Nel mio ultimo post, abbiamo visto come una query con un aggregato scalare potrebbe essere trasformata dall'ottimizzatore in una forma più efficiente. Come promemoria, ecco di nuovo lo schema:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Scelte del piano
Con 10.000 righe in ciascuna delle tabelle di base, l'ottimizzatore presenta un semplice piano che calcola il massimo leggendo tutte le 30.000 righe in un aggregato:
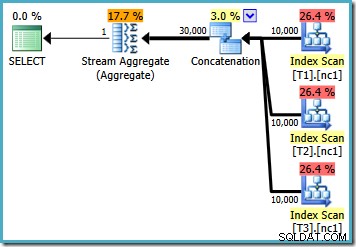
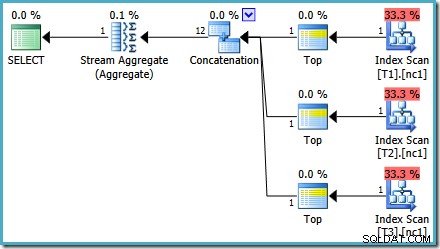
Con 50.000 righe in ogni tabella, l'ottimizzatore dedica un po' più di tempo al problema e trova un piano più intelligente. Legge solo la riga superiore (in ordine decrescente) da ciascun indice e quindi calcola il massimo solo da quelle 3 righe:
Un bug dell'ottimizzatore
Potresti notare qualcosa di strano in quella stima Piano. L'operatore di concatenazione legge una riga da tre tabelle e in qualche modo produce dodici righe! Questo è un errore è causato da un bug nella stima della cardinalità che ho segnalato a maggio 2011. Non è ancora stato risolto a partire da SQL Server 2014 CTP 1 (anche se viene utilizzato il nuovo stimatore di cardinalità) ma spero che venga risolto per il versione finale.
Per vedere come si verifica l'errore, ricorda che una delle alternative di piano considerate dall'ottimizzatore per il caso di 50.000 righe ha aggregati parziali al di sotto dell'operatore di concatenazione:
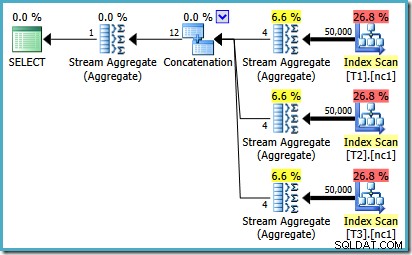
È la stima della cardinalità per questi MAX parziali aggregati che è in colpa. Stimano quattro righe in cui il risultato è garantito come una riga. Potresti visualizzare un numero diverso da quattro:dipende da quanti processori logici sono disponibili per l'ottimizzatore al momento della compilazione del piano (consulta il link del bug sopra per maggiori dettagli).
L'ottimizzatore sostituisce successivamente gli aggregati parziali con gli operatori Top (1), che ricalcolano correttamente la stima della cardinalità. Purtroppo, l'operatore di concatenazione riflette ancora le stime per gli aggregati parziali sostituiti (3 * 4 =12). Di conseguenza, ci ritroviamo con una concatenazione che legge 3 righe e ne produce 12.
Utilizzando TOP invece di MAX
Guardando ancora una volta il piano di 50.000 righe, sembra che il più grande miglioramento trovato dall'ottimizzatore sia quello di utilizzare gli operatori Top (1) invece di leggere tutte le righe e calcolare il valore massimo usando la forza bruta. Cosa succede se proviamo qualcosa di simile e riscriviamo la query utilizzando Top in modo esplicito?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Il piano di esecuzione per la nuova query è:
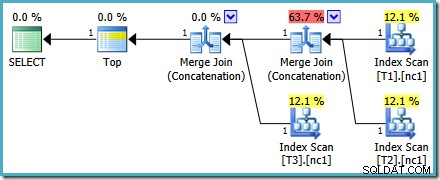
Questo piano è abbastanza diverso da quello scelto dall'ottimizzatore per il MAX interrogazione. È dotato di tre scansioni di indice ordinate, due Merge Join in esecuzione in modalità di concatenazione e un unico operatore Top. Questo nuovo piano di query ha alcune caratteristiche interessanti che vale la pena esaminare un po' in dettaglio.
Analisi del piano
La prima riga (in ordine decrescente di indice) viene letta dall'indice non cluster di ciascuna tabella e viene utilizzato un Merge Join operante in modalità di concatenazione. Sebbene l'operatore Merge Join non esegua un join nel senso normale, l'algoritmo di elaborazione di questo operatore è facilmente adattabile per concatenare i suoi input invece di applicare criteri di join.
