In questo articolo, spiegherò come spostare una tabella dal filegroup primario al filegroup secondario. Per prima cosa, capiamo cosa sono datafile, filegroup e tipo di filegroup.
File di database e filegroup
Quando SQL Server è installato su qualsiasi server, crea un file di dati primario e un file di registro per archiviare i dati. Il file di dati primario memorizza i dati e gli oggetti del database come tabelle, indici, procedure archiviate e così via. I file di registro memorizzano le informazioni necessarie per recuperare le transazioni. I file di dati possono essere raggruppati insieme in filegroup.
SQL Server ha tre tipi di file
- File principale :viene creato durante l'installazione del server SQL e contiene i metadati e le informazioni del database. I dati utente, gli oggetti possono essere archiviati nei file di dati primari. Il file principale ha l'estensione .mdf.
- File secondario :i file secondari sono definiti dall'utente. Memorizzano i dati dell'utente, gli oggetti creati da un utente. Hanno l'estensione .ndf.
- File di registro delle transazioni s:i file T-Logs registrano tutte le transazioni eseguite per recuperare il database. L'estensione del file di registro in .ldf.
Come accennato in precedenza, i file di dati possono essere raggruppati in un filegroup. Durante l'installazione di SQL Server, viene creato il filegroup primario con un file di dati primario. I filegroup secondari sono definiti dall'utente. Hanno file di dati secondari. Quando creiamo un nuovo database, possiamo creare file di dati e filegroup secondari. L'aggiunta di file di dati secondari aiuta a migliorare le prestazioni. Può essere creato su diverse unità disco o partizioni disco separate che riducono l'attesa IO e la latenza di lettura-scrittura.
Si consiglia di mantenere le tabelle e gli indici in filegroup separati. Inoltre, mantenere le tabelle di grandi dimensioni in file separati migliora le prestazioni.
Esistono tre tipi di gruppi di file:
- Filegroup di righe :il gruppo di file di riga, noto anche come filegroup primario, contiene un file di dati primario. Oggetti SQL, dati, tabelle di sistema allocati al filegroup primario.
- Filegroup con ottimizzazione per la memoria :il filegroup con ottimizzazione per la memoria contiene tabelle e dati con ottimizzazione per la memoria. Per abilitare OLTP in memoria, dobbiamo creare un filegroup ottimizzato per la memoria.
- FileStream :il filegroup del flusso di file contiene dati del flusso di file come immagini, documenti, file eseguibili ecc. Il filegroup primario non può contenere dati del flusso di file, è necessario creare un gruppo di file FileStream. Contiene i dati FileStream.
Impostazione demo
In questa demo, ho creato "DemoDatabase" sull'istanza di SQL Server 2017. Le schede "Records" e "PatientData" sono state create nel database. La chiave primaria "PK_CIDX_Records_ID" è stata creata nella tabella "Records" e l'indice cluster "CIDX_PatientData_ID" è stato creato nella tabella "PatientData". In questa demo, sposterò le tabelle "Records" e "PatientData" dal filegroup primario al filegroup secondario.
Per questo, dobbiamo fare quanto segue:
- Crea un filegroup secondario.
- Aggiungi file di dati al filegroup secondario.
- Sposta la tabella nel filegroup secondario spostando l'indice cluster con il vincolo della chiave primaria.
- Sposta le tabelle nel filegroup secondario spostando l'indice cluster senza la chiave primaria.
