Nota:questo post è stato originariamente pubblicato solo nel nostro eBook, High Performance Techniques for SQL Server, Volume 4. Puoi trovare informazioni sui nostri eBook qui.
Mi viene posta regolarmente la domanda "Da dove comincio quando si tratta di provare a ottimizzare un'istanza di SQL Server?" La mia prima risposta è chiedere loro la configurazione della loro istanza. Se alcune cose non sono configurate correttamente, iniziare subito a esaminare query di lunga durata o costose potrebbe essere uno sforzo inutile.
Ho scritto sul blog di cose comuni che gli amministratori perdono dove condivido molte delle impostazioni che gli amministratori dovrebbero modificare da un'installazione predefinita di SQL Server. Per gli elementi relativi alle prestazioni, dico loro che dovrebbero controllare quanto segue:
- Impostazioni di memoria
- Aggiornamento delle statistiche
- Manutenzione dell'indice
- MAXDOP e soglia di costo per il parallelismo
- Best practice per tempdb
- Ottimizza per carichi di lavoro ad hoc
Una volta superati gli elementi di configurazione, chiedo se hanno esaminato le statistiche di file e di attesa e le query ad alto costo. La maggior parte delle volte la risposta è "no", con una spiegazione che non sono sicuri di come trovare quell'informazione.
In genere, la conformità comune quando qualcuno afferma di aver bisogno di ottimizzare un server SQL è che sta funzionando lentamente. Cosa significa lento? È un determinato rapporto, un'applicazione specifica o altro? Ha appena iniziato a succedere o è peggiorato nel tempo? Comincio ponendo le solite domande di triage su ciò che la memoria, la CPU e l'utilizzo del disco vengono confrontati con quando le cose sono normali, il problema ha appena iniziato a verificarsi e cosa è cambiato di recente. A meno che il cliente non acquisisca una linea di base, non ha metriche con cui confrontare per sapere se le statistiche attuali sono anormali.
Quasi tutti i server SQL su cui lavoro ospitano più di un database utente. Quando un client segnala che SQL Server è lento, la maggior parte delle volte è preoccupato per un'applicazione specifica che causa problemi ai propri clienti. Una reazione istintiva è concentrarsi immediatamente su quel particolare database, tuttavia spesso un altro processo potrebbe consumare risorse preziose e il database dell'applicazione ne risente. Ad esempio, se si dispone di un database di report di grandi dimensioni e qualcuno ha avviato un report di grandi dimensioni che satura il disco, aumenta la CPU e svuota la cache del piano, si può scommettere che i database degli altri utenti rallenteranno durante la generazione del report.
Mi piace sempre iniziare guardando le statistiche dei file. Per SQL Server 2005 e versioni successive, è possibile interrogare la DMV sys.dm_io_virtual_file_stats per ottenere le statistiche di I/O per ogni file di registro e dati. Questo DMV ha sostituito la funzione fn_virtualfilestats. Per acquisire le statistiche del file, mi piace usare uno script che Paul Randal ha messo insieme:catturare le latenze IO per un periodo di tempo. Questo script catturerà una linea di base e, 30 minuti dopo (a meno che non modifichi la durata nella sezione WAITFOR DELAY), acquisirà le statistiche e calcolerà i delta tra di esse. La sceneggiatura di Paul fa anche un po' di calcoli per determinare le latenze di lettura e scrittura, il che rende molto più facile per noi leggere e capire.
Sul mio laptop ho ripristinato una copia del database AdventureWorks2014 su un'unità USB in modo da avere velocità del disco inferiori; Ho quindi avviato un processo per generare un carico contro di esso. Puoi vedere i risultati di seguito in cui la mia latenza in scrittura per il mio file di dati è 240 ms e la latenza in scrittura per il mio file di registro è 46 ms. Latenze così elevate sono fastidiose.
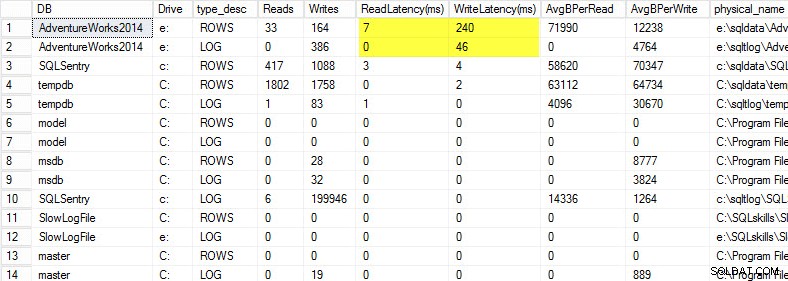
Qualsiasi cosa oltre i 20 ms dovrebbe essere considerata negativa, come ho condiviso in un post precedente:monitoraggio della latenza di lettura/scrittura. La mia latenza di lettura è decente, ma il database AdventureWorks2014 soffre di scritture lente. In questo caso indagherei su cosa sta generando le scritture e sulle prestazioni del mio sottosistema di I/O. Se si trattasse di latenze di lettura eccessivamente elevate, inizierei a esaminare le prestazioni delle query (perché esegue così tante letture, ad esempio da indici mancanti), nonché le prestazioni complessive del sottosistema di I/O.
