Quasi un anno fa ho pubblicato la mia soluzione per l'impaginazione in SQL Server, che prevedeva l'utilizzo di un CTE per individuare solo i valori chiave per l'insieme di righe in questione, e quindi il collegamento dal CTE alla tabella di origine per recuperare le altre colonne solo per quella "pagina" di righe. Ciò si è rivelato particolarmente vantaggioso quando c'era un indice ristretto che supportava l'ordinamento richiesto dall'utente, o quando l'ordinamento era basato sulla chiave di clustering, ma funzionava anche un po' meglio senza un indice per supportare l'ordinamento richiesto.
Da allora, mi sono chiesto se gli indici ColumnStore (sia cluster che non cluster) potessero aiutare uno di questi scenari. TL;DR :Basandosi su questo esperimento isolato, la risposta al titolo di questo post è un sonoro NO . Se non vuoi vedere l'impostazione del test, il codice, i piani di esecuzione o i grafici, non esitare a passare al mio riepilogo, tenendo presente che la mia analisi si basa su un caso d'uso molto specifico.
Configurazione
In una nuova macchina virtuale con SQL Server 2016 CTP 3.2 (13.0.900.73) installato, ho eseguito più o meno la stessa configurazione di prima, solo questa volta con tre tabelle. Innanzitutto, una tabella tradizionale con una chiave di clustering stretta e più indici di supporto:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Successivamente, una tabella con un indice ColumnStore cluster:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
E infine, una tabella con un indice ColumnStore non in cluster che copre tutte le colonne:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Si noti che per entrambe le tabelle con indici ColumnStore, ho omesso l'indice che supporterebbe ricerche più rapide nell'ordinamento "Rubrica" (cognome, nome).
Dati di prova
Ho quindi popolato la prima tabella con 1.000.000 di righe casuali, sulla base di uno script che ho riutilizzato nei post precedenti:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Quindi ho usato quella tabella per popolare le altre due esattamente con gli stessi dati e ho ricostruito tutti gli indici:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
La dimensione totale di ogni tabella:
| Tabella | Riservato | Dati | Indice |
|---|---|---|---|
| Clienti | 463.200 KB | 154.344 KB | 308.576 KB |
| Clienti_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Clienti_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
E il conteggio delle righe/delle pagine degli indici rilevanti (l'indice univoco sull'e-mail era più che altro per me per fare da babysitter al mio script di generazione dei dati):
| Tabella | Indice | Righe | Pagine |
|---|---|---|---|
| Clienti | PK_Clienti | 1.000.000 | 19.377 |
| Clienti | Rubrica_Clienti | 1.000.000 | 17.209 |
| Clienti | Clienti_Attivi | 808.012 | 13.977 |
| Clienti_CCI | PK_CustomersCCI | 1.000.000 | 2.737 |
| Clienti_CCI | Clienti_CCI | 1.000.000 | 3.826 |
| Clienti_NCCI | PK_CustomersNCCI | 1.000.000 | 19.377 |
| Clienti_NCCI | Clienti_NCCI | 1.000.000 | 16.971 |
Procedure
Quindi, per vedere se gli indici ColumnStore sarebbero entrati in picchiata e avrebbero migliorato uno qualsiasi degli scenari, ho eseguito lo stesso set di query di prima, ma ora su tutte e tre le tabelle. Sono diventato almeno un po' più intelligente e ho creato due stored procedure con SQL dinamico per accettare l'origine della tabella e l'ordinamento. (Sono ben consapevole dell'iniezione di SQL; questo non è quello che farei in produzione se queste stringhe provenissero da un utente finale, quindi per favore non prenderlo come una raccomandazione per farlo. Mi fido abbastanza di me stesso nel mio ambiente chiuso che non è un problema per questi test.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Quindi ho creato un SQL più dinamico per generare tutte le combinazioni di chiamate che avrei dovuto effettuare per chiamare sia la vecchia che la nuova stored procedure, in tutti e tre gli ordini di ordinamento desiderati e a diversi numeri di pagina (per simulare la necessità una pagina vicino all'inizio, al centro e alla fine dell'ordinamento). In modo da poter copiare PRINT output e incollarlo in SQL Sentry Plan Explorer per ottenere le metriche di runtime, ho eseguito questo batch due volte, una volta con le procedures CTE utilizzando P_Old , e poi ancora usando P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Questo ha prodotto un output in questo modo (36 chiamate in tutto per il vecchio metodo (P_Old ) e 36 chiama il nuovo metodo (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Lo so, è tutto molto ingombrante; arriveremo presto alla battuta finale, lo prometto.