Crea filegroup secondario
È possibile creare un filegroup secondario utilizzando T-SQL OPPURE utilizzando la procedura guidata Aggiungi file in SQL Server Management Studio. Per aggiungere un filegroup utilizzando SSMS, aprire SSMS e selezionare un database in cui è necessario creare un filegroup. Fare clic con il pulsante destro del database e selezionare "Proprietà ”>> seleziona “Filegroup " e fai clic su "Aggiungi filegroup ” come mostrato nell'immagine seguente:
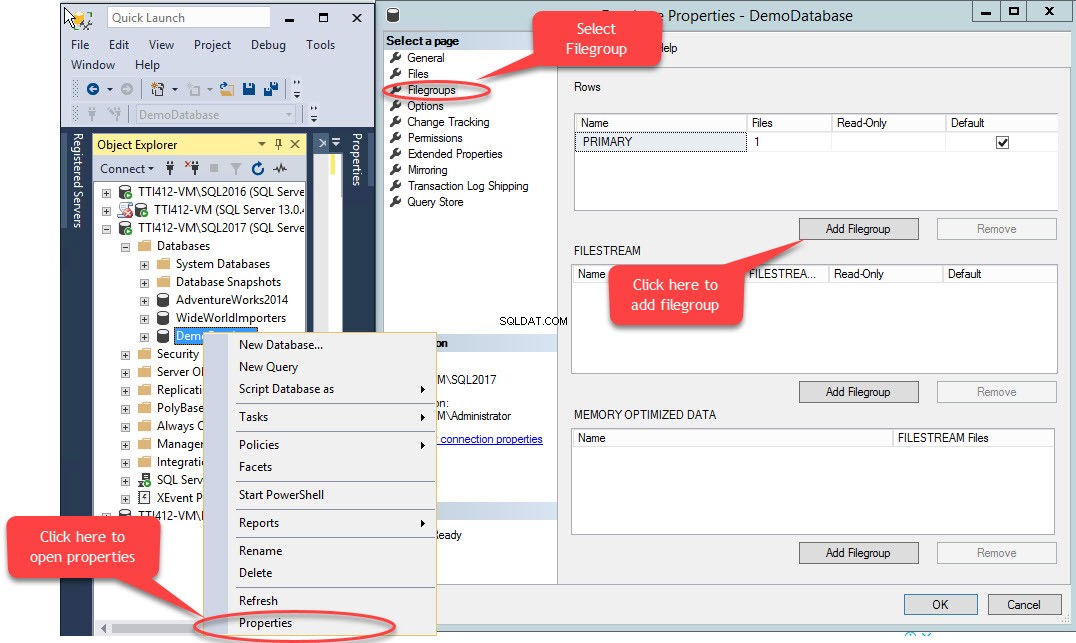
Quando facciamo clic su "Aggiungi filegroup ”, verrà aggiunta una riga nelle “Righe " griglia. Nelle "Righe ” griglia, fornisci il nome del filegroup appropriato in “Nome colonna ". Filegroup non è né di sola lettura né predefinito; quindi, mantieni il Sola lettura e Predefinito caselle di controllo deselezionate per il nuovo filegroup. Vedi l'immagine seguente:
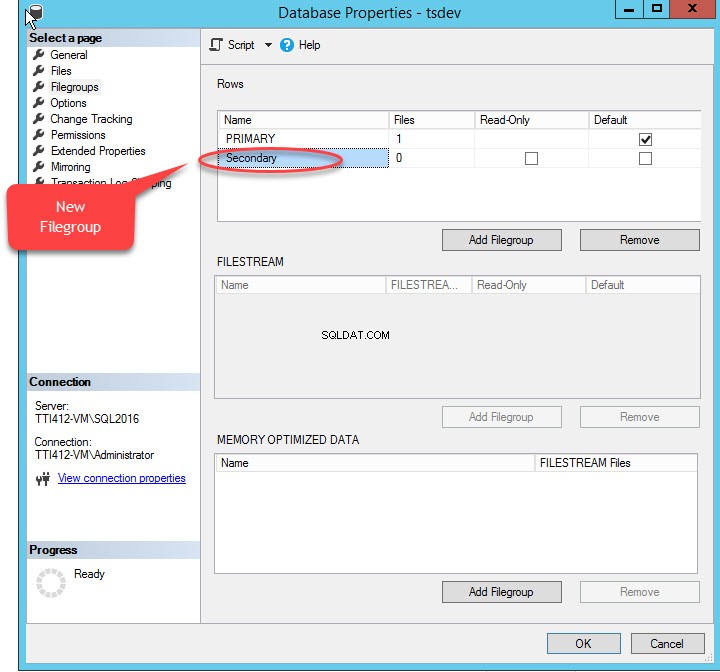
Fare clic su OK per chiudere la finestra di dialogo.
