Potresti aver sentito parlare del termine "failover" nel contesto della replica di MySQL. Forse ti sei chiesto cosa sia mentre stai iniziando la tua avventura con i database. Forse sai di cosa si tratta ma non sei sicuro dei potenziali problemi ad esso correlati e di come possono essere risolti?
In questo post del blog cercheremo di darti un'introduzione alla gestione del failover in MySQL e MariaDB.
Discuteremo cos'è il failover, perché è inevitabile, qual è la differenza tra failover e switchover. Discuteremo il processo di failover nella forma più generica. Toccheremo anche un po' i diversi problemi che dovrai affrontare in relazione al processo di failover.
Cosa significa "failover"?
La replica di MySQL è un insieme di nodi, ognuno dei quali può svolgere un ruolo alla volta. Può diventare un master o una replica. C'è un solo nodo master alla volta. Questo nodo riceve il traffico di scrittura e replica le scritture nelle sue repliche.
Come puoi immaginare, essendo un unico punto di ingresso per i dati nel cluster di replica, il nodo master è piuttosto importante. Cosa accadrebbe se non funzionasse e diventasse non disponibile?
Questa è una condizione piuttosto seria per un cluster di replica. Non può accettare alcuna scrittura in un dato momento. Come ci si può aspettare, una delle repliche dovrà assumere le attività del master e iniziare ad accettare le scritture. Potrebbe essere necessario modificare anche il resto della topologia di replica:le repliche rimanenti dovrebbero cambiare il loro master dal vecchio nodo non riuscito a quello appena scelto. Questo processo di "promozione" di una replica per diventare un master dopo che il vecchio master ha fallito è chiamato "failover".
D'altra parte, il "passaggio" si verifica quando l'utente attiva la promozione della replica. Un nuovo master viene promosso da una replica puntata dall'utente e il vecchio master, in genere, diventa una replica del nuovo master.
La differenza più importante tra "failover" e "switchover" è lo stato del vecchio master. Quando viene eseguito un failover, il vecchio master è, in qualche modo, non raggiungibile. Potrebbe essersi arrestato in modo anomalo, potrebbe aver subito un partizionamento di rete. Non può essere utilizzato in un dato momento e il suo stato è, in genere, sconosciuto.
D'altra parte, quando viene eseguito un passaggio, il vecchio maestro è vivo e vegeto. Questo ha gravi conseguenze. Se un master è irraggiungibile, può significare che alcuni dati non sono ancora stati inviati agli slave (a meno che non sia stata utilizzata la replica semisincrona). Alcuni dei dati potrebbero essere stati danneggiati o inviati parzialmente.
Esistono meccanismi in atto per evitare la propagazione di tali danneggiamenti sugli slave, ma il punto è che alcuni dati potrebbero andare persi durante il processo. Durante l'esecuzione di uno switchover, invece, è disponibile il vecchio master e viene mantenuta la coerenza dei dati.
Processo di failover
Dedichiamo un po' di tempo a discutere di come appare esattamente il processo di failover.
È stato rilevato un crash principale
Per cominciare, un master deve arrestarsi in modo anomalo prima che venga eseguito il failover. Quando non è disponibile, viene attivato un failover. Finora sembra semplice, ma la verità è che siamo già su un terreno scivoloso.
Prima di tutto, come viene testata la salute del maestro? Viene testato da una posizione o vengono distribuiti i test? Il software di gestione del failover tenta semplicemente di connettersi al master o implementa verifiche più avanzate prima che venga dichiarato un errore del master?
