Più di tre anni fa, ho pubblicato una serie in tre parti sulla divisione delle stringhe:
- Dividi le corde nel modo giusto o nel modo migliore successivo
- Dividi le stringhe:un seguito
- Dividi le stringhe:ora con meno T-SQL
Poi, a gennaio, ho affrontato un problema leggermente più elaborato:
- Confronto dei metodi di divisione/concatenazione delle stringhe
Per tutto il tempo, la mia conclusione è stata:STOP A FARE QUESTO IN T-SQL . Usa CLR o, meglio ancora, passa parametri strutturati come DataTables dalla tua applicazione ai parametri con valori di tabella (TVP) nelle tue procedure, evitando del tutto la costruzione e la decostruzione di stringhe, che è davvero la parte della soluzione che causa problemi di prestazioni.
E poi è arrivato SQL Server 2016...
Quando è stato rilasciato RC0, una nuova funzione è stata documentata senza troppi clamori:STRING_SPLIT . Un rapido esempio:
SELECT * FROM STRING_SPLIT('a,b,cd', ',');
/* result:
value
--------
a
b
cd
*/ Ha attirato l'attenzione di alcuni colleghi, tra cui Dave Ballantyne, che ha scritto delle caratteristiche principali, ma è stato così gentile da offrirmi il primo diritto di rifiuto su un confronto delle prestazioni.
Questo è principalmente un esercizio accademico, perché con una serie di limitazioni nella prima iterazione della funzionalità, probabilmente non sarà fattibile per un gran numero di casi d'uso. Ecco l'elenco delle osservazioni che Dave e io abbiamo fatto, alcune delle quali potrebbero essere rompicapo in determinati scenari:
- la funzione richiede che il database sia nel livello di compatibilità 130;
- accetta solo delimitatori di un carattere;
- non c'è modo di aggiungere colonne di output (come una colonna che indica la posizione ordinale all'interno della stringa);
- correlato, non c'è modo di controllare l'ordinamento:le uniche opzioni sono arbitrarie e alfabetiche
ORDER BY value;
- correlato, non c'è modo di controllare l'ordinamento:le uniche opzioni sono arbitrarie e alfabetiche
- finora, stima sempre 50 righe di output;
- quando lo usi per DML, in molti casi otterrai uno spool di tabella (per la protezione di Halloween);
NULLinput porta a un risultato vuoto;- non c'è modo di ridurre i predicati, come eliminare i duplicati o le stringhe vuote a causa di delimitatori consecutivi;
- non c'è modo di eseguire operazioni sui valori di output fino a dopo il fatto (ad esempio, molte funzioni di divisione eseguono
LTRIM/RTRIMo conversioni esplicite per te –STRING_SPLITsputa tutto il brutto, come gli spazi iniziali).
Quindi, con queste limitazioni allo scoperto, possiamo passare ad alcuni test delle prestazioni. Dato il track record di Microsoft con funzioni integrate che sfruttano CLR sotto le coperte (tosse FORMAT() tosse ), ero scettico sul fatto che questa nuova funzione potesse avvicinarsi ai metodi più veloci che avevo testato fino ad oggi.
Usiamo i divisori di stringhe per separare stringhe di numeri separate da virgole, in questo modo anche il nostro nuovo amico JSON può venire e giocare. E diremo che nessun elenco può superare gli 8.000 caratteri, quindi nessun MAX i tipi sono obbligatori e, poiché sono numeri, non abbiamo a che fare con nulla di esotico come Unicode.
Per prima cosa, creiamo le nostre funzioni, molte delle quali ho adattato dal primo articolo sopra. Ho tralasciato una coppia che non pensavo potesse competere; Lascio al lettore il compito di testarli.
Tabella dei numeri
Anche questo ha bisogno di un po' di configurazione, ma può essere un tavolo piuttosto piccolo a causa delle limitazioni artificiali che stiamo ponendo:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 8000;
;WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number); Quindi la funzione:
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT [Value] = SUBSTRING(@List, [Number],
CHARINDEX(@Delimiter, @List + @Delimiter, [Number]) - [Number])
FROM dbo.Numbers WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter
); JSON
Sulla base di un approccio rivelato per la prima volta dal team del motore di archiviazione, ho creato un wrapper simile attorno a OPENJSON , tieni presente che il delimitatore deve essere una virgola in questo caso, oppure devi eseguire una sostituzione di stringhe pesante prima di passare il valore nella funzione nativa:
CREATE FUNCTION dbo.SplitStrings_JSON
(
@List varchar(8000),
@Delimiter char(1) -- ignored but made automated testing easier
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); I CHAR(91)/CHAR(93) stanno semplicemente sostituendo [ e ] rispettivamente a causa di problemi di formattazione.