Per creare un filegroup utilizzando lo script T-SQL, eseguire lo script seguente.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Aggiunta di file al filegroup
Per aggiungere file in un filegroup, apri le proprietà del database, seleziona "file" e fai clic su "Aggiungi". Come mostrato nell'immagine seguente:
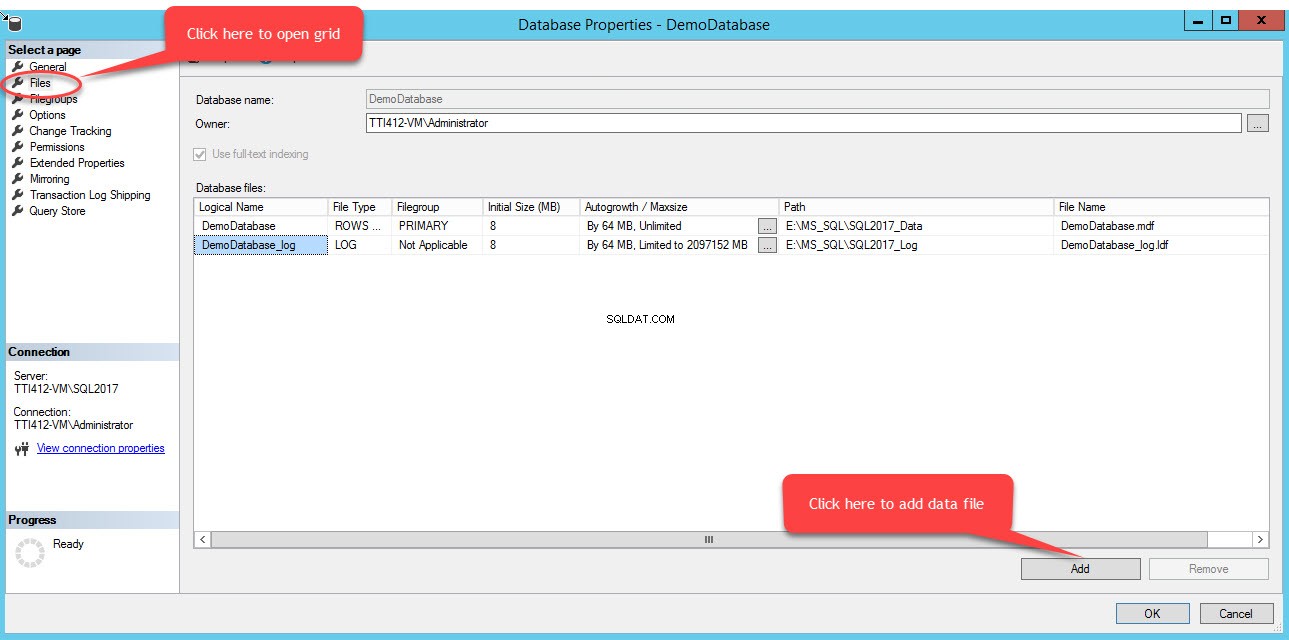
Verrà aggiunta una riga vuota nei File di database vista a griglia. Nella visualizzazione Griglia, fornisci il nome logico appropriato nel Nome logico colonna, seleziona Dati righe dal Tipo di file casella a discesa, seleziona secondaria dal Filegroup casella a discesa, imposta la dimensione iniziale del file nella Dimensione iniziale colonne, imposta il parametro di crescita automatica e dimensione massima in Crescita automatica/Dimensione massima colonna, fornisci la posizione fisica del file di dati secondario nel Percorso colonna e fornisci il nome file appropriato in Nome file colonna. Vedi l'immagine seguente:
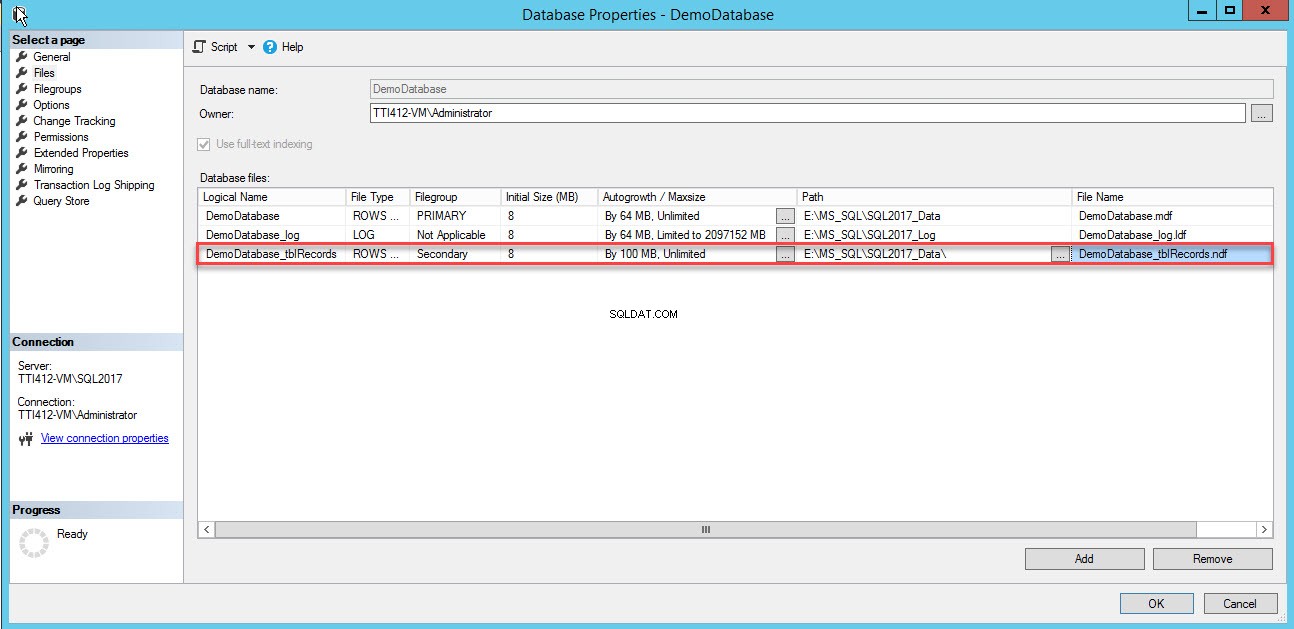
Utilizzare il seguente script T-SQL per creare un file di dati secondario.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
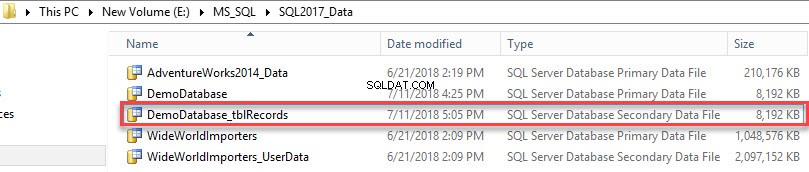
Il file di dati secondario è stato creato. Vedi l'immagine seguente:
