In tutto il mondo, il sito del portale del lavoro è una caratteristica ben nota nel panorama di Internet. Grandi attori come Indeed e Monster hanno trasformato la ricerca di lavoro e il reclutamento in una vera e propria industria online. Analizziamo le funzionalità elementari sfruttate dai portali del lavoro e costruiamo un modello di dati in grado di supportarle.
Le persone amano risparmiare tempo utilizzando le innovazioni tecnologiche; il portale del lavoro online è un'altra versione del lavoro in modo più intelligente, non più difficile. Sia le persone in cerca di lavoro che le aziende si rendono conto del valore di portare la loro ricerca online:ottengono una copertura migliore a velocità più elevate e costi inferiori.
Il settore dei portali di lavoro è ora abbastanza stabilizzato, almeno per quanto riguarda i volumi di traffico. I cercatori di lavoro utilizzano questi portali per trovare posizioni in molti settori, passando dall'IT a settori come l'ingegneria, le vendite, la produzione e i servizi finanziari. Tuttavia, stanno subendo una forte concorrenza dai social media e dai siti di networking professionali come LinkedIn. Ma ci sono ancora opportunità da esplorare, come espandere la loro penetrazione nelle aree rurali e nelle città più piccole.
Quindi, come abbiamo detto, esploreremo questo argomento dal punto di vista della progettazione del database. Cominciamo con l'enumerare le aspettative fondamentali per un portale del lavoro.
Cosa si aspettano le persone da un portale di lavoro online?
Sia i datori di lavoro che le persone in cerca di lavoro si aspettano le seguenti funzionalità da un sito di lavoro online:
- Le persone possono registrarsi come persone in cerca di lavoro, creare i propri profili e cercare un lavoro che corrisponda alle proprie competenze.
- Gli utenti possono caricare i propri curriculum esistenti. Se non ne hanno uno, dovrebbero essere in grado di compilare un modulo e avere un curriculum creato per loro.
- Le persone possono candidarsi direttamente ai lavori pubblicati.
- Le aziende possono registrarsi, pubblicare offerte di lavoro e cercare profili di persone in cerca di lavoro.
- Più rappresentanti di un'azienda dovrebbero essere in grado di registrarsi e pubblicare offerte di lavoro.
- I rappresentanti dell'azienda possono visualizzare un elenco di candidati al lavoro e contattarli, avviare un colloquio o eseguire altre azioni relative al loro posto.
- Gli utenti registrati dovrebbero essere in grado di cercare lavoro e filtrare i risultati in base a posizione, competenze richieste, stipendio, livello di esperienza, ecc.
Costruzione del modello di dati
Dopo aver considerato i requisiti di cui sopra, ho trovato tre grandi categorie funzionali:
- Gestione degli utenti – Come il portale gestisce gli utenti, ovvero persone in cerca di lavoro, personale delle risorse umane e reclutatori indipendenti o di consulenza. (Ai fini di questo modello, i singoli rappresentanti delle risorse umane e i reclutatori indipendenti o consulenti sono trattati come aziende, almeno in termini di modalità di utilizzo del portale.)
- Profili di costruzione – In che modo il portale consente alle persone in cerca di lavoro e alle organizzazioni di creare profili e curricula.
- Pubblicazione e ricerca di lavori – In che modo il portale facilita il processo di pubblicazione, ricerca e richiesta di lavoro.
Diamo un'occhiata a ciascuna di queste aree separatamente.