Risultati
Ho preso quei due set di 36 istruzioni e ho avviato due nuove sessioni in Plan Explorer, eseguendo ogni set più volte per assicurarmi di ottenere i dati da una cache calda e prendere le medie (potrei confrontare anche la cache fredda e calda, ma penso che ci siano abbastanza variabili qui).
Posso dirti subito un paio di semplici fatti senza nemmeno mostrarti grafici o piani di supporto:
- In nessun caso il "vecchio" metodo ha battuto il nuovo metodo CTE Ho promosso nel mio post precedente, indipendentemente dal tipo di indici presenti. In questo modo è facile ignorare virtualmente la metà dei risultati, almeno in termini di durata (che è la metrica a cui gli utenti finali si preoccupano di più).
- Nessun indice ColumnStore è andato bene durante il paging verso la fine del risultato – hanno fornito benefici solo all'inizio e solo in un paio di casi.
- Quando si ordina in base alla chiave primaria (clustered o no), la presenza degli indici ColumnStore non ha aiutato – ancora, in termini di durata.
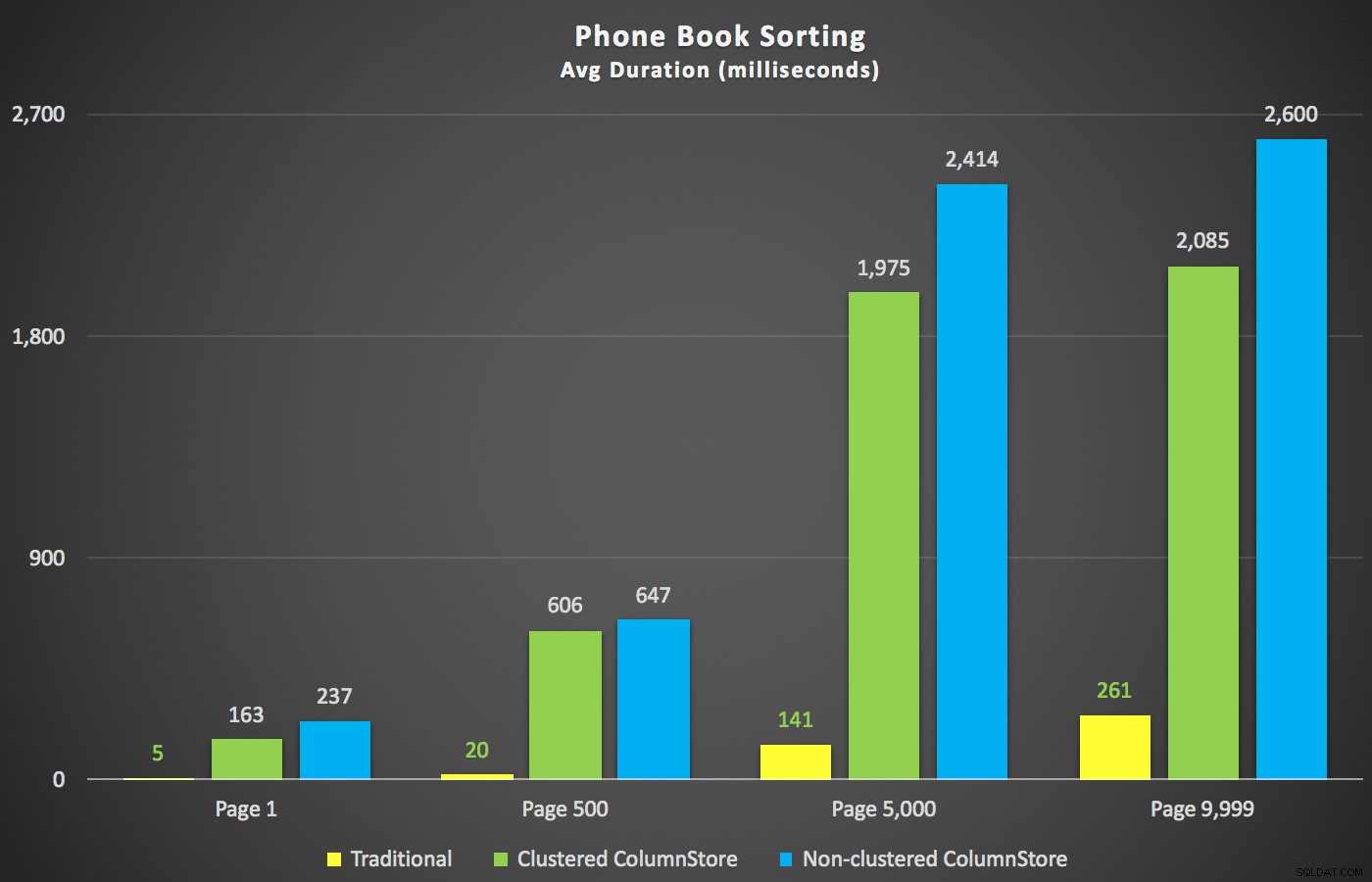
Con quei riepiloghi fuori mano, diamo un'occhiata ad alcune sezioni trasversali dei dati sulla durata. In primo luogo, i risultati della query ordinati per nome decrescente, quindi e-mail, senza alcuna speranza di utilizzare un indice esistente per l'ordinamento. Come puoi vedere nel grafico, le prestazioni sono state incoerenti:a numeri di pagina inferiori, ColumnStore non in cluster ha ottenuto risultati migliori; a numeri di pagina più alti vinceva sempre l'indice tradizionale:
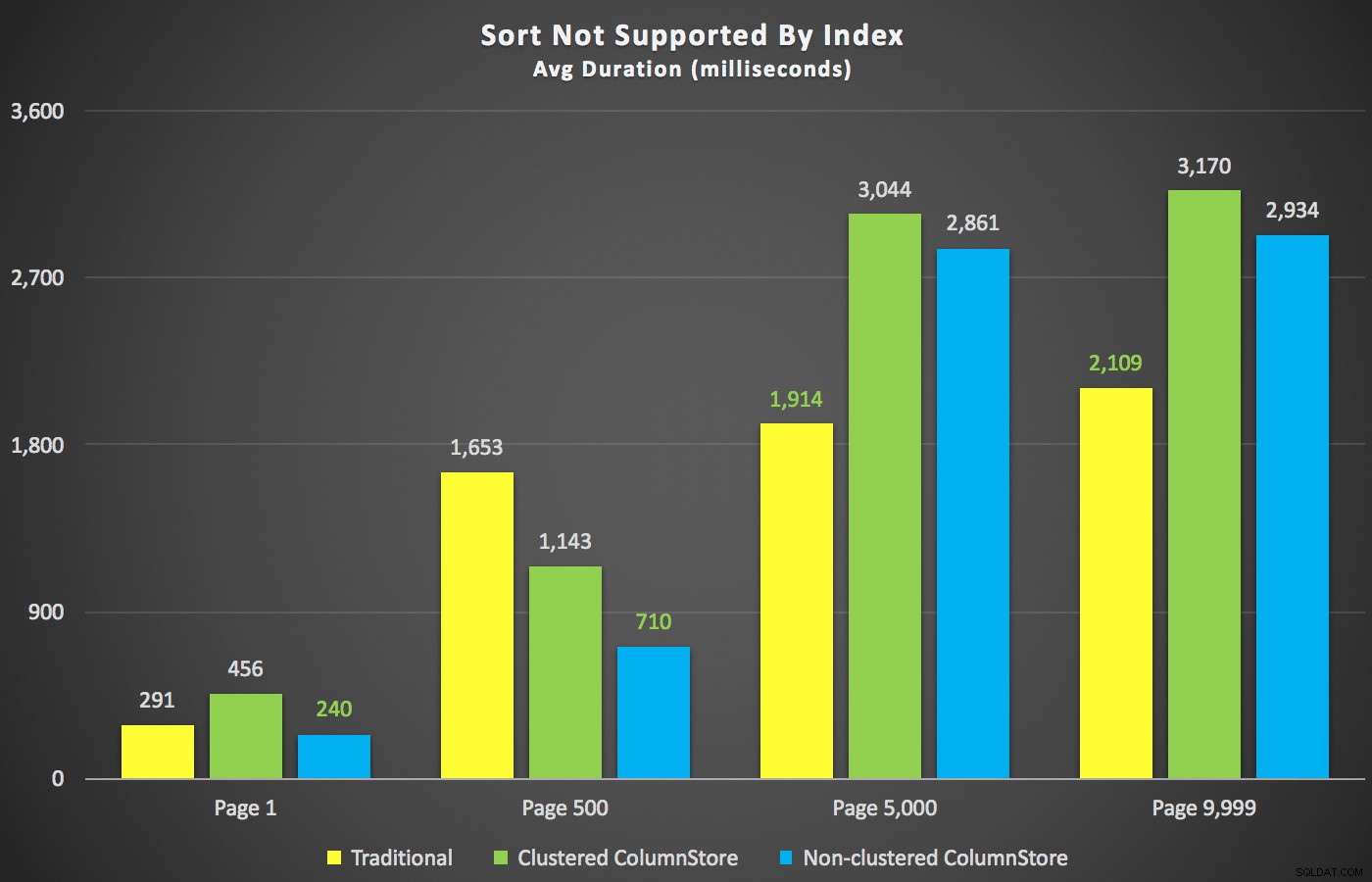 Durata (millisecondi) per diversi numeri di pagina e diversi tipi di indice
Durata (millisecondi) per diversi numeri di pagina e diversi tipi di indice
