Read committed è il secondo più debole dei quattro livelli di isolamento definiti dallo standard SQL. Tuttavia, è il livello di isolamento predefinito per molti motori di database, incluso SQL Server. Questo post in una serie sui livelli di isolamento e le proprietà ACID delle transazioni esamina le garanzie logiche e fisiche effettivamente fornite dall'isolamento read committed.
Garanzie logiche
Lo standard SQL richiede che una transazione in esecuzione in isolamento di lettura commit legga solo committed dati. Esprime questa esigenza vietando il fenomeno della concorrenza noto come lettura sporca. Una lettura sporca si verifica quando una transazione legge i dati che sono stati scritti da un'altra transazione, prima che la seconda transazione venga completata. Un altro modo per esprimere questo è dire che si verifica una lettura sporca quando una transazione legge dati non vincolati.
Lo standard menziona anche che una transazione eseguita con isolamento di lettura commit potrebbe incontrare i fenomeni di concorrenza noti come letture non ripetibili e fantasmi . Sebbene molti libri spieghino questi fenomeni in termini di una transazione in grado di vedere elementi di dati modificati o nuovi se i dati vengono successivamente riletti, questa spiegazione può rafforzare l'idea sbagliata che i fenomeni di concorrenza possono verificarsi solo all'interno di una transazione esplicita che contiene più istruzioni. Non è così. Una unica dichiarazione senza una transazione esplicita è altrettanto vulnerabile ai fenomeni di read e phantom non ripetibili, come vedremo tra poco.
Questo è praticamente tutto ciò che lo standard ha da dire sull'argomento dell'isolamento in lettura commessa. A prima vista, leggere solo i dati impegnati sembra una buona garanzia di comportamento sensato, ma come sempre il diavolo è nei dettagli. Non appena inizi a cercare potenziali scappatoie in questa definizione, diventa fin troppo facile trovare casi in cui le nostre transazioni commesse in lettura potrebbero non produrre i risultati che potremmo aspettarci. Di nuovo, ne discuteremo più in dettaglio tra un momento o due.
Diverse implementazioni fisiche
Ci sono almeno due cose che indicano che il comportamento osservato del livello di isolamento di lettura commit potrebbe essere molto diverso su motori di database diversi. In primo luogo, il requisito standard SQL di leggere solo i dati vincolati non significa necessariamente che i dati confermati letti da una transazione saranno i più recenti dati impegnati.
Un motore di database può leggere una versione confermata di una riga da qualsiasi punto nel passato , e sono comunque conformi alla definizione standard SQL. Diversi prodotti di database popolari implementano in questo modo l'isolamento con commit di lettura. I risultati delle query ottenuti nell'ambito di questa implementazione dell'isolamento con commit di lettura potrebbero essere arbitrariamente non aggiornati , se confrontato con lo stato di commit corrente del database. Tratteremo questo argomento in quanto si applica a SQL Server nel prossimo post della serie.
La seconda cosa su cui voglio attirare la vostra attenzione è che la definizione standard SQL non impedire a una particolare implementazione di fornire ulteriori protezioni per gli effetti di concorrenza oltre a prevenire letture sporche . Lo standard specifica solo che non sono consentite letture sporche, non richiede che altri fenomeni di concorrenza debbano essere consentiti a un dato livello di isolamento.
Per essere chiari su questo secondo punto, un motore di database conforme agli standard potrebbe implementare tutti i livelli di isolamento utilizzando serializzabile comportamento se così ha scelto. Alcuni dei principali motori di database commerciali forniscono anche un'implementazione di read commit che va ben oltre la semplice prevenzione di letture sporche (sebbene nessuno arrivi fino a fornire un isolamento completo nell'ACID senso della parola).
