Nel blog precedente, abbiamo trattato alcuni suggerimenti e trucchi per preparare un server MySQL per l'utilizzo in produzione dal punto di vista dell'amministratore di sistema. Questo post del blog è la continuazione...
Utilizzare uno strumento di backup del database
Ogni strumento di backup ha i suoi vantaggi e svantaggi. Ad esempio, Percona Xtrabackup (o MariaDB Backup per MariaDB) può eseguire un hot-backup fisico senza bloccare i database, ma può essere ripristinato solo nella stessa versione su un'altra istanza. Mentre per mysqldump, è compatibile in modo incrociato con altre versioni principali di MySQL e molto più semplice per il backup parziale, anche se è relativamente più lento durante il ripristino rispetto a Percona Xtrabackup su grandi database. MySQL 5.7 introduce anche mysqlpump, simile a mysqldump con capacità di elaborazione parallela per accelerare il processo di dump.
Non mancare di configurare tutti questi strumenti di backup nel tuo server MySQL in quanto sono disponibili gratuitamente e molto critici per il recupero dei dati. Poiché mysqldump e mysqlpump sono già inclusi in MySQL 5.7 e versioni successive, dobbiamo solo installare Percona Xtrabackup (o MariaDB Backup per MariaDB) ma richiede alcuni preparativi, come mostrato nei seguenti passaggi:
Fase uno
Assicurati che lo strumento di backup e le sue dipendenze siano installati:
$ yum install -y epel-release
$ yum install -y socat pv percona-xtrabackupPer i server MariaDB, usa invece MariaDB Backup:
$ yum install -y socat pv MariaDB-BackupFase due
Crea utente 'xtrabackup' su master se non esiste:
mysql> CREATE USER 'xtrabackup'@'localhost' IDENTIFIED BY 'Km4z9^sT2X';
mysql> GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'xtrabackup'@'localhost';Fase tre
Crea un altro utente chiamato 'mysqldump' su master se non esiste. Questo utente verrà utilizzato per 'mysqldump' e 'mysqlpump':
mysql> CREATE USER 'mysqldump'@'localhost' IDENTIFIED BY 'Km4z9^sT2X';
mysql> GRANT SELECT, SHOW VIEW, EVENT, TRIGGER, LOCK TABLES, RELOAD, REPLICATION CLIENT ON *.* TO 'mysqldump'@'localhost';Fase quattro
Aggiungi le credenziali degli utenti di backup all'interno del file di configurazione di MySQL nella direttiva [xtrabackup], [mysqldump] e [mysqlpump]:
$ cat /etc/my.cnf
...
[xtrabackup]
user=xtrabackup
password='Km4z9^sT2X'
[mysqldump]
user=mysqldump
password='Km4z9^sT2X'
[mysqlpump]
user=mysqldump
password='Km4z9^sT2X'Specificando le righe precedenti, non è necessario specificare nome utente e password nel comando di backup poiché lo strumento di backup caricherà automaticamente quelle opzioni di configurazione dal file di configurazione principale.
Assicurati in anticipo che gli strumenti di backup siano stati testati correttamente. Per Xtrabackup che supporta lo streaming di backup tramite rete, questo deve essere prima testato per assicurarsi che il collegamento di comunicazione possa essere stabilito correttamente tra il server di origine e di destinazione. Sul server di destinazione, esegui il seguente comando affinché Socat ascolti la porta 9999 e sia pronto ad accettare lo streaming in entrata:
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysqlQuindi, crea un backup sul server di origine e invialo in streaming alla porta 9999 sul server di destinazione:
$ innobackupex --socket=/var/lib/mysql/mysql.sock --stream=xbstream /var/lib/mysql/ | socat - TCP4:192.168.0.202:9999Dovresti ottenere un flusso continuo di output dopo aver eseguito il comando di backup. Attendi finché non vedi la riga "Completed OK" che indica un backup riuscito.
