Ho pubblicato più benchmark confrontando diverse versioni di PostgreSQL, come ad esempio il discorso sull'archeologia delle prestazioni (valutazione di PostgreSQL 7.4 fino a 9.4) e tutti quei benchmark presupposti ambiente fisso (hardware, kernel, ...). Il che va bene in molti casi (ad es. quando si valuta l'impatto sulle prestazioni di una patch), ma sulla produzione queste cose cambiano nel tempo:ottieni aggiornamenti hardware e di tanto in tanto ricevi un aggiornamento con una nuova versione del kernel.
Per gli aggiornamenti hardware (migliore storage, più RAM, CPU più veloci, ...), l'impatto è generalmente abbastanza facile da prevedere e inoltre le persone generalmente si rendono conto di dover valutare l'impatto analizzando i colli di bottiglia sulla produzione e forse anche testando prima il nuovo hardware .
Ma per quanto riguarda gli aggiornamenti del kernel? Purtroppo di solito non facciamo molti benchmark in quest'area. Il presupposto è principalmente che i nuovi kernel siano migliori di quelli più vecchi (più veloci, più efficienti, scalabili a più core della CPU). Ma è proprio vero? E quanto è grande la differenza? Ad esempio, cosa succede se aggiorni un kernel da 3.0 a 4.7:ciò influirà sulle prestazioni e, in caso affermativo, le prestazioni miglioreranno o no?
Di tanto in tanto riceviamo segnalazioni su gravi regressioni con una particolare versione del kernel o miglioramenti improvvisi tra le versioni del kernel. Quindi, chiaramente, le versioni del kernel possono influire sulle prestazioni.
Sono a conoscenza di un singolo benchmark PostgreSQL che confronta diverse versioni del kernel, realizzato nel 2014 da Sergey Konoplev in risposta ai consigli per evitare i kernel 3.0 – 3.8. Ma quel benchmark è abbastanza vecchio (l'ultima versione del kernel disponibile circa 18 mesi fa era la 3.13, mentre oggi abbiamo 3.19 e 4.6), quindi ho deciso di eseguire alcuni benchmark con i kernel attuali (e PostgreSQL 9.6beta1).
Versioni PostgreSQL e kernel
Ma prima, vorrei discutere alcune differenze significative tra le politiche che regolano gli impegni nei due progetti. In PostgreSQL abbiamo il concetto di versioni principali e secondarie:le versioni principali (ad es. 9.5) vengono rilasciate all'incirca una volta all'anno e includono varie nuove funzionalità. Le versioni minori (ad es. 9.5.2) includono solo correzioni di bug e vengono rilasciate circa ogni tre mesi (o più frequentemente, quando viene scoperto un bug grave). Quindi non dovrebbero esserci modifiche importanti alle prestazioni o al comportamento tra le versioni secondarie, il che rende abbastanza sicuro distribuire versioni secondarie senza test approfonditi.
Con le versioni del kernel, la situazione è molto meno chiara. Il kernel Linux ha anche rami (ad es. 2.6, 3.0 o 4.7), quelli non sono affatto uguali alle "versioni principali" di PostgreSQL, poiché continuano a ricevere nuove funzionalità e non solo correzioni di bug. Non sto affermando che la politica di controllo delle versioni di PostgreSQL sia in qualche modo automaticamente superiore, ma la conseguenza è che l'aggiornamento tra versioni minori del kernel può facilmente influire in modo significativo sulle prestazioni o persino introdurre bug (ad es. 3.18.37 soffre di problemi di OOM a causa di una tale correzione non di bug commit).
Naturalmente, le distribuzioni si rendono conto di questi rischi e spesso bloccano la versione del kernel ed eseguono ulteriori test per eliminare nuovi bug. Questo post utilizza tuttavia kernel vanilla a lungo termine, disponibili su www.kernel.org.
Parametro
Ci sono molti benchmark che potremmo usare:questo post presenta una suite di test pgbench, ovvero un benchmark OLTP (simile a TPC-B) abbastanza semplice. Ho intenzione di fare ulteriori test con altri tipi di benchmark (in particolare orientati a DWH/DSS) e li presenterò su questo blog in futuro.