Immaginiamo la seguente topologia:
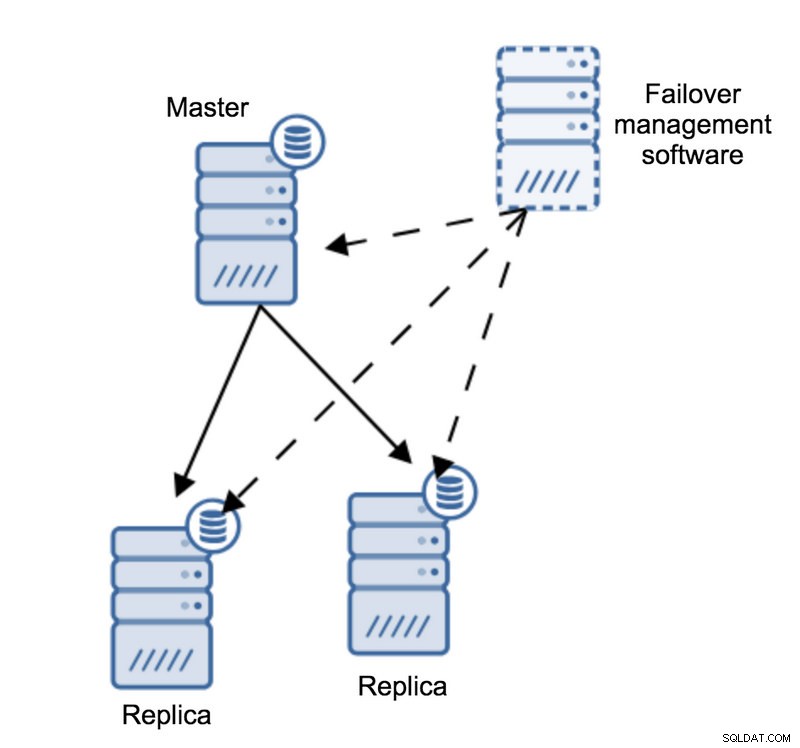
Abbiamo un master e due repliche. Abbiamo anche un software di gestione del failover situato su un host esterno. Cosa accadrebbe se una connessione di rete tra l'host con software di failover e il master fallisse?
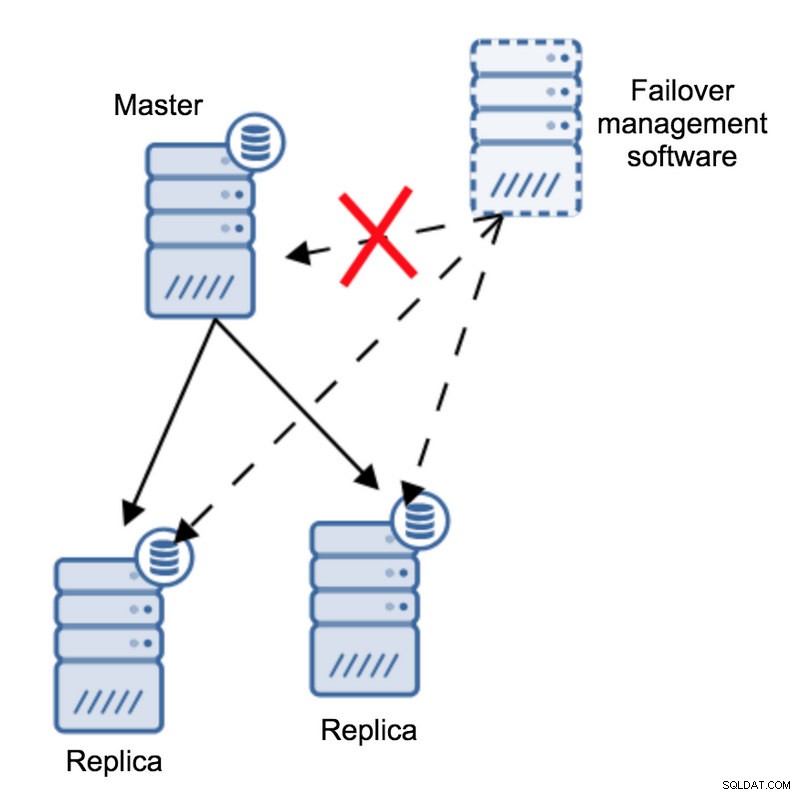
Secondo il software di gestione del failover, il master si è arrestato in modo anomalo:non c'è connettività ad esso. Tuttavia, la replica stessa funziona perfettamente. Quello che dovrebbe succedere qui è che il software di gestione del failover proverebbe a connettersi alle repliche e vedere qual è il loro punto di vista.
