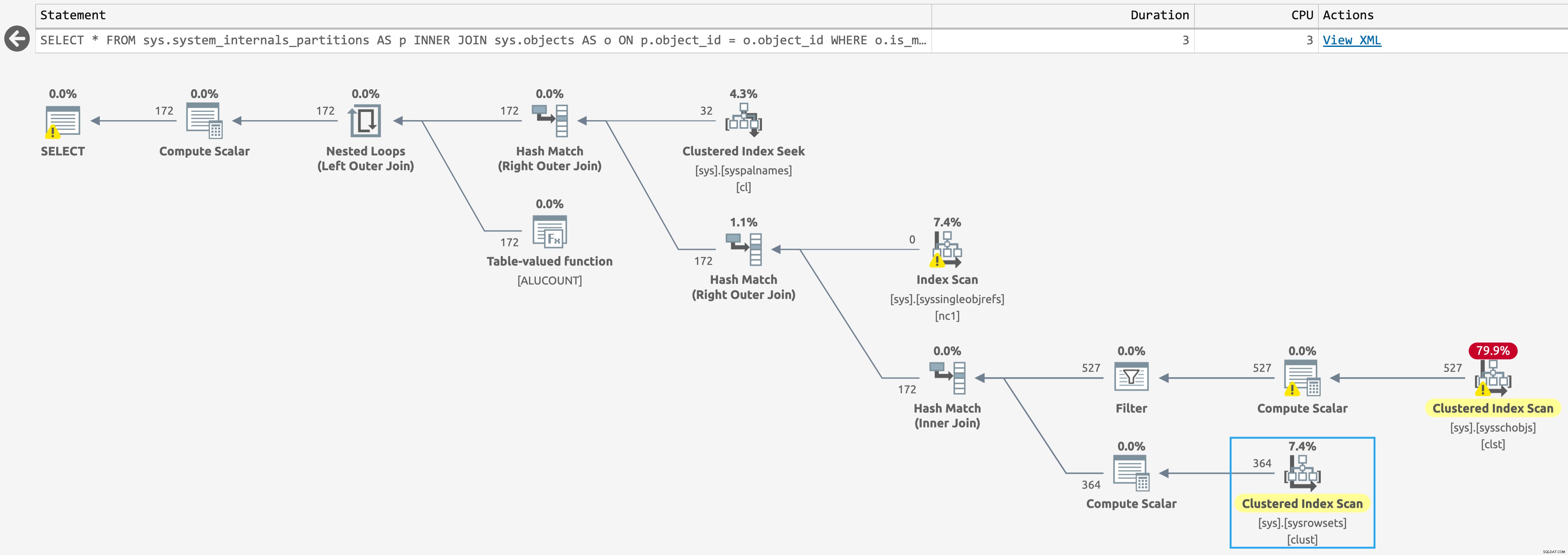 Piano per sys.system_internals_partitions, con indici columnstore presenti
Piano per sys.system_internals_partitions, con indici columnstore presenti
Se eseguiamo la stessa query nel database senza indici columnstore, il piano è ancora più semplice, con una ricerca su sys.sysschobjs (clicca per ingrandire):
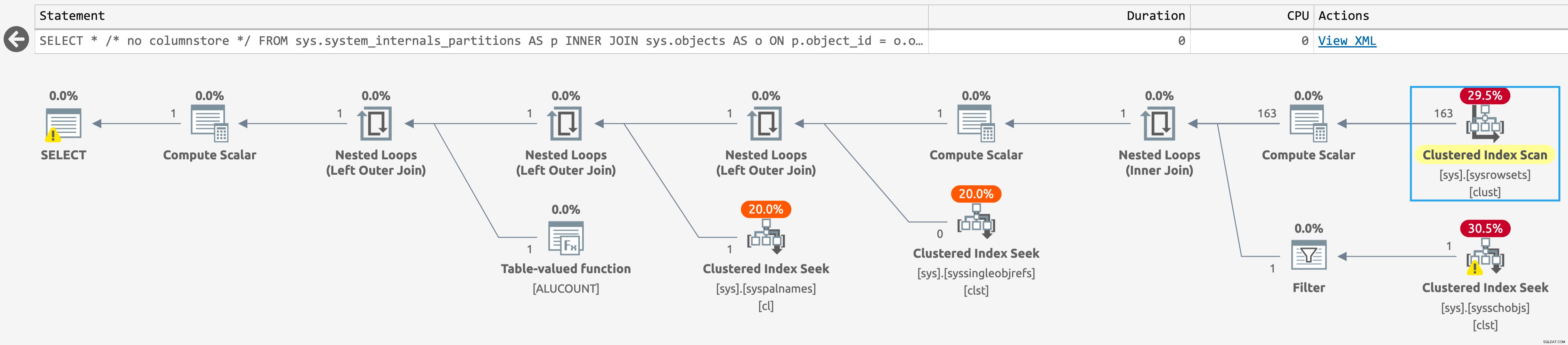 Pianifica per sys.system_internals_partitions, senza indici columnstore presenti
Pianifica per sys.system_internals_partitions, senza indici columnstore presenti
Tuttavia, questo non è del tutto quello che stiamo cercando, o almeno non proprio quello che stava cercando Jake, perché include anche artefatti dagli indici del columnstore. Se aggiungiamo questi filtri, l'output effettivo ora corrisponde alla nostra query precedente, molto più costosa:
SELECT *
FROM sys.system_internals_partitions AS p
INNER JOIN sys.objects AS o ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0
AND p.is_columnstore = 0
AND p.is_orphaned = 0;
Come bonus, la scansione contro sys.sysschobjs è diventata una ricerca anche nel database con oggetti columnstore. La maggior parte di noi non noterà questa differenza, ma se ti trovi in uno scenario come quello di Jake, potresti (fai clic per ingrandire):