Ora, tornando al pgbench:quando dico "raccolta di test" intendo combinazioni di
- sola lettura vs. lettura-scrittura
- dimensione del set di dati:il set attivo (non) si adatta ai buffer / RAM condivisi
- Conteggio dei clienti:un singolo cliente rispetto a molti clienti (blocco/programmazione)
I valori dipendono ovviamente dall'hardware utilizzato, quindi vediamo su quale hardware è stato eseguito questo round di benchmark:
- CPU:Intel i5-2500k a 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- Archiviazione:6 SSD Intel DC S3700 in RAID-10 (Linux sw raid)
- filesystem:ext4 con schedulatore I/O predefinito (cfq)
Quindi è la stessa macchina che ho usato per una serie di benchmark precedenti:una macchina abbastanza piccola, non esattamente la CPU più recente ecc. ma credo che sia comunque un sistema "piccolo" ragionevole.
I parametri di riferimento sono:
- Il set di dati è scalabile:30, 300 e 1500 (quindi circa 450 MB, 4,5 GB e 22,5 GB)
- conta client:1, 4, 16 (la macchina ha 4 core)
Per ogni combinazione c'erano 3 corse di sola lettura (15 minuti ciascuna) e 3 corse di lettura-scrittura (30 minuti ciascuna). Lo script effettivo che guida il benchmark è disponibile qui (insieme ai risultati e ad altri dati utili).
Nota :Se hai hardware significativamente diverso (ad es. unità di rotazione), potresti vedere risultati molto diversi. Se hai un sistema che vorresti testare, fammelo sapere e ti aiuterò in questo (supponendo che mi sarà consentito pubblicare i risultati).
Versioni del kernel
Per quanto riguarda le versioni del kernel, ho testato le ultime versioni in tutti i rami a lungo termine dalla 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 e 4.7). Ci sono ancora molti sistemi in esecuzione su kernel 2.6.x, quindi è utile sapere quante prestazioni potresti guadagnare (o perdere) aggiornando a un kernel più recente. Ma ho compilato tutti i kernel da solo (cioè usando i kernel vanilla, nessuna patch specifica per la distribuzione) e i file di configurazione sono nel repository git.
Risultati
Come al solito, tutti i dati sono disponibili su bitbucket, incluso
- file .config del kernel
- Script di benchmark (run-pgbench.sh)
- Configurazione PostgreSQL (con alcune regolazioni di base per l'hardware)
- Registri PostgreSQL
- vari registri di sistema (dmesg, sysctl, mount, ...)
I grafici seguenti mostrano i tps medi per ciascun caso sottoposto a benchmark:i risultati per le tre esecuzioni sono abbastanza coerenti, con una differenza di circa il 2% tra min e max nella maggior parte dei casi.
sola lettura
Per il set di dati più piccolo, c'è un netto calo delle prestazioni tra 3,4 e 3,10 per tutti i conteggi dei clienti. I risultati per 16 client (4 volte il numero di core) tuttavia più che recuperano in 3.12.
