In questa era di forte concorrenza, i portali del lavoro non sono solo piattaforme per pubblicare e trovare lavoro. Stanno sfruttando servizi e funzionalità avanzati per mantenere coinvolti i loro clienti. Analizziamo alcune funzionalità avanzate e costruiamo un modello di dati in grado di gestirle.
Ho spiegato le funzionalità di base necessarie per un sito Web del portale del lavoro in un articolo precedente. Il modello è mostrato di seguito. Considereremo questo modello come base, che cambieremo per soddisfare i nuovi requisiti. Per prima cosa, consideriamo quali dovrebbero essere questi requisiti (o miglioramenti).
Cosa stiamo aggiungendo al modello di dati del portale di lavoro online?
In breve, aggiungeremo quattro miglioramenti al nostro precedente modello di dati:
- Un dashboard personale per chi cerca lavoro. Questo tiene traccia di tutte le loro domande di lavoro e fornisce aggiornamenti in tempo reale su eventuali modifiche di stato (ad esempio, una domanda cambia da ricevere a essere esaminata).
- Un dashboard del profilo. Indica in dettaglio chi sta visitando il profilo di una persona in cerca di lavoro e quante volte il suo curriculum è stato scaricato nell'ultimo giorno, settimana o mese.
- Gestione dei servizi a pagamento. I portali del lavoro offrono spesso servizi come la preparazione di curriculum da parte di esperti, la gestione dei profili social, la consulenza professionale, ecc. Le nostre nuove funzionalità saranno in grado di supportare le offerte a pagamento.
- Gestione modulo pre-domanda. Quando i candidati presentano una domanda di lavoro, è possibile che venga loro chiesto di compilare un breve questionario relativo a orari di lavoro, luoghi e controlli dei precedenti. Costruiremo in modo che questo modulo possa essere personalizzato dai reclutatori e che le domande e le risposte vengano acquisite dal sistema.
Miglioramento n. 1:dashboard personale
Domande a cui rispondere: Qual è lo stato attuale di una domanda inviata? È nella rosa dei candidati per un colloquio? È già stato visualizzato?
Possiamo tenere traccia delle domande di lavoro inserendo il job_application_status_id colonna nella job_post_activity tavolo. Questa colonna contiene lo stato corrente di una domanda di lavoro. Dobbiamo creare un'altra tabella, job_application_status , per mantenere tutti i possibili stati dell'applicazione. Alcuni stati potrebbero essere "inviato", "in corso di revisione", "archiviato", "rifiutato", "selezionato per il colloquio", "in corso di assunzione" e così via.
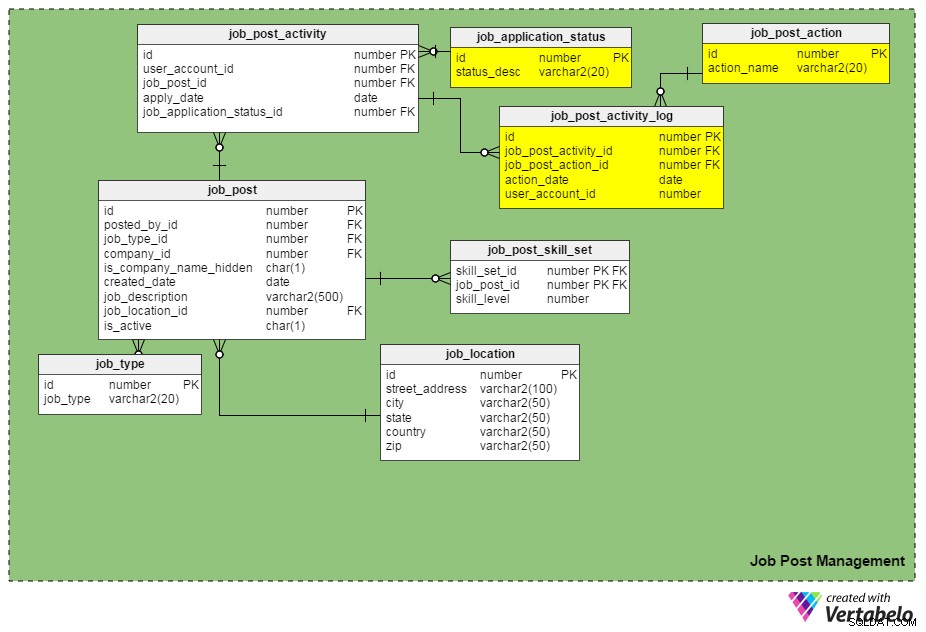
Un'altra nuova tabella, job_post_activity_log , memorizza le informazioni relative a tutte le azioni eseguite sulle domande di lavoro, chi ha eseguito l'azione e quando è stata eseguita. Questa tabella contiene le seguenti colonne:
id– La chiave primaria della tabella.job_post_activity_id– L'ID applicazione su cui viene eseguita l'azione.job_post_action_id– L'ID dell'azione eseguita. Questa è una chiave esterna che si collega ajob_post_actiontavolo. I tipi di azioni che potremmo memorizzare qui includono "inviato", "visualizzato", "intervistato", "test scritto sostenuto", "offerta in corso", "offerta inviata", "offerta accettata", ecc.action_date– La data in cui è stata eseguita un'azione.user_account_id– L'ID della persona che ha eseguito l'azione.