Per visualizzare un elenco di gruppi di file creati nel database, eseguire la query seguente.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Di seguito è riportato un output della query.

Trasferimento di una tabella esistente dal filegroup primario al filegroup secondario
Possiamo spostare una tabella esistente in un altro filegroup spostando l'indice cluster in un altro filegroup. Come sappiamo, un nodo foglia dell'indice cluster ha dati effettivi; quindi lo spostamento dell'indice cluster può spostare l'intera tabella in un altro gruppo di file. Lo spostamento dell'indice presenta una limitazione:se l'indice è una chiave primaria o un vincolo univoco, non è possibile spostare l'indice utilizzando SQL Server Management Studio. Per spostare questi indici, dobbiamo utilizzare crea indice istruzione e con DROP_Existing=ON opzione.
Spostamento dell'indice cluster con vincolo della chiave primaria.
La chiave primaria applica valori univoci, quindi crea l'indice cluster univoco. La colonna chiave è PRN. Per crearlo nel filegroup secondario, imposta DROP_EXISTING=ON opzione e il filegroup dovrebbe essere secondario. Esegui il seguente script.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
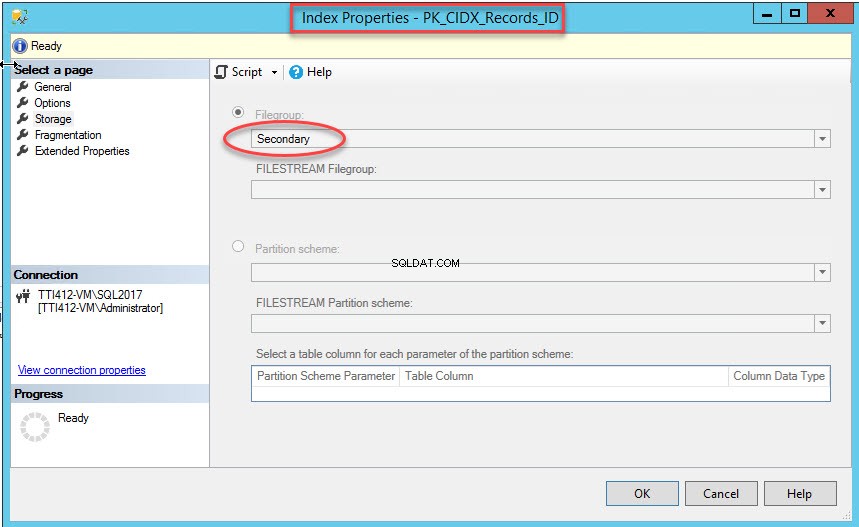