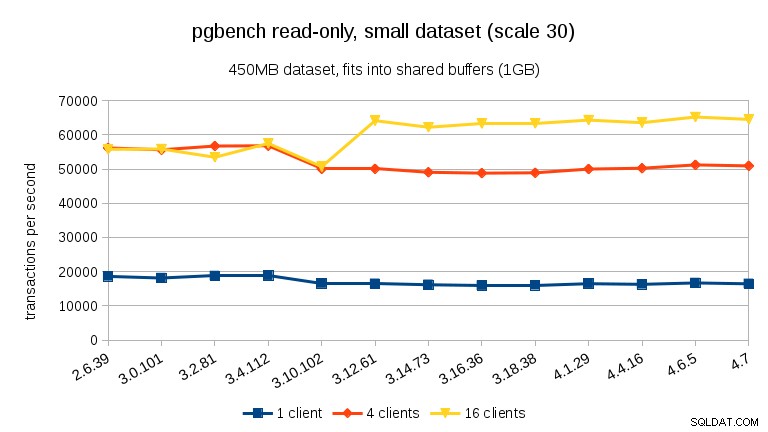
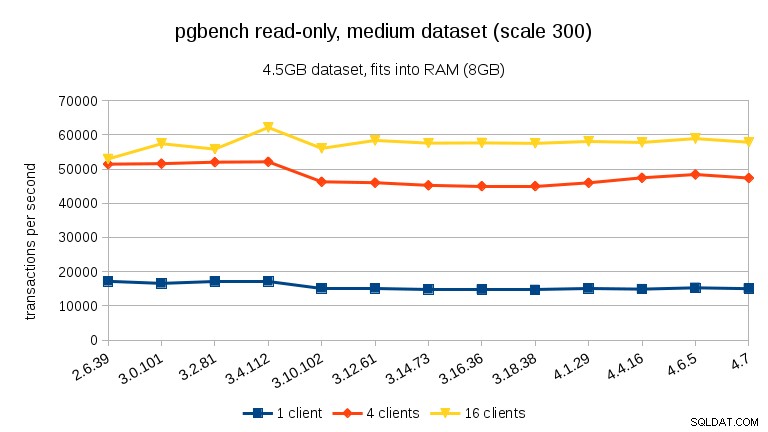
Per il set di dati medio (entra nella RAM ma non nei buffer condivisi), possiamo vedere lo stesso calo tra 3.4 e 3.10 ma non il recupero in 3.12.
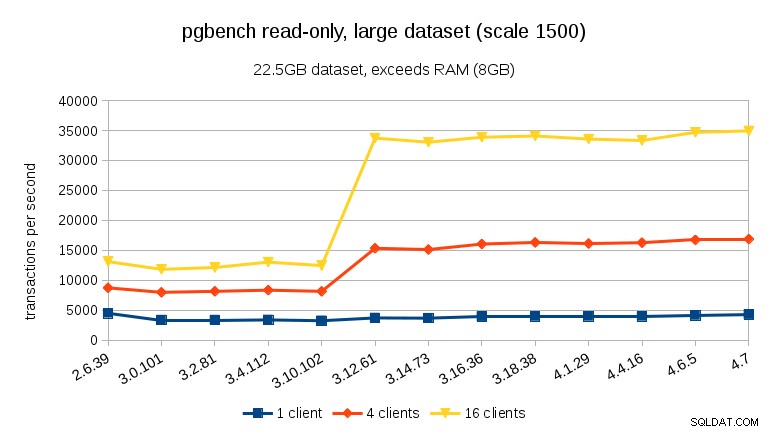
Per set di dati di grandi dimensioni (che superano la RAM, quindi fortemente I/O-bound), i risultati sono molto diversi:non sono sicuro di cosa sia successo tra 3.10 e 3.12, ma il miglioramento delle prestazioni (in particolare per un numero maggiore di client) è piuttosto sorprendente.
lettura-scrittura
Per il carico di lavoro di lettura-scrittura, i risultati sono abbastanza simili. Per i set di dati piccoli e medi possiamo osservare lo stesso calo del ~10% tra 3,4 e 3,10, ma purtroppo nessun recupero in 3,12.
