Questa è la quarta parte di una serie in cinque parti che analizza in modo approfondito il modo in cui viene avviata l'esecuzione dei piani paralleli in modalità riga di SQL ServerSQL Server. La parte 1 ha inizializzato il contesto di esecuzione zero per l'attività padre e la parte 2 ha creato l'albero di scansione della query. La parte 3 ha avviato la scansione delle query, eseguito alcune fase iniziali elaborazione e avviato le prime attività parallele aggiuntive nel ramo C.
Dettagli di esecuzione del ramo C
Questo è il secondo passaggio della sequenza di esecuzione:
- Ramo A (attività principale).
- Ramo C (attività parallele aggiuntive).
- Ramo D (attività parallele aggiuntive).
- Ramo B (attività parallele aggiuntive).
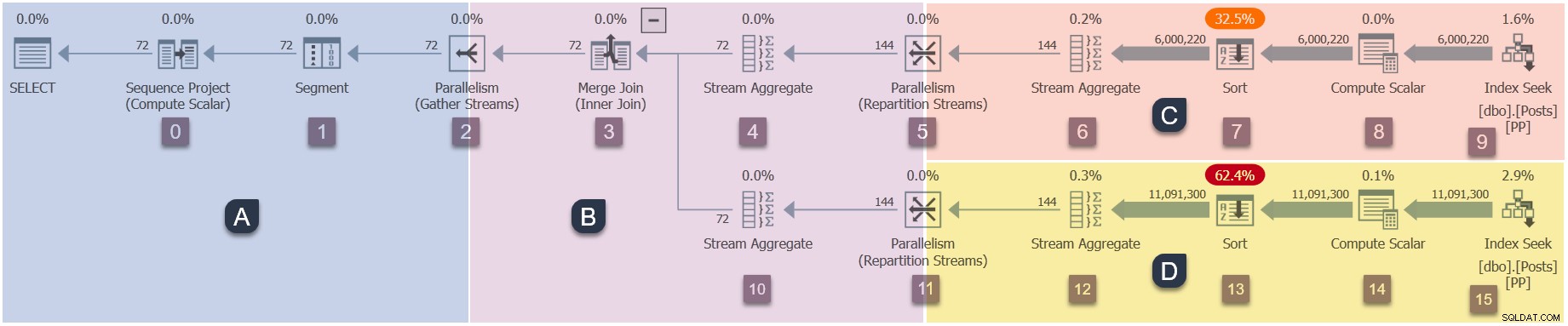
Un promemoria delle filiali nel nostro piano parallelo (clicca per ingrandire)
Poco tempo dopo i nuovi compiti per il ramo C sono in coda, SQL Server allega un lavoratore a ciascuna attività e colloca il lavoratore in un programmatore pronto per l'esecuzione. Ogni nuova attività viene eseguita all'interno di un nuovo contesto di esecuzione. In DOP 2, ci sono due nuove attività, due thread di lavoro e due contesti di esecuzione per il ramo C. Ogni attività esegue la propria copia degli iteratori nel ramo C sul proprio thread di lavoro:

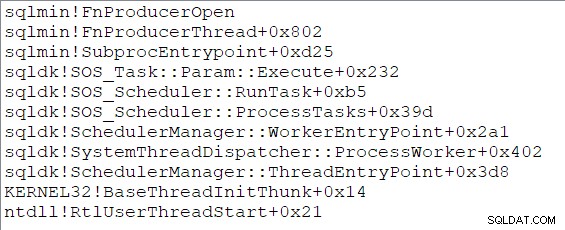
Le due nuove attività parallele iniziano a essere eseguite con una sottoprocedura punto di ingresso, che inizialmente porta a un Open chiama il produttore dello scambio (CQScanXProducerNew::Open ). Entrambe le attività hanno uno stack di chiamate identico all'inizio della loro vita:
Sincronizzazione di Exchange
Nel frattempo, l'attività principale (in esecuzione sul proprio thread di lavoro) registra i nuovi processi secondari con il manager dei processi secondari, quindi attende dal lato del consumatore dello scambio di flussi di ripartizione al nodo 5. L'attività padre attende su CXPACKET * fino a tutti delle attività parallele del ramo C completano il loro Open chiama e torna al lato produttore dello scambio. Le attività parallele apriranno ogni iteratore nel loro sottoalbero (cioè fino alla ricerca dell'indice al nodo 9 e ritorno) prima di tornare allo scambio di flussi di ripartizione al nodo 5. L'attività principale attenderà CXPACKET mentre questo accade. Ricorda che l'attività principale sta eseguendo chiamate nelle prime fasi.