E poi i tre piani che rappresentano i tre diversi tipi di indici (con la scala di grigi aggiunta da Photoshop per evidenziare le maggiori differenze tra i piani):
 Piano per l'indice tradizionale
Piano per l'indice tradizionale
 Piano per l'indice ColumnStore in cluster
Piano per l'indice ColumnStore in cluster
 Piano per l'indice ColumnStore non in cluster
Piano per l'indice ColumnStore non in cluster
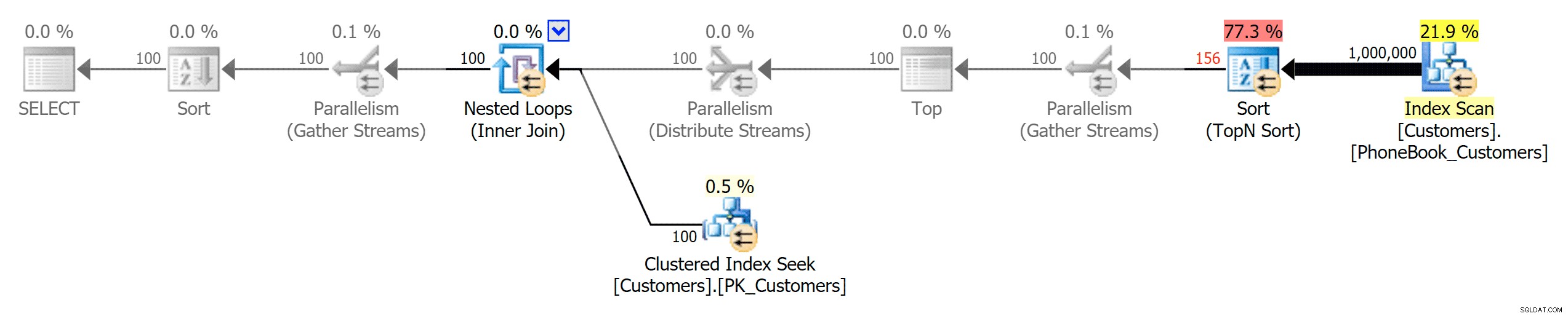
Uno scenario che mi interessava di più, anche prima di iniziare i test, era l'approccio di ordinamento della rubrica (cognome, nome). In questo caso gli indici ColumnStore erano in realtà piuttosto dannosi per la performance del risultato:
I piani ColumnStore qui sono quasi immagini speculari rispetto ai due piani ColumnStore mostrati sopra per l'ordinamento non supportato. Il motivo è lo stesso in entrambi i casi:scansioni o ordinamenti costosi dovuti alla mancanza di un indice di supporto dell'ordinamento.
