Prima di tentare di eseguire qualsiasi modifica dello schema sui database di produzione, è necessario assicurarsi di disporre di un solido piano di rollback; e che la procedura di modifica è stata testata e convalidata con successo in un ambiente separato. Allo stesso tempo, è tua responsabilità assicurarti che il cambiamento non causi alcun impatto o il minimo possibile accettabile per l'azienda. Non è sicuramente un compito facile.
In questo articolo, daremo un'occhiata a come eseguire modifiche al database su MySQL e MariaDB in modo controllato. Parleremo di alcune buone abitudini nel tuo lavoro DBA quotidiano. Ci concentreremo sui prerequisiti e sulle attività durante le operazioni e i problemi effettivi che potresti incontrare quando gestisci le modifiche allo schema del database. Parleremo anche di strumenti open source che potrebbero aiutarti nel processo.
Scenari di test e ripristino
Backup
Ci sono molti modi per perdere i tuoi dati. L'errore di aggiornamento dello schema è uno di questi. A differenza del codice dell'applicazione, non puoi eliminare un pacchetto di file e dichiarare che una nuova versione è stata distribuita correttamente. Inoltre, non puoi semplicemente ripristinare un set di file precedente per ripristinare le modifiche. Naturalmente, puoi eseguire un altro script SQL per modificare nuovamente il database, ma in alcuni casi l'unico modo accurato per ripristinare le modifiche è ripristinare l'intero database dal backup.
Tuttavia, cosa succede se non puoi permetterti di eseguire il rollback del tuo database all'ultimo backup o se la tua finestra di manutenzione non è abbastanza grande (considerando le prestazioni del sistema), quindi non puoi eseguire un backup completo del database prima della modifica?
Si può avere un ambiente sofisticato e ridondante, ma finché i dati vengono modificati sia nelle posizioni primarie che in quelle di standby, non c'è molto da fare al riguardo. Molti script possono essere eseguiti solo una volta o le modifiche sono impossibili da annullare. La maggior parte del codice di modifica SQL rientra in due gruppi:
- Esegui una volta:non puoi aggiungere la stessa colonna alla tabella due volte.
- Impossibile annullare:una volta eliminata quella colonna, non c'è più. Potresti indubbiamente ripristinare il tuo database, ma non è esattamente un annullamento.
Puoi affrontare questo problema in almeno due modi possibili. Uno sarebbe abilitare il registro binario e fare un backup, che è compatibile con PITR. Tale backup deve essere completo, completo e coerente. Per xtrabackup, purché contenga un set di dati completo, sarà compatibile con PITR. Per mysqldump, c'è un'opzione per renderlo compatibile anche con PITR. Per modifiche più piccole, una variante del backup di mysqldump sarebbe quella di richiedere solo un sottoinsieme di dati da modificare. Questo può essere fatto con l'opzione --where. Il backup dovrebbe far parte della manutenzione pianificata.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlUn'altra possibilità è usare CREATE TABLE AS SELECT.
È possibile memorizzare dati o semplici modifiche alla struttura sotto forma di una tabella temporanea fissa. Con questo approccio otterrai una fonte se devi ripristinare le modifiche. Potrebbe essere molto utile se non modifichi molti dati. Il rollback può essere eseguito rimuovendo i dati da esso. Se si verificano errori durante la copia dei dati nella tabella, questi vengono automaticamente eliminati e non creati, quindi assicurati che la tua dichiarazione crei una copia di cui hai bisogno.
Ovviamente ci sono anche alcune limitazioni.
Poiché non è sempre possibile determinare l'ordine delle righe nelle istruzioni SELECT sottostanti, CREATE TABLE ... IGNORE SELECT e CREATE TABLE ... REPLACE SELECT sono contrassegnati come non sicuri per la replica basata su istruzioni. Tali istruzioni producono un avviso nel registro degli errori quando si utilizza la modalità basata su istruzioni e vengono scritte nel registro binario utilizzando il formato basato su riga quando si utilizza la modalità MIXED.
Un esempio molto semplice di tale metodo potrebbe essere:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Un'altra opzione interessante potrebbe essere il database flashback MariaDB. Quando si verifica un aggiornamento o un'eliminazione errati e si desidera ripristinare uno stato del database (o solo una tabella) in un determinato momento, è possibile utilizzare la funzione di flashback.