Possiamo vedere questa attesa nelle attività in attesa DMV:

Il contesto di esecuzione zero (l'attività padre) è bloccato da entrambi i nuovi contesti di esecuzione. Questi contesti di esecuzione sono i primi ad essere creati dopo il contesto zero, quindi vengono assegnati i numeri uno e due. Per enfatizzare:entrambi i nuovi contesti di esecuzione devono aprire i loro sottoalberi e tornare allo scambio per il CXPACKET dell'attività padre aspetta che finisca.
Forse ti aspettavi di vedere CXCONSUMER attende qui, ma quell'attesa è riservata all'attesa su dati riga arrivare. L'attesa corrente non è per righe — spetta al produttore aprire , quindi otteniamo un generico CXPACKET * aspetta.
* Il database SQL di Azure e l'istanza gestita usano il nuovo CXSYNC_PORT wait invece di CXPACKET qui, ma quel miglioramento non si è ancora fatto strada in SQL Server (a partire dal 2019 CU9).
Ispezione delle nuove attività parallele
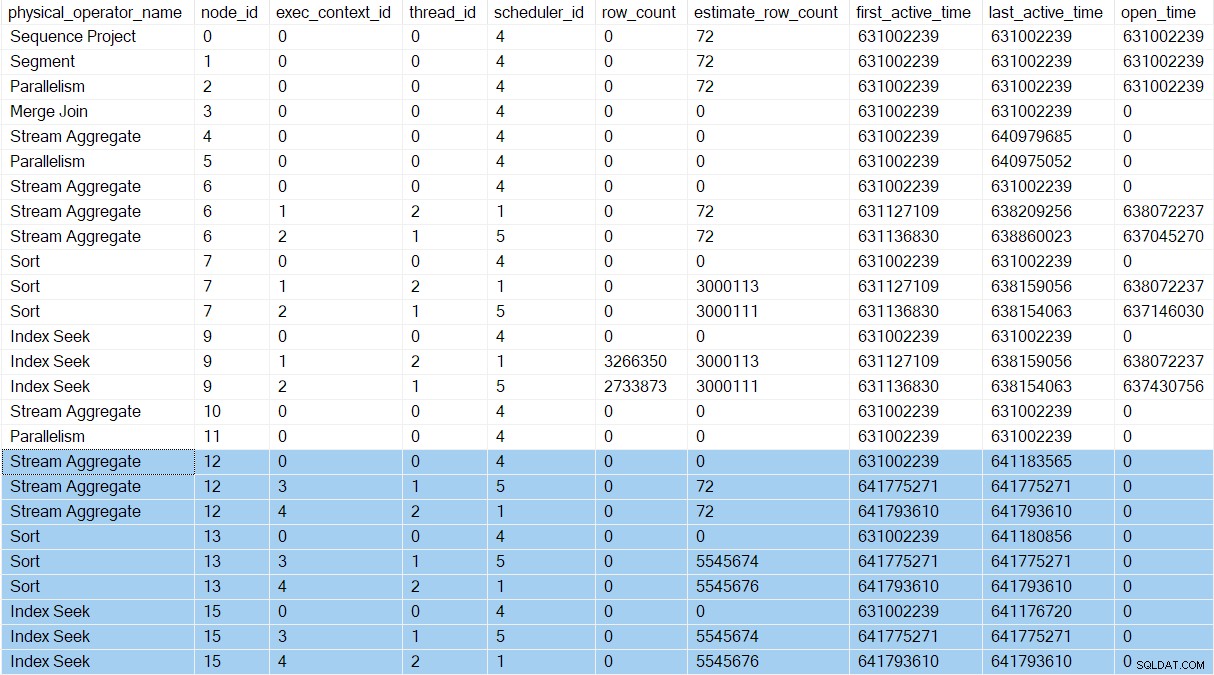
Possiamo vedere le nuove attività nei profili di query DMV. Le informazioni di profilatura per le nuove attività vengono visualizzate nella DMV perché i loro contesti di esecuzione sono stati derivati (clonati, quindi aggiornati) dal genitore (contesto di esecuzione zero):
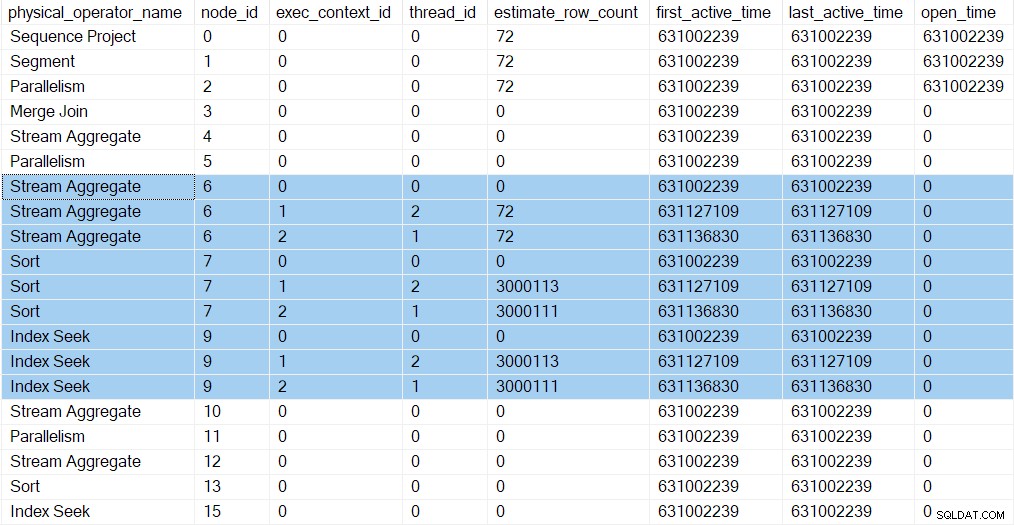