1. Gestione degli utenti
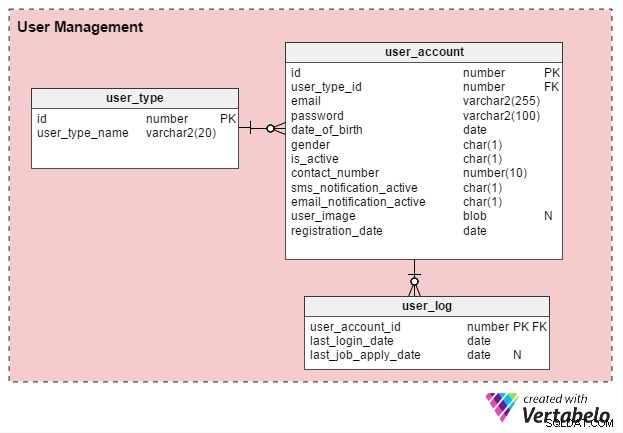
Esistono principalmente due tipi di utenti del portale del lavoro online:i singoli in cerca di lavoro e i reclutatori delle risorse umane (o consulenti di reclutamento indipendenti). Creiamo una tabella denominata user_type per memorizzare questi record. Per iniziare, avrà due record:uno per i cercatori di lavoro e un altro per i reclutatori. (Possiamo sempre creare tipi di record aggiuntivi secondo necessità.)
Gli utenti sono tenuti a registrarsi prima di poter utilizzare il portale. Il user_account la tabella memorizza i dettagli dell'account di base. In precedenza ho pensato di nominare questa tabella "utente", ma poiché user è una parola chiave definita dal sistema in quasi tutti i database, preferisco restare con "user_account".
Il user_account tabella ha le seguenti colonne:
- id – Questa è sia la chiave primaria della tabella che un identificatore univoco per ciascun utente. Questo ID sarà indicato da altre tabelle nel modello di dati.
- id_tipo_utente – Indica se l'utente è in cerca di lavoro o reclutatore.
- e-mail – Questa colonna contiene l'indirizzo email dell'utente. Agisce come un altro ID utente per il portale.
- password – Questo memorizza una password dell'account crittografata (creata dagli utenti durante la registrazione).
- data_di_nascita e genere – Come suggeriscono i loro nomi, queste colonne contengono la data di nascita e il sesso degli utenti.
- è_attivo – Inizialmente questa colonna sarebbe "Y", ma gli utenti possono impostare il proprio profilo su inattivo o "N". Questa colonna memorizza la loro scelta.
- numero_contatto – Questo è il numero di telefono (solitamente mobile) fornito in fase di registrazione. Gli utenti possono ricevere notifiche SMS (di testo) su questo numero. Può essere lo stesso numero (o meno) di una persona in cerca di lavoro elencata nel proprio profilo o curriculum.
- sms_notification_active e email_notification_active – Queste colonne memorizzano le preferenze degli utenti relative alla ricezione di notifiche tramite SMS e/o e-mail.
- immagine_utente – Questo è un attributo di tipo BLOB che memorizza l'immagine del profilo di ciascun utente. Poiché questo portale consente solo un'immagine del profilo per utente, ha senso salvarla qui.
- data_di_registrazione – Questa colonna conserva un record di quando l'utente si è registrato al portale.
Creeremo un'altra tabella, user_log , che memorizza un record della data dell'ultimo accesso degli utenti e della data dell'ultima domanda di lavoro. Ci sono molte funzionalità che possono essere costruite da questa conoscenza. Ad esempio, possiamo utilizzare queste informazioni per rispondere alla domanda L'utente X sta cercando attivamente un lavoro ? In tal caso, può essere offerto loro un prodotto per creare un curriculum efficace. Gli utenti che non cercano attivamente un lavoro non riceverebbero un'offerta del genere.
2. Profili di costruzione
Possiamo dividere ulteriormente questa sezione in due aree:profili aziendali o organizzativi e profili in cerca di lavoro.
