Amazon Relational Database Service (AWS RDS) è un servizio di database completamente gestito che può supportare più motori di database. Tra quelli supportati ci sono PostgreSQL, MySQL e MariaDB. ClusterControl, d'altra parte, è un software di gestione e automazione del database che supporta anche la gestione del backup per i database open source PostgreSQL, MySQL e MariaDB.
Sebbene l'RDS sia stato ampiamente adottato da molte aziende, alcune potrebbero non avere familiarità con il funzionamento del loro Point-in-time Recovery (PITR) e come può essere utilizzato.
Diversi motori di database utilizzati da Amazon RDS hanno considerazioni speciali durante il ripristino da un momento specifico e in questo blog illustreremo come funziona per PostgreSQL, MySQL e MariaDB. Confronteremo anche le differenze con la funzione PITR in ClusterControl.
Cos'è il Point-in-Time Recovery (PITR)
Se non hai ancora familiarità con il Disaster Recovery Planning (DRP) o il Business Continuity Planning (BCP), dovresti sapere che PITR è una delle pratiche standard importanti per la gestione dei database. Come accennato nel nostro blog precedente, Point In Time Recovery (PITR) comporta il ripristino del database in un dato momento del passato. Per poterlo fare, dovremo ripristinare un backup completo e quindi PITR avrà luogo applicando tutte le modifiche avvenute in un momento specifico che desideri ripristinare.
Recupero point-in-time (PITR) con AWS RDS
AWS RDS gestisce PITR in modo diverso rispetto al modo tradizionale comune a un database locale. Il risultato finale condivide lo stesso concetto, ma con AWS RDS il backup completo è uno snapshot, quindi applica il PITR (che è archiviato in S3) e quindi avvia una nuova (diversa) istanza del database.
Il metodo comune richiede di utilizzare un backup logico (usando pg_dump, mysqldump, mydumper) o fisico (Percona Xtrabackup, Mariabackup, pg_basebackup, pg_backrest) prima di applicare il PITR.
AWS RDS richiederà di avviare una nuova istanza database, mentre l'approccio tradizionale consente di archiviare in modo flessibile il PITR sullo stesso nodo di database in cui è stato eseguito il backup o di scegliere come target un'istanza database diversa (esistente) che necessita di ripristino o in una nuova istanza database.
Al momento della creazione dell'istanza AWS RDS, verranno attivati i backup automatici. Amazon RDS esegue automaticamente uno snapshot giornaliero completo dei tuoi dati. Le pianificazioni delle istantanee possono essere impostate durante la creazione nella finestra di backup preferita. Mentre i backup automatici sono attivi, AWS acquisisce anche i log delle transazioni su Amazon S3 ogni 5 minuti registrando tutti gli aggiornamenti del tuo DB. Dopo aver avviato un ripristino point-in-time, i log delle transazioni vengono applicati al backup giornaliero più appropriato per ripristinare l'istanza database all'ora specifica richiesta.
Come applicare un PITR con AWS RDS
L'applicazione di PITR può essere eseguita in tre modi diversi. Puoi utilizzare la Console di gestione AWS, l'AWS CLI o l'API Amazon RDS una volta che l'istanza database è disponibile. Devi anche tenere in considerazione che i log delle transazioni vengono acquisiti ogni cinque minuti, che vengono poi archiviati in AWS S3.
Dopo aver ripristinato un'istanza database, il gruppo di sicurezza database (SG) predefinito viene applicato alla nuova istanza database. Se hai bisogno del db SG personalizzato, puoi definirlo in modo esplicito utilizzando la Console di gestione AWS, il comando AWS CLI modify-db-instance o l'operazione ModifyDBInstance dell'API Amazon RDS dopo che l'istanza database è disponibile.