Il rollback point-in-time consente ai DBA di recuperare i dati più rapidamente ripristinando le transazioni a un momento precedente anziché eseguire un ripristino da un backup. Sulla base di eventi DML basati su ROW, il flashback può trasformare il registro binario e invertire gli scopi. Ciò significa che può aiutare a annullare rapidamente determinate modifiche alle righe. Ad esempio, può cambiare gli eventi DELETE in INSERT e viceversa, e scambierà le parti WHERE e SET degli eventi UPDATE. Questa semplice idea può accelerare notevolmente il recupero da determinati tipi di errori o disastri. Per coloro che hanno familiarità con il database Oracle, è una funzionalità ben nota. Il limite del flashback di MariaDB è la mancanza del supporto DDL.
Crea uno slave di replica ritardato
Dalla versione 5.6, MySQL supporta la replica ritardata. Un server slave può rimanere indietro rispetto al master di almeno un determinato periodo di tempo. Il ritardo predefinito è 0 secondi. Usa l'opzione MASTER_DELAY per CHANGE MASTER TO per impostare il ritardo su N secondi:
CHANGE MASTER TO MASTER_DELAY = N;Sarebbe una buona opzione se non avessi il tempo di preparare uno scenario di ripristino adeguato. È necessario disporre di un ritardo sufficiente per notare il cambiamento problematico. Il vantaggio di questo approccio è che non è necessario ripristinare il database per eliminare i dati necessari per correggere la modifica. Standby DB è attivo e funzionante, pronto a raccogliere i dati riducendo al minimo il tempo necessario.
Crea uno slave asincrono che non fa parte del cluster
Quando si tratta del cluster Galera, testare le modifiche non è facile. Tutti i nodi eseguono gli stessi dati e un carico pesante può danneggiare il controllo del flusso. Quindi non solo è necessario verificare se le modifiche sono state applicate correttamente, ma anche quale è stato l'impatto sullo stato del cluster. Per rendere la procedura di test il più vicino