Quindi, successivamente, ho creato indici "PhoneBook" di supporto anche sulle tabelle con gli indici ColumnStore, per vedere se potevo convincere un piano diverso e/o tempi di esecuzione più rapidi in uno di questi scenari. Ho creato questi due indici, quindi ricostruito di nuovo:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Ecco le nuove durate:
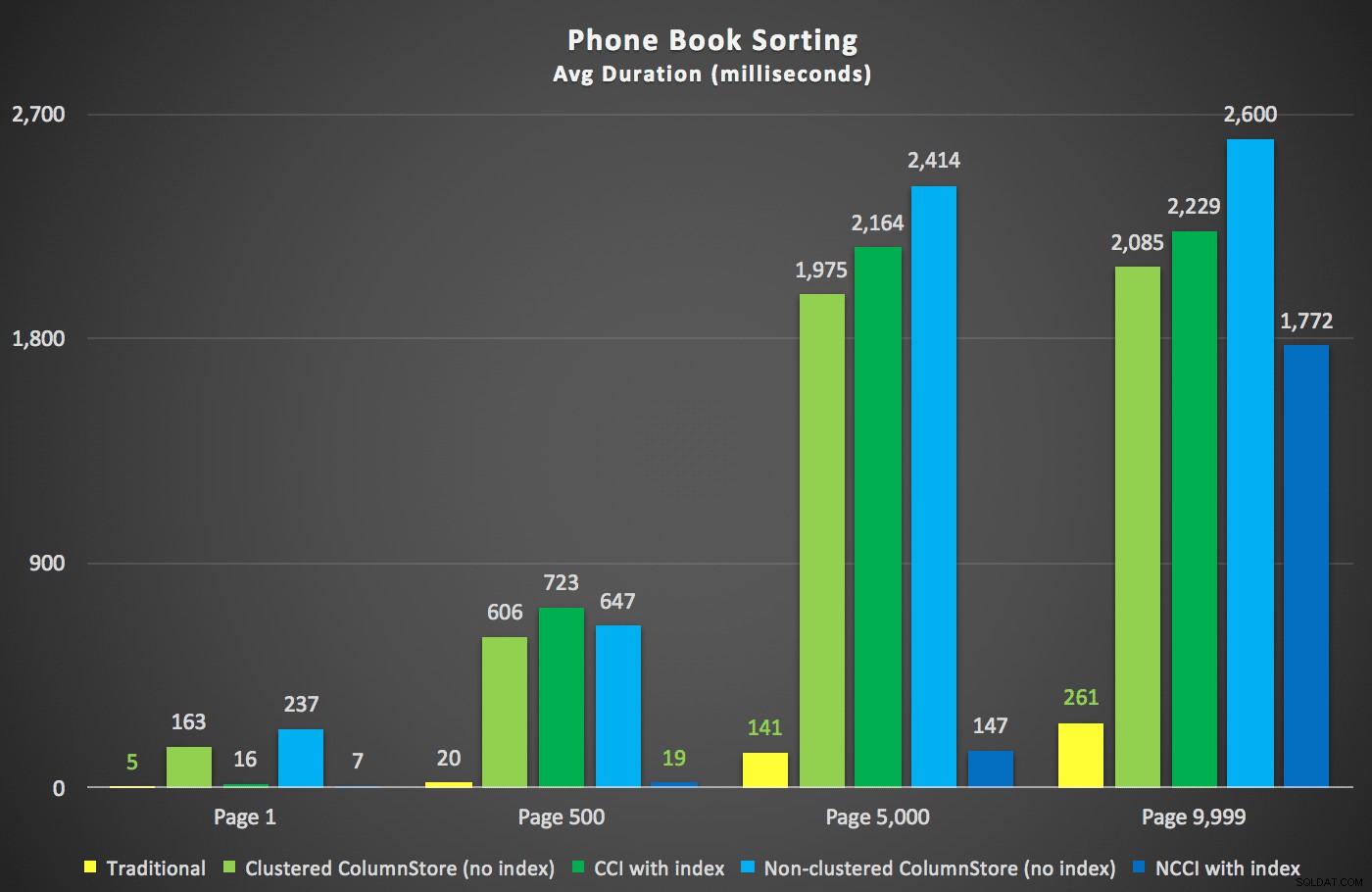
La cosa più interessante qui è che ora la query di paging sulla tabella con l'indice ColumnStore non cluster sembra tenere il passo con l'indice tradizionale, fino a quando non arriviamo oltre la metà della tabella. Guardando i piani, possiamo vedere che a pagina 5.000 viene utilizzata una scansione dell'indice tradizionale e l'indice ColumnStore viene completamente ignorato:
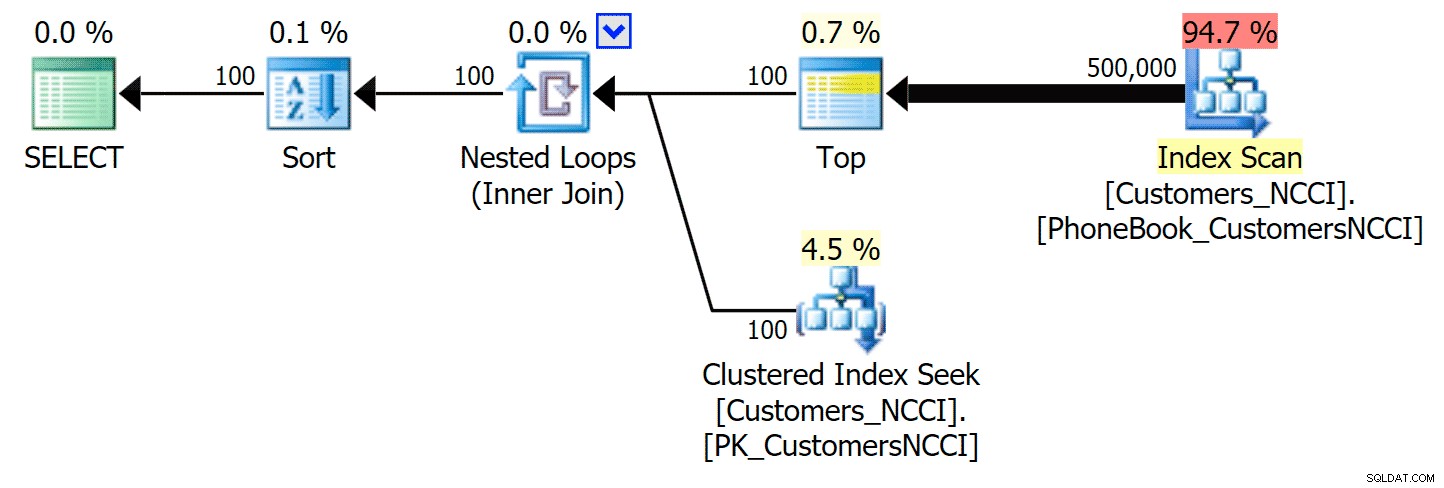 Piano della rubrica che ignora l'indice ColumnStore non in cluster
Piano della rubrica che ignora l'indice ColumnStore non in cluster
Ma da qualche parte tra il punto medio di 5.000 pagine e la "fine" della tabella a 9.999 pagine, l'ottimizzatore ha raggiunto una sorta di punto critico e, per la stessa identica query, ora sta scegliendo di eseguire la scansione dell'indice ColumnStore non in cluster :