Si lamentano di una replica non funzionante o stanno replicando felicemente?
Le cose possono diventare ancora più complesse. E se aggiungessimo un proxy (o un insieme di proxy)? Verrà utilizzato per instradare il traffico:scrive sul master e legge sulle repliche. Cosa succede se un proxy non può accedere al master? Cosa succede se nessuno dei proxy può accedere al master?
Ciò significa che l'applicazione non può funzionare in tali condizioni. Dovrebbe essere attivato il failover (in realtà, sarebbe più un passaggio poiché il master è tecnicamente attivo)?
Tecnicamente, il master è vivo ma non può essere utilizzato dall'applicazione. Qui deve entrare la logica aziendale e prendere una decisione.
Impedire al vecchio maestro di correre
Non importa come e perché, se si decide di promuovere una delle repliche per diventare un nuovo maestro, il vecchio maestro deve essere fermato e, idealmente, non dovrebbe essere in grado di ricominciare.
Il modo in cui ciò può essere ottenuto dipende dai dettagli del particolare ambiente; pertanto questa parte del processo di failover è comunemente rafforzata da script esterni integrati nel processo di failover tramite diversi hook.
Questi script possono essere progettati per utilizzare gli strumenti disponibili in un particolare ambiente per fermare il vecchio master. Può essere una chiamata CLI o API che arresterà una VM; può essere un codice shell che esegue comandi attraverso una sorta di dispositivo di "gestione delle luci spente"; può essere uno script che invia trap SNMP all'unità di distribuzione dell'alimentazione che disabilita le prese di corrente utilizzate dal vecchio master (senza alimentazione elettrica possiamo essere sicuri che non si riavvierà).
Se un software di gestione del failover fa parte di un prodotto più complesso, che gestisce anche il ripristino dei nodi (come nel caso di ClusterControl), il vecchio master potrebbe essere contrassegnato come escluso dalle routine di ripristino.
Potresti chiederti perché è così importante impedire che il vecchio maestro diventi di nuovo disponibile?
Il problema principale è che nelle impostazioni di replica è possibile utilizzare un solo nodo per le scritture. In genere ti assicuri che abilitando una variabile di sola lettura (e super_sola_lettura, se applicabile) su tutte le repliche e mantenendola disabilitata solo sul master.
Una volta che un nuovo master è stato promosso, avrà read_only disabilitato. Il problema è che, se il vecchio master non è disponibile, non possiamo riportarlo a read_only=1. Se MySQL o un host si arresta in modo anomalo, questo non è un grosso problema poiché è buona norma avere my.cnf configurato con tale impostazione, quindi, una volta avviato MySQL, si avvia sempre in modalità di sola lettura.
Il problema mostra quando non si tratta di un arresto anomalo ma di un problema di rete. Il vecchio master è ancora in esecuzione con read_only disabilitato, semplicemente non è disponibile. Quando le reti convergono, ti ritroverai con due nodi scrivibili. Questo può essere o meno un problema. Alcuni dei proxy utilizzano l'impostazione di sola lettura come indicatore se un nodo è un master o una replica. La visualizzazione di due master in un determinato momento può causare un grosso problema poiché i dati vengono scritti su entrambi gli host, ma le repliche ottengono solo la metà del traffico di scrittura (la parte che ha colpito il nuovo master).
A volte si tratta di impostazioni hardcoded in alcuni script che sono configurati per connettersi solo a un determinato host. Normalmente fallirebbero e qualcuno noterebbe che il master è cambiato.
Con il vecchio master disponibile, si collegheranno felicemente ad esso e si verificherà discrepanza nei dati. Come puoi vedere, assicurarsi che il vecchio master non si avvii è un elemento di priorità piuttosto alta.
Decidi un candidato per il Master
Il vecchio padrone è a terra e non tornerà dalla sua tomba, ora è il momento di decidere quale host dovremmo usare come nuovo padrone. Di solito c'è più di una replica tra cui scegliere, quindi è necessario prendere una decisione. Ci sono molte ragioni per cui una replica può essere scelta rispetto a un'altra, pertanto è necessario eseguire dei controlli.