XML
CREATE FUNCTION dbo.SplitStrings_XML
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(8000)')
FROM (SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)); CLR
Ancora una volta ho preso in prestito il fidato codice di divisione di Adam Machanic di quasi sette anni fa, anche se supporta Unicode, MAX tipi e delimitatori di più caratteri (e in realtà, poiché non voglio pasticciare con il codice della funzione, questo limita le nostre stringhe di input a 4.000 caratteri invece di 8.000):
CREATE FUNCTION dbo.SplitStrings_CLR ( @List nvarchar(MAX), @Delimiter nvarchar(255) ) RETURNS TABLE ( value nvarchar(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
Solo per coerenza, ho inserito un wrapper attorno a STRING_SPLIT :
CREATE FUNCTION dbo.SplitStrings_Native
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM STRING_SPLIT(@List, @Delimiter));
Dati di origine e verifica dell'integrità
Ho creato questa tabella per fungere da origine delle stringhe di input per le funzioni:
CREATE TABLE dbo.SourceTable
(
RowNum int IDENTITY(1,1) PRIMARY KEY,
StringValue varchar(8000)
);
;WITH x AS
(
SELECT TOP (60000) x = STUFF((SELECT TOP (ABS(o.[object_id] % 20))
',' + CONVERT(varchar(12), c.[object_id]) FROM sys.all_columns AS c
WHERE c.[object_id] < o.[object_id] ORDER BY NEWID() FOR XML PATH(''),
TYPE).value(N'(./text())[1]', N'varchar(8000)'),1,1,'')
FROM sys.all_objects AS o CROSS JOIN sys.all_objects AS o2
ORDER BY NEWID()
)
INSERT dbo.SourceTable(StringValue)
SELECT TOP (50000) x
FROM x WHERE x IS NOT NULL
ORDER BY NEWID(); Solo per riferimento, convalidiamo che 50.000 righe siano entrate nella tabella e controlliamo la lunghezza media della stringa e il numero medio di elementi per stringa:
SELECT
[Values] = COUNT(*),
AvgStringLength = AVG(1.0*LEN(StringValue)),
AvgElementCount = AVG(1.0*LEN(StringValue)-LEN(REPLACE(StringValue, ',','')))