"job_post_action" è identico a "job_application_status"? In che modo sono diversi?
All'inizio sembrano identici, ma in realtà sono diversi. Ci sono validi motivi per cui abbiamo bisogno di due campi simili:
- Un candidato viene intervistato da due o più persone separatamente. In questo caso, lo stato della domanda di lavoro rimane lo stesso (ovvero "in fase di assunzione") fino al completamento di tutte le fasi del colloquio. Tuttavia, i record per ogni singolo intervistatore vengono inseriti nel
job_post_activity_logtabella e hanno l'azione "intervistato". - Una candidatura può essere visualizzata da più reclutatori nella stessa azienda. Utilizzando questi due attributi, non perderai le informazioni di un richiedente.
- La presentazione di un'offerta a un candidato selezionato è soggetta a più approvazioni (vale a dire l'approvazione del team finanziario, l'approvazione del responsabile del dipartimento di assunzione e così via). In questo caso, lo stato di una domanda di lavoro rimane "offerta in corso di revisione", ma il database può registrare quali approvazioni sono arrivate e quali no tramite il
job_post_activity_logtabella.
Miglioramento n. 2:una dashboard del profilo
Domande a cui rispondere: Chi ha trovato il mio profilo di recente? Quante volte è stato visualizzato dai reclutatori nell'ultimo mese, settimana o giorno? I reclutatori delle migliori aziende hanno guardato il mio profilo?
Le risposte a tutte queste domande sono nel profile_visit_log tavolo. Questa tabella acquisisce tutti i dati sulle visite al profilo, inclusi chi ha visitato un profilo, quando è stato visualizzato e così via. Le colonne di questa tabella sono:
id– La chiave primaria della tabella.seeker_profile_id– Quale profilo è stato visitato.visit_date– Quando è stato effettuato l'accesso al profilo.user_account_id– Chi ha visto il profilo.is_resume_downloaded– Una colonna flag che denota se il relativo curriculum è stato scaricato durante la visita. Questa colonna ci aiuterà a ricavare quante volte un curriculum viene scaricato dai reclutatori.is_job_notification_sent– Un'altra colonna flag, questa che indica se una notifica di lavoro è stata inviata al proprietario del profilo.
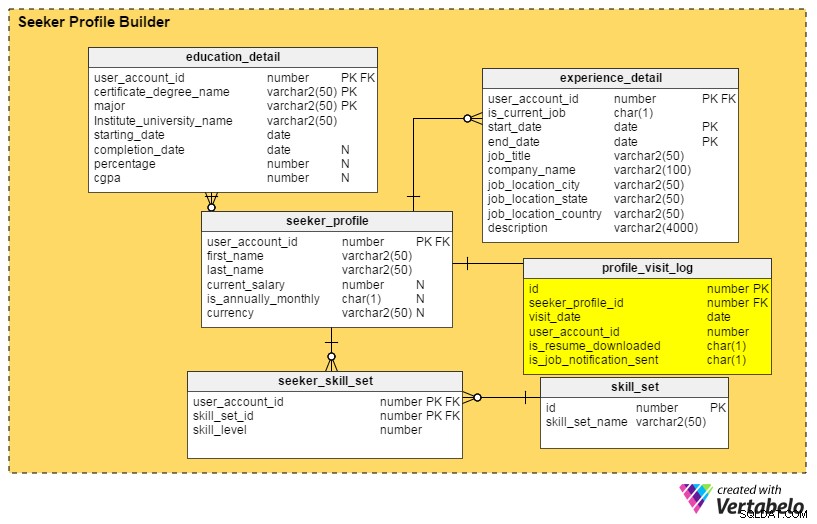
Miglioramento n. 3:gestione dei servizi a pagamento
Domanda a cui rispondere: In che modo i portali online possono sfruttare servizi aggiuntivi a pagamento?