In aggiunta a ciò, per diversi prodotti popolari, leggi impegnati l'isolamento è il più basso livello di isolamento disponibile; le loro implementazioni di read uncommitted isolamento sono esattamente gli stessi di read commit. Ciò è consentito dallo standard, ma questo tipo di differenze aggiunge complessità al già difficile compito di migrare il codice da una piattaforma all'altra. Quando si parla dei comportamenti di un livello di isolamento, di solito è importante specificare anche la particolare piattaforma.
Per quanto ne so, SQL Server è l'unico tra i principali motori di database commerciali nel fornire due implementazioni del livello di isolamento read committed, ciascuna con comportamenti fisici molto diversi. Questo post copre il primo di questi, blocco letto impegnato.
Lettura con blocco SQL Server impegnata
Se l'opzione del database READ_COMMITTED_SNAPSHOT è OFF , SQL Server utilizza un blocco implementazione del livello di isolamento in lettura commit, in cui vengono presi i blocchi condivisi per impedire che una transazione simultanea modifichi i dati contemporaneamente, perché la modifica richiederebbe un blocco esclusivo, che non è compatibile con il blocco condiviso.
La differenza fondamentale tra il blocco della lettura con commit di SQL Server e il blocco della lettura ripetibile (che accetta anche i blocchi condivisi durante la lettura dei dati) è che la lettura con commit rilascia il blocco condiviso il prima possibile , mentre la lettura ripetibile mantiene questi blocchi fino alla fine della transazione di inclusione.
Quando il blocco della lettura con commit acquisisce blocchi alla granularità della riga, il blocco condiviso acquisito su una riga viene rilasciato quando viene acquisito un blocco condiviso nella riga successiva . Alla granularità della pagina, il blocco della pagina condivisa viene rilasciato quando viene letta la prima riga nella pagina successiva e così via. A meno che non venga fornito un suggerimento di granularità di blocco con la query, il motore di database decide con quale livello di granularità iniziare. Si noti che i suggerimenti di granularità vengono trattati solo come suggerimenti dal motore, è possibile che inizialmente venga comunque utilizzato un blocco meno granulare di quello richiesto. I blocchi potrebbero anche essere aumentati durante l'esecuzione dal livello di riga o pagina a livello di partizione o tabella a seconda della configurazione del sistema.
Il punto importante qui è che i blocchi condivisi vengono generalmente mantenuti solo per un tempo molto breve mentre l'istruzione è in esecuzione. Per affrontare in modo esplicito un malinteso comune, il blocco della lettura con commit non mantieni i blocchi condivisi fino alla fine dell'istruzione.
Blocco dei comportamenti di lettura vincolati
I blocchi condivisi a breve termine utilizzati dall'implementazione di lettura commit del blocco di SQL Server forniscono pochissime delle garanzie comunemente previste per una transazione di database dai programmatori T-SQL. In particolare, un'istruzione eseguita con il blocco read commit isolamento:
- Può incontrare la stessa riga più volte;
- Può mancare completamente alcune righe; e
- Non non fornire una visualizzazione puntuale dei dati
Quell'elenco potrebbe sembrare più una descrizione dei comportamenti strani che potresti associare di più all'uso di NOLOCK suggerimenti, ma tutte queste cose possono davvero accadere e accadono quando si utilizza l'isolamento con commit di lettura del blocco.
Esempio
Considera il semplice compito di contare le righe in una tabella, usando l'ovvia query a istruzione singola. Con il blocco dell'isolamento in lettura confermata con granularità del blocco delle righe, la nostra query prenderà un blocco condiviso sulla prima riga, lo leggerà, rilascerà il blocco condiviso, passerà alla riga successiva e così via fino a raggiungere la fine della struttura. sta leggendo. Per il bene di questo esempio, supponiamo che la nostra query stia leggendo un b-tree dell'indice in ordine di chiave crescente (sebbene potrebbe anche utilizzare un ordine decrescente o qualsiasi altra strategia).