È importante conoscere le prestazioni complessive del tuo sottosistema I/O e il modo migliore per sapere di cosa è capace è confrontarlo. Glenn Berry ne parla nel suo articolo che analizza le prestazioni di I/O per SQL Server. Glenn spiega la latenza, gli IOPS e il throughput e mostra CrystalDiskMark, uno strumento gratuito che puoi utilizzare per basare il tuo spazio di archiviazione.
Dopo aver scoperto come si comportano le statistiche dei file, mi piace esaminare le statistiche di attesa utilizzando il DMV sys.dm_os_wait_stats, che restituisce informazioni su tutte le attese che si sono verificate. Per questo mi rivolgo a un altro script che Paul Randal fornisce nel suo post sul blog di acquisizione delle statistiche di attesa per un periodo di tempo. La sceneggiatura di Paul ci fa di nuovo un po' di matematica ma, cosa più importante, esclude molte delle attese benigne di cui di solito non ci interessa. Questo script ha anche un WAITFOR DELAY ed è impostato su 30 minuti. La lettura delle statistiche di attesa può essere un po' più complicata:puoi avere attese che sembrano essere alte in base alla percentuale, ma l'attesa media è così bassa che non c'è nulla di cui preoccuparsi.
Ho avviato lo stesso processo di caricamento e acquisito le mie statistiche di attesa, che ho mostrato di seguito. Per spiegazioni su molti di questi tipi di attesa puoi leggere un altro dei post del blog di Paul, le statistiche di attesa o per favore dimmi dove fa male, oltre ad alcuni dei suoi post su questo blog.
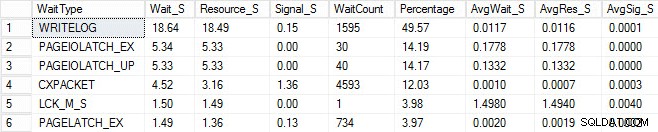
In questo output inventato, le attese di PAGEIOLATCH potrebbero indicare un collo di bottiglia con il mio sottosistema di I/O, ma potrebbero anche essere un problema di memoria, ricerche di tabelle o una serie di altri problemi. Nel mio caso, sappiamo che si tratta di un problema con il disco, poiché sto archiviando il database su una chiavetta USB. Il tempo di attesa LCK_M_S è molto alto, tuttavia c'è solo un'istanza dell'attesa. Anche il mio WRITELOG è più alto di quanto vorrei vedere, ma è comprensibile conoscendo i problemi di latenza con la chiavetta USB. Questo mostra anche le attese di CXPACKET e sarebbe facile avere una reazione istintiva e pensare di avere un problema di parallelismo/MAXDOP, tuttavia il contatore AvgWait_S è molto basso. Fai attenzione quando usi le attese per la risoluzione dei problemi. Lascia che sia una guida per dirti cose che non sono un problema e per darti una direzione su dove andare per cercare i problemi. Una corretta risoluzione dei problemi correla i comportamenti di più aree per restringere il problema.
Dopo aver esaminato il file e attendere le statistiche, inizio a scavare nelle query ad alto costo in base ai problemi che ho riscontrato. Per questo mi rivolgo alle query di informazioni diagnostiche di Glenn Berry. Questi insiemi di query sono gli script di riferimento utilizzati da molti consulenti. Glenn e la community forniscono costantemente aggiornamenti per renderli il più informativi e solidi possibile. Una delle mie query preferite sono le prime query memorizzate nella cache in base al conteggio delle esecuzioni. Mi piace trovare query o stored procedure che hanno un conteggio_esecuzione elevato accoppiato a letture_logiche_logiche elevate. Se queste query hanno opportunità di ottimizzazione, puoi fare rapidamente una grande differenza per il server. Negli script sono inclusi anche i principali SP memorizzati nella cache in base alle letture logiche totali e gli SP principali nella cache in base alle letture fisiche totali. Entrambi sono utili per cercare letture elevate con conteggi di esecuzione elevati in modo da poter ridurre il numero di I/O.
Oltre agli script di Glenn, mi piace usare sp_whoisactive di Adam Machanic per vedere cosa è attualmente in esecuzione.
C'è molto di più nell'ottimizzazione delle prestazioni oltre a guardare le statistiche di file e wait e le query ad alto costo, tuttavia è da lì che mi piace iniziare. È un modo per valutare rapidamente un ambiente per iniziare a determinare la causa del problema. Non esiste un modo completamente infallibile per l'ottimizzazione:ciò di cui ogni DBA di produzione ha bisogno è una checklist di cose da eseguire per eliminare e una raccolta davvero buona di script da eseguire per analizzare lo stato del sistema. Avere una linea di base è la chiave per escludere rapidamente il comportamento normale rispetto a quello anormale. La mia buona amica Erin Stellato ha un intero corso su Pluralsight chiamato SQL Server:benchmarking e baseline se hai bisogno di aiuto con l'impostazione e l'acquisizione della tua linea di base.