PITR richiede di identificare l'ultimo tempo ripristinabile per un'istanza database. A tale scopo, puoi utilizzare il comando AWS CLI describe-db-instances e guardare il valore restituito nel campo LatestRestorableTime per l'istanza database. Ad esempio,
[example@sqldat.com ~]# aws rds describe-db-instances --db-instance-identifier database-s9s-mysql|grep LatestRestorableTime
"LatestRestorableTime": "2020-05-08T07:25:00+00:00",Applicazione di PITR con la Console AWS
Per applicare PITR nella Console AWS, accedi alla Console AWS → vai su Amazon RDS → Database → Seleziona (o fai clic) sull'istanza database desiderata, quindi fai clic su Azioni. Vedi sotto,
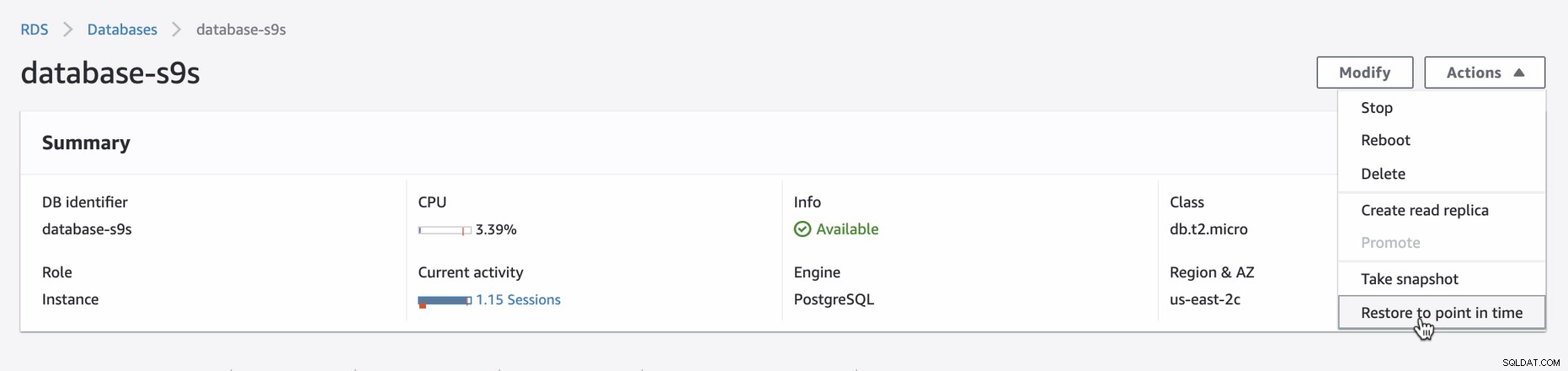
Una volta tentato il ripristino tramite PITR, l'interfaccia utente della console ti avviserà l'ultimo tempo di ripristino che è possibile impostare. È possibile utilizzare l'ultima ora ripristinabile o specificare la data e l'ora di destinazione desiderate. Vedi sotto:
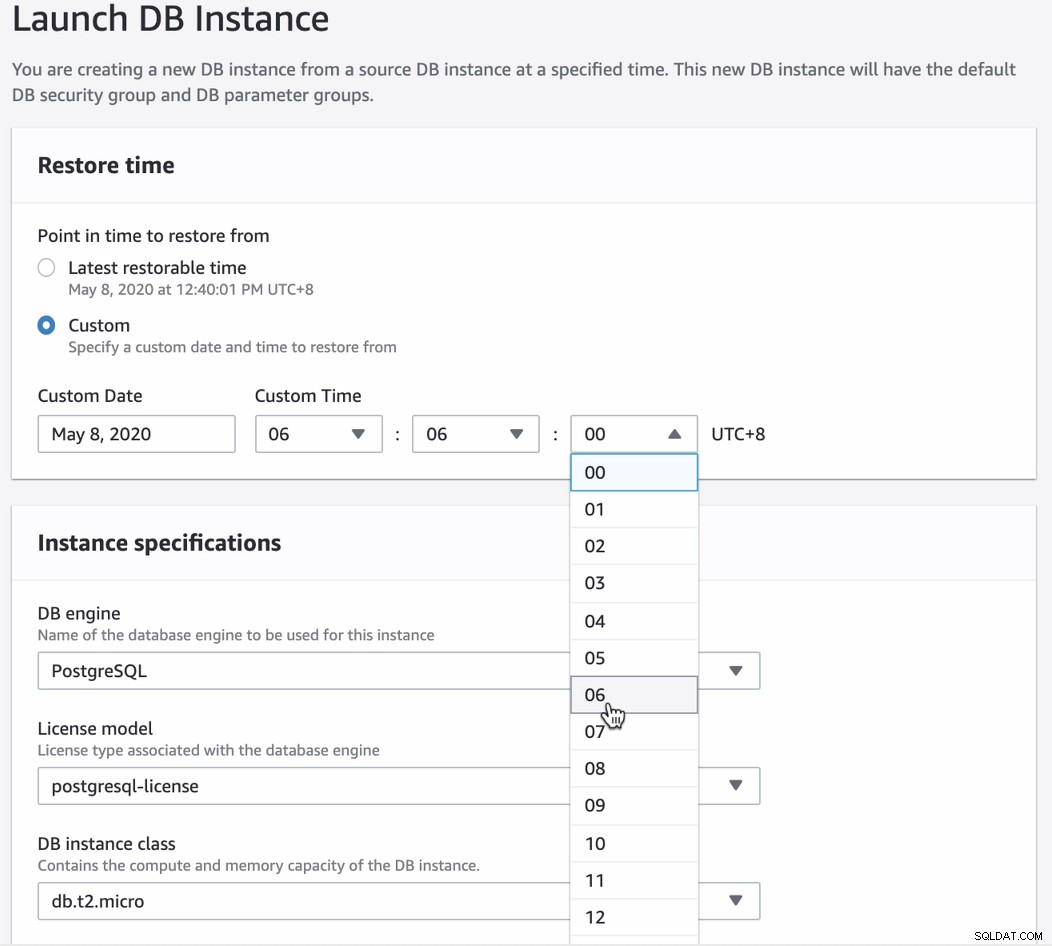
È abbastanza facile da seguire ma richiede attenzione e compilazione le specifiche desiderate necessarie per avviare la nuova istanza.
Applicazione di PITR con AWS CLI
L'utilizzo dell'AWS CLI può essere molto utile soprattutto se è necessario incorporarlo con gli strumenti di automazione per la pipeline CI/CD. Per fare ciò, puoi iniziare semplicemente con,
[example@sqldat.com ~]# aws rds restore-db-instance-to-point-in-time \
> --source-db-instance-identifier database-s9s-mysql \
> --target-db-instance-identifier database-s9s-mysql-pitr \
> --restore-time 2020-05-08T07:30:00+00:00
{
"DBInstance": {
"DBInstanceIdentifier": "database-s9s-mysql-pitr",
"DBInstanceClass": "db.t2.micro",
"Engine": "mysql",
"DBInstanceStatus": "creating",