Poiché solo una singola riga è bloccato dalla condivisione in un dato momento, è chiaramente possibile che le transazioni simultanee modifichino le righe sbloccate nell'indice che la nostra query sta attraversando. Se queste modifiche simultanee cambiano i valori della chiave dell'indice, le righe si sposteranno all'interno della struttura dell'indice. Tenendo presente questa possibilità, il diagramma seguente illustra due scenari problematici che possono verificarsi:
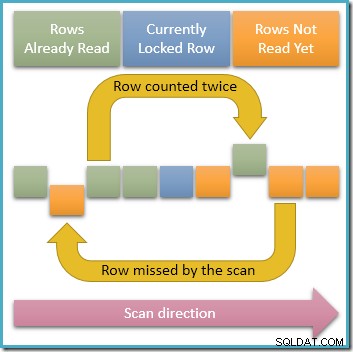
La freccia in alto mostra una riga che abbiamo già contato con la sua chiave di indice modificata contemporaneamente in modo che la riga si sposti davanti alla posizione di scansione corrente nell'indice, il che significa che la riga verrà contata due volte . La seconda freccia mostra una riga che la nostra scansione non ha ancora incontrato e si sposta dietro la posizione di scansione, il che significa che la riga non verrà conteggiata affatto.
Non una vista temporale
La sezione precedente ha mostrato come il blocco della lettura con commit può perdere completamente i dati o contare lo stesso elemento più volte (più di due volte, se siamo sfortunati). Il terzo punto elenco nell'elenco dei comportamenti imprevisti affermava che il blocco della lettura confermata non fornisce nemmeno una vista puntuale dei dati.
Il ragionamento alla base di tale affermazione dovrebbe ora essere facile da vedere. La nostra query di conteggio, ad esempio, potrebbe leggere facilmente i dati inseriti da transazioni simultanee dopo che la nostra query ha iniziato l'esecuzione. Allo stesso modo, i dati che la nostra query vede potrebbero essere modificati da attività simultanee dopo l'avvio della nostra query e prima del suo completamento. Infine, i dati che abbiamo letto e conteggiato potrebbero essere eliminati da una transazione simultanea prima del completamento della nostra query.
Chiaramente, i dati visualizzati da un'istruzione o una transazione in esecuzione con isolamento in lettura con blocco non corrispondono a nessuno stato del database in un particolare punto temporale . I dati che incontriamo potrebbero benissimo provenire da una varietà di momenti diversi, con l'unico fattore comune che ogni elemento rappresentava l'ultimo valore impegnato di quei dati al momento in cui sono stati letti (anche se potrebbe essere cambiato o scomparso da allora).
Quanto sono gravi questi problemi?
Tutto ciò potrebbe sembrare uno stato di cose piuttosto lanoso se sei abituato a pensare alle tue query a istruzione singola e alle transazioni esplicite come eseguite logicamente istantaneamente o come in esecuzione su un singolo stato point-in-time impegnato del database quando si utilizza il livello di isolamento predefinito di SQL Server. Certamente non si adatta bene al concetto di isolamento in senso ACIDO.
Data l'apparente debolezza delle garanzie fornite dal blocco dell'isolamento read commit, potresti iniziare a chiederti come qualsiasi del tuo codice T-SQL di produzione ha mai funzionato correttamente! Naturalmente, possiamo accettare che l'utilizzo di un livello di isolamento inferiore al serializzabile significhi rinunciare al completo isolamento delle transazioni ACID in cambio di altri potenziali vantaggi, ma quanto possiamo aspettarci seri questi problemi nella pratica?
Righe mancanti e conteggiate due volte
Questi primi due problemi si basano essenzialmente sull'attività simultanea che modifica le chiavi in una struttura di indice che stiamo attualmente scansionando. Tieni presente che scansione qui include la porzione di scansione dell'intervallo parziale di un indice ricerca , così come la familiare scansione senza restrizioni dell'indice o della tabella.