Profili aziendali
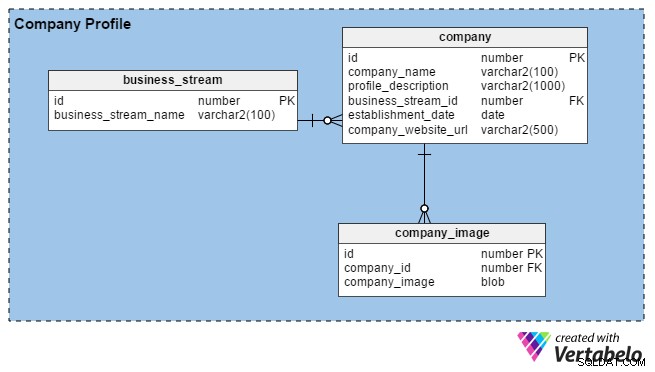
Di solito i team delle risorse umane costruiscono profili aziendali inserendo dettagli sulla loro organizzazione e immagini dei loro uffici, edifici, ecc. Il loro obiettivo principale è attirare buoni talenti. Quando i reclutatori si registrano al portale, anche loro possono costruire profili delle loro aziende (o del loro marchio personale, se sono indipendenti) fornendo alcuni dettagli di base come da quanto tempo sono in attività, la loro posizione e il loro flusso di affari principale ( es. manifatturiero, servizi IT, finanziari, ecc.).
Il portale consente alle risorse umane e ai reclutatori di consulenza di caricare tutte le immagini che desiderano (al contrario delle persone in cerca di lavoro, che possono caricarne solo una). Pertanto, abbiamo creato il company_image tabella per memorizzare più immagini per ciascun account reclutatore. L'company_id colonna in questa tabella è una chiave esterna che fa riferimento all'identificatore univoco utilizzato nella company tabella.
Nella company tabella, abbiamo le seguenti colonne:
- id – La chiave primaria di questa tabella viene utilizzata anche per identificare in modo univoco le aziende.
- nome_azienda – Come suggerisce il nome della colonna, contiene il nome legale di un'azienda.
- descrizione_profilo – Contiene una breve descrizione di ciascuna azienda.
- business_stream_id – Questa colonna descrive a quale flusso di affari appartiene un'azienda. Ad esempio, una società di esplorazione di petrolio e gas può assumere ingegneri IT , ma il loro flusso di affari principale rimane "petrolio e gas".
- data_di_istituzione – Questa colonna indica quanti anni ha un'azienda.
- URL_sito_web_azienda – Questa è una colonna obbligatoria (non annullabile). Contiene un puntatore al sito Web ufficiale dell'azienda in modo che chi cerca lavoro possa trovare maggiori informazioni.
Infine, il business_stream table ha solo due attributi, un id che è la chiave primaria per questa tabella e una descrizione del flusso di affari principale dell'azienda (business_stream_name ).
Profili in cerca di lavoro
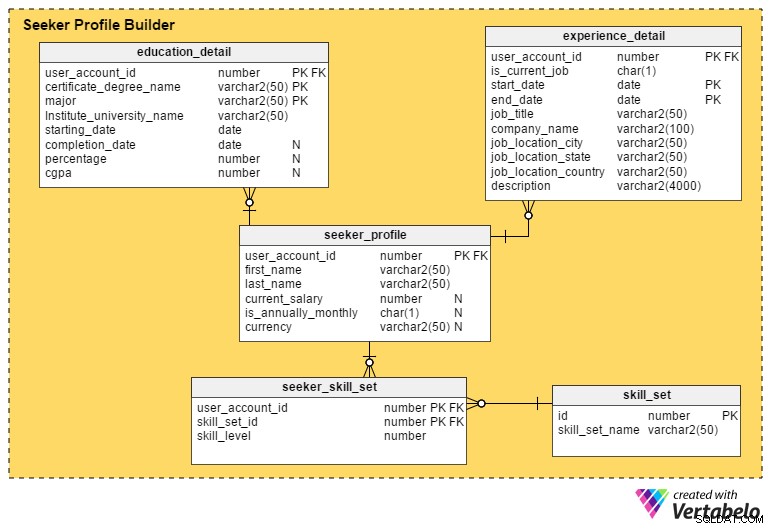
Questa è la sezione più critica di un portale del lavoro. A meno che un portale non acquisisca il maggior numero possibile di dettagli dalle persone in cerca di lavoro, è difficile per i reclutatori selezionare i profili oi candidati.
Il seeker_profile la tabella contiene dettagli aggiuntivi che non sono stati acquisiti durante il processo di registrazione. Contiene questi campi:
- id_account_utente – Questa colonna è referenziata da
user_accounttabella e funge da chiave primaria per questa tabella. Garantisce che ci sarà un massimo di un profilo per persona in cerca di lavoro. - nome e cognome – Come suggeriscono i nomi, queste colonne contengono il nome e il cognome della persona in cerca di lavoro.
