L'uso della replica per i tuoi database PostgreSQL potrebbe essere utile non solo per avere un ambiente ad alta disponibilità e tolleranza ai guasti, ma anche per migliorare le prestazioni del tuo sistema bilanciando il traffico tra i nodi di standby. In questa prima parte del blog in due parti, vedremo alcuni concetti relativi alla replica di PostgreSQL.
Metodi di replica in PostgreSQL
Esistono diversi metodi per replicare i dati in PostgreSQL, ma qui ci concentreremo sui due metodi principali:Streaming Replication e Logical Replication.
Replica in streaming
PostgreSQL Streaming Replication, la replica PostgreSQL più comune, è una replica fisica che replica le modifiche a livello di byte per byte, creando una copia identica del database in un altro server. Si basa sul metodo di spedizione del registro. I record WAL vengono spostati direttamente da un server di database a un altro per essere applicati. Possiamo dire che è una specie di PITR continuo.
Questo trasferimento WAL viene eseguito in due modi diversi, trasferendo i record WAL un file (segmento WAL) alla volta (log shipping basato su file) e trasferendo i record WAL (un file WAL è composto da record WAL) al volo (log shipping basato su record), tra un server primario e uno o più server di standby, senza attendere il riempimento del file WAL.
In pratica, un processo chiamato ricevitore WAL, in esecuzione sul server di standby, si connetterà al server primario utilizzando una connessione TCP/IP. Nel server primario esiste un altro processo, denominato WAL sender, che ha il compito di inviare i registri WAL al server di standby man mano che si verificano.
Una replica di streaming di base può essere rappresentata come segue:
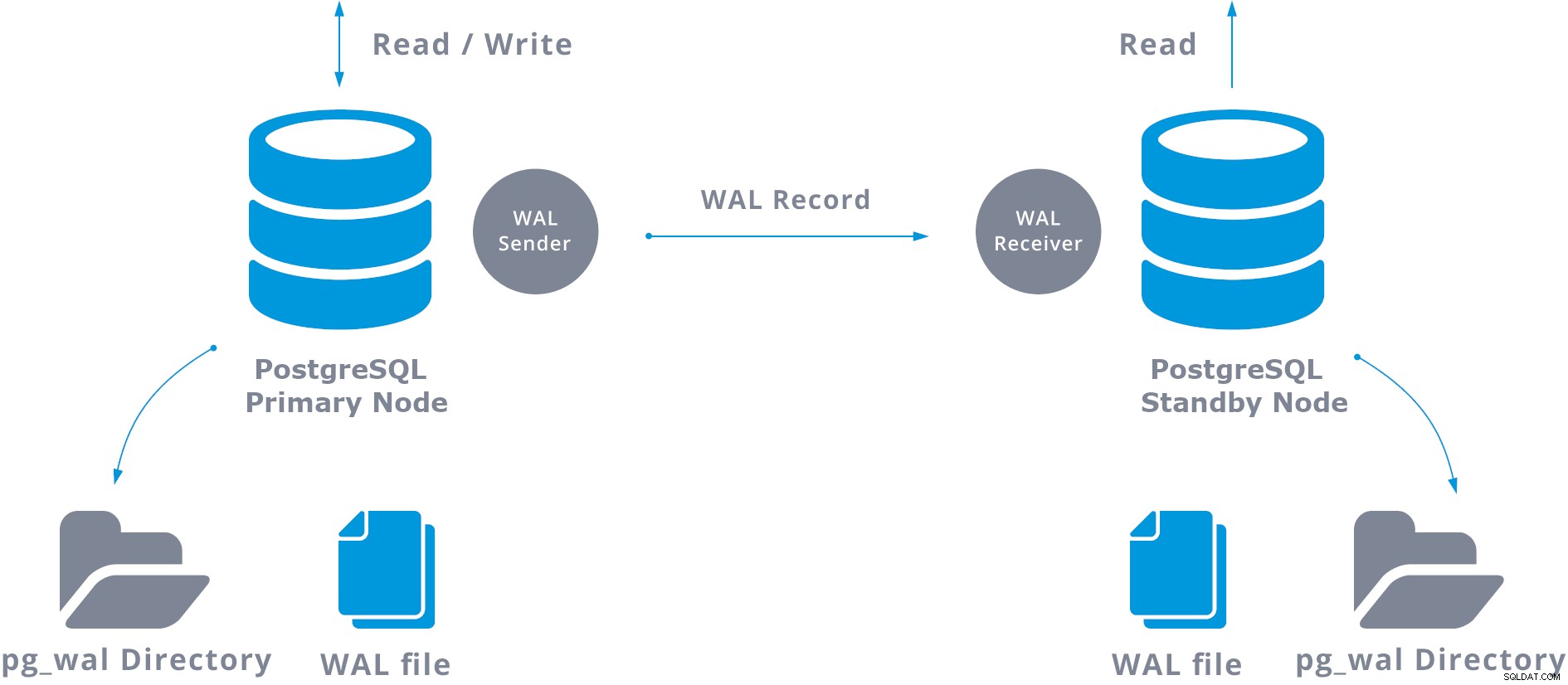
Quando si configura la replica in streaming, è possibile abilitare l'archiviazione WAL. Questo non è obbligatorio, ma è estremamente importante per una solida configurazione della replica, poiché è necessario evitare che il server principale ricicli i vecchi file WAL che non sono ancora stati applicati al server di standby. In questo caso dovrai ricreare la replica da zero.