FROM dbo.SourceTable;
/* result:
Values AvgStringLength AbgElementCount
------ --------------- ---------------
50000 108.476380 8.911840
*/
Infine, assicuriamoci che ogni funzione restituisca i dati corretti per ogni dato RowNum , quindi ne sceglieremo uno a caso e confronteremo i valori ottenuti con ciascun metodo. I tuoi risultati varieranno ovviamente.
SELECT f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f WHERE s.RowNum = 37219 ORDER BY f.value;
Abbastanza sicuro, tutte le funzioni funzionano come previsto (l'ordinamento non è numerico; ricorda, le funzioni emettono stringhe):
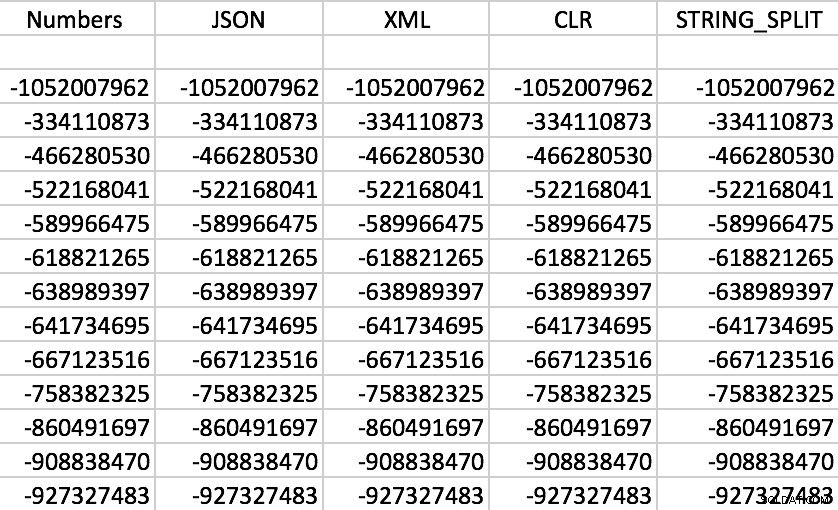 Set di esempio di output da ciascuna delle funzioni
Set di esempio di output da ciascuna delle funzioni
Test delle prestazioni
SELECT SYSDATETIME(); GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue,',') AS f; GO 100 SELECT SYSDATETIME();
Ho eseguito il codice sopra 10 volte per ciascun metodo e ho calcolato la media dei tempi per ciascuno. Ed è qui che è arrivata la sorpresa per me. Date le limitazioni nel STRING_SPLIT nativo funzione, la mia ipotesi era che fosse stato messo insieme rapidamente e che le prestazioni avrebbero dato credito a questo. Boy è stato il risultato diverso da quello che mi aspettavo:
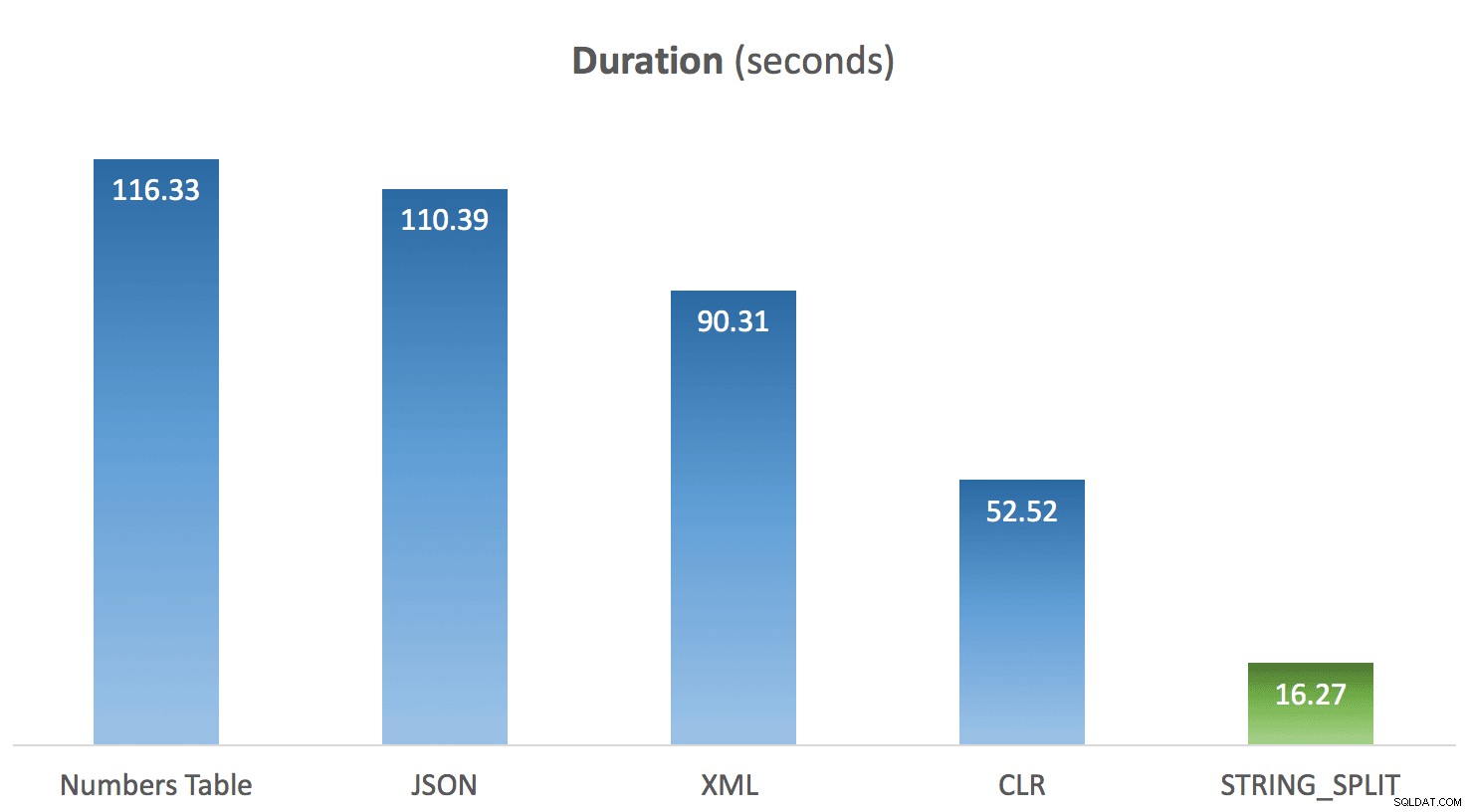 Durata media di STRING_SPLIT rispetto ad altri metodi
Durata media di STRING_SPLIT rispetto ad altri metodi
Aggiornamento 20-03-2016
Sulla base della domanda seguente di Lars, ho eseguito nuovamente i test con alcune modifiche:
- Ho monitorato la mia istanza con SQL Sentry Performance Advisor per acquisire il profilo della CPU durante il test;
- Ho acquisito le statistiche di attesa a livello di sessione tra ogni batch;
- Ho inserito un ritardo tra i batch in modo che l'attività sia visivamente distinta nella dashboard di Performance Advisor.