Con pv, possiamo limitare l'utilizzo della larghezza di banda o vedere l'avanzamento come un processo che viene condotto attraverso di essa. In genere, il processo di streaming saturerà la rete se non è abilitato il throttling e ciò potrebbe causare problemi con altri server nell'interazione con un altro nello stesso segmento. Usando pv, possiamo rallentare il processo di streaming prima di passarlo allo strumento di streaming come socat o netcat. L'esempio seguente mostra che lo streaming di backup sarà limitato a circa 80 MB/s sia per le connessioni in entrata che in uscita:
$ innobackupex --slave-info --socket=/var/lib/mysql/mysql.sock --stream=xbstream /var/lib/mysql/ | pv -q -L 80m | socat - TCP4:192.168.0.202:9999Lo streaming di un backup viene comunemente utilizzato per eseguire lo stage di uno slave o archiviare il backup in remoto su un altro server.
Per mysqldump e mysqlpump, possiamo testare con i seguenti comandi:
$ mysqldump --set-gtid-purged=OFF --all-databases
$ mysqlpump --set-gtid-purged=OFF --all-databasesAssicurati di visualizzare righe non di errore nell'output.
Test di stress del server
Lo stress test del server del database è importante per comprendere la capacità massima che possiamo prevedere per quel particolare server. Ciò risulterà utile quando ci si avvicina a soglie o colli di bottiglia in una fase successiva. Puoi utilizzare molti strumenti di benchmarking disponibili sul mercato come mysqlslap, DBT2 e sysbench.
In questo esempio, utilizziamo sysbench per misurare le prestazioni di picco del server, il livello di saturazione e anche la temperatura dei componenti durante l'esecuzione in un ambiente con un carico di lavoro di database elevato. Ciò ti consentirà di comprendere a fondo quanto è buono il server e di anticipare il carico di lavoro che il server può elaborare per la nostra applicazione in produzione.
Per installare e configurare sysbench, puoi compilarlo dal sorgente o installare il pacchetto dal repository Percona:
$ yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
$ yum install -y sysbenchCrea lo schema del database e l'utente sul server MySQL:
mysql> CREATE DATABASE sbtest;
mysql> CREATE USER 'sbtest'@'localhost' IDENTIFIED BY 'sysbenchP4ss';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'localhost';Genera i dati del test:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host=localhost \
--mysql-user=sbtest \
--mysql-password=sysbenchP4ss \
--tables=50 \
--table-size=100000 \
prepareQuindi esegui il benchmark per 1 ora (3600 secondi):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=64 \
--max-requests=0 \
--db-driver=mysql \
--time=3600 \
--db-ps-mode=disable \
--mysql-host=localhost \
--mysql-user=sbtest \
--mysql-password=sysbenchP4ss \
--tables=50 \
--table-size=100000 \
runMentre il test è in esecuzione, usa iostat (disponibile nel pacchetto sysstat) in un altro terminale per monitorare l'utilizzo del disco, la larghezza di banda, IOPS e I/O wait:
$ yum install -y sysstat
$ iostat -x 60
avg-cpu: %user %nice %system %iowait %steal %idle
40.55 0.00 55.27 4.18 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.19 6.18 1236.23 816.92 61283.83 14112.44 73.44 4.00 1.96 2.83 0.65 0.34 69.29Il risultato sopra verrà stampato ogni 60 secondi. Attendi fino al termine del test e prendi la media di r/s (letture/secondo), w/s (scritture/secondo), %iowait, %util, rkB/s e wkB/s (larghezza di banda). Se stai riscontrando un utilizzo relativamente basso di disco, CPU, RAM o rete, probabilmente dovrai aumentare il valore "--threads" a un numero ancora più alto in modo da utilizzare tutte le risorse al limite.
Considera i seguenti aspetti da misurare di:
- Query al secondo =Riepilogo Sysbench una volta completato il test in Statistiche SQL -> Query -> Per sec.
- Latenza della query =riepilogo Sysbench una volta completato il test in Latenza (ms) -> 95° percentile.
- IOPS disco =media di r/s + w/s
- Utilizzo del disco =media di %util
- Larghezza di banda del disco R/W =Media di rkB/s / Media di wkB/s
- Disk IO wait =Media di %iowait
- Carico medio del server =carico medio medio riportato dal comando superiore.
