Nel mio precedente post di questa serie, ho dimostrato che non tutti gli scenari di query possono trarre vantaggio dalle tecnologie OLTP in memoria. In effetti, l'utilizzo di Hekaton in determinati casi d'uso può effettivamente avere un effetto negativo sulle prestazioni (clicca per ingrandire):

Profilo di monitoraggio delle prestazioni durante l'esecuzione della procedura memorizzata
Tuttavia, in quello scenario avrei potuto impilare il mazzo contro Hekaton, in due modi:
- Il tipo di tabella con ottimizzazione per la memoria che ho creato aveva un numero di bucket di 256, ma stavo passando fino a 2.000 valori da confrontare. In un post sul blog più recente del team di SQL Server, hanno spiegato che sovradimensionare il conteggio del bucket è meglio che sottodimensionarlo, qualcosa che sapevo in generale, ma non mi rendevo conto che avesse anche effetti significativi sulle variabili della tabella:Keep tieni presente che per un indice hash il bucket_count dovrebbe essere circa 1-2 volte il numero di chiavi di indice univoche previste. Di solito è meglio sovradimensionare che sottodimensionare:se a volte inserisci solo 2 valori nelle variabili, ma a volte inserisci fino a 1000 valori, di solito è meglio specificare
BUCKET_COUNT=1000.Non discutono esplicitamente il vero motivo di ciò, e sono sicuro che ci sono molti dettagli tecnici che potremmo approfondire, ma la guida prescrittiva sembra essere troppo grande.
- La chiave primaria era un indice hash su due colonne, mentre il parametro con valori di tabella stava solo tentando di far corrispondere i valori in una di queste colonne. Molto semplicemente, ciò significava che l'indice hash non poteva essere utilizzato. Tony Rogerson lo spiega un po' più in dettaglio in un recente post sul blog:L'hash viene generato in tutte le colonne contenute nell'indice, devi anche specificare tutte le colonne nell'indice hash sulla tua espressione di controllo di uguaglianza, altrimenti l'indice non può essere utilizzato .
Non l'ho mostrato prima, ma nota che il piano rispetto alla tabella ottimizzata per la memoria con l'indice hash a due colonne esegue effettivamente una scansione della tabella anziché la ricerca dell'indice che potresti aspettarti rispetto all'indice hash non cluster (poiché il principale la colonna era
SalesOrderID):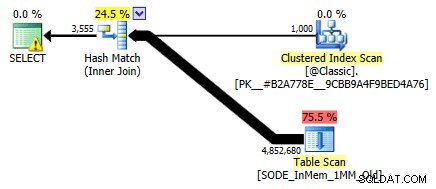
Piano di query che coinvolge una tabella in memoria con due colonne indice hashPer essere più specifici, in un indice hash, la colonna principale non significa una collina di fagioli da sola; l'hash è ancora abbinato in tutte le colonne, quindi non funziona affatto come un tradizionale indice B-tree (con un indice tradizionale, un predicato che coinvolge solo la colonna iniziale potrebbe essere comunque molto utile per eliminare le righe).
Cosa fare?
Bene, in primo luogo, ho creato un indice hash secondario solo su SalesOrderID colonna. Un esempio di una di queste tabelle, con un milione di bucket:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Ricorda che i nostri tipi di tavoli sono impostati in questo modo:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Dopo aver popolato le nuove tabelle con i dati e creato una nuova procedura memorizzata per fare riferimento alle nuove tabelle, il piano che otteniamo mostra correttamente una ricerca dell'indice rispetto all'indice hash a colonna singola:

Piano migliorato utilizzando l'indice hash a colonna singola
Ma cosa significherebbe davvero per le prestazioni? Ho eseguito di nuovo lo stesso set di test:query su questa tabella con conteggi di bucket di 16.000, 131.000 e 1 MM; utilizzando sia TVP classici che in memoria con 100, 1.000 e 2.000 valori; e nel caso TVP in memoria, utilizzando sia una stored procedure tradizionale che una stored procedure compilata in modo nativo. Ecco come sono andate le prestazioni per 10.000 iterazioni per combinazione:

Profilo di prestazioni per 10.000 iterazioni rispetto a un indice hash a colonna singola, utilizzando un TVP a 256 bucket
Potresti pensare, ehi, che il profilo delle prestazioni non sia così eccezionale; al contrario, è molto meglio del mio precedente test del mese scorso. Dimostra semplicemente che il numero di bucket per la tabella può avere un enorme impatto sulla capacità di SQL Server di utilizzare in modo efficace l'indice hash. In questo caso, l'utilizzo di un conteggio di bucket di 16.000 chiaramente non è ottimale per nessuno di questi casi e peggiora esponenzialmente all'aumentare del numero di valori nel TVP.
Ora, ricorda, il numero di secchi del TVP era 256. Quindi cosa accadrebbe se lo aumentassi, secondo le indicazioni di Microsoft? Ho creato un secondo tipo di tabella con una dimensione del bucket più appropriata. Dato che stavo testando 100, 1.000 e 2.000 valori, ho usato la potenza successiva di 2 per il conteggio del secchio (2.048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Ho creato procedure di supporto per questo ed ho eseguito di nuovo la stessa batteria di test. Ecco i profili delle prestazioni affiancati:

Confronto del profilo delle prestazioni con TVP a 256 e 2.048 bucket
La modifica del conteggio dei bucket per il tipo di tabella non ha avuto l'impatto che mi sarei aspettato, data la dichiarazione di Microsoft sul dimensionamento. In realtà non ha avuto un gran effetto positivo; infatti per alcuni scenari era un po' peggio. Ma nel complesso i profili delle prestazioni sono, a tutti gli effetti, gli stessi.
Ciò che ha avuto un enorme effetto, tuttavia, è stata la creazione dell'indice hash *right* per supportare il modello di query. Sono stato grato di essere stato in grado di dimostrare che, nonostante i miei precedenti test indicassero il contrario, un tavolo in memoria e un TVP in memoria potevano battere il metodo della vecchia scuola per ottenere la stessa cosa. Prendiamo solo il caso più estremo del mio esempio precedente, quando la tabella aveva solo un indice hash a due colonne:

Profilo di prestazioni per 10 iterazioni rispetto a un indice hash a due colonne
La barra più a destra mostra la durata di sole 10 iterazioni della stored procedure nativa che corrispondono a un indice hash non appropriato:tempi di query che vanno da 735 a 1.601 millisecondi. Ora, tuttavia, con l'indice hash corretto, le stesse query vengono eseguite in un intervallo molto più piccolo, da 0,076 millisecondi a 51,55 millisecondi. Se tralasciamo il caso peggiore (16.000 bucket conteggiati), la discrepanza è ancora più pronunciata. In tutti i casi, questo è almeno due volte più efficiente (almeno in termini di durata) di entrambi i metodi, senza una procedura memorizzata ingenuamente compilata, rispetto alla stessa tabella ottimizzata per la memoria; e centinaia di volte meglio di qualsiasi approccio rispetto alla nostra vecchia tabella ottimizzata per la memoria con l'unico indice hash a due colonne.
Conclusione
Spero di aver dimostrato che occorre prestare molta attenzione quando si implementano tabelle ottimizzate per la memoria di qualsiasi tipo e che in molti casi, l'utilizzo di un TVP ottimizzato per la memoria da solo potrebbe non produrre il massimo guadagno in termini di prestazioni. Ti consigliamo di prendere in considerazione l'utilizzo di stored procedure compilate in modo nativo per ottenere il massimo dai tuoi soldi e, per scalare al meglio, vorrai davvero prestare attenzione al conteggio dei bucket per gli indici hash nelle tue tabelle ottimizzate per la memoria (ma forse no tanta attenzione ai tipi di tabella ottimizzati per la memoria).
Per ulteriori letture sulla tecnologia OLTP in memoria in generale, puoi consultare queste risorse:
- Il blog del team di SQL Server (Tag:Hekaton e Tag:In-Memory OLTP – i nomi in codice non sono divertenti?)
- Blog di Bob Beauchemin
- Blog di Klaus Aschenbrenner