"MasterUsername": "admin",
"DBName": "s9s",
"AllocatedStorage": 18,
"PreferredBackupWindow": "00:00-00:30",
"BackupRetentionPeriod": 7,
"DBSecurityGroups": [],
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-xxxxx",
"Status": "active"
}
],
"DBParameterGroups": [
{
"DBParameterGroupName": "default.mysql5.7",
"ParameterApplyStatus": "in-sync"
}
],
"DBSubnetGroup": {
"DBSubnetGroupName": "default",
"DBSubnetGroupDescription": "default",
"VpcId": "vpc-f91bdf90",
"SubnetGroupStatus": "Complete",
"Subnets": [
{
"SubnetIdentifier": "subnet-exxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2a"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2c"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2b"
},
"SubnetStatus": "Active"
}
]
},
"PreferredMaintenanceWindow": "fri:06:01-fri:06:31",
"PendingModifiedValues": {},
"MultiAZ": false,
"EngineVersion": "5.7.22",
"AutoMinorVersionUpgrade": true,
"ReadReplicaDBInstanceIdentifiers": [],
"LicenseModel": "general-public-license",
"OptionGroupMemberships": [
{
"OptionGroupName": "default:mysql-5-7",
"Status": "pending-apply"
}
],
"PubliclyAccessible": true,
"StorageType": "gp2",
"DbInstancePort": 0,
"StorageEncrypted": false,
"DbiResourceId": "db-XXXXXXXXXXXXXXXXX",
"CACertificateIdentifier": "rds-ca-2019",
"DomainMemberships": [],
"CopyTagsToSnapshot": false,
"MonitoringInterval": 0,
"DBInstanceArn": "arn:aws:rds:us-east-2:042171833148:db:database-s9s-mysql-pitr",
"IAMDatabaseAuthenticationEnabled": false,
"PerformanceInsightsEnabled": false,
"DeletionProtection": false,
"AssociatedRoles": []
}
}Entrambi questi approcci richiedono tempo per creare o preparare l'istanza del database finché non sarà disponibile e visualizzabile nell'elenco delle istanze del database nella tua console AWS RDS.