Replica logica
La replica logica di PostgreSQL è un metodo per replicare gli oggetti dati e le relative modifiche, in base alla loro identità di replica (di solito una chiave primaria). Si basa su una modalità di pubblicazione e sottoscrizione, in cui uno o più abbonati si iscrivono a una o più pubblicazioni su un nodo editore.
Una pubblicazione è un insieme di modifiche generate da una tabella o da un gruppo di tabelle. Il nodo in cui è definita una pubblicazione è denominato editore. Una sottoscrizione è il lato a valle della replica logica. Il nodo in cui è definita una sottoscrizione è denominato abbonato e definisce la connessione a un altro database e insieme di pubblicazioni (una o più) a cui desidera iscriversi. Gli abbonati estraggono i dati dalle pubblicazioni a cui si iscrivono.
La replica logica è costruita con un'architettura simile alla replica fisica dello streaming. È implementato dai processi "walsender" e "applica". Il processo walsender avvia la decodifica logica del WAL e carica il plug-in di decodifica logica standard. Il plugin trasforma le modifiche lette da WAL nel protocollo di replica logica e filtra i dati in base alle specifiche di pubblicazione. I dati vengono quindi trasferiti continuamente utilizzando il protocollo di replica in streaming all'application worker, che mappa i dati su tabelle locali e applica le singole modifiche man mano che vengono ricevute, in un corretto ordine transazionale.
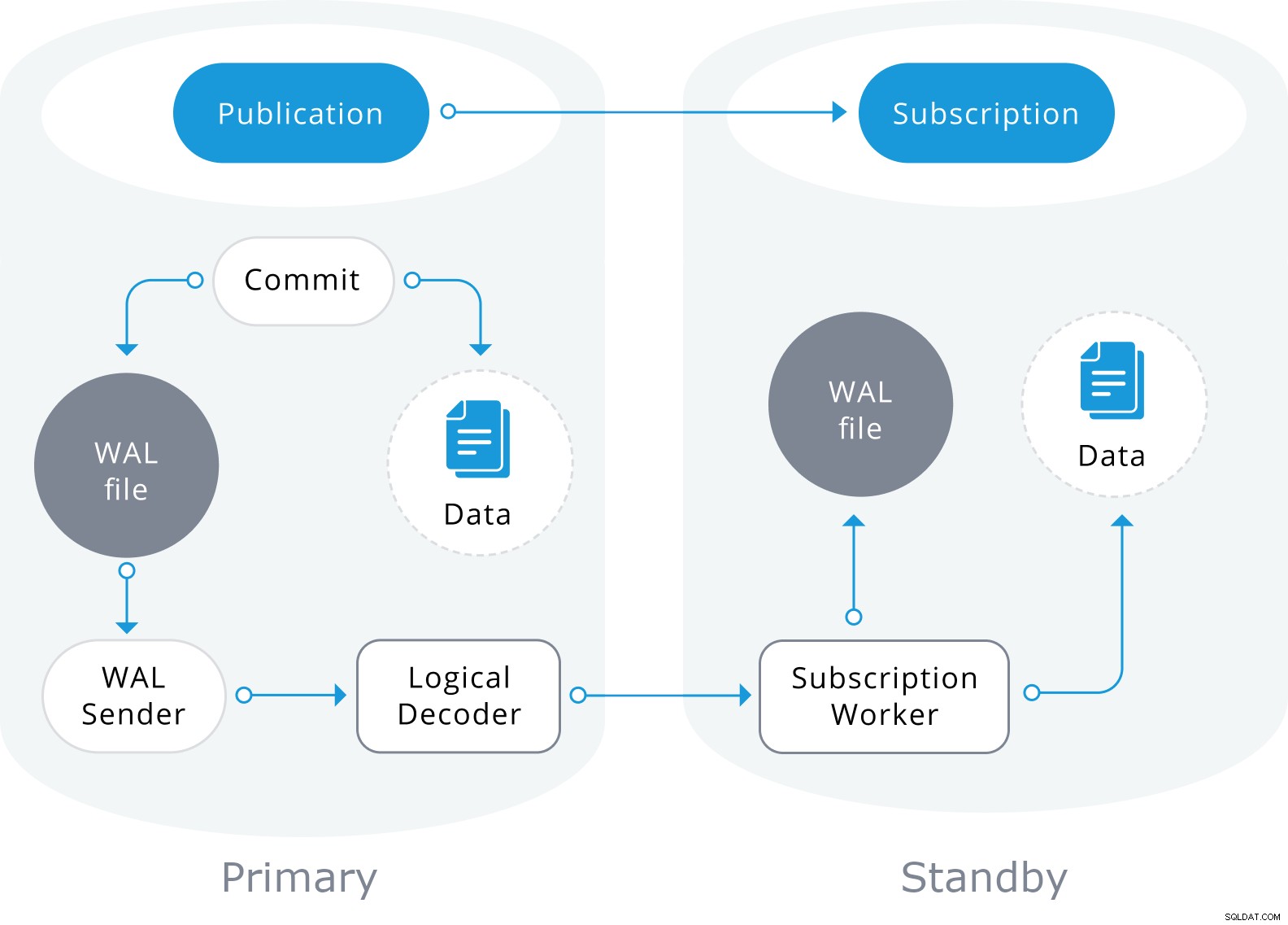