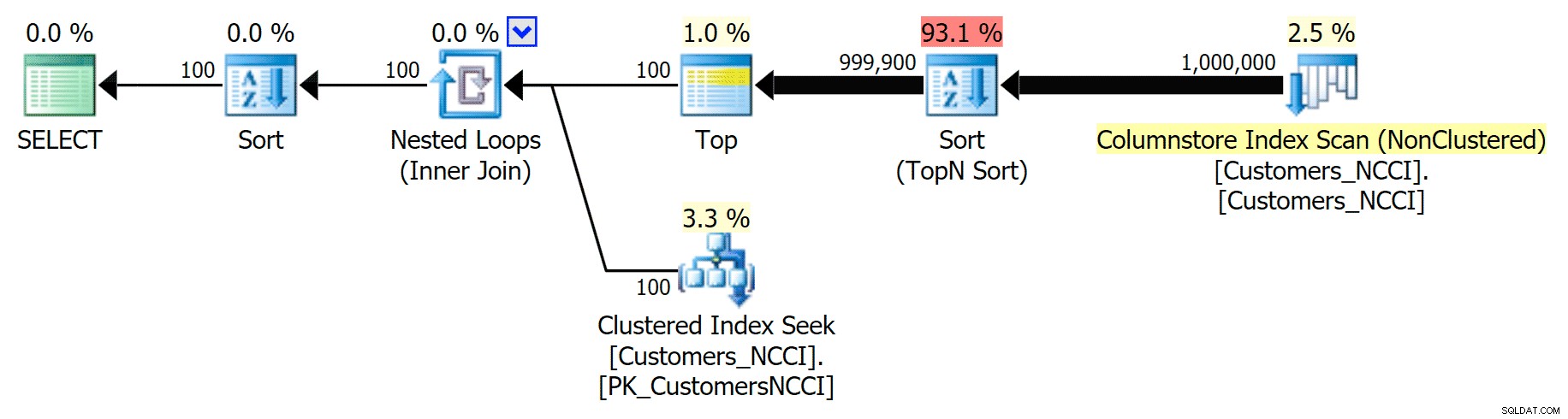 Piano della rubrica "suggerimenti" e utilizza l'indice ColumnStore
Piano della rubrica "suggerimenti" e utilizza l'indice ColumnStore
Questa risulta essere una decisione non eccezionale da parte dell'ottimizzatore, principalmente a causa del costo dell'operazione di ordinamento. Puoi vedere quanto migliora la durata se suggerisci l'indice normale:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Questo produce il seguente piano, quasi identico al primo piano sopra (un costo leggermente più alto per la scansione, però, semplicemente perché c'è più output):
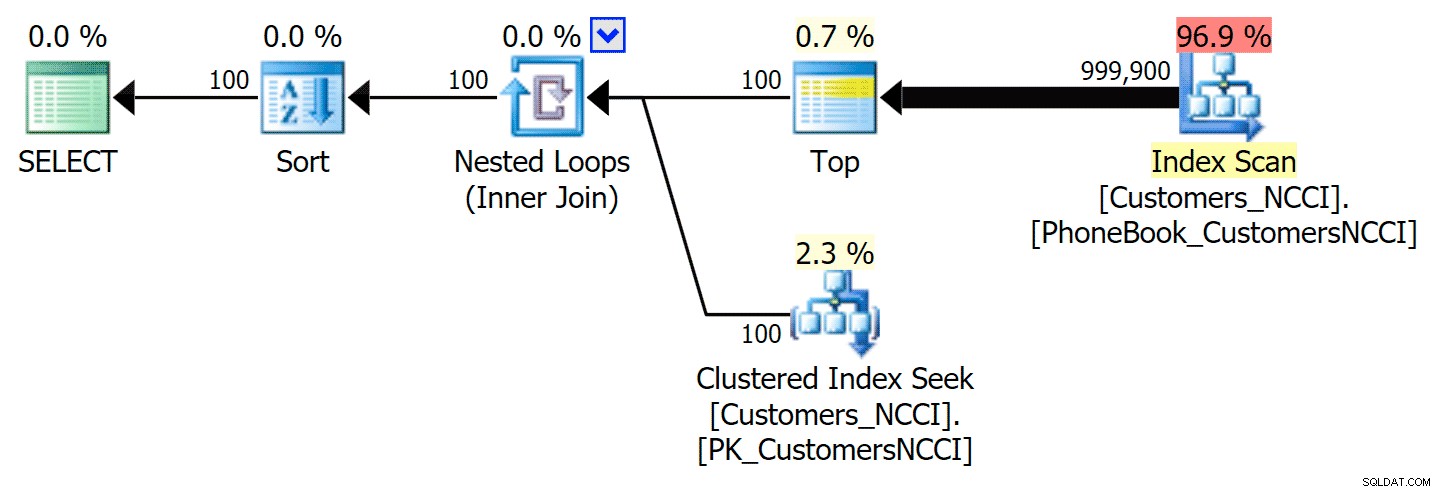 Piano della rubrica con indice suggerito
Piano della rubrica con indice suggerito
Puoi ottenere lo stesso risultato utilizzando OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) invece del suggerimento di indice esplicito. Tieni presente che è come non avere l'indice ColumnStore in primo luogo.
Conclusione