Limitazioni AWS RDS PITR
Quando utilizzi AWS RDS sei legato a loro come fornitore. Spostare le tue operazioni fuori dal loro sistema può essere problematico. Ecco alcune cose che devi considerare:
- Il livello di blocco del fornitore quando si utilizza AWS RDS
- La tua unica opzione per il ripristino tramite PITR richiede l'avvio di una nuova istanza in esecuzione su RDS
- Non è possibile eseguire il ripristino utilizzando il processo PITR su un nodo esterno non in RDS
- Richiede l'apprendimento e la familiarità con i loro strumenti e il framework di sicurezza.
Come applicare un PITR con ClusterControl
ClusterControl esegue PITR in modo semplice ma diretto (ma richiede che sia necessario abilitare o impostare i prerequisiti per poter utilizzare PITR). Come discusso in precedenza, PITR per ClusterControl funziona in modo diverso da AWS RDS. Di seguito un elenco di dove è possibile applicare PITR utilizzando ClusterControl (a partire dalla versione 1.7.6):
- Si applica dopo il backup completo in base alle soluzioni del metodo di backup disponibili che supportiamo per i database PostgreSQL, MySQL e MariaDB.
- Per PostgreSQL, solo il metodo di backup pg_basebackup è supportato e compatibile per funzionare con PITR
- Per MySQL o MariaDB, solo il metodo di backup xtrabackup/mariabackup è supportato e compatibile per funzionare con PITR
- Applicabile ai database MySQL o MariaDB, PITR si applica solo se il nodo di origine del backup completo è il nodo di destinazione da ripristinare.
- I database MySQL o MariaDB richiedono che la registrazione binaria sia abilitata
- Applicabile ai database PostgreSQL, PITR si applica solo al master/primario attivo e richiede l'abilitazione dell'archiviazione WAL.
- PITR può essere applicato solo durante il ripristino di un backup completo esistente
La gestione del backup per ClusterControl è applicabile per ambienti in cui i database non sono completamente gestiti e richiedono l'accesso SSH, che è totalmente diverso da AWS RDS. Sebbene condividano lo stesso risultato che è il ripristino dei dati, le soluzioni di backup presenti in ClusterControl non possono essere applicabili in AWS RDS. ClusterControl inoltre non supporta RDS per la gestione e il monitoraggio.
