Molte persone usano le statistiche di attesa come parte della loro metodologia generale di risoluzione dei problemi delle prestazioni, così come me, quindi la domanda che volevo esplorare in questo post riguarda i tipi di attesa associati al sovraccarico dell'osservatore. Per sovraccarico dell'osservatore, intendo l'impatto sul throughput del carico di lavoro di SQL Server causato da SQL Profiler, tracce lato server o sessioni di eventi estesi. Per ulteriori informazioni sull'argomento dell'osservatore dall'alto, vedere i seguenti due post del mio collega Jonathan Kehayias :
- Misurazione del "overhead dell'osservatore" di SQL Trace rispetto agli eventi estesi
- Impatto dell'evento esteso query_post_execution_showplan in SQL Server 2012
Quindi in questo post vorrei esaminare alcune variazioni dell'osservatore sopra la testa e vedere se riusciamo a trovare tipi di attesa coerenti associati al degrado misurato. Esistono diversi modi in cui gli utenti di SQL Server implementano la traccia nei loro ambienti di produzione, quindi i risultati possono variare, ma volevo coprire alcune categorie generali e riferire su ciò che ho trovato:
- Utilizzo della sessione di SQL Profiler
- Utilizzo della traccia lato server
- Utilizzo della traccia lato server, scrittura su un percorso I/O lento
- Utilizzo di eventi estesi con una destinazione buffer ad anello
- Utilizzo di eventi estesi con un file di destinazione
- Utilizzo di eventi estesi con un file di destinazione su un percorso I/O lento
- Utilizzo di eventi estesi con un file di destinazione su un percorso I/O lento senza perdita di eventi
È probabile che tu possa pensare ad altre variazioni sul tema e ti invito a condividere eventuali scoperte interessanti relative al sovraccarico dell'osservatore e ad attendere le statistiche come commento in questo post.
Linea di base
Per il test ho utilizzato una macchina virtuale VMware con quattro vCPU e 4 GB di RAM. Il mio ospite della macchina virtuale era su SSD OCZ Vertex. Il sistema operativo era Windows Server 2008 R2 Enterprise e la versione di SQL Server è 2012, SP1 CU4.
Per quanto riguarda il "carico di lavoro", sto utilizzando una query di sola lettura in loop rispetto al database di esempio del credito 2008, impostato su GO 10.000.000 di volte.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Sto anche eseguendo questa query tramite 16 sessioni simultanee. Il risultato finale sul mio sistema di test è l'utilizzo della CPU al 100% su tutte le vCPU sul guest virtuale e una media di 14.492 richieste batch al secondo in un periodo di 2 minuti.
Per quanto riguarda il tracciamento degli eventi, in ogni test ho utilizzato Showplan XML Statistics Profile per i test di traccia SQL Profiler e lato server e query_post_execution_showplan per le sessioni di eventi estesi. Gli eventi del piano di esecuzione sono molto costosi, motivo per cui li ho scelti in modo da poter vedere se in circostanze estreme potevo ricavare o meno temi di tipo wait.
Per testare l'accumulo del tipo di attesa in un periodo di prova, ho utilizzato la query seguente. Niente di speciale:basta cancellare le statistiche, attendere 2 minuti e quindi raccogliere i primi 10 accumuli di attesa per l'istanza di SQL Server durante il periodo di test di degradazione:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Nota che non lo sono filtrando i tipi di attesa in background che sono generalmente filtrati, e questo perché non volevo eliminare qualcosa che normalmente è benigno, ma in questa circostanza indica effettivamente un'area reale su cui indagare ulteriormente.
Sessione SQL Profiler
La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita un tracciamento di traccia SQL Profiler locale Showplan XML Statistics Profile (in esecuzione sulla stessa macchina virtuale dell'istanza di SQL Server):
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di sessioni di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 1.416 |
È possibile notare che la traccia di SQL Profiler provoca un calo significativo della velocità effettiva.
Per quanto riguarda il tempo di attesa accumulato nello stesso periodo, i principali tipi di attesa erano i seguenti (come per il resto dei test in questo articolo, ho eseguito alcuni test e l'output è stato generalmente coerente):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67.142 | 1.149.824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 313 | 180.449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.086 |
| LAZYWRITER_SLEEP | 120 | 120.059 |
| PAGINA_DIRTY_POLL | 1.198 | 120.038 |
| HADR_WORK_QUEUE | 12 | 120.015 |
| LOGMGR_QUEUE | 937 | 120.011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
Il tipo di attesa che mi viene visualizzato è TRACEWRITE – che è definito dalla documentazione in linea come un tipo di attesa che "si verifica quando il provider di traccia del set di righe di SQL Trace attende un buffer libero o un buffer con eventi da elaborare". Il resto dei tipi di attesa sembrano tipi di attesa in background standard che in genere vengono filtrati dal set di risultati. Inoltre, ho parlato di un problema simile con la traccia eccessiva in un articolo del 2011 intitolato Observer overhead – i pericoli di una traccia eccessiva – quindi avevo familiarità con questo tipo di attesa a volte indicando correttamente i problemi di overhead dell'osservatore. Ora, in quel caso particolare di cui ho parlato nel blog, non era SQL Profiler, ma un'altra applicazione che utilizzava il provider di traccia del set di righe (in modo inefficiente).
