Quando ero a Chicago alcune settimane fa per uno dei nostri eventi di immersione, un partecipante ha avuto una domanda sulle statistiche. Non entrerò in tutti i dettagli sul problema, ma il partecipante ha affermato che le statistiche sono state aggiornate utilizzando sp_updatestats . Questo è un metodo per aggiornare le statistiche che non ho mai consigliato; Ho sempre consigliato una combinazione di ricostruzioni di indici e UPDATE STATISTICS per mantenere le statistiche aggiornate. Se non hai familiarità con sp_updatestats , è un comando che viene eseguito per l'intero database per aggiornare le statistiche. Ma come ha fatto notare Kimberly al partecipante, sp_updatestats aggiornerà una statistica purché sia stata modificata una riga. Whoa. Ho aperto immediatamente Books Online e per sp_updatestats vedrai questo:
Ora, lo ammetto, ho fatto un'ipotesi su cosa significasse "...richiede l'aggiornamento in base alle informazioni rowmodctr nella vista del catalogo sys.sysindexes ...". Ho presupposto che la decisione di aggiornamento seguisse la stessa logica seguita dall'opzione Statistiche di aggiornamento automatico, ovvero:
- La dimensione della tabella è passata da 0 a>0 righe (test 1).
- Il numero di righe nella tabella quando sono state raccolte le statistiche era 500 o meno e da allora il colmodctr della colonna principale dell'oggetto statistiche è cambiato di oltre 500 (test 2).
- La tabella aveva più di 500 righe quando sono state raccolte le statistiche e il colmodctr della colonna iniziale dell'oggetto statistiche è cambiato di oltre il 500 + 20% del numero di righe nella tabella quando sono state raccolte le statistiche ( prova 3).
Questa logica non viene seguita per sp_updatestats . In effetti, la logica è così incredibilmente semplice, fa paura:se una riga viene modificata, la statistica viene aggiornata. Una riga. UNA FILA. Qual è la mia preoccupazione? Sono preoccupato per il sovraccarico dell'aggiornamento delle statistiche per un sacco di statistiche che non hanno davvero bisogno di essere aggiornate. Diamo un'occhiata più da vicino a sp_updatestats .
Inizieremo con una nuova copia del database AdventureWorks2012 che puoi scaricare da Codeplex. Per prima cosa aggiornerò le righe in tre tabelle diverse:
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
Abbiamo modificato una riga in Production.Product , 211 righe in Person.Person e abbiamo aggiunto 10.000 righe a Sales.SalesReason . Se il sp_updatestats la procedura ha seguito la stessa logica per gli aggiornamenti dell'opzione Statistiche di aggiornamento automatico, quindi solo Sales.SalesReason si aggiornerebbe perché aveva 10 righe per iniziare (mentre le 211 righe aggiornate in Person.Person rappresentano circa l'uno per cento della tabella). Tuttavia, se esaminiamo sp_updatestats , possiamo vedere che la logica utilizzata è diversa. Tieni presente che sto solo estraendo le istruzioni da sp_updatestats che vengono utilizzati per determinare quali statistiche vengono aggiornate.
Un cursore scorre tutte le tabelle definite dall'utente e le tabelle interne nel database:
declare ms_crs_tnames cursor local fast_forward read_only for select name, object_id, schema_id, type from sys.objects o where o.type = 'U' or o.type = 'IT' open ms_crs_tnames fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
Un altro cursore scorre le statistiche per ogni tabella ed esclude gli heap e gli indici e le statistiche ipotetici. Nota che sys.sysindexes è usato in sp_helpstats . Sysindexes è una tabella di sistema di SQL Server 2000 e dovrebbe essere rimossa in una versione futura di SQL Server. Questo è interessante, poiché l'altro metodo per determinare le righe aggiornate è il sys.dm_db_stats_properties DMF, disponibile solo in SQL 2008 R2 SP2 e SQL 2012 SP1.
set @index_names = cursor local fast_forward read_only for select name, indid, rowmodctr from sys.sysindexes where id = @table_id and indid > 0 and indexproperty(id, name, 'ishypothetical') = 0 order by indid
Dopo un po' di preparazione e logica aggiuntiva, arriviamo a un IF dichiarazione che rivela che sp_updatestats filtra le statistiche per le quali non è stata aggiornata alcuna riga... confermando che anche se è stata modificata solo una riga, la statistica verrà aggiornata. C'è anche un controllo per @is_ver_current , che è determinato da una funzione interna incorporata.
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
Un altro paio di controlli relativi al campionamento e al livello di compatibilità, quindi UPDATE l'istruzione viene eseguita per la statistica. Prima di eseguire effettivamente sp_updatestats, possiamo interrogare sys.sysindexes per vedere quali statistiche verranno aggiornate:
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type] FROM [sys].[objects] [o] JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id] WHERE ([o].[type] = 'U' OR [o].[type] = 'IT') AND [si].[indid] > 0 AND [si].[rowmodctr] <> 0 ORDER BY [o].[type] DESC, [o].[name];
Oltre alle tre tabelle che abbiamo modificato, c'è un'altra statistica per una tabella utente (dbo.DatabaseLog ) e tre statistiche interne che verranno aggiornate:
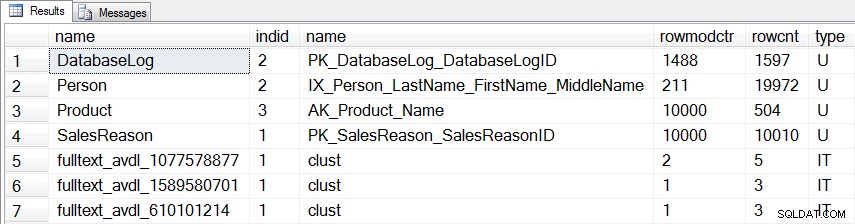
Statistiche che verranno aggiornate
Se eseguiamo sp_updatestats per il database AdventureWorks, l'output elenca tutte le tabelle e le statistiche aggiornate. L'output di seguito viene modificato per mostrare solo le statistiche aggiornate:
Aggiornamento di [sys].[fulltext_avdl_1589580701]
[clust] è stato aggiornato…
1 indice/i/statistica/i sono stati aggiornati, 0 non richiedeva l'aggiornamento.