Il vantaggio dell'utilizzo di questo operatore nel nuovo piano è che Merge Concatenation conserva l'ordinamento tra i suoi input. Al contrario, un normale operatore di concatenazione legge i suoi input in sequenza. Il diagramma seguente illustra la differenza (clicca per espandere):
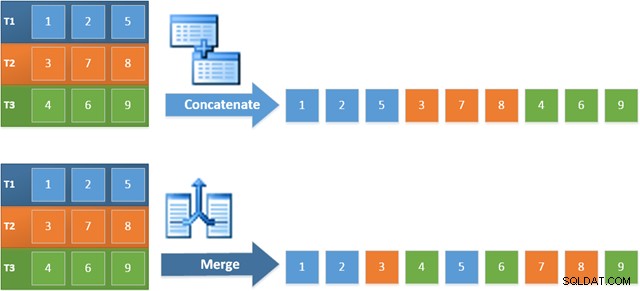
Il comportamento di conservazione dell'ordine di Merge Concatenation significa che la prima riga prodotta dall'operatore Merge più a sinistra nel nuovo piano è garantita come la riga con il valore più alto nella colonna c1 in tutte e tre le tabelle. In particolare, il piano opera come segue:
- Una riga viene letto da ciascuna tabella (in ordine decrescente di indice); e
- Ogni unione esegue un test per vedere quale delle sue righe di input ha il valore più alto
Questa sembra una strategia molto efficiente, quindi potrebbe sembrare strano che l'ottimizzatore sia MAX piano ha un costo stimato inferiore alla metà del nuovo piano. In larga misura, il motivo è che si presume che la concatenazione di unione che preserva l'ordine sia più costosa di una semplice concatenazione. L'ottimizzatore non si rende conto che ogni unione può vedere solo un massimo di una riga e di conseguenza ne sovrastima il costo.
Altri problemi relativi ai costi
A rigor di termini qui non stiamo confrontando mele con mele, perché i due piani riguardano query diverse. Il confronto di costi del genere non è generalmente una cosa valida da fare, sebbene SSMS faccia esattamente questo visualizzando le percentuali di costo per diversi estratti conto in un batch. Ma sto divagando.
Se guardi il nuovo piano in SSMS invece di SQL Sentry Plan Explorer vedrai qualcosa del genere:
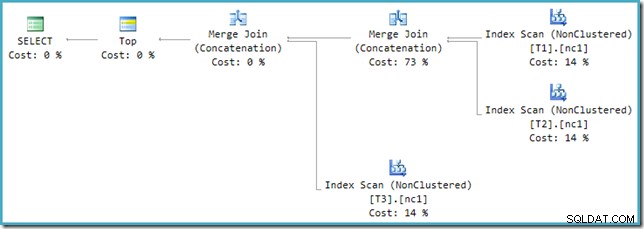
Uno degli operatori Merge Join Concatenation ha un costo stimato del 73% mentre il secondo (che opera esattamente sullo stesso numero di righe) viene mostrato come se non costasse nulla. Un altro segno che qualcosa non va qui è che le percentuali di costo dell'operatore in questo piano non ammontano al 100%.
Ottimizzatore e motore di esecuzione
Il problema risiede in un'incompatibilità tra l'ottimizzatore e il motore di esecuzione. Nell'ottimizzatore, Union e Union All possono avere 2 o più input. Nel motore di esecuzione, solo l'operatore di concatenazione è in grado di accettare 2 o più ingressi; Unisciti richiede esattamente due input, anche se configurato per eseguire una concatenazione anziché un join.
Per risolvere questa incompatibilità, viene applicata una riscrittura post-ottimizzazione per tradurre l'albero di output dell'ottimizzatore in una forma che il motore di esecuzione può gestire. Laddove viene implementata una Union o Union All con più di due input utilizzando Merge, è necessaria una catena di operatori. Con tre input per Union All, nel presente caso, sono necessarie due Merge Unions:
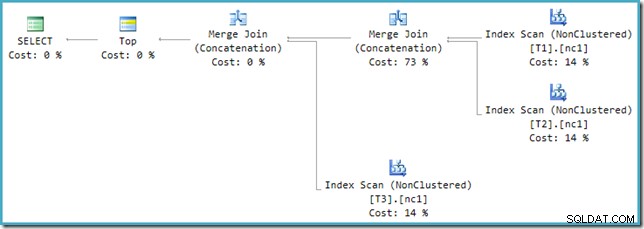
Possiamo vedere l'albero di output dell'ottimizzatore (con tre input per un'unione di unione fisica) usando il flag di traccia 8607:
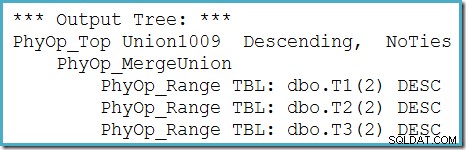
Una correzione incompleta
Sfortunatamente, la riscrittura post-ottimizzazione non è perfettamente implementata. Fa un po' di confusione con i numeri di costo. A parte i problemi di arrotondamento, i costi del piano si sommano al 114% con il 14% aggiuntivo proveniente dall'input alla concatenazione di unisci unisci aggiuntiva generata dalla riscrittura:
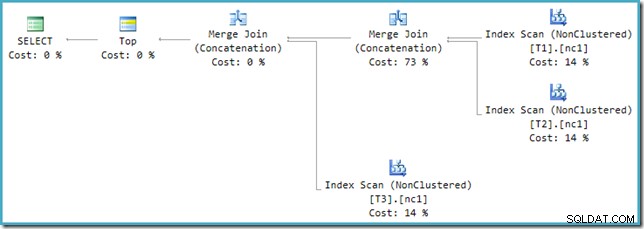
L'unione più a destra in questo piano è l'operatore originale nell'albero di output dell'ottimizzatore. Gli viene assegnato l'intero costo dell'operazione Union All. L'altra unione viene aggiunta dalla riscrittura e riceve un costo zero.
