Questo è il primo articolo di una serie di articoli su In-Memory OLTP. Ti aiuta a capire come funziona internamente il nuovo motore Hekaton. Ci concentreremo sui dettagli delle tabelle e degli indici ottimizzati in memoria. Questo è l'articolo di base, il che significa che non è necessario essere un esperto di SQL Server, tuttavia, è necessario avere alcune conoscenze di base sul motore di SQL Server tradizionale.
Introduzione
Il motore OLTP in memoria di SQL Server 2014 (progetto Hekaton) è stato creato da zero per utilizzare terabyte di memoria disponibile e un numero enorme di core di elaborazione. In-Memory OLTP consente agli utenti di lavorare con tabelle e indici ottimizzati per la memoria e stored procedure compilate in modo nativo. Puoi usarlo insieme alle tabelle e agli indici basati su disco e alle stored procedure T-SQL, che SQL Server ha sempre fornito.
Gli interni e le capacità del motore OLTP in memoria differiscono notevolmente dal motore relazionale standard. Devi rivedere quasi tutto ciò che sapevi su come vengono gestiti più processi simultanei.
Il motore di SQL Server è ottimizzato per l'archiviazione basata su disco. Legge pagine di dati da 8 KB in memoria per l'elaborazione e scrive pagine di dati da 8 KB su disco dopo le modifiche. Naturalmente, SQL Server risolve principalmente le modifiche al disco nel registro delle transazioni. La lettura di pagine di dati da 8 KB dal disco e la riscrittura può generare molto I/O e comporta un costo di latenza più elevato. Anche quando i dati sono nella cache del buffer, SQL Server è progettato per presumere che non lo sia, il che porta a un utilizzo inefficiente della CPU.
Considerando i limiti delle tradizionali strutture di archiviazione basate su disco, il team di SQL Server ha iniziato a creare un motore di database ottimizzato per la memoria principale di grandi dimensioni e le CPU multi-core. Il team ha fissato i seguenti obiettivi:
- Ottimizzato per i dati che erano stati archiviati completamente in memoria ma erano anche durevoli al riavvio di SQL Server
- Completamente integrato nel motore di SQL Server esistente
- Prestazioni molto elevate per le operazioni OLTP
- Progettato per le moderne CPU
SQL Server In-Memory OLTP soddisfa tutti questi obiettivi.
Informazioni su OLTP in memoria
SQL Server 2014 In-Memory OLTP offre una serie di tecnologie per lavorare con le tabelle con ottimizzazione per la memoria, insieme alle tabelle basate su disco. Ad esempio, consente di accedere ai dati in memoria utilizzando interfacce standard come T-SQL e SSMS. L'illustrazione seguente mostra le tabelle e gli indici ottimizzati per la memoria, come parte di In-Memory OLTP (a sinistra) e le tabelle basate su disco (a sinistra) che richiedono la lettura e la scrittura di pagine di dati da 8 KB. OLTP in memoria supporta anche stored procedure compilate in modo nativo e fornisce un nuovo compilatore OLTP in memoria.