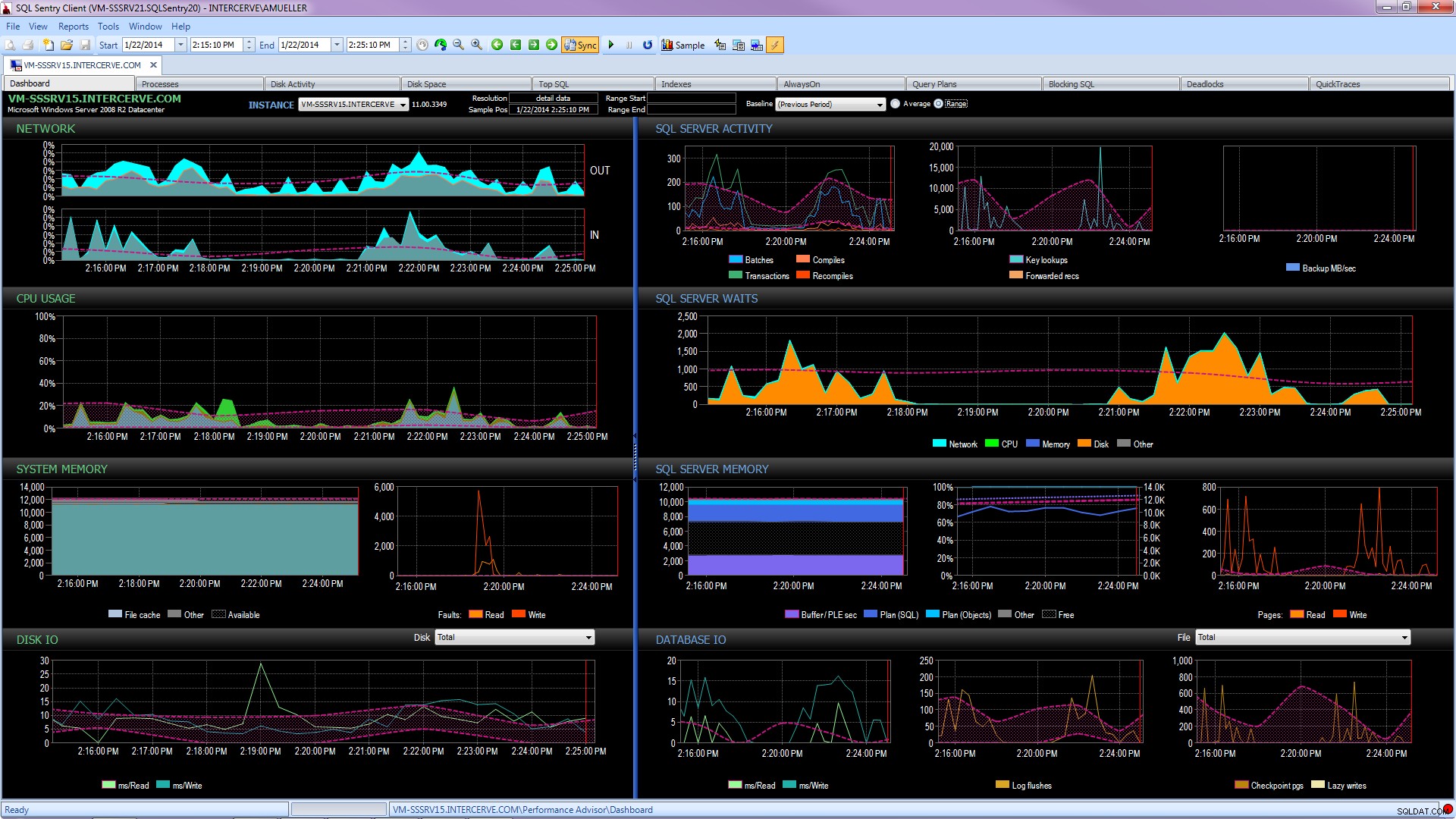
Meglio ancora, ottieni uno strumento all'avanguardia come SQL Sentry Performance Advisor che non solo raccoglierà e memorizzerà informazioni storiche per la profilazione e l'andamento e darà facile accesso a tutti i dettagli sopra menzionati e altro, ma fornisce anche la capacità di confrontare l'attività con le linee di base integrate o definite dall'utente, mantenere in modo efficiente gli indici senza muovere un dito e avvisare o automatizzare le risposte sulla base di un'architettura di condizioni personalizzate molto robusta. La schermata seguente mostra la visualizzazione storica del dashboard di Performance Advisor, con le attese del disco in arancione, l'I/O del database in basso a destra e le linee di base che confrontano il periodo corrente e precedente su ogni grafico (fare clic per ingrandire):
Gli strumenti di monitoraggio della qualità non sono gratuiti, ma forniscono un sacco di funzionalità e supporto che ti consentono di concentrarti sui problemi di prestazioni dei tuoi server, invece di concentrarti su query, lavori e avvisi che potrebbero ti permettono di concentrarti sui tuoi problemi di prestazioni, ma solo una volta che li hai corretti. Spesso è molto utile non reinventare la ruota.