- salario_corrente – Questo attributo contiene lo stipendio attuale della persona in cerca di lavoro. È nullable perché le persone potrebbero non volerlo rivelare.
- è_annualmente_mensile – Definisce se l'importo del loro stipendio è annuale o mensile.
- valuta – Memorizza la valuta dello stipendio.
Il education_detail la tabella memorizza la storia educativa di ogni persona in cerca di lavoro, come fornita da loro. Ha una chiave primaria composita composta da user_account_id , nome_laurea_certificato e principali colonne. Ciò garantisce che gli utenti inseriscano solo uno record per ogni laurea o certificato. La tabella contiene questi attributi:
- id_account_utente – Questa colonna è referenziata da
user_accounttabella e funge da chiave primaria per questa tabella. - nome_laurea_certificato – Questo è il tipo di certificato o laurea; per esempio. diploma di scuola superiore, secondaria superiore, laurea, post-laurea o professionale.
- importante – Questa colonna contiene il corso di studi principale per il certificato o la laurea – ad es. una laurea con una specializzazione in informatica.
- nome_istituto_università – Questo è l'istituto, la scuola o l'università che ha rilasciato la laurea o il certificato.
- data_inizio – Questo attributo memorizza la data in cui l'utente è stato accettato in un programma educativo.
- data_di_completamento – Questa è la data in cui è stato rilasciato il titolo o il certificato. Tuttavia, questo attributo è annullabile; le persone potrebbero ancora completare il programma mentre cercano un lavoro o potrebbero aver abbandonato del tutto il programma.
- percentuale e cgpa – Queste colonne memorizzano la percentuale di voto o CGPA (media cumulativa dei voti) raggiunta dagli utenti nel corso di laurea o certificato.
Il experience_detail la tabella registra l'esperienza professionale passata e attuale degli utenti. Contiene le seguenti colonne importanti:
- id_account_utente – Questa colonna è referenziata da
user_accounttable ed è la chiave primaria per questa tabella. - è_corrente_lavoro – Questa è una colonna di indicatore che indica il lavoro corrente dell'utente. Questa colonna svolge anche un ruolo importante nel ricavare le posizioni attuali degli utenti e per quanto tempo hanno mantenuto la loro posizione attuale.
- data_inizio – Memorizza quando un utente avvia un lavoro.
- data_fine – Memorizza quando un utente termina un lavoro.
- job_title:contiene informazioni sul ruolo lavorativo dell'utente.
- nome_azienda – Questo attributo contiene il nome dell'azienda pertinente associato a un lavoro.
- job_location_city – Indica la città in cui si trovava il lavoro.
- job_location_state – Indica lo stato in cui si trovava il lavoro.
- posto_lavoro_paese – Indica il paese in cui si trovava il lavoro.
- descrizione – Questa colonna memorizza i dettagli sui ruoli e le responsabilità lavorative, le sfide e i risultati raggiunti.
Le persone in cerca di lavoro possono possedere molteplici abilità. Per tenere traccia di tutti questi set di abilità, creeremo la tabella seeker_skill_set . Le colonne sono:
- id_account_utente – Questa colonna è referenziata da
user_accounttable ed è la chiave primaria per questa tabella. - skill_set_id – Questo ID indica quale set di abilità possiede l'utente.
- livello di abilità – Questo attributo numerico quantifica l'esperienza di chi cerca lavoro in una particolare abilità. Un numero da 1 (principiante) a 10 (esperto) indica il loro livello di esperienza.
Infine, il skill_set la tabella contiene le descrizioni di tutte le abilità a cui si fa riferimento nel skill_set_id della tabella sopra attributo. Contiene solo due colonne, un skill_set_name e il relativo id .