La replica logica inizia acquisendo uno snapshot dei dati nel database dell'editore e copiandolo all'abbonato. I dati iniziali nelle tabelle sottoscritte esistenti vengono catturati e copiati in un'istanza parallela di un tipo speciale di processo di applicazione. Questo processo creerà il proprio slot di replica temporaneo e copierà i dati esistenti. Una volta copiati i dati esistenti, il lavoratore entra in modalità di sincronizzazione, che assicura che la tabella venga portata a uno stato sincronizzato con il processo di applicazione principale trasmettendo in streaming tutte le modifiche avvenute durante la copia dei dati iniziale utilizzando la replica logica standard. Una volta eseguita la sincronizzazione, il controllo della replica della tabella viene restituito al processo di applicazione principale in cui la replica continua normalmente. Le modifiche sull'editore vengono inviate all'abbonato man mano che si verificano in tempo reale.
Modalità di replica in PostgreSQL
La replica in PostgreSQL può essere sincrona o asincrona.
Replica asincrona
È la modalità predefinita. Qui è possibile avere alcune transazioni impegnate nel nodo primario che non sono state ancora replicate sul server di standby. Ciò significa che esiste la possibilità di una potenziale perdita di dati. Questo ritardo nel processo di commit dovrebbe essere molto piccolo se il server di standby è abbastanza potente da tenere il passo con il carico. Se questo piccolo rischio di perdita di dati non è accettabile in azienda, puoi invece utilizzare la replica sincrona.
Replica sincrona
Ogni commit di una transazione di scrittura attenderà fino alla conferma che il commit è stato scritto sul disco di registrazione write-ahead sia del server primario che di quello di standby. Questo metodo riduce al minimo la possibilità di perdita di dati. Affinché si verifichi una perdita di dati, è necessario che sia il primario che lo standby si interrompano contemporaneamente.