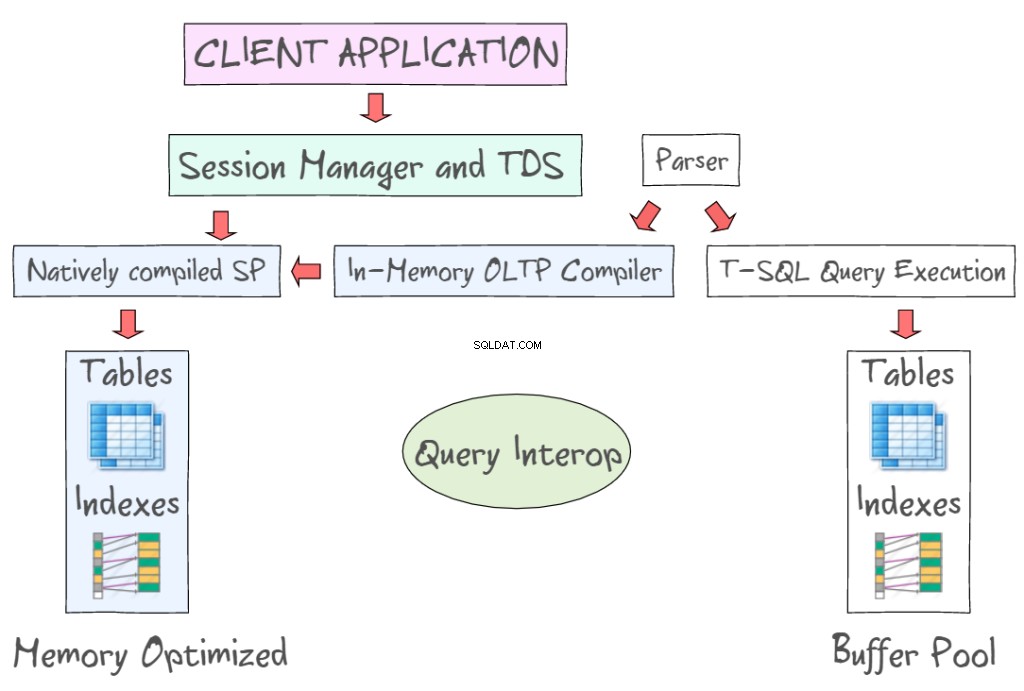
Query Interop consente di interpretare T-SQL per fare riferimento a tabelle ottimizzate per la memoria. Se una transazione fa riferimento a tabelle con ottimizzazione per la memoria e basate su disco, può essere definita transazione cross-container. L'app client utilizza Tabular Data Stream, un protocollo a livello di applicazione utilizzato per trasferire dati tra un server di database e un client. Inizialmente è stato progettato e sviluppato da Sybase Inc. per il motore di database relazionale Sybase SQL Server nel 1984 e successivamente da Microsoft in Microsoft SQL Server.
Tabelle ottimizzate per la memoria
Durante l'accesso alle tabelle basate su disco, i dati richiesti potrebbero essere già in memoria, anche se potrebbe non esserlo. Se i dati non sono in memoria, SQL Server deve leggerli dal disco. La differenza più fondamentale durante l'utilizzo di tabelle con ottimizzazione per la memoria è che l'intera tabella e i relativi indici sono sempre archiviati in memoria . Le operazioni simultanee sui dati non richiedono il blocco o la memorizzazione.
Mentre un utente modifica i dati in memoria, SQL Server esegue alcune operazioni di I/O su disco per qualsiasi tabella che deve essere durevole, altrimenti è necessaria una tabella per conservare i dati in memoria al momento di un arresto anomalo o del riavvio del server.
Struttura di archiviazione basata su righe
Un'altra differenza significativa è la struttura di archiviazione sottostante. Le tabelle basate su disco sono ottimizzate per indirizzabile a blocchi spazio di archiviazione su disco, mentre le tabelle ottimizzate in memoria sono ottimizzate per indirizzabile a byte memoria.
SQL Server mantiene le righe di dati in pagine di dati da 8 KB, con l'allocazione dello spazio dalle estensioni per le tabelle basate su disco. La pagina dei dati è l'unità fondamentale di archiviazione su disco e memoria. Durante la lettura e la scrittura di dati dal disco, SQL Server legge e scrive solo le pagine di dati rilevanti. Una pagina di dati conterrà solo i dati di una tabella o di un indice. I processi dell'applicazione modificano le righe su diverse pagine di dati in base alle esigenze. Successivamente, durante l'operazione CHECKPOINT, SQL Server prima corregge i record di registro su disco e quindi scrive tutte le pagine sporche su disco. Questa operazione provoca spesso molti I/O fisici casuali.