possibile al carico di lavoro di produzione, potresti voler aggiungere uno slave asincrono al tuo cluster ed eseguire lì il test. Il test non influirà sulla sincronizzazione tra i nodi del cluster, perché tecnicamente non fa parte del cluster, ma avrai la possibilità di verificarlo con dati reali. Tale slave può essere facilmente aggiunto da ClusterControl.
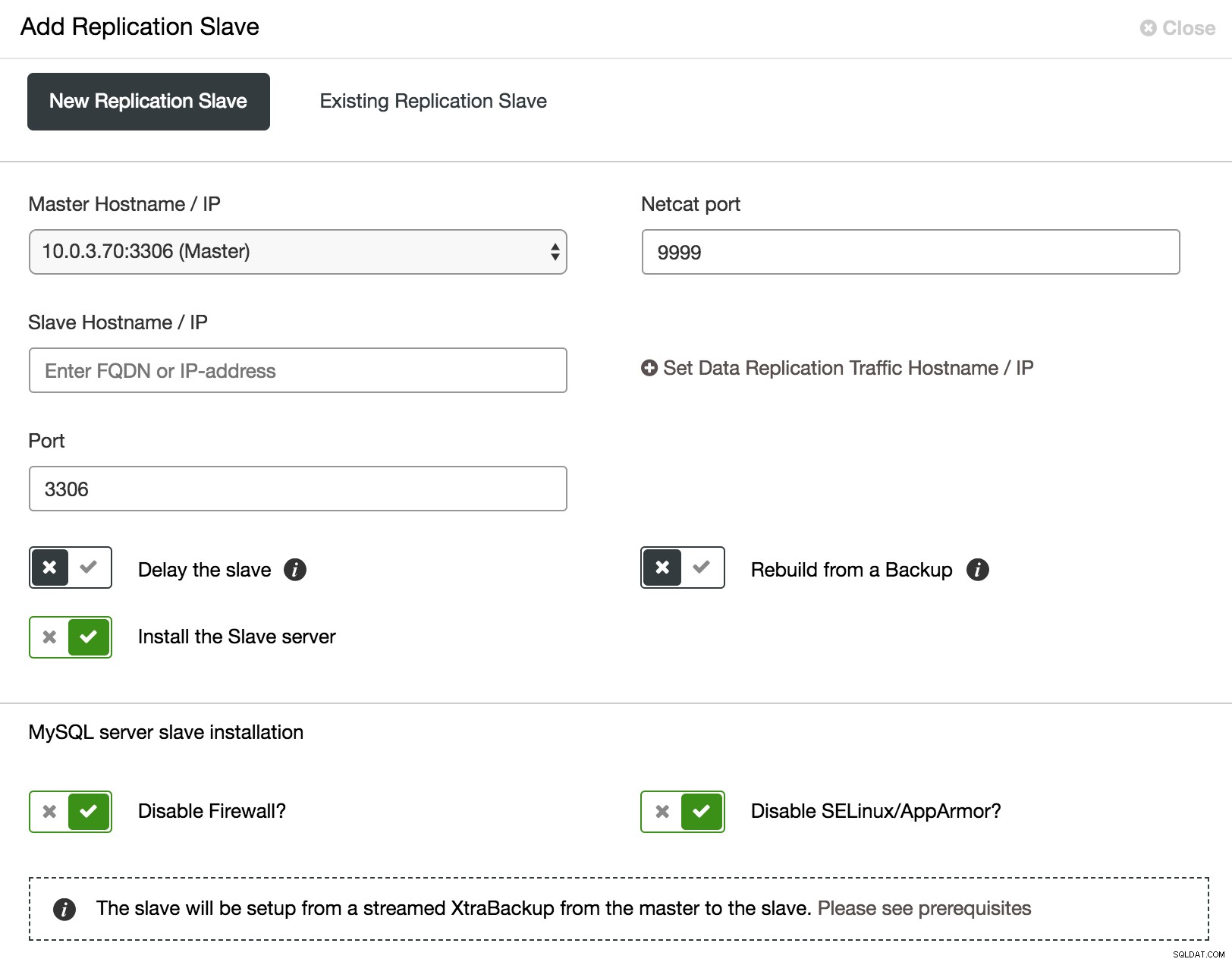 ClusterControl aggiunge uno slave asincrono
ClusterControl aggiunge uno slave asincrono Come mostrato nella schermata sopra, ClusterControl può automatizzare il processo di aggiunta di uno slave asincrono in alcuni modi. Puoi aggiungere il nodo al cluster, ritardare lo slave. Per ridurre l'impatto sul master, puoi utilizzare un backup esistente invece del master come origine dati durante la creazione dello slave.
Clone database e misura tempo
Un buon test dovrebbe essere il più vicino possibile al cambio di produzione. Il modo migliore per farlo è clonare il tuo ambiente esistente.
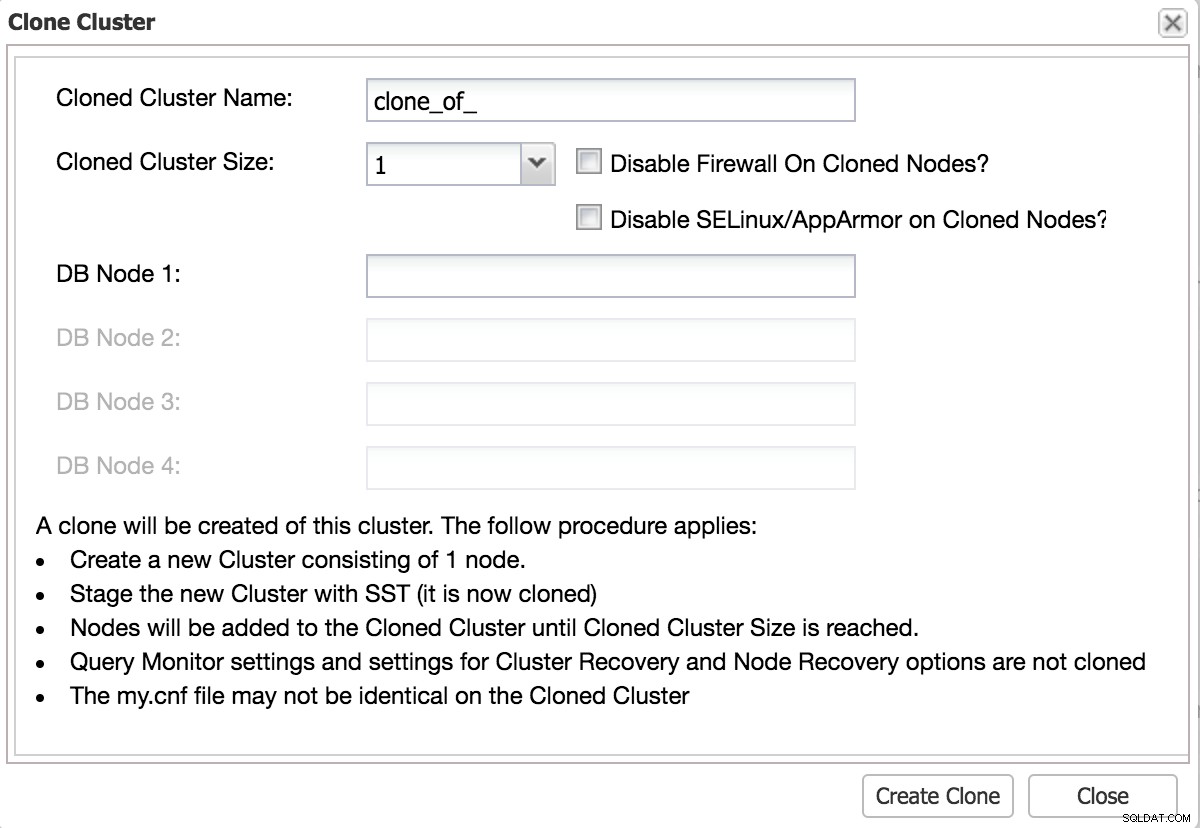 ClusterControl Clona Cluster per test
ClusterControl Clona Cluster per test Esegui modifiche tramite replica
Per avere un migliore controllo sulle modifiche, puoi applicarle in anticipo su un server slave e quindi eseguire il passaggio. Per la replica basata su istruzioni, funziona bene, ma per la replica basata su riga, questo può funzionare fino a un certo punto. La replica basata su riga consente l'esistenza di colonne aggiuntive alla fine della tabella, quindi finché può scrivere le prime colonne, andrà bene. Applicare prima queste impostazioni a tutti gli slave, quindi eseguire il failover su uno degli slave, quindi implementare la modifica sul master e collegarlo come slave. Se la modifica comporta l'inserimento o la rimozione di una colonna al centro della tabella, funzionerà con la replica basata su riga.
Operazione