Ho creato una nuova tabella per acquisire informazioni sulle statistiche di attesa:
CREATE TABLE dbo.Timings ( dt datetime, test varchar(64), point varchar(64), session_id smallint, wait_type nvarchar(60), wait_time_ms bigint, );
Quindi il codice per ogni test è cambiato in questo:
WAITFOR DELAY '00:00:30'; DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = /* 'method' */, point = 'Start', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f GO 100 DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, /* 'method' */, 'End', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
Ho eseguito il test e quindi ho eseguito le seguenti query:
-- validate that timings were in same ballpark as previous tests
SELECT test, DATEDIFF(SECOND, MIN(dt), MAX(dt))
FROM dbo.Timings WITH (NOLOCK)
GROUP BY test ORDER BY 2 DESC;
-- determine window to apply to Performance Advisor dashboard
SELECT MIN(dt), MAX(dt) FROM dbo.Timings;
-- get wait stats registered for each session
SELECT test, wait_type, delta FROM
(
SELECT f.test, rn = RANK() OVER (PARTITION BY f.point ORDER BY f.dt),
f.wait_type, delta = f.wait_time_ms - COALESCE(s.wait_time_ms, 0)
FROM dbo.Timings AS f
LEFT OUTER JOIN dbo.Timings AS s
ON s.test = f.test
AND s.wait_type = f.wait_type
AND s.point = 'Start'
WHERE f.point = 'End'
) AS x
WHERE delta > 0
ORDER BY rn, delta DESC; Dalla prima query, i tempi sono rimasti coerenti con i test precedenti (li classificherei di nuovo ma non rivelerebbero nulla di nuovo).
Dalla seconda query, sono stato in grado di evidenziare questo intervallo nella dashboard di Performance Advisor e da lì è stato facile identificare ogni batch:
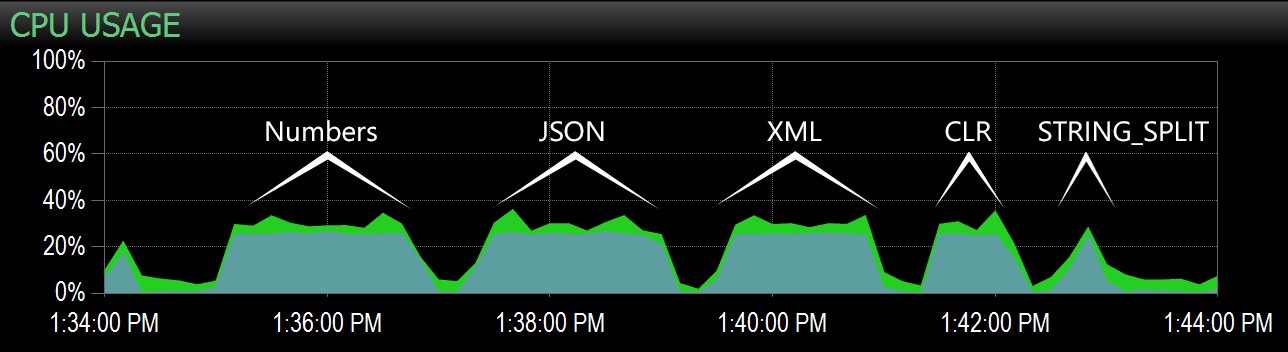 Batch acquisiti nel grafico CPU nella dashboard di Performance Advisor
Batch acquisiti nel grafico CPU nella dashboard di Performance Advisor
Chiaramente, tutti i metodi *tranne* STRING_SPLIT ancorato un singolo core per tutta la durata del test (questa è una macchina quad-core e la CPU era costantemente al 25%). È probabile che Lars stesse insinuando sotto quel STRING_SPLIT è più veloce a costo di martellare la CPU, ma non sembra che sia così.