- Utilizzo CPU MySQL =Utilizzo medio CPU riportato dal comando principale.
Con ClusterControl, puoi facilmente osservare e ottenere le informazioni di cui sopra tramite il pannello Panoramica dei nodi, come mostrato nella schermata seguente:
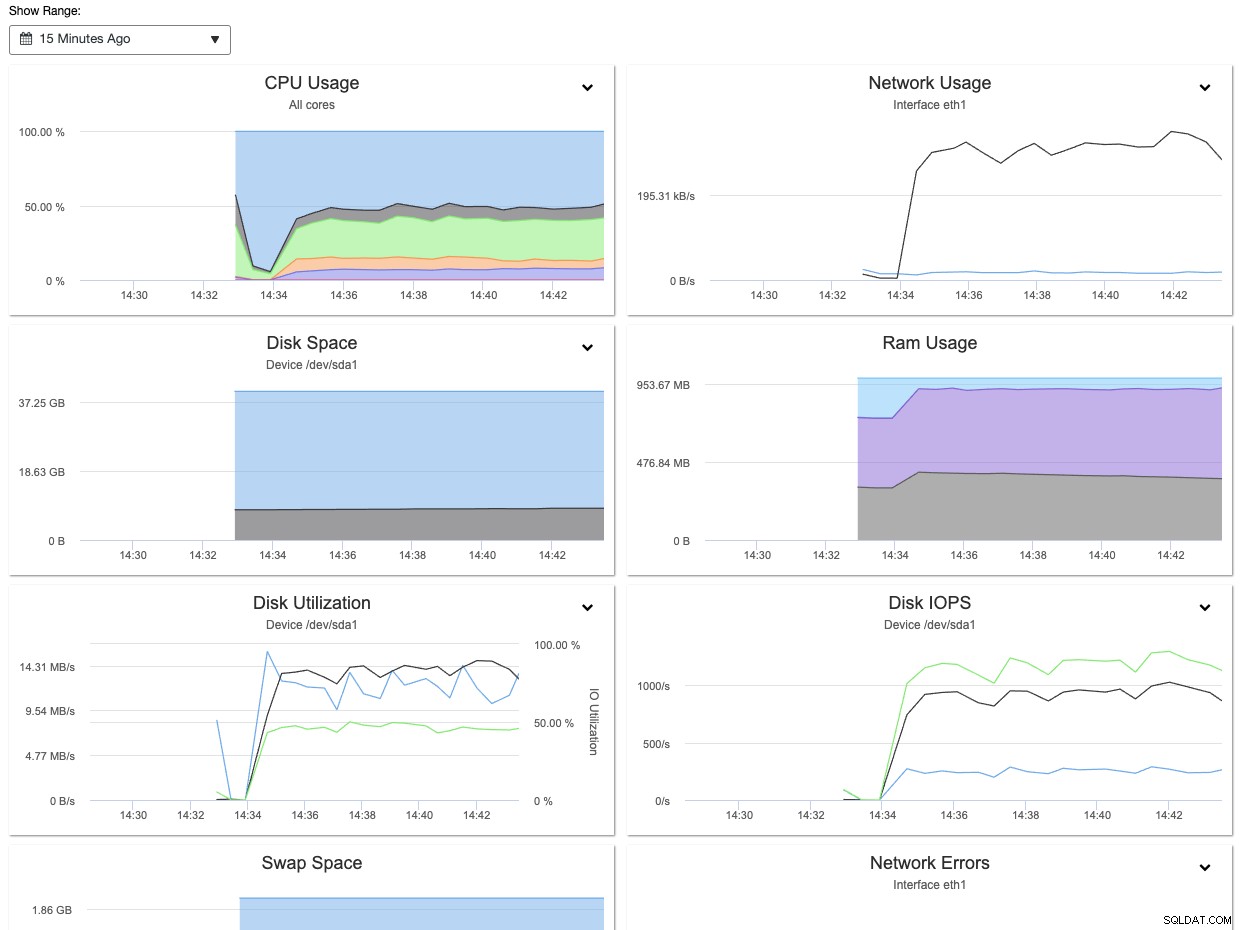
Inoltre, le informazioni raccolte durante lo stress test possono essere utilizzate per ottimizzare MySQL e variabili InnoDB di conseguenza come innodb_buffer_pool_size, innodb_io_capacity, innodb_io_capacity_max, innodb_write_io_threads, innodb_read_io_threads e anche max_connections.