Durante la finestra di manutenzione, non vogliamo che il traffico dell'applicazione sul database. A volte è difficile chiudere tutte le applicazioni sparse nell'intera azienda. In alternativa, vogliamo consentire solo ad alcuni host specifici di accedere a MySQL da remoto (ad esempio il sistema di monitoraggio o il server di backup). A questo scopo, possiamo usare il filtraggio dei pacchetti di Linux. Per vedere quali regole di filtraggio dei pacchetti sono disponibili, possiamo eseguire il seguente comando:
iptables -L INPUT -vPer chiudere la porta MySQL su tutte le interfacce utilizziamo:
iptables -A INPUT -p tcp --dport mysql -j DROPe per aprire nuovamente la porta MySQL dopo la finestra di manutenzione:
iptables -D INPUT -p tcp --dport mysql -j DROPPer quelli senza accesso come root, puoi cambiare max_connection su 1 o 'salta la rete'.
Registrazione
Per avviare il processo di registrazione, utilizzare il comando tee al prompt del client MySQL, in questo modo:
mysql> tee /tmp/my.out;Quel comando dice a MySQL di registrare sia l'input che l'output della tua attuale sessione di login MySQL in un file chiamato /tmp/my.out . Quindi esegui il tuo file di script con il comando source.
Per avere un'idea migliore dei tuoi tempi di esecuzione, puoi combinarlo con la funzione del profiler. Avvia il profiler con
SET profiling = 1;Quindi esegui la tua query con
SHOW PROFILES;viene visualizzato un elenco di query per le quali il profiler ha le statistiche. Quindi, alla fine, scegli con quale query esaminare
SHOW PROFILE FOR QUERY 1;Strumenti di migrazione dello schema
Molte volte, un ALTER diretto sul master non è possibile:nella maggior parte dei casi provoca un ritardo sullo slave e questo potrebbe non essere accettabile per le applicazioni. Ciò che si può fare, tuttavia, è eseguire la modifica in modalità continuativa. Puoi iniziare con gli slave e, una volta applicata la modifica allo slave, migrare uno degli slave come nuovo master, retrocedere il vecchio master a slave ed eseguire la modifica su di esso.