Per le tabelle con ottimizzazione per la memoria, non sono presenti pagine di dati né estensioni. Ci sono solo righe di dati scritte in memoria in sequenza, nell'ordine in cui si sono verificate le transazioni. Ogni riga contiene un puntatore di indice alla riga successiva. Tutto l'I/O è la scansione in memoria di queste strutture. Non esiste alcuna idea che le righe di dati vengano scritte in una posizione particolare che appartiene a un oggetto specificato. Tuttavia, non devi pensare che le tabelle ottimizzate per la memoria siano archiviate come set non organizzato di righe di dati (simile agli heap basati su disco). Ogni istruzione CREATE TABLE per una tabella con ottimizzazione per la memoria crea almeno un indice utilizzato da SQL Server per collegare tutte le righe di dati in quella tabella.
Ogni singola riga di dati è costituita dall'intestazione di riga e dal payload che è la colonna di dati effettivi. L'intestazione memorizza le informazioni sull'istruzione che ha creato la riga, i puntatori per ogni indice nella tabella di destinazione e i valori di timestamp. Timestamp indica l'ora in cui una transazione ha inserito ed eliminato una riga. Record di SQL Server aggiornati inserendo una nuova versione di riga e contrassegnando la versione precedente come eliminata. Possono esistere più versioni della stessa riga in un dato momento. Ciò consente l'accesso simultaneo alla stessa riga durante la modifica dei dati. SQL Server visualizza la versione della riga relativa a ciascuna transazione in base all'ora in cui è stata avviata la transazione rispetto ai timestamp della versione della riga. Questo è il fulcro del nuovo controllo della concorrenza multi-versione meccanismo per tabelle in memoria.
A proposito, Oracle ha un eccellente sistema di controllo multi-versione. Fondamentalmente, funziona come segue:
- L'utente A avvia una transazione e aggiorna 1000 righe con un valore all'ora T1.
- L'utente B legge le stesse 1000 righe all'ora T2.
- L'utente A aggiorna la riga 565 con il valore Y (il valore originale era X).
- L'utente B raggiunge la riga 565 e rileva che una transazione è in esecuzione dall'ora T1.
- Il database restituisce il record non modificato dai log. Il valore restituito è il valore di cui è stato eseguito il commit in quel momento minore o uguale a T2.
- Se non è stato possibile recuperare il record dai registri di ripristino, significa che il database non è impostato correttamente. È necessario allocare più spazio ai registri.
- I risultati restituiti sono sempre gli stessi rispetto all'ora di inizio della transazione. Quindi all'interno della transazione si ottiene la coerenza di lettura.
Tabelle compilate in modo nativo
L'ultima grande differenza è che le tabelle ottimizzate in memoria sono compilate in modo nativo . Quando un utente crea una tabella o un indice ottimizzato per la memoria, SQL ServerSQL Server archivia la struttura di ogni tabella (insieme a tutti gli indici) nei metadati. Successivamente, SQL Server utilizza tali metadati per compilare in DDL un insieme di routine del linguaggio nativo per l'accesso alla tabella. Tali DDL sono associati al database ma non ne fanno effettivamente parte.
In altre parole, SQL Server mantiene in memoria non solo tabelle e indici ma anche DDL per l'accesso e la modifica di queste strutture. Dopo che una tabella è stata modificata, SQL Server deve ricreare tutti i DDL per le operazioni sulle tabelle. Ecco perché non è possibile modificare una tabella una volta creata. Queste operazioni sono invisibili agli utenti.
Procedure memorizzate compilate in modo nativo
Le migliori prestazioni si ottengono utilizzando stored procedure compilate in modo nativo per accedere alle tabelle compilate in modo nativo. Tali procedure contengono istruzioni del processore e possono essere eseguite direttamente dalla CPU senza ulteriore compilazione. Tuttavia, esistono alcune restrizioni sulle costruzioni T-SQL per le stored procedure compilate in modo nativo (rispetto al codice interpretato tradizionalmente). Un altro punto significativo è che le stored procedure compilate in modo nativo possono accedere solo a tabelle ottimizzate per la memoria.