Per saperne di più sul benchmark delle prestazioni di MySQL utilizzando sysbench, dai un'occhiata a questo post del blog, Come confrontare le prestazioni di MySQL e MariaDB utilizzando SysBench.
Utilizzare uno strumento di modifica dello schema online
Il cambio di schema è qualcosa che è inevitabile nei database relazionali. Man mano che l'applicazione cresce e diventa più impegnativa nel tempo, richiede sicuramente alcune modifiche alla struttura del database. Esistono alcune operazioni DDL che ricostruiranno la tabella bloccando così l'esecuzione di altre istruzioni DML e ciò potrebbe influire sulla disponibilità del database se si eseguono modifiche strutturali su una tabella enorme. Per vedere l'elenco delle operazioni DDL di blocco, controlla questa pagina della documentazione di MySQL e cerca le operazioni che hanno "Permits Concurrent DML" =No.
Se non puoi permetterti tempi di inattività sui server di produzione durante l'esecuzione della modifica dello schema, è probabilmente una buona idea configurare lo strumento di modifica dello schema online nella fase iniziale. In questo esempio, installiamo e configuriamo gh-ost, una modifica dello schema online creata da Github. Gh-ost utilizza il flusso di log binario per acquisire le modifiche alla tabella e applicarle in modo asincrono alla tabella fantasma.
Per installare gh-ost su un box CentOS, segui semplicemente i seguenti passaggi:
Fase uno
Scarica l'ultimo gh-ost da qui:
$ wget https://github.com/github/gh-ost/releases/download/v1.0.48/gh-ost-1.0.48-1.x86_64.rpmFase due
Installa il pacchetto:
$ yum localinstall gh-ost-1.0.48-1.x86_64.rpm Fase tre
Crea un utente del database per gh-ost se non esiste e concedigli i privilegi appropriati:
mysql> CREATE USER 'gh-ost'@'{host}' IDENTIFIED BY 'ghostP455';
mysql> GRANT ALTER, CREATE, DELETE, DROP, INDEX, INSERT, LOCK TABLES, SELECT, TRIGGER, UPDATE ON {db_name}.* TO 'gh-ost'@'{host}';
mysql> GRANT SUPER, REPLICATION SLAVE ON *.* TO 'gh-ost'@'{host}';** Sostituisci {host} e {db_name} con i valori appropriati. Idealmente, {host} è uno degli host slave che eseguirà la modifica dello schema online. Fare riferimento alla documentazione di gh-ost per i dettagli.
Fase quattro
Crea il file di configurazione di gh-ost per memorizzare il nome utente e la password in /root/.gh-ost.cnf:
[client]
user=gh-ost
password=ghostP455Allo stesso modo, è possibile configurare Percona Toolkit Online Schema Change (pt-osc) sul server del database. L'idea è assicurarsi di essere preparati con questo strumento prima sul server di database che probabilmente eseguirà questa operazione in futuro.
Utilizza Percona Toolkit
Percona Toolkit è una raccolta di strumenti a riga di comando open source avanzati, sviluppati da Percona, progettati per eseguire una varietà di server MySQL, MongoDB e PostgreSQL e attività di sistema troppo difficili o complesse da eseguire manualmente. Questi strumenti sono diventati l'ultimo salvatore, utilizzato dai DBA di tutto il mondo per affrontare o risolvere problemi tecnici riscontrati nei server MySQL e MariaDB.