Oltre a una piattaforma per la pubblicazione e la ricerca di lavoro, molti portali online forniscono altri servizi, come la creazione di curriculum di esperti, la consulenza professionale, ecc. Offrono anche prodotti per aiutare le persone in cerca di lavoro a trovare il lavoro dei loro sogni nella città dei loro sogni. Ad esempio, uno dei principali siti di lavoro offre un prodotto che mantiene il tuo profilo in cima agli elenchi dei reclutatori in modo da poter ottenere più offerte di interviste. La maggior parte di questi prodotti o servizi è disponibile su abbonamento. Quando un utente acquista un servizio o prodotto, paga in un periodo di tempo specifico (ad esempio un mese, tre mesi, un anno) per l'utilizzo di quel prodotto o servizio.
Guardando questi portali di lavoro, ho notato che quasi nessun prodotto o servizio viene offerto singolarmente. Per la maggior parte, più prodotti e servizi sono raggruppati in un pacchetto e questo pacchetto viene offerto a persone in cerca di lavoro o reclutatori.
Tenendo conto di tutti questi punti, ho creato il seguente modello di dati per incorporare servizi e prodotti a pagamento nel nostro sito di lavoro online esistente:
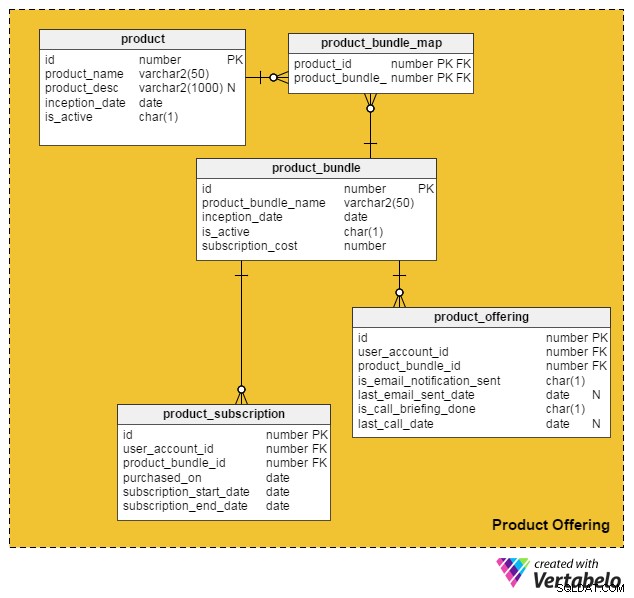
Il product la tabella contiene i dettagli sui singoli prodotti. (Ci riferiremo sia ai prodotti che ai servizi come "prodotti"). Le colonne di questa tabella sono:
id– La chiave primaria di questa tabella, che fornisce un ID univoco a ciascun prodotto offerto sul nostro portale.product_name– Contiene il nome del prodotto.product_desc– Memorizza una breve descrizione del prodotto.inception_date– La data di introduzione di un prodotto.is_active– Se un prodotto è attivo o meno.
Poiché i prodotti e i servizi possono essere riuniti in un pacchetto e offerti ai clienti, ho creato il product_bundle tabella per memorizzare i record di tutti questi bundle. Gli attributi sono:
id– La chiave primaria della tabella, che fornisce un ID univoco per ogni pacchetto di prodotti.product_bundle_name– Memorizza il nome del pacchetto.inception_date– La data di introduzione del pacchetto.is_active– Indica se un pacchetto è attivo o meno.subscription_cost– Memorizza il prezzo richiesto per il bundle.
È possibile offrire un singolo prodotto ai clienti?
Sì. In questo modello di dati, un singolo prodotto può essere il proprio "bundle". Le tabelle seguenti gestiscono questa e alcune altre importanti funzionalità.