Nessun blocco
In-Memory OLTP è un sistema senza blocco. Ciò è possibile perché SQL Server non modifica mai alcuna riga esistente. L'operazione UPDATE crea la nuova versione e contrassegna la versione precedente come eliminata. Quindi inserisce una nuova versione di riga con nuovi dati al suo interno.
Indici
Come avrai intuito, gli indici sono molto diversi da quelli tradizionali. Le tabelle ottimizzate in memoria non hanno pagine. SQL Server utilizza gli indici per collegare tutte le righe che appartengono a una tabella in un'unica struttura. Non è possibile utilizzare l'istruzione CREATE INDEX per creare un indice per la tabella ottimizzata in memoria. Dopo aver creato la CHIAVE PRIMARIA su una colonna, SQL Server crea automaticamente un indice univoco su tale colonna. In realtà, è l'unico indice univoco consentito. Puoi creare un massimo di otto indici su una tabella con ottimizzazione per la memoria.
Per analogia con le tabelle, SQL Server mantiene in memoria gli indici ottimizzati per la memoria. Tuttavia, SQL Server non registra mai le operazioni sugli indici. SQL ServerSQL Server mantiene gli indici automaticamente durante le modifiche alle tabelle.
Le tabelle ottimizzate per la memoria supportano due tipi di indici:indice hash e indice di intervallo . Entrambe sono strutture non raggruppate.
L'indice hash è un nuovo tipo di indice, progettato specificamente per le tabelle con ottimizzazione della memoria. È estremamente utile per eseguire ricerche su valori specifici. L'indice stesso viene archiviato come tabella hash. È un array di hash bucket, in cui ogni bucket è un puntatore a una singola riga.
L'indice di intervallo (non cluster) è utile per recuperare intervalli di valori.
Recupero
Il meccanismo di ripristino di base per un database con tabelle ottimizzate per la memoria è lo stesso del meccanismo di ripristino dei database con tabelle basate su disco. Tuttavia, il ripristino delle tabelle ottimizzate per la memoria include la fase di caricamento in memoria delle tabelle ottimizzate per la memoria prima che il database sia disponibile per l'accesso dell'utente.
Al riavvio di SQL Server, ogni database passa attraverso le seguenti fasi del processo di ripristino:analisi , ripeti e annulla .
Nella fase di analisi, il motore OLTP In-Memory identifica l'inventario del checkpoint da caricare e precarica le voci di registro della tabella di sistema. Elaborerà anche alcuni record del registro di allocazione dei file.
Nella fase di ripetizione, i dati delle coppie di file dati e delta vengono caricati in memoria. Quindi i dati vengono aggiornati dal registro delle transazioni attivo in base all'ultimo checkpoint durevole e le tabelle in memoria vengono popolate e gli indici ricostruiti. Durante questa fase, il ripristino delle tabelle basato su disco e ottimizzato per la memoria viene eseguito contemporaneamente.
La fase di annullamento non è necessaria per le tabelle con ottimizzazione per la memoria poiché In-Memory OLTP non registra alcuna transazione non vincolata per le tabelle con ottimizzazione per la memoria.
Al termine di tutte le operazioni, il database è disponibile per l'accesso.
Riepilogo
In questo articolo, abbiamo dato una rapida occhiata al motore OLTP in memoria di SQL Server. Abbiamo imparato che le strutture ottimizzate per la memoria sono archiviate nella memoria. I processi applicativi possono trovare i dati richiesti accedendo a queste strutture in memoria senza la necessità di I/O su disco. Nei seguenti articoli, daremo un'occhiata a come creare e accedere a database e tabelle OLTP in memoria.
Ulteriori letture
OLTP in memoria:novità di SQL Server 2016
Utilizzo degli indici nelle tabelle con ottimizzazione per la memoria di SQL Server