Traccia lato server
Era per SQL Profiler, ma per quanto riguarda l'overhead di traccia lato server? La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita una traccia lato server locale che scrive su un file:
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 4.015 |
I principali tipi di attesa erano i seguenti (ho eseguito alcuni test e l'output è stato coerente):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| SLEEP_TASK | 253 | 180.871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.046 |
| HADR_WORK_QUEUE | 12 | 120.042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.021 |
| XE_DISPATCHER_WAIT | 3 | 120.006 |
| ATTENDERE | 1 | 120.000 |
| LOGMGR_QUEUE | 931 | 119.993 |
| PAGINA_DIRTY_POLL | 1.193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Questa volta non vediamo TRACEWRITE (stiamo utilizzando un provider di file ora) e l'altro tipo di attesa relativo alla traccia, il SQLTRACE_INCREMENTAL_FLUSH_SLEEP non documentato è salito – ma rispetto al primo test ha un tempo di attesa accumulato molto simile (120.046 contro 120.006) – e la mia collega Erin Stellato (@erinstellato) ha parlato di questo particolare tipo di attesa nel suo post Capire quando le statistiche di attesa sono state cancellate per l'ultima volta . Quindi, guardando gli altri tipi di attesa, nessuno salta fuori come una bandiera rossa affidabile.
Traccia lato server in scrittura su un percorso I/O lento
Cosa succede se mettiamo il file di traccia lato server su disco lento? La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita una traccia lato server locale che scrive su un file su una chiavetta USB:
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 260 |
Come possiamo vedere – le prestazioni sono notevolmente degradate – anche rispetto al test precedente.
I principali tipi di attesa erano i seguenti:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.273 | 299.995 |
| SLEEP_TASK | 240 | 194.264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181.458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125.007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120.559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120.516 |
| ATTENDERE | 1 | 120.515 |
| PAGINA_DIRTY_POLL | 1.204 | 120.513 |
Un tipo di attesa che salta fuori per questo test è SQLTRACE_FILE_BUFFER non documentato . Non molto documentato su questo, ma in base al nome, possiamo fare un'ipotesi plausibile (soprattutto vista la configurazione di questo particolare test).
Eventi estesi alla destinazione del buffer dell'anello
Quindi esaminiamo i risultati per gli equivalenti della sessione di eventi estesi. Ho usato la seguente definizione di sessione:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita una sessione XE con una destinazione buffer ad anello (catturando il query_post_execution_showplan evento):
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 4.737 |
I principali tipi di attesa erano i seguenti:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299.992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| SLEEP_TASK | 240 | 181.739 |
| LAZYWRITER_SLEEP | 120 | 120.219 |
| HADR_WORK_QUEUE | 12 | 120.038 |
| PAGINA_DIRTY_POLL | 1.198 | 120.035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.011 |
| LOGMGR_QUEUE | 936 | 120.008 |
| ATTENDERE | 1 | 120.001 |
Niente è saltato fuori come "rumore" relativo a XE, solo attività in background.
Eventi estesi a un file di destinazione
Che ne dici di modificare la sessione per utilizzare una destinazione file invece di una destinazione buffer ad anello? La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita una sessione XE con una destinazione file anziché una destinazione buffer ad anello:
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 4.299 |
I principali tipi di attesa erano i seguenti:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.103 | 299.996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 253 | 180.663 |
| LAZYWRITER_SLEEP | 120 | 120.187 |
| HADR_WORK_QUEUE | 12 | 120.029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| ATTENDERE | 1 | 120.001 |
| XE_TIMER_EVENT | 59 | 119.966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Niente, ad eccezione di XE_TIMER_EVENT , è saltato fuori come relativo a XE. Il Wait Type Repository di Bob Ward si riferisce a questo come sicuro da ignorare a meno che non ci sia qualcosa che non va, ma realisticamente noteresti questo tipo di attesa solitamente benigno se fosse al 9 posto sul tuo sistema durante un degrado delle prestazioni? E se lo stai già filtrando a causa della sua natura normalmente benigna?
Eventi estesi a una destinazione file di percorso I/O lenta
Ora cosa succede se metto il file su un percorso di I/O lento? La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita una sessione XE con un file di destinazione su una chiavetta USB:
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 4.386 |
I principali tipi di attesa erano i seguenti:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| SLEEP_TASK | 253 | 180.719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.427 |
| LAZYWRITER_SLEEP | 120 | 120.190 |
| HADR_WORK_QUEUE | 12 | 120.025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| ATTENDERE | 1 | 120.002 |
| PAGINA_DIRTY_POLL | 1.197 | 119.977 |
| XE_TIMER_EVENT | 59 | 119.949 |
Ancora una volta, nulla relativo a XE salta fuori tranne il XE_TIMER_EVENT .