3. Pubblicazione e ricerca di lavori
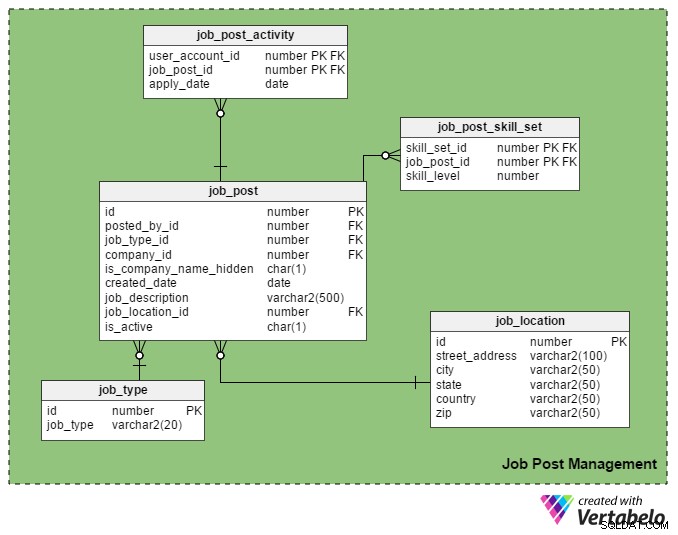
Questo è il principale USP (Unique Selling Point) di un portale di lavoro. Solo i reclutatori registrati possono pubblicare un lavoro sul portale e solo i cercatori di lavoro registrati possono candidarsi.
Il job_post table è la tabella principale in questa area tematica. Come puoi immaginare, contiene dettagli sui posti di lavoro. Tutte le altre tabelle in questa sezione vengono create attorno ad esso e collegate ad esso.
- id – Questa è la chiave primaria di questa tabella. A ogni posto di lavoro viene assegnato un numero univoco, a cui si fa riferimento in altre tabelle.
- posted_by_id – Questa colonna contiene il register_user_id del recruiter che ha pubblicato il lavoro.
- job_type_id – Questa colonna indica se la durata del lavoro è permanente o temporanea (contratto).
- ID_azienda – Questa colonna memorizza l'ID dell'azienda correlata al post di lavoro. È un riferimento alla
companytabella. - è_nome_azienda_nascosto – Questa è una colonna flag che mostra se il nome dell'azienda deve essere mostrato alle persone in cerca di lavoro. I reclutatori potrebbero preferire non mostrare i nomi delle aziende sui loro post. Usano invece termini come "Compagnia automobilistica globale", "Società IT con sede in California" e così via.
- data_creata – Memorizza la data di pubblicazione del lavoro.
- job_description – Contiene una breve descrizione del lavoro.
- job_location_id – Si riferisce a un attributo in
job_locationtabella che memorizza la posizione effettiva del lavoro:indirizzo, città, provincia, paese e codice postale. - è_attivo – Questo significa se un lavoro è ancora aperto. I reclutatori possono contrassegnare i loro post inattivi non appena le posizioni sono occupate.
Il job_post_skill_set la tabella memorizza i dettagli sui set di abilità richiesti per un lavoro. La struttura della tabella è identica al seeker_skill_set tavolo.
E l'ultima tabella in questa sezione, il job_post_activity tabella, contiene i dettagli su quali persone in cerca di lavoro si candidano per un lavoro e quando.
Cosa aggiungeresti a questo modello di dati del portale di lavoro online?
I portali di lavoro online di oggi non si limitano a fornire una piattaforma per pubblicare e candidarsi per lavori. Spesso includono altri servizi professionali come:
- Una dashboard personale per tenere traccia delle domande di lavoro
- Aggiornamenti in tempo reale sulle applicazioni
- Costruttori di curriculum video
- Servizi esperti di scrittura di curriculum
- LinkedIn o altri creatori di profili di social media
- Rapporti sugli stipendi per ruoli professionali, aziende, settori o località geografiche
Se volessimo integrare queste funzionalità nel nostro sistema, quali modifiche aggiuntive dovremmo apportare? Riuscite a pensare ad altri must-have in un portale di lavoro?
Fateci sapere le vostre opinioni nella sezione commenti.