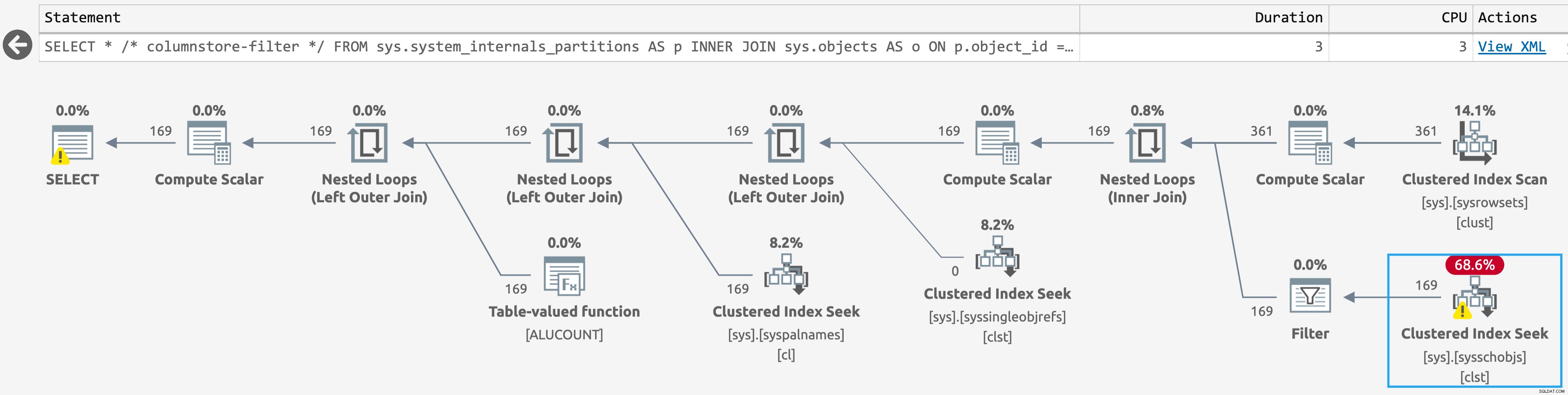 Piano più semplice per sys.system_internals_partitions, con filtri aggiuntivi
Piano più semplice per sys.system_internals_partitions, con filtri aggiuntivi
sys.system_internals_partitions espone un diverso insieme di colonne rispetto a sys.partitions (alcuni sono completamente diversi, altri hanno nuovi nomi) quindi, se stai consumando l'output a valle, dovrai adattarti per quelli. Ti consigliamo inoltre di verificare che restituisca tutte le informazioni desiderate negli indici rowstore, ottimizzati per la memoria e columnstore e non dimenticare quei fastidiosi heap. E, infine, preparati a tralasciare le s in internals molte, molte volte.
Conclusione
Come accennato in precedenza, questa vista di sistema non è ufficialmente supportata, quindi la sua funzionalità potrebbe cambiare in qualsiasi momento; potrebbe anche essere spostato in Dedicated Administrator Connection (DAC) o rimosso del tutto dal prodotto. Sentiti libero di usare questo approccio se sys.partitions non funziona bene per te ma, per favore, assicurati di avere un piano di riserva. E assicurati che sia documentato come un test di regressione quando inizi a testare le versioni future di SQL Server o dopo l'aggiornamento, per ogni evenienza.