Lo svantaggio di questo metodo è lo stesso per tutti i metodi sincroni poiché con questo metodo aumenta il tempo di risposta per ogni transazione di scrittura. Ciò è dovuto alla necessità di attendere fino a quando tutte le conferme che la transazione è stata impegnata. Fortunatamente, le transazioni di sola lettura non saranno interessate da questo ma; solo le transazioni di scrittura.
Alta disponibilità per la replica PostgreSQL
L'elevata disponibilità è un requisito per molti sistemi, indipendentemente dalla tecnologia che utilizziamo, e ci sono diversi approcci per raggiungere questo obiettivo utilizzando diversi strumenti.
Bilanciamento del carico
I sistemi di bilanciamento del carico sono strumenti che possono essere utilizzati per gestire il traffico dalla tua applicazione per ottenere il massimo dall'architettura del tuo database. Non solo è utile per bilanciare il carico dei nostri database, ma aiuta anche le applicazioni a essere reindirizzate ai nodi disponibili/integri e persino a specificare porte con ruoli diversi.
HAProxy è un sistema di bilanciamento del carico che distribuisce il traffico da un'origine a una o più destinazioni e può definire regole e/o protocolli specifici per questa attività. Se una qualsiasi delle destinazioni smette di rispondere, viene contrassegnata come offline e il traffico viene inviato alle altre destinazioni disponibili. Avere un solo nodo Load Balancer genererà un Single Point of Failure, quindi per evitare ciò, dovresti distribuire almeno due nodi HAProxy e configurare Keepalived tra di loro.
Keepalived è un servizio che ci permette di configurare un IP virtuale all'interno di un gruppo di server attivo/passivo. Questo IP virtuale è assegnato a un server attivo. Se questo server si guasta, l'IP viene automaticamente migrato sul server passivo "Secondario", consentendogli di continuare a lavorare con lo stesso IP in modo trasparente per i sistemi.
Miglioramento delle prestazioni sulla replica PostgreSQL
Le prestazioni sono sempre importanti in qualsiasi sistema. Dovrai fare buon uso delle risorse disponibili per garantire il miglior tempo di risposta possibile e ci sono diversi modi per farlo. Ogni connessione a un database consuma risorse, quindi uno dei modi per migliorare le prestazioni del tuo database PostgreSQL è disporre di un buon pool di connessioni tra la tua applicazione e i server del database.
Collegamenti in pool
Un pool di connessioni è un metodo per creare un pool di connessioni e riutilizzarle, evitando di aprire continuamente nuove connessioni al database, il che aumenterà notevolmente le prestazioni delle tue applicazioni. PgBouncer è un popolare pool di connessioni progettato per PostgreSQL.
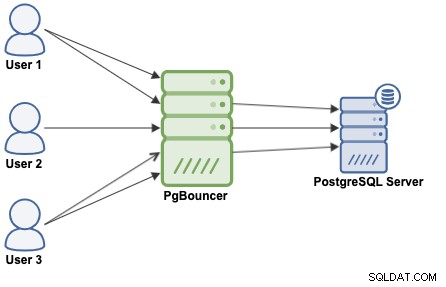
PgBouncer funge da server PostgreSQL, quindi devi solo accedere al tuo database utilizzando le informazioni di PgBouncer (Indirizzo IP/Nome host e Porta) e PgBouncer creerà una connessione al server PostgreSQL, oppure ne riutilizzerà una se esiste.
Quando PgBouncer riceve una connessione, esegue l'autenticazione, che dipende dal metodo specificato nel file di configurazione. PgBouncer supporta tutti i meccanismi di autenticazione supportati dal server PostgreSQL. Successivamente, PgBouncer verifica la presenza di una connessione memorizzata nella cache, con la stessa combinazione nome utente + database. Se viene trovata una connessione memorizzata nella cache, restituisce la connessione al client, in caso contrario crea una nuova connessione. A seconda della configurazione di PgBouncer e del numero di connessioni attive, potrebbe essere possibile che la nuova connessione venga accodata fino a quando non può essere creata, o addirittura interrotta.
Con tutti questi concetti citati, nella seconda parte di questo blog, vedremo come combinarli per avere un buon ambiente di replica in PostgreSQL.