Liste bianche e liste nere
Per cominciare, un team che gestisce i database potrebbe avere i suoi motivi per scegliere una replica rispetto a un'altra quando decide su un candidato master. Forse sta utilizzando hardware più debole o gli è stato assegnato un lavoro particolare (quella replica esegue backup, query analitiche, gli sviluppatori hanno accesso ad essa ed eseguono query personalizzate e fatte a mano). Forse è una replica di prova in cui una nuova versione viene sottoposta a test di accettazione prima di procedere con l'aggiornamento. La maggior parte dei software di gestione del failover supporta whitelist e blacklist, che possono essere utilizzate per definire con precisione quali repliche devono o non possono essere utilizzate come candidati master.
Replica semisincrona
Una configurazione di replica può essere una combinazione di repliche asincrone e semisincrone. C'è un'enorme differenza tra loro:è garantito che la replica semisincrona contenga tutti gli eventi dal master. Una replica asincrona potrebbe non aver ricevuto tutti i dati, pertanto il failover potrebbe causare la perdita di dati. Preferiremmo vedere repliche semisincrone da promuovere.
Ritardo di replica
Anche se una replica semisincrona conterrà tutti gli eventi, tali eventi possono comunque risiedere solo nei registri di inoltro. Con traffico intenso, tutte le repliche, non importa se semi-sincronizzate o asincrone, potrebbero essere in ritardo.
Il problema con il ritardo di replica è che, quando si promuove una replica, è necessario ripristinare le impostazioni di replica in modo che non tenti di connettersi al vecchio master. Ciò rimuoverà anche tutti i registri di inoltro, anche se non sono ancora applicati, il che porta alla perdita di dati.
Anche se non si ripristinano le impostazioni di replica, non è comunque possibile aprire un nuovo master alle connessioni se non ha applicato tutti gli eventi dal registro di inoltro. In caso contrario, rischierai che le nuove query influiscano sulle transazioni del registro di inoltro, innescando ogni tipo di problema (ad esempio, un'applicazione potrebbe rimuovere alcune righe a cui accedono le transazioni dal registro di inoltro).
Prendendo in considerazione tutto ciò, l'unica opzione sicura è attendere l'applicazione del registro di inoltro. Tuttavia, potrebbe volerci un po' di tempo se la replica presentava un notevole ritardo. È necessario prendere decisioni su quale replica sarebbe un master migliore:asincrono, ma con un piccolo ritardo o semi-sincrono, ma con un ritardo che richiederebbe una notevole quantità di tempo per l'applicazione.
Transazioni errate
Anche se le repliche non dovrebbero essere scritte, potrebbe comunque succedere che qualcuno (o qualcosa) gli abbia scritto.
Potrebbe essere stata solo una singola transazione in passato, ma potrebbe comunque avere un grave effetto sulla capacità di eseguire un failover. Il problema è strettamente correlato al Global Transaction ID (GTID), una funzionalità che assegna un ID distinto a ogni transazione eseguita su un determinato nodo MySQL.
Al giorno d'oggi è una configurazione piuttosto popolare in quanto offre grandi livelli di flessibilità e consente prestazioni migliori (con repliche multi-thread).
Il problema è che, durante la riassegnazione a un nuovo master, la replica GTID richiede che tutti gli eventi di quel master (che non sono stati eseguiti sulla replica) siano replicati nella replica.
Consideriamo il seguente scenario:ad un certo punto nel passato, è avvenuta una scrittura su una replica. È passato molto tempo e questo evento è stato eliminato dai registri binari della replica. Ad un certo punto un master ha fallito e la replica è stata nominata come nuovo master. Tutte le repliche rimanenti verranno svincolate dal nuovo master. Chiederanno informazioni sulle transazioni eseguite sul nuovo master. Risponderà con un elenco di GTID provenienti dal vecchio master e il singolo GTID relativo a quella vecchia scrittura. I GTID del vecchio master non rappresentano un problema poiché tutte le repliche rimanenti ne contengono almeno la maggior parte (se non tutti) e tutti gli eventi mancanti dovrebbero essere sufficientemente recenti da essere disponibili nei log binari del nuovo master.
