Lo scenario migliore è che, in caso di guasto del database, hai un buon Disaster Recovery Plan (DRP) e un ambiente altamente disponibile con un processo di failover automatico, ma... cosa succede se fallisce per qualche motivo inaspettato? Cosa succede se è necessario eseguire un failover manuale? In questo blog condivideremo alcuni consigli da seguire nel caso in cui sia necessario eseguire il failover del database.
Controlli di verifica
Prima di eseguire qualsiasi modifica, è necessario verificare alcune cose di base per evitare nuovi problemi dopo il processo di failover.
Stato della replica
Potrebbe essere possibile che, al momento dell'errore, il nodo slave non sia aggiornato, a causa di un errore di rete, di un carico elevato o di un altro problema, quindi è necessario assicurarsi che il slave ha tutte (o quasi tutte) le informazioni. Se hai più di un nodo slave, dovresti anche controllare quale è il nodo più avanzato e sceglierlo per il failover.
es:controlliamo lo stato della replica in un server MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Nel caso di PostgreSQL, è un po' diverso in quanto è necessario controllare lo stato dei WAL e confrontare quelli applicati con quelli recuperati.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Credenziali
Prima di eseguire il failover, devi verificare se la tua applicazione/i tuoi utenti potranno accedere al tuo nuovo master con le credenziali correnti. Se non stai replicando gli utenti del tuo database, forse le credenziali sono state modificate, quindi dovrai aggiornarle nei nodi slave prima di qualsiasi modifica.
es:puoi interrogare la tabella utente nel database mysql per verificare le credenziali utente in un MariaDB/MySQL Server:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)In caso di PostgreSQL, puoi usare il comando '\du' per conoscere i ruoli, e devi anche controllare il file di configurazione pg_hba.conf per gestire l'accesso utente (non le credenziali). Quindi:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}E pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustAccesso alla rete/al firewall
Le credenziali non sono l'unico problema possibile per accedere al tuo nuovo master. Se il nodo si trova in un altro data center o hai un firewall locale per filtrare il traffico, devi verificare se ti è consentito accedervi o anche se hai il percorso di rete per raggiungere il nuovo nodo master.
es:iptables. Consentiamo il traffico dalla rete 167.124.57.0/24 e controlliamo le regole attuali dopo averlo aggiunto:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationes:rotte. Supponiamo che il tuo nuovo nodo master sia nella rete 10.0.0.0/24, il tuo server delle applicazioni sia in 192.168.100.0/24 e tu possa raggiungere la rete remota usando 192.168.100.100, quindi nel tuo server delle applicazioni, aggiungi il percorso corrispondente:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Punti azione
Dopo aver verificato tutti i punti menzionati, dovresti essere pronto per eseguire le azioni per il failover del tuo database.
Nuovo indirizzo IP
Poiché promuoverai un nodo slave, l'indirizzo IP principale cambierà, quindi dovrai cambiarlo nell'applicazione o nell'accesso client.
L'utilizzo di un Load Balancer è un modo eccellente per evitare questo problema/modifica. Dopo il processo di failover, Load Balancer rileverà il vecchio master come offline e (dipende dalla configurazione) invierà il traffico a quello nuovo per scriverci sopra, quindi non è necessario modificare nulla nell'applicazione.
es:Vediamo un esempio per una configurazione HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkIn questo caso, se un nodo è inattivo, HAProxy non invierà traffico lì e invierà il traffico solo al nodo disponibile.
Riconfigura i nodi slave
Se hai più di un nodo slave, dopo aver promosso uno di essi, devi riconfigurare il resto degli slave per connetterti al nuovo master. Questa potrebbe essere un'attività che richiede tempo, a seconda del numero di nodi.
Verifica e configura i backup
Dopo aver impostato tutto (nuovo master promosso, slave riconfigurati, applicazione scritta nel nuovo master), è importante intraprendere le azioni necessarie per prevenire un nuovo problema, quindi i backup sono un must in questo passaggio. Molto probabilmente avevi una politica di backup in esecuzione prima dell'incidente (in caso contrario, devi averla di sicuro), quindi devi controllare se i backup sono ancora in esecuzione o funzioneranno nella nuova topologia. Potrebbe essere possibile che i backup siano in esecuzione sul vecchio master o che utilizzi il nodo slave che ora è master, quindi devi verificarlo per assicurarti che la tua policy di backup funzioni ancora dopo le modifiche.