Sebbene ci siano un paio di casi limite sopra in cui un indice ColumnStore potrebbe (a malapena) ripagare, non mi sembra che siano adatti a questo specifico scenario di impaginazione. Penso che, soprattutto, mentre ColumnStore dimostri un notevole risparmio di spazio dovuto alla compressione, le prestazioni di runtime non sono fantastiche a causa dei requisiti di ordinamento (anche se si stima che questi ordinamenti vengano eseguiti in modalità batch, una nuova ottimizzazione per SQL Server 2016).
In generale, questo potrebbe avere molto più tempo speso in ricerca e test; seguendo gli articoli precedenti, volevo cambiare il meno possibile. Mi piacerebbe trovare quel punto di svolta, ad esempio, e vorrei anche riconoscere che questi non sono esattamente test su vasta scala (a causa delle dimensioni della VM e dei limiti di memoria) e che ti ho lasciato indovinare su molti le metriche di runtime (principalmente per brevità, ma non so che un grafico di letture che non sono sempre proporzionali alla durata te lo direbbe davvero). Questi test presuppongono anche i lussi di SSD, memoria sufficiente, una cache sempre calda e un ambiente per utente singolo. Mi piacerebbe davvero eseguire una serie più ampia di test su più dati, su server più grandi con dischi più lenti e istanze con meno memoria, per tutto il tempo con simultaneità simulata.
Detto questo, questo potrebbe anche essere solo uno scenario che ColumnStore non è progettato per aiutare a risolvere in primo luogo, poiché la soluzione sottostante con gli indici tradizionali è già abbastanza efficiente nell'estrarre un insieme ristretto di righe, non esattamente la timoneria di ColumnStore. Forse un'altra variabile da aggiungere alla matrice è la dimensione della pagina:tutti i test precedenti estraggono 100 righe alla volta, ma cosa succede se siamo dopo 10.000 o 100.000 righe alla volta, indipendentemente dalle dimensioni della tabella sottostante?
Hai una situazione in cui il tuo carico di lavoro OLTP è stato migliorato semplicemente aggiungendo gli indici ColumnStore? So che sono progettati per carichi di lavoro in stile data warehouse, ma se hai riscontrato vantaggi altrove, mi piacerebbe conoscere il tuo scenario e vedere se riesco a incorporare elementi di differenziazione nel mio banco di prova.