Utilizzo di ClusterControl per PITR in PostgreSQL
Come accennato in precedenza sui prerequisiti per sfruttare il PITR, è necessario abilitare l'archiviazione WAL. Questo può essere ottenuto facendo clic sull'icona a forma di ingranaggio come mostrato di seguito:
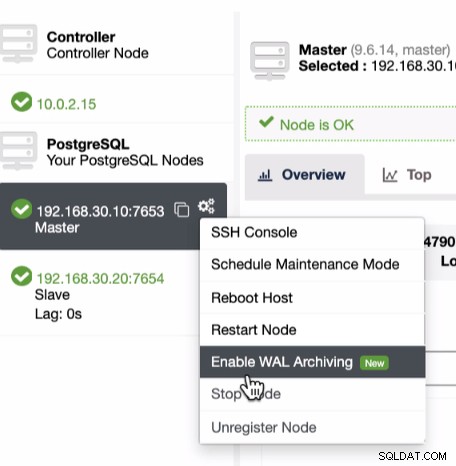
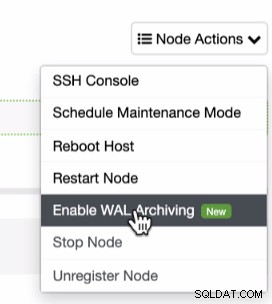
Poiché PITR può essere applicato subito dopo un backup completo, puoi solo eseguire trova questa funzione nell'elenco Backup in cui puoi tentare di ripristinare un backup esistente. Per farlo, la sequenza di schermate ti mostrerà come farlo:
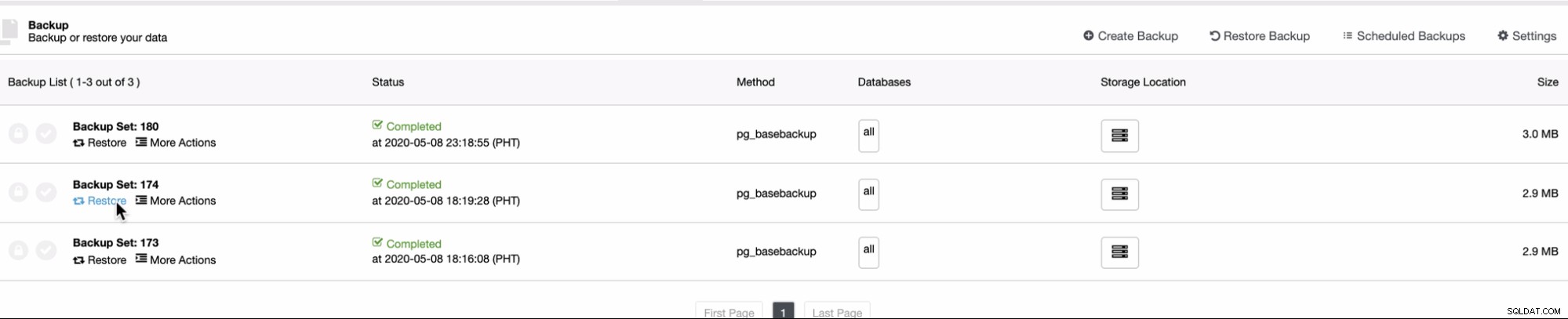
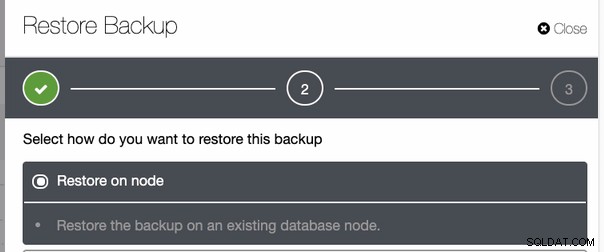
Quindi ripristinalo sullo stesso host dell'origine del backup eseguito ,
Quindi specifica la data e l'ora,
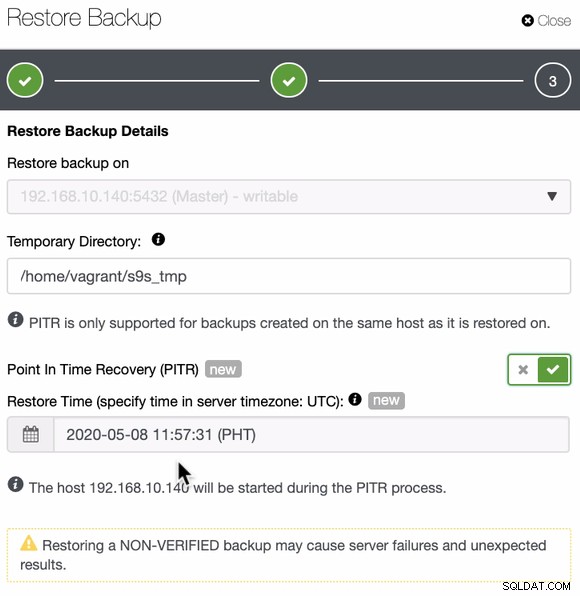
Una volta impostati e specificati la data e l'ora, ClusterControl ripristinerà il backup quindi applica il PITR al termine del backup. Puoi anche verificarlo esaminando i registri delle attività lavorative proprio come di seguito,