Eventi estesi a un file di destinazione del percorso I/O lento, nessuna perdita di eventi
La tabella seguente mostra le richieste batch prima e dopo al secondo quando si abilita una sessione XE con un file di destinazione su una chiavetta USB, ma questa volta senza consentire la perdita di eventi (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – che non è consigliato e vedrai nei risultati perché potrebbe essere:
| Richieste batch di riferimento al secondo (media di 2 minuti) | Richieste batch di SQL Profiler al secondo (media di 2 minuti) |
|---|---|
| 14.492 | 539 |
I principali tipi di attesa erano i seguenti:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8.773 | 1.707.845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 337 | 180.446 |
| LAZYWRITER_SLEEP | 120 | 120.032 |
| PAGINA_DIRTY_POLL | 1.198 | 120.026 |
| HADR_WORK_QUEUE | 12 | 120.009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
| ATTENDERE | 1 | 120.000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Con l'estrema riduzione del throughput, vediamo XE_BUFFERMGR_FREEBUF_EVENT salta alla posizione numero uno nei risultati del tempo di attesa accumulato. Questo è documentato nella documentazione in linea e Microsoft ci dice che questo evento è associato a sessioni XE configurate per nessuna perdita di eventi e in cui tutti i buffer della sessione sono pieni.
Impatto dell'osservatore
A parte i tipi di attesa, è stato interessante notare quale impatto ha avuto ciascun metodo di osservazione sulla capacità del nostro carico di lavoro di elaborare le richieste batch:
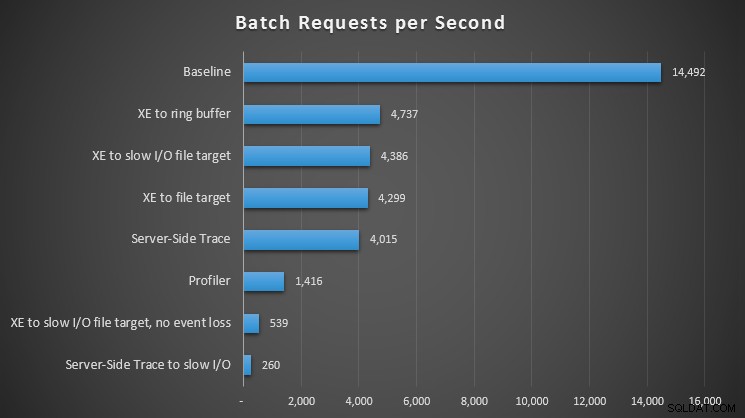
Impatto di diversi metodi di osservazione sulle richieste batch al secondo
Per tutti gli approcci, c'è stato un colpo significativo, ma non scioccante, rispetto alla nostra linea di base (nessuna osservazione); il problema maggiore, tuttavia, è stato avvertito quando si utilizza Profiler, quando si utilizza la traccia lato server su un percorso I/O lento o gli eventi estesi su una destinazione file su un percorso I/O lento, ma solo se configurato per nessuna perdita di eventi. Con la perdita di eventi, questa configurazione ha effettivamente funzionato alla pari con un file di destinazione su un percorso I/O veloce, presumibilmente perché è stato in grado di eliminare molti più eventi.
Riepilogo
Non ho testato tutti gli scenari possibili e ci sono sicuramente altre combinazioni interessanti (per non parlare dei diversi comportamenti basati sulla versione di SQL Server), ma la conclusione chiave che traggo da questa esplorazione è che non puoi sempre fare affidamento su un ovvio accumulo di tipi di attesa puntatore quando ci si trova di fronte a uno scenario dall'alto dell'osservatore. Sulla base dei test in questo post, solo tre scenari su sette hanno manifestato un tipo di attesa specifico che potrebbe potenzialmente aiutarti a indirizzarti nella giusta direzione. Anche allora, questi test erano su un sistema controllato e spesso le persone filtrano i suddetti tipi di attesa come tipi di background benigni, quindi potresti non vederli affatto.
Detto questo, cosa puoi fare? Per un degrado delle prestazioni senza sintomi chiari o evidenti, consiglio di ampliare l'ambito per chiedere informazioni su tracce e sessioni XE (per inciso, consiglio anche di ampliare l'ambito se il sistema è virtualizzato o potrebbe avere opzioni di alimentazione errate). Ad esempio, come parte della risoluzione dei problemi di un sistema, controlla sys.[traces] e sys.[dm_xe_sessions] per vedere se sul sistema è in esecuzione qualcosa di imprevisto. È un livello in più rispetto a ciò di cui devi preoccuparti, ma eseguire alcune rapide convalide potrebbe farti risparmiare una notevole quantità di tempo.