La product_bundle_map table memorizza un elenco di tutti i prodotti che fanno parte di un bundle. I suoi attributi sono autoesplicativi.
La tabella successiva, product_subscription , entra in gioco quando i clienti si iscrivono ai pacchetti di prodotti. Registra i dettagli di quali clienti hanno registrato su quali bundle. Le colonne di questa tabella sono:
id– La chiave primaria della tabella.user_account_id– L'utente che ha acquistato il pacchetto.product_bundle_id– Il pacchetto di prodotti acquistato dall'utente.purchased_on– La data di acquisto.subscription_start_date– La data di inizio dell'abbonamento. Tieni presente che la data di acquisto del prodotto e la data di inizio dell'abbonamento potrebbero differire. Pertanto, abbiamo due colonne diverse per questi.subscription_end_date– Al termine dell'abbonamento.
Il tavolo finale, product_offering , è utilizzato principalmente per il marketing. Di solito i portali di lavoro analizzano le attività recenti degli utenti (sia in cerca di lavoro che reclutatori) e quindi decidono quali prodotti saranno vantaggiosi per quali utenti. Quindi utilizzano e-mail o telefonate per contattare i clienti con offerte selezionate. Le colonne di questa tabella sono:
id– La chiave primaria della tabella.user_account_id– L'utente a cui si rivolge il portale del lavoro.product_bundle_id– Il pacchetto di prodotti che i marketer del portale hanno abbinato all'utente.is_email_notification_sent– Se è stata inviata un'e-mail relativa all'offerta del prodotto.last_email_sent_date– Quando l'utente ha ricevuto l'ultima volta un'e-mail di prodotto dal team di marketing. È comune per gli esperti di marketing inviare più notifiche a un utente e inviare altre notifiche periodicamente. Questa colonna memorizza la data in cui è stata inviata l'ultima notifica.is_call_briefing_done– Se il cliente ha ricevuto una telefonata che lo informava su un prodotto.last_call_date–La data dell'ultima telefonata. Possono essere effettuate più chiamate (chiamate di follow-up) ai clienti.
Miglioramento n. 4:gestione dei moduli pre-domanda
Domanda a cui rispondere: Come può un recruiter ottenere un modulo di consenso personalizzato compilato da tutti i potenziali candidati?
Molte volte, le persone in cerca di lavoro rispondono a domande specifiche mentre fanno domanda per un posto. Ciò include comunemente cose come il consenso a un controllo dei precedenti penali. Tuttavia, ci sono vari altri tipi di consensi che potrebbero essere necessari. Ad esempio, un lavoro nel marketing può richiedere molti viaggi; i lavori in Business Process Outsourcing (BPO) possono richiedere ai dipendenti di lavorare in turni cimiteriali (cioè a tarda notte). Questi sono affrontati nei moduli di pre-domanda.
È sempre meglio ottenere il consenso quando viene presentata la domanda di lavoro. In questo modo, i candidati che non sono disposti a soddisfare questi requisiti non si candidano al lavoro.
Prima di passare al modello di dati, consentitemi di evidenziare alcuni fatti di base sui moduli di consenso:
- Un annuncio di lavoro può avere più di un modulo di consenso.
- Ogni modulo di consenso contiene varie domande associate a varie sezioni.
- Una domanda può essere impostata come obbligatoria o facoltativa, a seconda di come la domanda è contrassegnata nel modulo. Una domanda può essere facoltativa in una forma e obbligatoria in un'altra.
- Ogni domanda può essere risolta come (1) sì, (2) no o (3) non applicabile.
- Tutte le risposte verranno registrate.