Utilizzo di ClusterControl per PITR in MySQL/MariaDB
PITR per MySQL o MariaDB non differisce dall'approccio che abbiamo sopra per PostgreSQL. Tuttavia, non esiste un'equivalenza di archiviazione WAL né un pulsante o un'opzione che è possibile impostare necessari per abilitare la funzionalità PITR. Poiché MySQL e MariaDB richiedono che un PITR possa essere applicato utilizzando i log binari, in ClusterControl, questo può essere gestito nella scheda Gestisci. Vedi sotto:
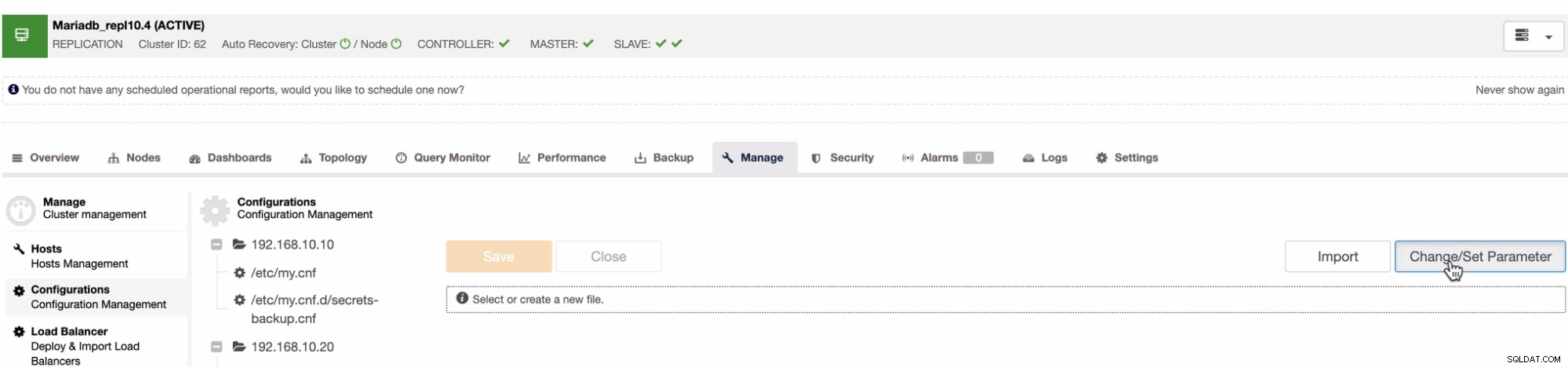
Quindi specifica la variabile log_bin con il valore booleano corrispondente. Ad esempio,
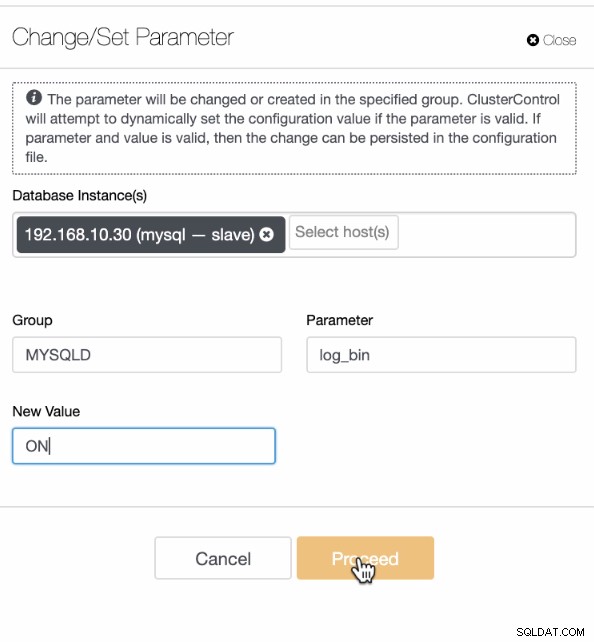
Una volta impostato log_bin sul nodo, assicurati di avere il backup effettuato sullo stesso nodo dove applicherai anche il processo di PITR. Questo è affermato in precedenza nei prerequisiti. In alternativa, puoi anche modificare i file di configurazione (/etc/my.cnf o /etc/mysql/my.cnf) e aggiungere log_bin=ON nella sezione [mysqld], ad esempio.