Uno strumento che può aiutare con tale compito è pt-online-schema-change di Percona. Pt-online-schema-change è semplice:crea una tabella temporanea con il nuovo schema desiderato (ad esempio, se abbiamo aggiunto un indice o rimosso una colonna da una tabella). Quindi, crea trigger sulla vecchia tabella. Quei trigger sono lì per rispecchiare le modifiche che si verificano sulla tabella originale nella nuova tabella. Le modifiche vengono rispecchiate durante il processo di modifica dello schema. Se una riga viene aggiunta alla tabella originale, viene aggiunta anche a quella nuova. Emula il modo in cui MySQL altera le tabelle internamente, ma funziona su una copia della tabella che desideri modificare. Significa che la tabella originale non è bloccata e che i client possono continuare a leggere e modificare i dati in essa contenuti.
Allo stesso modo, se una riga viene modificata o eliminata nella vecchia tabella, viene applicata anche nella nuova tabella. Quindi, inizia un processo in background di copia dei dati (usando LOW_PRIORITY INSERT) tra la vecchia e la nuova tabella. Una volta copiati i dati, viene eseguito RENAME TABLE.
Un altro strumento interessante è gh-ost. Gh-ost crea una tabella temporanea con lo schema alterato, proprio come fa pt-online-schema-change. Esegue query INSERT, che utilizzano il seguente schema per copiare i dati dalla vecchia alla nuova tabella. Tuttavia non utilizza trigger. Sfortunatamente i trigger possono essere la fonte di molte limitazioni. gh-ost utilizza il flusso di log binario per acquisire le modifiche alla tabella e applicarle in modo asincrono alla tabella fantasma. Una volta verificato che gh-ost può eseguire correttamente la nostra modifica dello schema, è il momento di eseguirla effettivamente. Tieni presente che potrebbe essere necessario eliminare manualmente le vecchie tabelle create da gh-ost durante il processo di test della migrazione. Puoi anche usare i flag --initially-drop-ghost-table e --initially-drop-old-table per chiedere a gh-ost di farlo per te. Il comando finale da eseguire è esattamente lo stesso che abbiamo usato per testare la nostra modifica, abbiamo appena aggiunto --execute.
pt-online-schema-change e gh-ost sono molto popolari tra gli utenti di Galera. Tuttavia Galera ha alcune opzioni aggiuntive. I due metodi Total Order Isolation (TOI) e Rolling Schema Upgrade (RSU) hanno sia i loro pro che i loro contro.
TOI:questo è il metodo di replica DDL predefinito. Il nodo che origina il writeset rileva DDL in fase di analisi e invia un evento di replica per l'istruzione SQL prima ancora di avviare l'elaborazione DDL. Gli aggiornamenti dello schema vengono eseguiti su tutti i nodi del cluster nella stessa sequenza di ordini totali, impedendo il commit di altre transazioni per la durata dell'operazione. Questo metodo è utile quando vuoi che gli aggiornamenti dello schema online vengano replicati attraverso il cluster e non ti dispiace bloccare l'intera tabella (simile a come sono avvenute le modifiche allo schema predefinito in MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU:esegue gli aggiornamenti dello schema in locale. In questo metodo, le tue scritture interessano solo il nodo su cui vengono eseguite. Le modifiche non vengono replicate nel resto del cluster. Questo metodo è utile per operazioni non in conflitto e non rallenterà il cluster.
SET GLOBAL wsrep_OSU_method='RSU';Mentre il nodo elabora l'aggiornamento dello schema, si sincronizza con il cluster. Al termine dell'elaborazione dell'aggiornamento dello schema, applica eventi di replica ritardata e si sincronizza con il cluster. Questa potrebbe essere una buona opzione per eseguire pesanti creazioni di indici.
Conclusione
Abbiamo presentato qui diversi metodi che possono aiutarti a pianificare le modifiche allo schema. Ovviamente tutto dipende dalla tua applicazione e dai requisiti aziendali. Puoi progettare il tuo piano di cambiamento, eseguire i test necessari, ma c'è ancora una piccola possibilità che qualcosa vada storto. Secondo la legge di Murphy - "le cose andranno male in ogni situazione, se gli dai una possibilità". Quindi assicurati di provare diversi modi per eseguire queste modifiche e scegli quello con cui ti senti più a tuo agio.