Nel peggiore dei casi, alcuni eventi mancanti verranno letti dai registri binari e trasferiti alle repliche. Il problema è con quella vecchia scrittura:è successo solo su un nuovo master, mentre era ancora una replica, quindi non esiste sugli host rimanenti. È un vecchio evento quindi non c'è modo di recuperarlo dai log binari. Di conseguenza, nessuna delle repliche sarà in grado di asservire il nuovo master. L'unica soluzione qui è intraprendere un'azione manuale e iniettare un evento vuoto con quel GTID problematico su tutte le repliche. Significa anche che, a seconda di quanto accaduto, le repliche potrebbero non essere sincronizzate con il nuovo master.
Come puoi vedere, è molto importante tenere traccia delle transazioni errate e determinare se è sicuro promuovere una determinata replica per diventare un nuovo master. Se contiene transazioni errate, potrebbe non essere l'opzione migliore.
Gestione failover per l'applicazione
È fondamentale tenere presente che l'interruttore principale, forzato o meno, ha un effetto sull'intera topologia. Le scritture devono essere reindirizzate a un nuovo nodo. Questa operazione può essere eseguita in diversi modi ed è fondamentale garantire che questa modifica sia il più trasparente possibile per l'applicazione. In questa sezione daremo uno sguardo ad alcuni esempi di come il failover può essere reso trasparente all'applicazione.
DNS
Uno dei modi in cui un'applicazione può essere indirizzata a un master consiste nell'utilizzare le voci DNS. Con un TTL basso è possibile modificare l'indirizzo IP a cui punta una voce DNS come 'master.dc1.example.com'. Tale modifica può essere eseguita tramite script esterni eseguiti durante il processo di failover.
Scoperta del servizio
Strumenti come Consul o etc.d possono essere utilizzati anche per indirizzare il traffico verso una posizione corretta. Tali strumenti possono contenere informazioni sul fatto che l'IP del master corrente è impostato su un valore. Alcuni di essi danno anche la possibilità di utilizzare le ricerche di nomi host per puntare a un IP corretto. Anche in questo caso, è necessario mantenere le voci negli strumenti di rilevamento dei servizi e uno dei modi per farlo è apportare tali modifiche durante il processo di failover, utilizzando hook eseguiti in diverse fasi del failover.
Delega
I proxy possono anche essere usati come fonte di verità sulla topologia. In generale, indipendentemente da come scoprono la topologia (può essere un processo automatico o il proxy deve essere riconfigurato quando la topologia cambia), dovrebbero contenere lo stato corrente della catena di replica, altrimenti non sarebbero in grado di instradare correttamente le query.
L'approccio per utilizzare un proxy come fonte di verità può essere abbastanza comune insieme all'approccio per collocare proxy sugli host delle applicazioni. Ci sono numerosi vantaggi nella collocazione di proxy e server Web:comunicazione veloce e sicura utilizzando il socket Unix, mantenendo un livello di memorizzazione nella cache (poiché alcuni dei proxy, come ProxySQL possono anche eseguire la memorizzazione nella cache) vicino all'applicazione. In tal caso, ha senso che l'applicazione si connetta semplicemente al proxy e presuppone che instraderà le query correttamente.
Failover in ClusterControl
ClusterControl applica le migliori pratiche del settore per assicurarsi che il processo di failover venga eseguito correttamente. Garantisce inoltre che il processo sia sicuro:le impostazioni predefinite hanno lo scopo di interrompere il failover se vengono rilevati possibili problemi. Tali impostazioni possono essere sovrascritte dall'utente se desidera dare la priorità al failover rispetto alla sicurezza dei dati.
Una volta rilevato un errore principale da ClusterControl, viene avviato un processo di failover e viene immediatamente eseguito un primo hook di failover:

Successivamente, viene verificata la disponibilità principale.