Monitoraggio database
Quando esegui un processo di failover, il monitoraggio è d'obbligo prima, durante e dopo il processo. Con questo, puoi prevenire un problema prima che peggiori, rilevare un problema imprevisto durante il failover o anche sapere se qualcosa va storto dopo di esso. Ad esempio, devi monitorare se la tua applicazione può accedere al tuo nuovo master controllando il numero di connessioni attive.
Metriche chiave da monitorare
Vediamo alcune delle metriche più importanti di cui tenere conto:
- Ritardo di replica
- Stato della replica
- Numero di connessioni
- Utilizzo/errori della rete
- Carico del server (CPU, memoria, disco)
- Database e registri di sistema
Ripristino
Ovviamente, se qualcosa è andato storto, devi essere in grado di tornare indietro. Bloccare il traffico verso il vecchio nodo e mantenerlo il più isolato possibile potrebbe essere una buona strategia per questo, quindi nel caso in cui sia necessario eseguire il rollback, avrai il vecchio nodo disponibile. Se il rollback è dopo alcuni minuti, a seconda del traffico, probabilmente dovrai inserire i dati di questi minuti nel vecchio master, quindi assicurati di avere anche il tuo nodo master temporaneo disponibile e isolato per prendere queste informazioni e riapplicarle .
Automatizzazione del processo di failover con ClusterControl
Vedendo tutte queste attività necessarie per eseguire un failover, molto probabilmente vorrai automatizzarlo ed evitare tutto questo lavoro manuale. Per questo, puoi sfruttare alcune delle funzionalità che ClusterControl può offrirti per diverse tecnologie di database, come il ripristino automatico, i backup, la gestione degli utenti, il monitoraggio, tra le altre funzionalità, tutte dallo stesso sistema.
Con ClusterControl puoi verificare lo stato della replica e il relativo ritardo, creare o modificare credenziali, conoscere lo stato della rete e dell'host e ancora più verifiche.
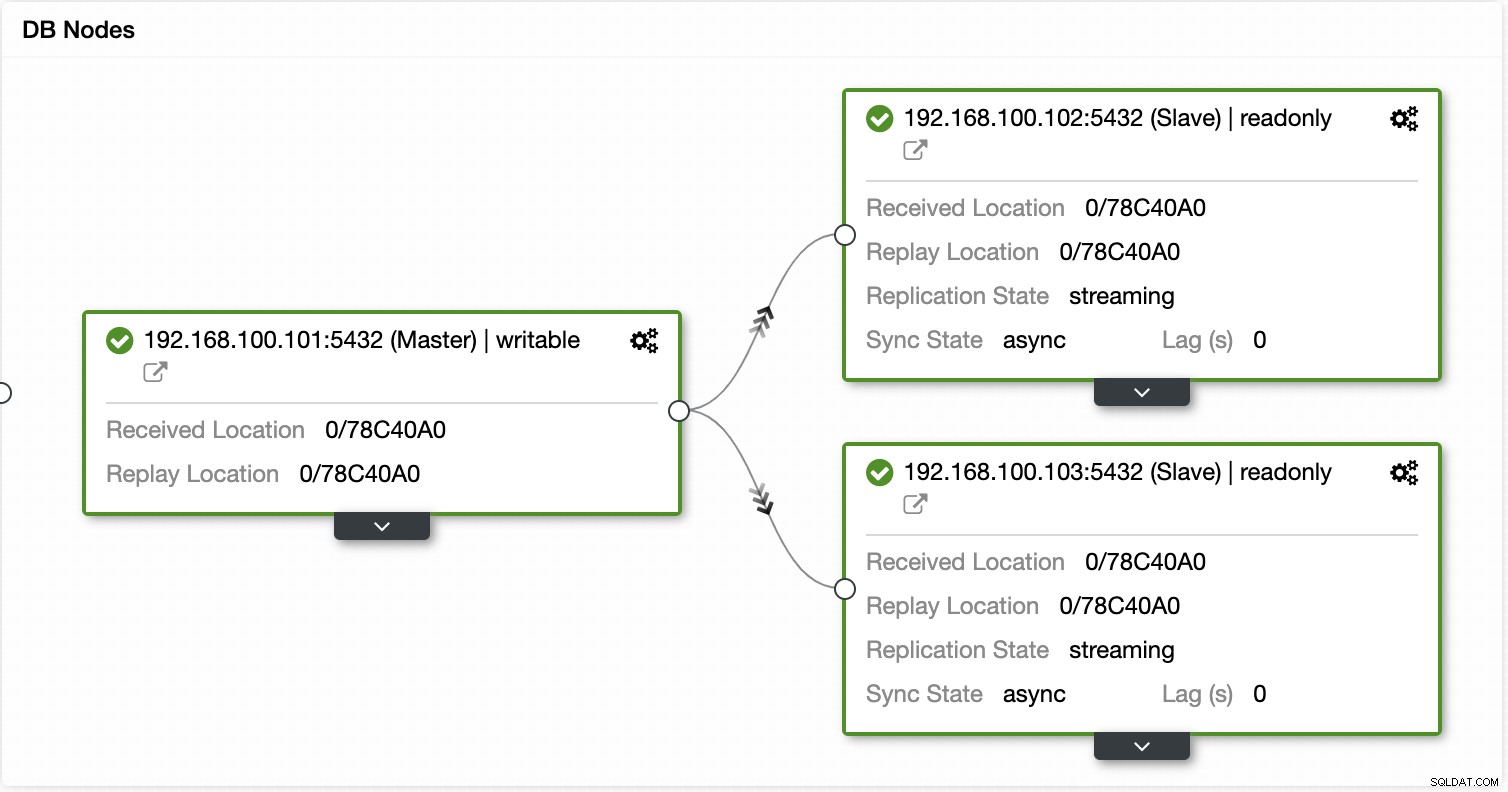
Utilizzando ClusterControl puoi anche eseguire diverse azioni cluster e nodi, come promuovere slave , riavvia il database e il server, aggiungi o rimuovi nodi di database, aggiungi o rimuovi nodi di bilanciamento del carico, ricostruisci uno slave di replica e altro ancora.
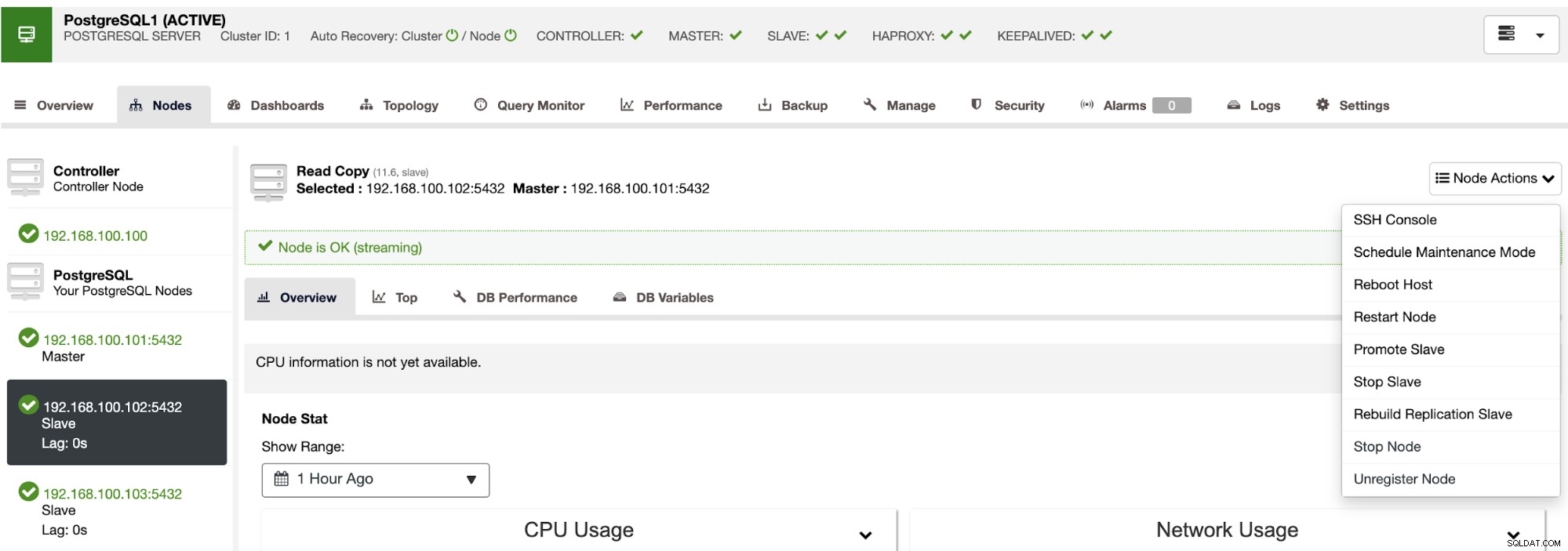
Utilizzando queste azioni puoi anche eseguire il rollback del failover, se necessario, ricostruendo e promuovendo il maestro precedente.