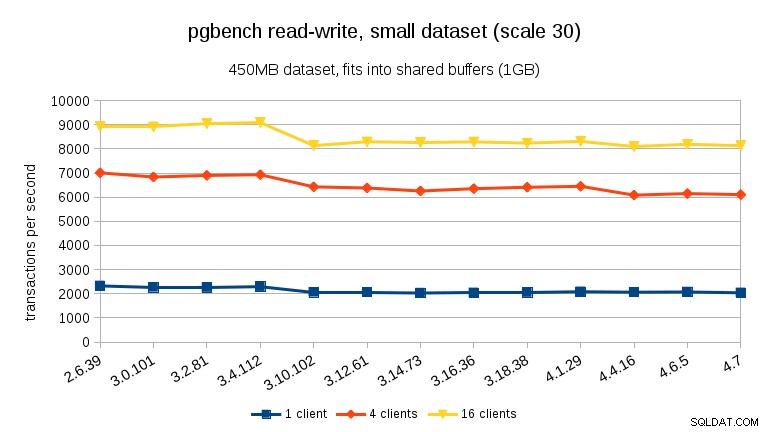
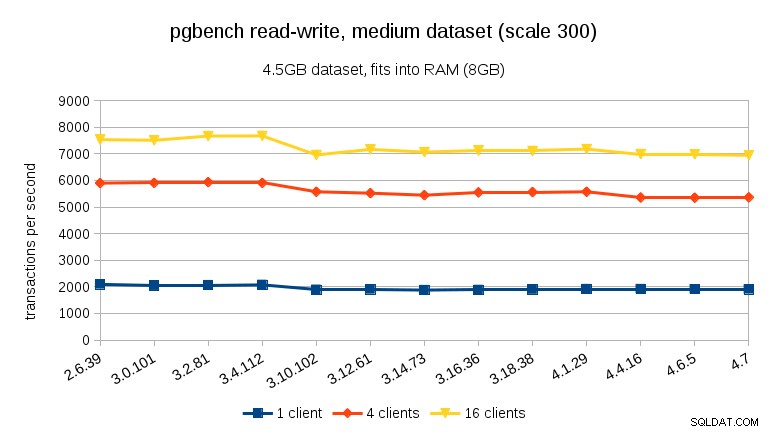
Per l'ampio set di dati (di nuovo, significativamente legato all'I/O) possiamo vedere un miglioramento simile in 3.12 (non così significativo come per il carico di lavoro di sola lettura, ma comunque significativo):
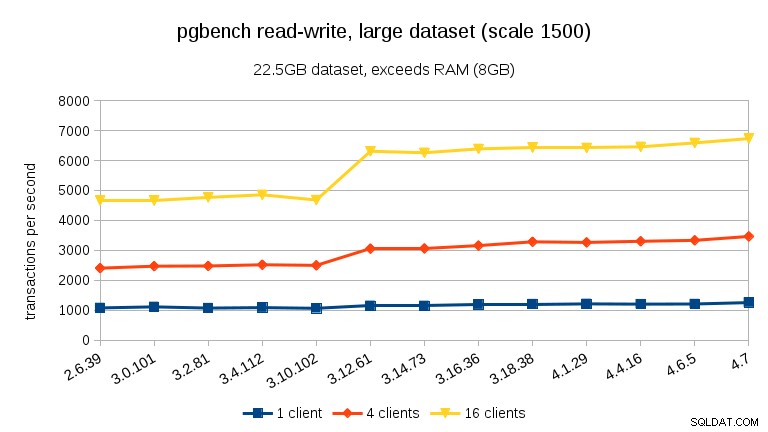
Riepilogo
Non oso trarre conclusioni da un singolo benchmark su una singola macchina, ma penso che sia sicuro dire:
- Le prestazioni complessive sono abbastanza stabili, ma possiamo notare alcuni cambiamenti significativi nelle prestazioni (in entrambe le direzioni).
- Con i set di dati che si adattano alla memoria (o in shared_buffers o almeno nella RAM) vediamo un calo misurabile delle prestazioni tra 3.4 e 3.10. Durante il test di sola lettura, questo viene parzialmente ripristinato in 3.12 (ma solo per molti client).
- Con i set di dati che superano la memoria, e quindi principalmente legati all'I/O, non vediamo cali di prestazioni di questo tipo, ma invece un miglioramento significativo in 3.12.
Per quanto riguarda i motivi per cui si verificano questi cambiamenti improvvisi, non sono del tutto sicuro. Ci sono molti commit potenzialmente rilevanti tra le versioni, ma non sono sicuro di come identificare quello corretto senza test estesi (e dispendiosi in termini di tempo). Se hai altre idee (ad es. sei a conoscenza di tali commit), fammelo sapere.