Ci sono ora tre voci per ogni iteratore nel ramo C (evidenziato). Uno per l'attività padre (contesto di esecuzione zero) e uno per ogni nuova attività parallela aggiuntiva (contesti 1 e 2). Nota che i conteggi di riga stimati per thread ( vedi parte 1) sono arrivati ora e sono mostrati solo per le attività parallele. Il primo e l'ultimo orario di attività per le attività parallele rappresentano il momento in cui sono stati creati i loro contesti di esecuzione. Nessuna delle nuove attività è stata aperta tutti gli iteratori ancora.
Gli stream di ripartizione lo scambio sul nodo 5 ha ancora una sola voce nell'uscita DMV. Questo perché il profiler invisibile associato monitora il consumatore lato dello scambio. Le attività parallele aggiuntive si trovano nel produttore lato dello scambio. Il lato consumer del nodo 5 alla fine abbiamo compiti paralleli, ma non siamo ancora arrivati a quel punto.
Punto di controllo
Questo sembra un buon punto per fermarsi a riprendere fiato e riassumere dove si trova tutto in questo momento. Ci saranno più di questi punti di sosta man mano che procediamo.
- L'attività principale è dal lato dei consumatori dello scambio di flussi di ripartizione al nodo 5 , in attesa di
CXPACKET. È nel mezzo dell'esecuzione delle prime fasi delle chiamate. Si è fermato per avviare il ramo C perché quel ramo contiene un ordinamento bloccante. L'attesa dell'attività principale continuerà fino a quando entrambe le attività parallele non completeranno l'apertura delle rispettive sottostrutture. - Due nuove attività parallele dal lato produttore dello scambio del nodo 5 sono pronti per aprire gli iteratori nel ramo C.