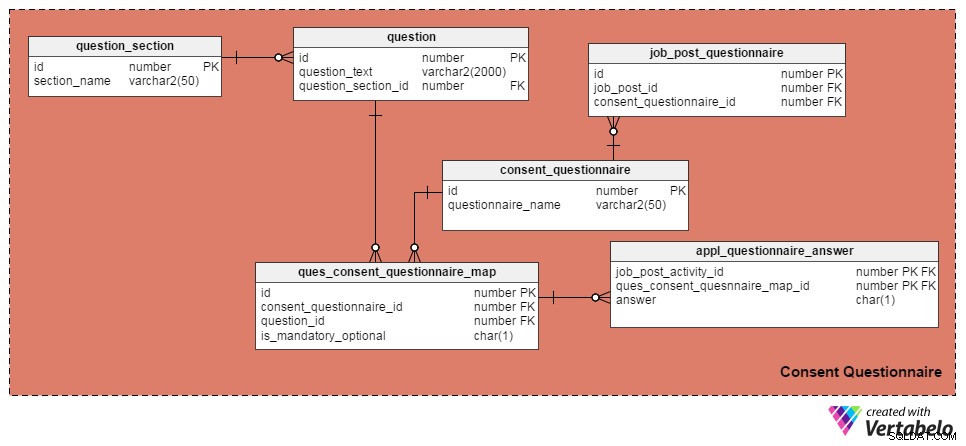
Ho utilizzato le seguenti quattro tabelle per gestire le domande e i moduli di consenso. La prima, la question tabella, contiene un elenco di domande. Ha questi attributi:
id– La chiave primaria della tabella, che assegna un numero ID univoco a ciascuna domanda.question_text– Memorizza il testo effettivo della domanda.question_section_id– La sezione in cui compare la domanda. (Ad es. "Hai lavorato nello sviluppo di software per almeno cinque anni?" apparirà nella sezione "Esperienza lavorativa".) Questa è una colonna di chiave esterna a cui si fa riferimento daquestion_sectiontabella.
La question_section la tabella memorizza le informazioni sulla sezione. È un modo per raggruppare domande relative allo stesso argomento. A parte l'id attributo, che è la chiave primaria per la tabella, l'unico attributo è section_name , che si spiega da sé.
Il consent_questionnaire la tabella contiene i nomi dei moduli di consenso. Anche i suoi due attributi sono autoesplicativi.
Il ques_consent_questionnaire_map tabella è il fulcro di questa area tematica. Tutte le altre tabelle in questa area tematica sono direttamente o indirettamente collegate ad essa. Il suo scopo è quello di mantenere un elenco di domande taggate nei moduli di consenso. Le colonne di questa tabella sono:
id– La chiave primaria di questa tabella.consent_questionnaire_id– Il numero ID del modulo di consenso.question_id– Il numero ID della domanda.is_mandatory_optional– Indica se la domanda è obbligatoria o facoltativa per un determinato modulo di consenso. Una domanda può essere parte di più moduli di consenso, ma può essere obbligatoria in alcuni e facoltativa in altri. Questo è l'unico motivo per mantenere questa colonna qui invece di averla nellaquestiontabella.
Nelle prossime tabelle parleremo dei moduli per il consenso ai tag per i singoli annunci di lavoro e registreremo le risposte dei candidati. Iniziamo con il job_post_questionnaire tabella, che memorizza informazioni su quali moduli di consenso fanno parte di un annuncio di lavoro. Possono esserci uno o più moduli di consenso taggati con un annuncio di lavoro. Le colonne di questa tabella sono:
id– La chiave primaria della tabella.job_post_id– Indica con quale post di lavoro è contrassegnato il modulo di consenso.consent_questionnaire_id– Il modulo di consenso taggato in un post di lavoro.
Successivamente, il appl_questionnaire_answer tabella registra le singole risposte a ciascuna domanda del modulo di consenso compilate dai richiedenti. Le colonne di questa tabella sono:
job_post_activity_id– Una colonna di chiave esterna a cui si fa riferimento dajob_post_activitytavolo. Memorizza le informazioni sul candidato che ha risposto alla domanda.quest_consent_quesnnaire_map_id– Un'altra colonna di chiave esterna a cui si fa riferimento daquest_consent_questionnaire_maptavolo. Memorizza a quale domanda da quale modulo di consenso viene data risposta.answer– La risposta effettiva del candidato al lavoro. L'ho tenuta come colonna CHAR(1) perché tutte le domande nel nostro modello possono essere risolte come 'Sì' (risposta ='Y'), 'No' (risposta ='N') o 'Non applicabile' (risposta ='X').
Il nuovo e migliorato modello di dati del portale del lavoro online
Puoi vedere il modello di dati completato di seguito.
Cosa aggiungeresti?
Riuscite a pensare ad altre funzionalità da aggiungere al nostro portale per il lavoro online? Per favore condividi le tue opinioni nella sezione commenti.