…
Aggiornamento di [dbo].[DatabaseLog]
[PK_DatabaseLog_DatabaseLogID] è stato aggiornato…
1 indice/i/statistica/i sono stati aggiornati, 0 non necessitava di aggiornamento.
…
Aggiornamento di [sys].[fulltext_avdl_1077578877]
[clust] è stato aggiornato…
1 indice/i/statistica/i sono stati aggiornati, 0 non richiedeva l'aggiornamento.
…
Aggiornamento di [Person].[Person]
[PK_Person_BusinessEntityID], aggiornamento non necessario…
[IX_Person_LastName_FirstName_MiddleName] è stato aggiornato…
[AK_Person_rowguid], aggiornamento non necessario…
1 gli indici/statistiche sono stati aggiornati, 2 non richiedeva l'aggiornamento.
…
Aggiornamento di [Sales].[SalesReason]
[PK_SalesReason_SalesReasonID] è stato aggiornato…
1 indice/i/statistica/i sono stati aggiornati, 0 non necessitava di aggiornamento.
…
Aggiornamento di [Produzione].[Prodotto]
[PK_Product_ProductID], aggiornamento non necessario…
[AK_Product_ProductNumber], aggiornamento non necessario…
[AK_Product_Name] è stato aggiornato…
[ AK_Product_rowguid], l'aggiornamento non è necessario…
[_WA_Sys_00000013_75A278F5], l'aggiornamento non è necessario…
[_WA_Sys_00000014_75A278F5], l'aggiornamento non è necessario…
[_WA_Sys_0000000D_75A278F5], l'aggiornamento non è necessario…
[_WA_Sys_0000000C_75A278F5], l'aggiornamento non è necessario…
1 indice/i/statistica/i sono stati aggiornati, 7 non richiedeva l'aggiornamento.
…
Le statistiche per tutte le tabelle sono state aggiornate.
L'ultima riga dell'output è un po' fuorviante:le statistiche per tutte le tabelle non sono state aggiornate, sono state aggiornate solo le statistiche che hanno avuto una o più righe modificate. E ancora, lo svantaggio di ciò è che forse sono state utilizzate risorse che non erano necessarie. Se una statistica ha solo una riga modificata, dovrebbe essere aggiornata? No. Se ha 10.000 righe aggiornate, dovrebbe essere aggiornato? Beh, questo dipende. Se la tabella ha solo 5.000 righe, allora assolutamente; se la tabella ha 1 milione di righe, allora no, poiché solo l'uno percento della tabella è stato modificato.
Il punto è che se stai usando sp_updatestats per aggiornare le tue statistiche, molto probabilmente stai sprecando risorse, inclusi CPU, I/O e tempdb. Inoltre, l'aggiornamento di ogni statistica richiede tempo e, se hai una finestra di manutenzione ristretta, probabilmente hai altre attività di manutenzione che possono essere eseguite in quel lasso di tempo, invece di aggiornamenti non necessari. Infine, probabilmente non stai fornendo alcun vantaggio in termini di prestazioni aggiornando le statistiche quando sono state modificate così poche righe. La modifica della distribuzione è probabilmente insignificante se solo una piccola percentuale di righe è stata modificata, quindi i valori dell'istogramma e della densità non finiscono per cambiare molto. Inoltre, ricorda che l'aggiornamento delle statistiche invalida i piani di query che utilizzano tali statistiche. Quando tali query vengono eseguite, i piani vengono rigenerati e il piano probabilmente sarà esattamente lo stesso di prima, poiché non vi sono state modifiche significative nell'istogramma. La ricompilazione dei piani di query comporta un costo:non è sempre facile da misurare, ma non dovrebbe essere ignorata.
Un metodo migliore per gestire le statistiche, poiché è necessario gestire le statistiche, consiste nell'implementare un lavoro pianificato che si aggiorna in base alle percentuali di righe che sono state modificate. Puoi usare la suddetta query che interroga sys.sysindexes oppure puoi utilizzare la query seguente che sfrutta il nuovo DMF aggiunto in SQL Server 2008 R2 SP2 e SQL Server 2012 SP1:
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] , [ss].[name] AS [Statistic], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications] FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp WHERE [so].[type] = 'U' AND [sp].[modification_counter] > 0 ORDER BY [sp].[last_updated] DESC;
Renditi conto che tabelle diverse possono avere soglie diverse e dovrai modificare la query sopra per i tuoi database. Per alcune tabelle, aspettare fino a quando il 15% o il 20% delle righe è stato modificato può essere accettabile. Ma per altri, potrebbe essere necessario aggiornare al 10% o addirittura al 5%, a seconda dei valori effettivi e della loro inclinazione. Non c'è proiettile d'argento. Per quanto amiamo gli assoluti, esistono raramente in SQL Server e le statistiche non fanno eccezione. Vuoi comunque lasciare abilitate le statistiche di aggiornamento automatico:è una sicurezza che si attiva se ti manca qualcosa, proprio come la crescita automatica per i file del tuo database. Ma la soluzione migliore è conoscere i tuoi dati e implementare una metodologia che ti permetta di aggiornare le statistiche in base alla percentuale di righe modificate.