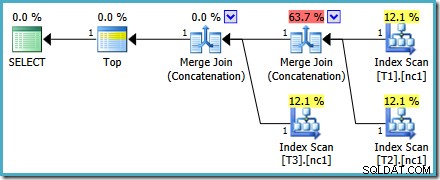
Qualunque sia il modo in cui scegliamo di guardarlo (e ci sono diversi problemi che influenzano la normale concatenazione) i numeri sembrano dispari. Plan Explorer fa del suo meglio per aggirare le informazioni interrotte nel piano XML assicurando almeno che i numeri raggiungano il 100%:
Questo particolare problema relativo ai costi è stato risolto in SQL Server 2014 CTP 1:
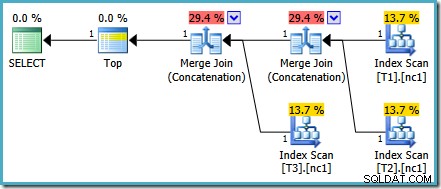
I costi della Merge Concatenation sono ora equamente divisi tra i due operatori e le percentuali si sommano fino al 100%. Poiché l'XML sottostante è stato corretto, anche SSMS riesce a mostrare gli stessi numeri.
Quale piano è migliore?
Se scriviamo la query usando MAX , dobbiamo fare affidamento sull'ottimizzatore che sceglie di eseguire il lavoro extra necessario per trovare un piano efficiente. Se l'ottimizzatore trova un piano apparentemente abbastanza buono all'inizio, può produrre un piano relativamente inefficiente che legge ogni riga da ciascuna delle tabelle di base:
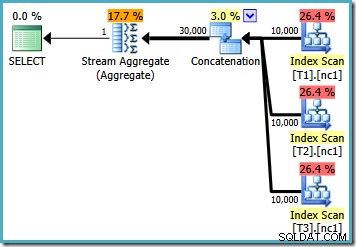
Se si esegue SQL Server 2008 o SQL Server 2008 R2, l'ottimizzatore sceglierà comunque un piano inefficiente indipendentemente dal numero di righe nelle tabelle di base. Il seguente piano è stato prodotto su SQL Server 2008 R2 con 50.000 righe:
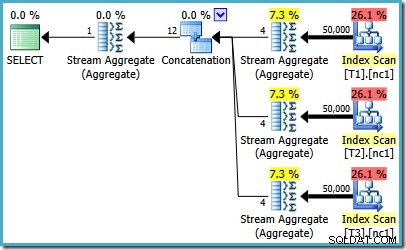
Anche con 50 milioni di righe in ogni tabella, l'ottimizzatore R2 2008 e 2008 aggiunge solo il parallelismo, non introduce gli operatori Top:
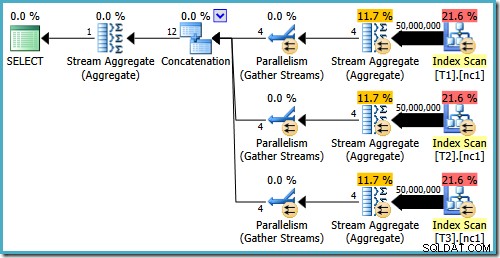
Come accennato nel mio post precedente, è necessario il flag di traccia 4199 per ottenere SQL Server 2008 e 2008 R2 per produrre il piano con i migliori operatori. SQL Server 2005 e 2012 in poi non richiedono il flag di traccia:
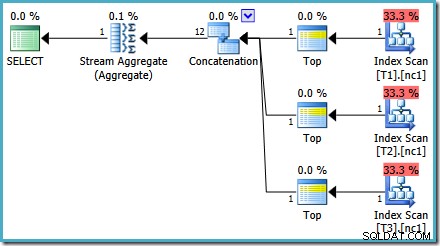
TORNA CON ORDINA PER
Una volta compreso cosa sta succedendo nei piani di esecuzione precedenti, possiamo fare una scelta consapevole (e informata) di riscrivere la query utilizzando un TOP esplicito con ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Il piano di esecuzione risultante potrebbe avere percentuali di costo che sembrano strane in alcune versioni di SQL Server, ma il piano sottostante è valido. La riscrittura post-ottimizzazione che fa sembrare dispari i numeri viene applicata al termine dell'ottimizzazione della query, quindi possiamo essere sicuri che la selezione del piano dell'ottimizzatore non è stata interessata da questo problema.