Una volta eseguito correttamente il comando, verificare che l'indice sia stato creato nel filegroup secondario. A tale scopo, fai clic con il pulsante destro del mouse su Archiviazione opzione nelle Proprietà dell'indice la finestra di dialogo. Per aprire le proprietà dell'indice, espandi il DemoDatabase database>> espandi Tabelle>> espandi Indici . Fai clic con il pulsante destro del mouse su PK_CIDX_Records_ID , come mostrato nell'immagine seguente:
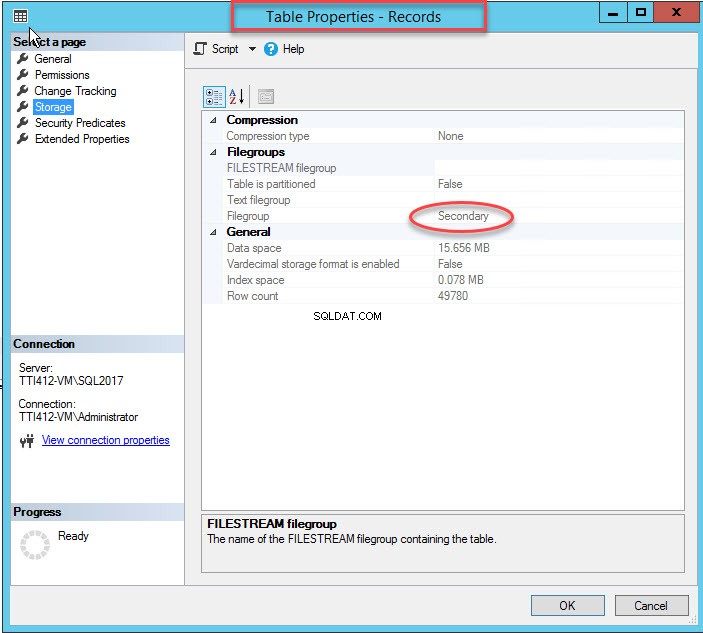
Come accennato, una volta che l'indice cluster si sposta in un filegroup secondario, la tabella verrà spostata nel filegroup secondario. Per verificarlo, fai clic con il pulsante destro del mouse su Archiviazione opzione nelle Proprietà tabella la finestra di dialogo. Per aprire le proprietà dell'indice, espandi il DemoDatabase database>> espandi Tabella s>> fare clic con il pulsante destro del mouse su Record e seleziona archiviazione, come mostrato nell'immagine seguente:
Spostamento dell'indice cluster senza chiave primaria
Possiamo spostare l'indice cluster senza chiave primaria utilizzando SQL Server Management Studio. Per farlo, espandi il DemoDatabase database>> espandi Tabelle>> espandi Indice s>> fare clic con il pulsante destro del mouse su CIDX_PatientData_ID indicizza e seleziona Proprietà come mostrato nell'immagine seguente:
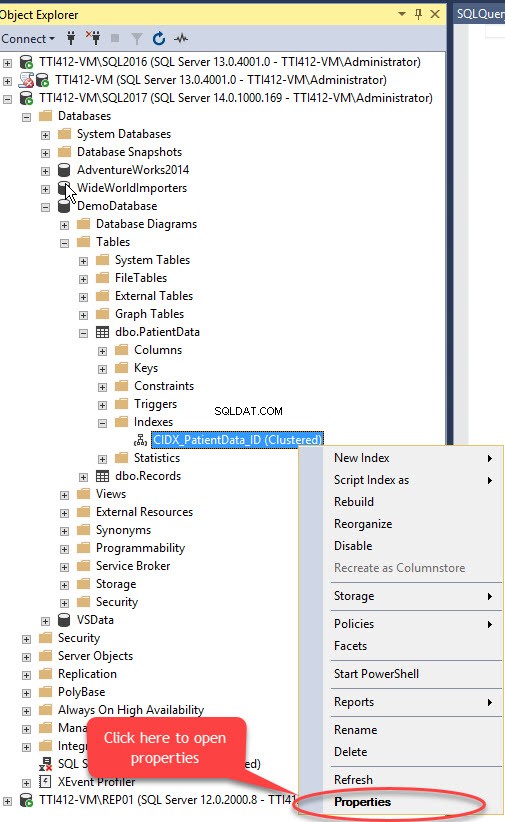
Le Proprietà dell'Indice si apre la finestra di dialogo. Nella finestra di dialogo, seleziona Archiviazione e nella finestra Archiviazione, fai clic su Filegroup casella a discesa, seleziona il Secondario filegroup e fai clic su OK come mostrato nell'immagine seguente:
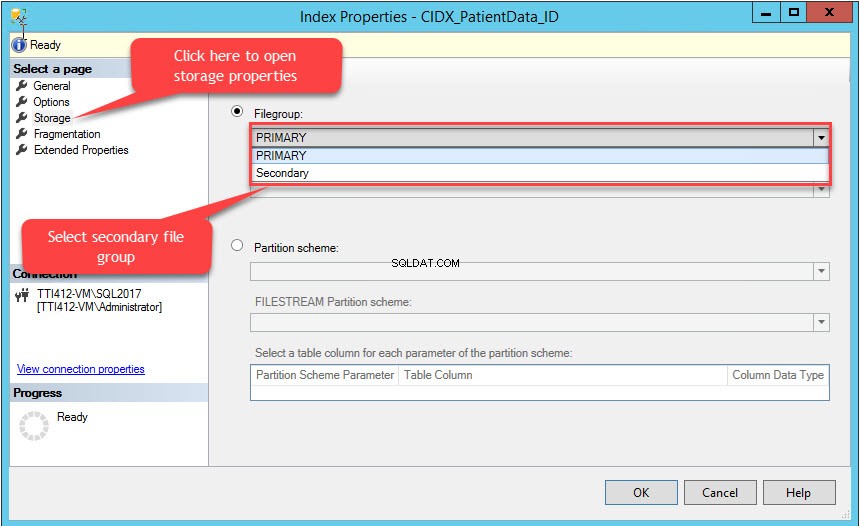
La modifica del filegroup di indice ricreerà l'intero indice. Dopo aver ricreato l'indice, apri Proprietà tabella e seleziona uno spazio di archiviazione.
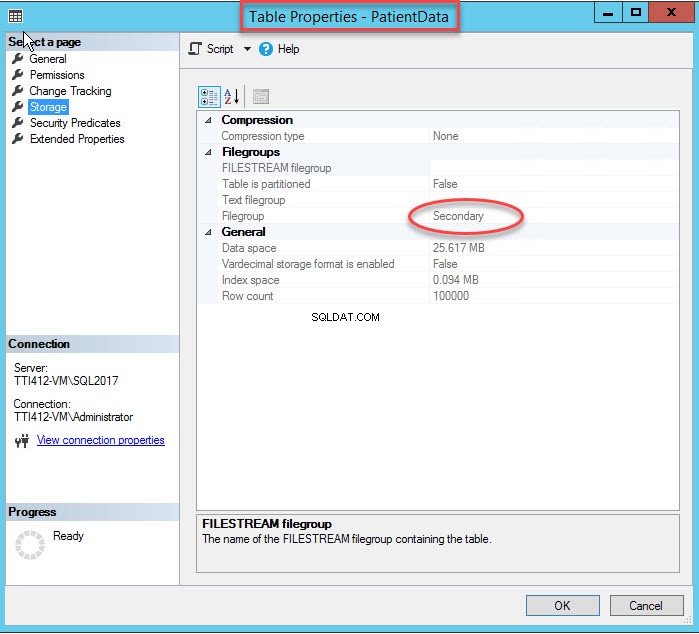
Come puoi vedere nell'immagine sopra, insieme allo spostamento di CIDX_PatientData_ID indice cluster nel filegroup secondario, i PatientData la tabella viene spostata anche nella Secondaria filegroup.
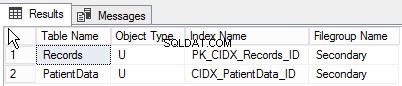
Eseguendo la query seguente, puoi trovare l'elenco degli oggetti creati in gruppi di file diversi:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Di seguito è riportato l'output della query:
Riepilogo
In questo articolo ho spiegato
-
- Nozioni di base su file di dati e filegroup.
- Come creare un filegroup secondario e aggiungervi un file di dati secondario.
- Sposta la tabella nel filegroup secondario spostando:
- Chiave primaria.
- Indice raggruppato.