ClusterControl esegue test approfonditi per assicurarsi che il master non sia effettivamente disponibile. Questo comportamento è abilitato di default ed è gestito dalla seguente variabile:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Come passaggio successivo, ClusterControl assicura che il vecchio master sia inattivo e, in caso contrario, ClusterControl non tenterà di ripristinarlo:

Il passaggio successivo consiste nel determinare quale host può essere utilizzato come candidato master. ClusterControl controlla se è stata definita una whitelist o una blacklist.
Puoi farlo utilizzando le seguenti variabili nel file di configurazione di cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.È anche possibile configurare ClusterControl per cercare le differenze nei filtri di log binari in tutte le repliche. Può essere fatto usando la variabile replication_check_binlog_filtration_bf_failover. Per impostazione predefinita, questi controlli sono disabilitati. ClusterControl verifica inoltre che non siano in atto transazioni errate, che potrebbero causare problemi.

Puoi anche chiedere a ClusterControl di ricostruire automaticamente le repliche che non possono essere replicate dal nuovo master utilizzando le seguenti impostazioni nel file di configurazione cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Successivamente viene eseguito un secondo script:è definito nell'impostazione replication_pre_failover_script. Successivamente, un candidato viene sottoposto al processo di preparazione.


ClusterControl attende l'applicazione dei registri di ripristino (assicurando che la perdita di dati sia minima). Verifica inoltre se sono disponibili altre transazioni sulle repliche rimanenti, che non sono state applicate al candidato master. Entrambi i comportamenti possono essere controllati dall'utente, utilizzando le seguenti impostazioni nel file di configurazione cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Come puoi vedere, puoi forzare un failover anche se non tutti gli eventi del log di ripristino sono stati applicati:consente all'utente di decidere quale ha la priorità più alta:coerenza dei dati o velocità di failover.