Quando i log binari sono abilitati ed è disponibile un backup completo, puoi quindi eseguire il processo PITR come l'interfaccia utente di PostgreSQL ma con campi diversi che puoi compilare. Puoi specificare la data e l'ora o specificare in base al file e alla posizione del binlog (o alla posizione x e y). Vedi sotto:
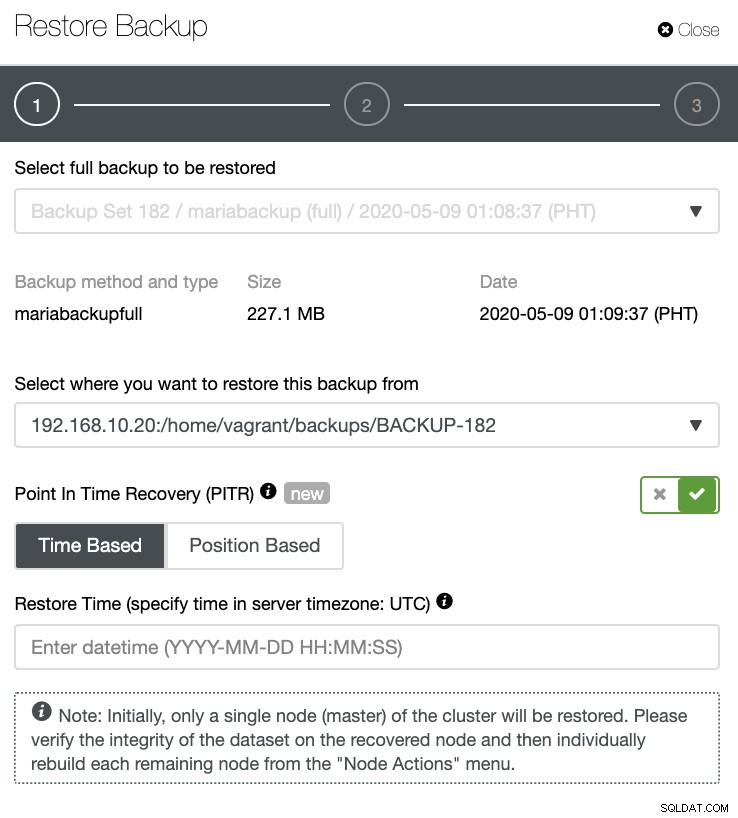
Limitazioni di ClusterControl PITR
Nel caso ti stia chiedendo cosa puoi e non puoi fare per PITR in ClusterControl, ecco l'elenco seguente:
- Non esiste attualmente uno strumento CLI s9s che supporti il processo PITR, quindi non è possibile automatizzare o integrare la pipeline CI/CD.
- Nessun supporto PITR per nodi esterni
- Nessun supporto PITR quando l'origine del backup è diversa dal nodo di destinazione
- Non esiste una notifica periodica di qual è l'ultimo periodo di tempo in cui puoi richiedere PITR
Conclusione
Entrambi gli strumenti hanno approcci e soluzioni diverse per l'ambiente di destinazione. Il punto chiave è che AWS RDS ha il proprio PITR che è più veloce, ma è applicabile solo se il tuo database è ospitato in RDS e sei legato a un vendor lock-in.
ClusterControl consente di applicare liberamente il processo PITR a qualsiasi data center o on-premise purché vengano presi in considerazione i prerequisiti. Il suo obiettivo è recuperare i dati. Indipendentemente dai suoi limiti, si basa su come utilizzerai la soluzione in base all'ambiente architettonico che stai utilizzando.