Se stiamo (range) scansionando una struttura di indice le cui chiavi non sono in genere modificate da alcuna attività simultanea, questi primi due problemi non dovrebbero essere un gran problema pratico. Tuttavia, è difficile esserne certi, perché i piani di query possono cambiare per utilizzare un metodo di accesso diverso e il nuovo indice cercato potrebbe incorporare chiavi volatili.
Dobbiamo anche tenere a mente che molte query di produzione richiedono solo un approssimativo o comunque la risposta migliore ad alcuni tipi di domande. Il fatto che alcune righe siano mancanti o contate due volte potrebbe non avere molta importanza nello schema più ampio delle cose. Su un sistema con molte modifiche simultanee, potrebbe anche essere difficile essere sicuri che il risultato era impreciso, dato che i dati cambiano così frequentemente. In questo tipo di situazione, una risposta approssimativamente corretta potrebbe essere sufficiente per gli scopi del consumatore di dati.
Nessuna vista temporale
Anche la terza questione (quella di una cosiddetta 'coerente' visione puntuale dei dati) si riduce allo stesso tipo di considerazioni. A fini di reporting, laddove le incoerenze tendono a generare domande imbarazzanti da parte dei consumatori di dati, è spesso preferibile una vista istantanea. In altri casi, il tipo di incoerenza derivante dalla mancanza di una visione puntuale dei dati può essere tollerabile.
Scenari problematici
Ci sono anche molti casi in cui i problemi elencati saranno essere importante. Ad esempio, se scrivi codice che applica regole aziendali in T-SQL bisogna fare attenzione a selezionare un livello di isolamento (o intraprendere altre azioni idonee) per garantire la correttezza. Molte regole aziendali possono essere applicate utilizzando chiavi esterne o vincoli, in cui le complessità della selezione del livello di isolamento vengono gestite automaticamente dal motore di database. Come regola generale, utilizzare il set integrato di integrità dichiarativa caratteristiche è preferibile alla creazione di regole personalizzate in T-SQL.
Esiste un'altra ampia classe di query che non applica una regola aziendale di per sé , ma che tuttavia potrebbe avere conseguenze spiacevoli se eseguito al livello di isolamento di lettura commit di blocco predefinito. Questi scenari non sono sempre così ovvi come gli esempi spesso citati di trasferire denaro tra conti bancari o garantire che il saldo su un numero di conti collegati non scenda mai sotto lo zero. Ad esempio, considera la seguente query che identifica le fatture scadute come input per un processo che invia lettere di sollecito con parole severe:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Chiaramente non vorremmo inviare una lettera a qualcuno che aveva interamente pagato la fattura a rate, semplicemente perché l'attività simultanea del database nel momento in cui è stata eseguita la nostra query significava che abbiamo calcolato una somma errata dei pagamenti ricevuti. Le query reali su sistemi di produzione reali sono spesso molto più complesse del semplice esempio sopra, ovviamente.
Per concludere la giornata di oggi, dai un'occhiata alla query seguente e verifica se riesci a individuare quante opportunità ci sono che si verifichi qualcosa di non intenzionale, se diverse di queste query vengono eseguite contemporaneamente al livello di isolamento con blocco della lettura (forse mentre altre transazioni non correlate stanno anche modificando la tabella Casi):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Una volta che inizi a cercare tutti i piccoli modi in cui una query può andare storta a questo livello di isolamento, può essere difficile fermarsi. Tieni a mente gli avvertimenti osservati in precedenza sulla reale necessità di risultati accurati completamente isolati e puntuali. Va benissimo avere query che restituiscano risultati sufficientemente buoni, a patto che tu sia consapevole dei compromessi che stai facendo usando read commit.
La prossima volta
La parte successiva di questa serie esamina la seconda implementazione fisica dell'isolamento con commit di lettura disponibile in SQL Server, l'isolamento di snapshot con commit di lettura.
[Vedi l'indice per l'intera serie]