Infine, viene eletto il master e viene eseguito l'ultimo script (uno script che può essere definito replication_post_failover_script.
Se non hai ancora provato ClusterControl, ti consiglio di scaricarlo (è gratuito) e provarlo.
Rilevamento principale in ClusterControl
ClusterControl ti dà la possibilità di distribuire lo stack ad alta disponibilità completo, inclusi i livelli di database e proxy. La scoperta del maestro è sempre uno dei problemi da affrontare.
Come funziona in ClusterControl?
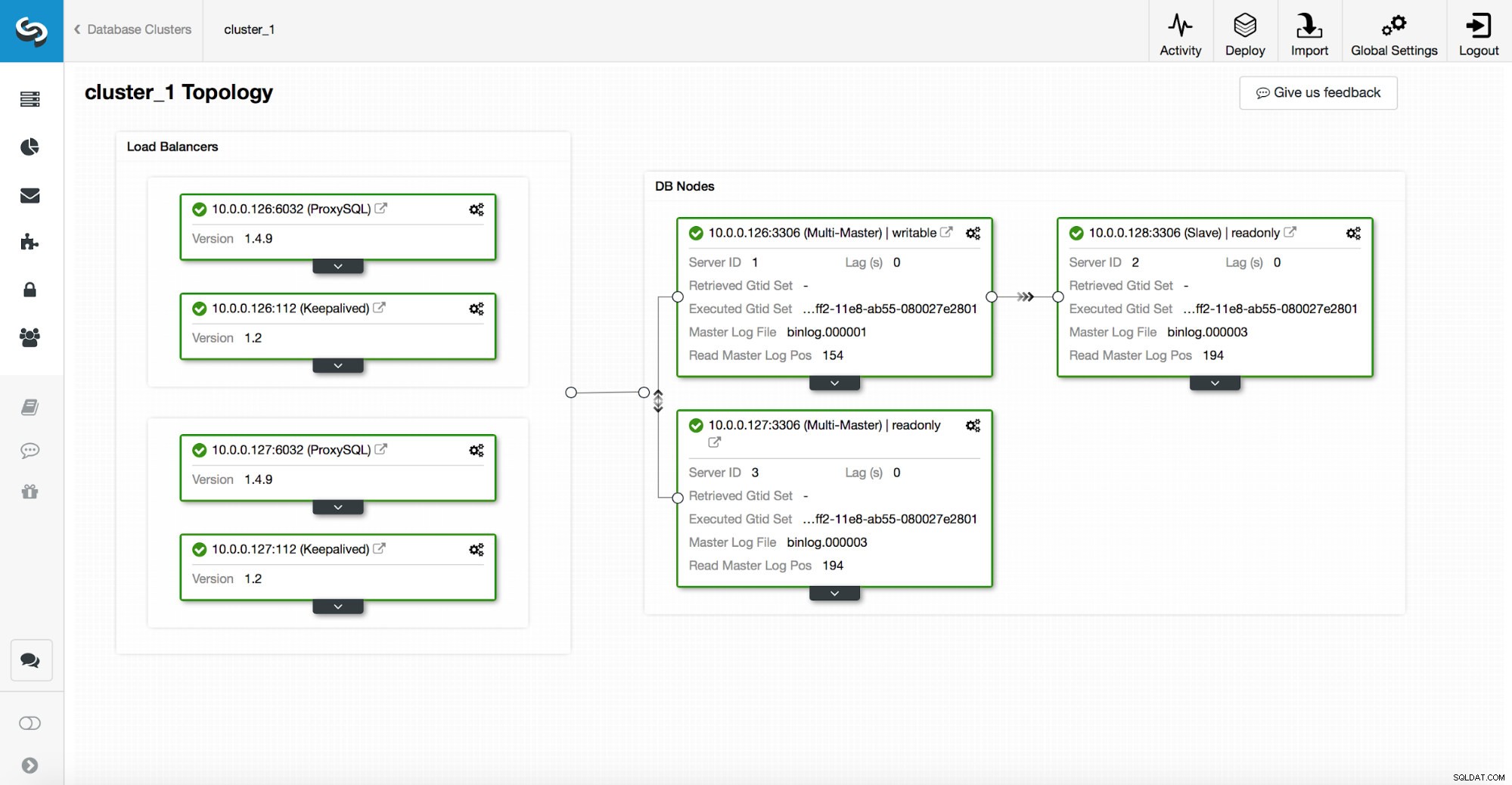
Uno stack ad alta disponibilità, distribuito tramite ClusterControl, è costituito da tre parti:
- Livello database
- livello proxy che può essere HAProxy o ProxySQL
- livello keepalived, che, con l'uso di IP virtuale, garantisce un'elevata disponibilità del livello proxy
I proxy si basano su variabili di sola lettura sui nodi.
Come puoi vedere nello screenshot sopra, solo un nodo nella topologia è contrassegnato come "scrivibile". Questo è il master e questo è l'unico nodo che riceverà le scritture.
Un proxy (in questo esempio, ProxySQL) monitorerà questa variabile e si riconfigura automaticamente.
Dall'altro lato dell'equazione, ClusterControl si occupa delle modifiche alla topologia:failover e switchover. Apporterà le modifiche necessarie al valore di sola lettura per riflettere lo stato della topologia dopo la modifica. Se viene promosso un nuovo master, diventerà l'unico nodo scrivibile. Se un master viene eletto dopo il failover, sarà disabilitato in sola lettura.
Sopra il livello proxy, viene distribuito keepalived. Distribuisce un VIP e monitora lo stato dei nodi proxy sottostanti. VIP punta a un nodo proxy alla volta. Se questo nodo si interrompe, l'IP virtuale viene reindirizzato a un altro nodo, assicurando che il traffico diretto a VIP raggiunga un nodo proxy integro.
Per riassumere, un'applicazione si connette al database utilizzando un indirizzo IP virtuale. Questo IP punta a uno dei proxy. I proxy reindirizzano il traffico in base alla struttura della topologia. Le informazioni sulla topologia derivano dallo stato di sola lettura. Questa variabile è gestita da ClusterControl ed è impostata in base alle modifiche alla topologia richieste dall'utente o ClusterControl eseguite automaticamente.