Infine, dalla terza query, sono stato in grado di vedere le seguenti statistiche di attesa accumulate dopo ogni batch:
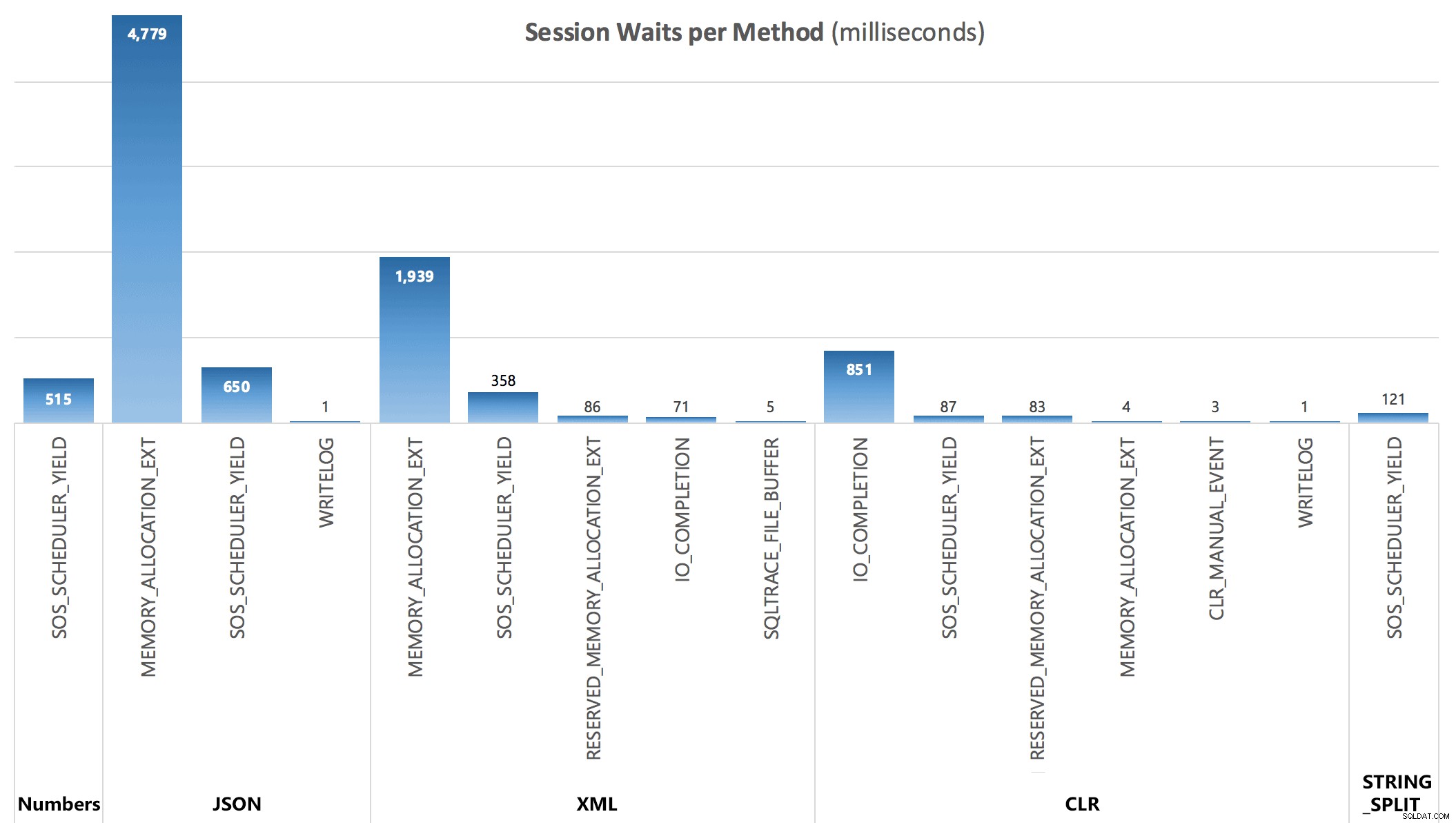 Attese per sessione, in millisecondi
Attese per sessione, in millisecondi
Le attese catturate dal DMV non spiegano completamente la durata delle query, ma servono a mostrare dove aggiuntivo si verificano attese.
Conclusione
Sebbene il CLR personalizzato mostri ancora un enorme vantaggio rispetto ai tradizionali approcci T-SQL e l'utilizzo di JSON per questa funzionalità sembra non essere altro che una novità, STRING_SPLIT è stato il chiaro vincitore - di un miglio. Quindi, se hai solo bisogno di dividere una stringa e puoi gestire tutte le sue limitazioni, sembra che questa sia un'opzione molto più praticabile di quanto mi sarei aspettato. Si spera che nelle build future vedremo funzionalità aggiuntive, come una colonna di output che indica la posizione ordinale di ciascun elemento, la possibilità di filtrare i duplicati e le stringhe vuote e i delimitatori di più caratteri.
Rispondo a più commenti di seguito in due post di follow-up:
- STRING_SPLIT() in SQL Server 2016:follow-up n. 1
- STRING_SPLIT() in SQL Server 2016:follow-up n. 2