ClusterControl dispone di servizi di monitoraggio e avviso che ti aiutano a sapere cosa sta succedendo o anche se è successo qualcosa in precedenza.
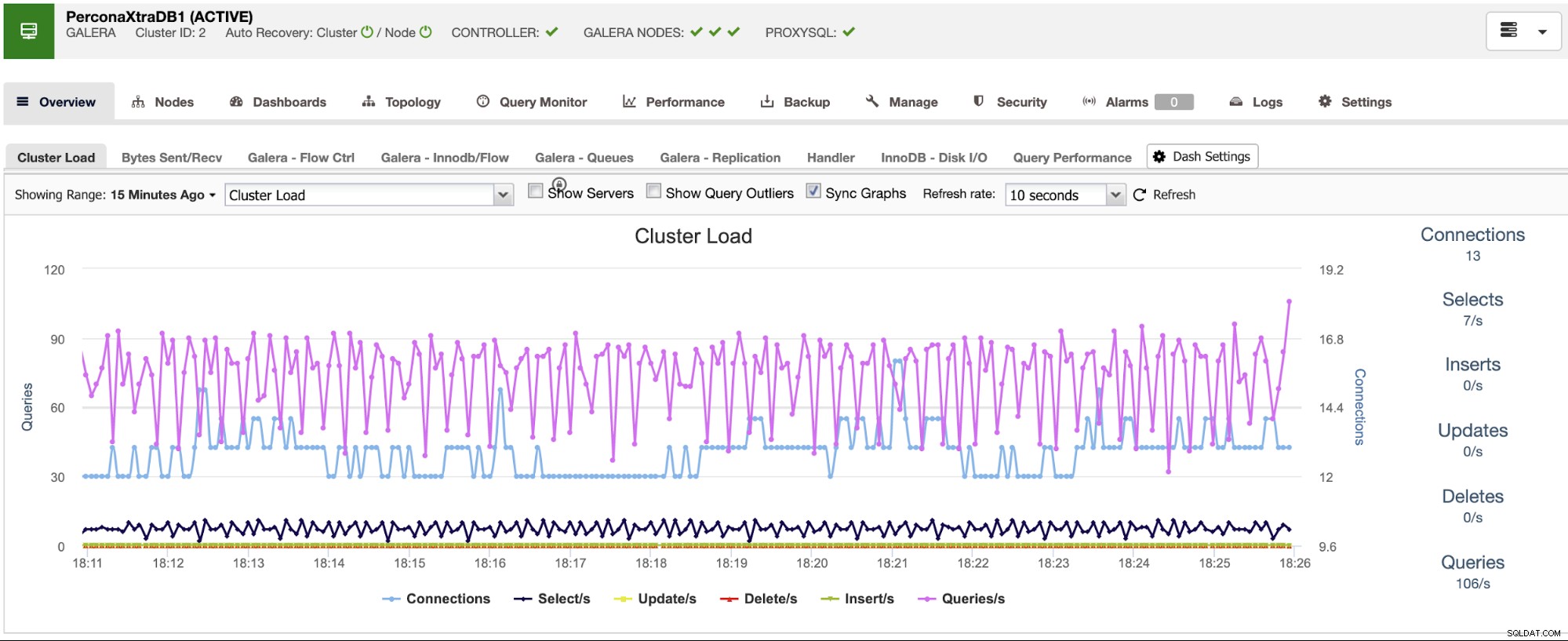
Puoi anche utilizzare la sezione dashboard per avere una visualizzazione più intuitiva sullo stato dei tuoi sistemi.
Conclusione
In caso di errore del database principale, vorrai avere tutte le informazioni in atto per intraprendere le azioni necessarie il prima possibile. Avere un buon DRP è la chiave per mantenere il tuo sistema in esecuzione tutto (o quasi) il tempo. Questo DRP dovrebbe includere un processo di failover ben documentato per avere un RTO (Recovery Time Objective) accettabile per l'azienda.