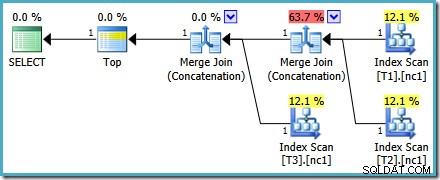
Questo piano non cambia a seconda del numero di righe nella tabella di base e non richiede la generazione di flag di traccia. Un piccolo vantaggio in più è che questo piano viene trovato dall'ottimizzatore durante la prima fase dell'ottimizzazione basata sui costi (ricerca 0):
Il miglior piano selezionato dall'ottimizzatore per il MAX query richiesta l'esecuzione di due fasi di ottimizzazione basata sui costi (cerca 0 e cerca 1).
C'è una piccola differenza semantica tra il TOP query e il MAX originale forma che dovrei citare. Se nessuna delle tabelle contiene una riga, la query originale produrrebbe un singolo NULL risultato. La sostituzione TOP (1) query non produce alcun output nelle stesse circostanze. Questa differenza non è spesso importante nelle query del mondo reale, ma è qualcosa di cui essere consapevoli. Possiamo replicare il comportamento di TOP utilizzando MAX in SQL Server 2008 in poi aggiungendo un set vuoto GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Questa modifica non influisce sui piani di esecuzione generati per MAX interrogare in modo che sia visibile agli utenti finali.
MAX con unisci concatenazione
Dato il successo di Merge Join Concatenation nel TOP (1) piano di esecuzione, è naturale chiedersi se lo stesso piano ottimale possa essere generato per il MAX originale query se forziamo l'ottimizzatore a utilizzare Merge Concatenation invece della normale concatenazione per UNION ALL operazione.
C'è un suggerimento per la query a questo scopo:MERGE UNION – ma purtroppo funziona correttamente solo da SQL Server 2012 in poi. Nelle versioni precedenti, il UNION il suggerimento riguarda solo UNION query, non UNION ALL . Da SQL Server 2012 in poi, possiamo provare questo:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Siamo ricompensati con un piano che include Merge Concatenation. Sfortunatamente, non è proprio tutto ciò che avremmo potuto sperare:
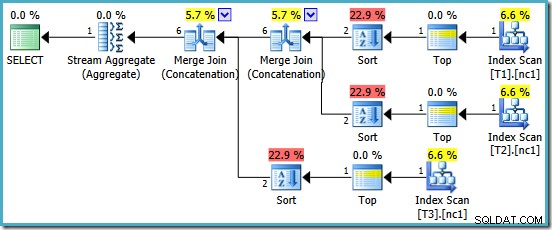
Gli operatori interessanti in questo piano sono i tipi. Si noti la stima della cardinalità di input di 1 riga e la stima di 4 righe dell'output. La causa dovrebbe ormai esserti familiare:è lo stesso errore di stima della cardinalità aggregata parziale di cui abbiamo discusso in precedenza.
La presenza delle specie rivela un altro problema con gli aggregati parziali. Non solo producono una stima della cardinalità errata, ma non riescono anche a preservare l'ordinamento dell'indice che renderebbe l'ordinamento non necessario (la concatenazione di unione richiede input ordinati). Gli aggregati parziali sono MAX scalari aggregati, garantiti per produrre una riga, quindi il problema dell'ordinamento dovrebbe essere comunque discutibile (c'è solo un modo per ordinare una riga!)
Questo è un peccato, perché senza i tipi questo sarebbe un piano di esecuzione decente. Se gli aggregati parziali sono stati implementati correttamente, e il MAX scritto con un GROUP BY () clausola, potremmo anche sperare che l'ottimizzatore possa individuare che i tre Top e lo Stream Aggregate finale potrebbero essere sostituiti da un unico operatore Top finale, fornendo esattamente lo stesso piano dell'esplicito TOP (1) interrogazione. L'ottimizzatore non contiene questa trasformazione oggi e suppongo che non sarebbe utile abbastanza spesso da rendere utile la sua inclusione in futuro.
Le ultime parole
Usando TOP non sarà sempre preferibile a MIN o MAX . In alcuni casi produrrà un piano significativamente meno ottimale. Il punto di questo post è che la comprensione delle trasformazioni applicate dall'ottimizzatore può suggerire modi per riscrivere la query originale che potrebbero rivelarsi utili.