Per installare Percona Toolkit, esegui semplicemente il seguente comando:
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
$ yum install percona-toolkitCi sono oltre 30 strumenti disponibili all'interno di questo pacchetto. Alcuni di essi sono progettati specificamente per MongoDB e PostgreSQL. Alcuni degli strumenti più popolari per la risoluzione dei problemi e l'ottimizzazione delle prestazioni di MySQL sono pt-stalk, pt-mysql-summary, pt-query-digest, pt-table-checksum, pt-table-sync e pt-archiver. Questo toolkit può aiutare i DBA a verificare l'integrità della replica di MySQL controllando la coerenza dei dati master e di replica, archiviare in modo efficiente righe, trovare indici duplicati, analizzare query MySQL da log e tcpdump e molto altro.
L'esempio seguente mostra uno degli strumenti di output (pt-table-checksum) in cui può eseguire il controllo di coerenza della replica online eseguendo query di checksum sul master, che produce risultati diversi sulle repliche che non sono coerenti con il master:
$ pt-table-checksum --no-check-binlog-format --replicate-check-only
Checking if all tables can be checksummed ...
Starting checksum ...
Differences on mysql2.local
TABLE CHUNK CNT_DIFF CRC_DIFF CHUNK_INDEX LOWER_BOUNDARY UPPER_BOUNDARY
mysql.proc 1 0 1
mysql.tables_priv 1 0 1
mysql.user 1 1 1L'output sopra mostra che ci sono 3 tabelle sullo slave (mysql2.local) che non sono coerenti con il master. Possiamo quindi utilizzare lo strumento pt-table-sync per riparare i dati mancanti dal master o semplicemente risincronizzare nuovamente lo slave.
Blocca il server
Infine, una volta completata la fase di configurazione e preparazione, possiamo isolare il nodo del database dalla rete pubblica e limitare l'accesso del server a host e reti noti. Puoi utilizzare firewall (iptables, firewalld, ufw), gruppi di sicurezza, hosts.allow e/o hosts.deny o semplicemente disabilitare l'interfaccia di rete che si affaccia su Internet se hai più interfacce di rete.
Per iptables, è importante specificare un commento per ogni regola usando il flag '-m comment --comment':
$ iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 22 -m comment --comment 'Allow local net to SSH port' -j ACCEPT
$ iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 3306 -m comment --comment 'Allow local net to MySQL port' -j ACCEPT
$ iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 9999 -m comment --comment 'Allow local net to backup streaming port' -j ACCEPT
$ iptables -A INPUT -p tcp -s 0.0.0.0/0 -m comment --comment 'Drop everything apart from the above' -j DROPIn modo simile per il firewall di Ubuntu (ufw), dobbiamo prima definire la regola predefinita e quindi creare regole simili per MySQL/MariaDB simili a questa:
$ sudo ufw default deny incoming comment 'Drop everything apart from the above'
$ sudo ufw default allow outgoing comment 'Allow outgoing everything'
$ sudo ufw allow from 192.168.0.0/24 to any port 22 comment 'Allow local net to SSH port'
$ sudo ufw allow from 192.168.0.0/24 to any port 3306 comment 'Allow local net to MySQL port'
$ sudo ufw allow from 192.168.0.0/24 to any port 9999 comment 'Allow local net to backup streaming port'Abilita il firewall:
$ ufw enableQuindi, verifica che le regole siano caricate correttamente:
$ ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
22 ALLOW IN 192.168.0.0/24 # Allow local net to SSH port
3306 ALLOW IN 192.168.0.0/24 # Allow local net to MySQL port
9999 ALLOW IN 192.168.0.0/24 # Allow local net to backup streaming portAncora una volta, è molto importante specificare i commenti su ogni regola per aiutarci a capire meglio la regola.
Per la limitazione dell'accesso al database remoto, possiamo anche utilizzare il server VPN come mostrato in questo post del blog, Utilizzo di OpenVPN per proteggere l'accesso al cluster di database nel cloud.
Conclusione
La preparazione di un server di produzione non è ovviamente un compito facile, come abbiamo mostrato in questa serie di blog. Se sei preoccupato di sbagliare, perché non usi ClusterControl per distribuire il tuo cluster di database? ClusterControl ha un'ottima esperienza nell'implementazione di database e ha consentito fino ad oggi oltre 70.000 implementazioni MySQL e MariaDB per tutti gli ambienti.