Niente al di fuori del ramo C di questo piano di esecuzione parallela può avanzare fino a quando l'attività padre non viene rilasciata dal suo CXPACKET aspettare. Ricorda che finora abbiamo creato solo un set di lavoratori paralleli aggiuntivi, per il ramo C. L'unico altro thread è l'attività principale, che è bloccata.
Esecuzione parallela del ramo C
Le due attività parallele iniziano dal lato produttore dello scambio di flussi di ripartizione al nodo 5. Ciascuno ha un piano (seriale) separato con il proprio flusso di aggregazione, ordinamento e ricerca dell'indice. Lo scalare di calcolo non viene visualizzato nel piano di runtime perché i suoi calcoli sono posticipati all'ordinamento.
Ogni istanza della ricerca dell'indice è consapevole del parallelo e opera su insiemi disgiunti di righe. Questi set vengono generati su richiesta dal set di righe padre creato in precedenza dall'attività padre (trattato nella parte 1). Quando una delle istanze della ricerca richiede un nuovo sottointervallo di righe, si sincronizza con gli altri thread di lavoro, in modo che solo uno stia allocando un nuovo sottointervallo contemporaneamente. Anche l'oggetto di sincronizzazione utilizzato è stato creato in precedenza dall'attività padre. Quando un'attività attende l'accesso esclusivo al set di righe padre per acquisire un nuovo sottointervallo, attende CXROWSET_SYNC .
Attività del ramo C aperte
La sequenza di Open chiamate per ogni attività nella filiale C è:
CQScanXProducerNew::Open. Si noti che non esiste un profiler precedente sul lato produttore di uno scambio. Questo è un peccato per i sintonizzatori di query.CXTransLocal::OpenCXPort::RegisterCXTransLocal::ActivateWorkersCQScanProfileNew::Open. Il profiler sopra il nodo 6.CQScanStreamAggregateNew::Open(nodo 6)CQScanProfileNew::Open. Il profiler sopra il nodo 7.CQScanSortNew::Open(nodo 7)
L'ordinamento è un operatore di blocco completo . Consuma l'intero input durante il suo Open chiamata. Ci sono un gran numero di dettagli interni interessanti da esplorare qui, ma lo spazio è poco, quindi tratterò solo i punti salienti:
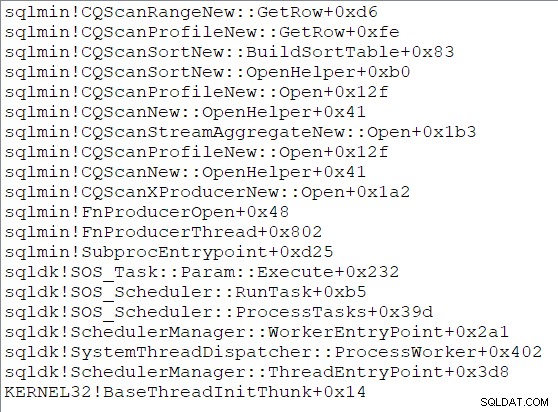
Il ordinamento costruisce la sua tabella di ordinamento aprendo il suo sottoalbero e consumando tutte le righe che i suoi figli possono fornire. Una volta completato l'ordinamento, l'ordinamento è pronto per la transizione alla modalità di output e restituisce il controllo al padre. L'ordinamento risponderà in seguito a GetRow() chiamate, restituendo ogni volta la riga successiva ordinata. Uno stack di chiamate illustrativo durante l'input di ordinamento è:
L'esecuzione continua fino a quando ogni ordinamento ha consumato tutte le righe (intervalli disgiunti di) disponibili dal suo figlio ricerca indice . Gli ordinamenti quindi chiamano Close sull'indice cerca e restituisce il controllo al suo aggregato di flusso padre . Gli aggregati di flusso inizializzano i loro contatori e restituiscono il controllo al produttore lato dello scambio di ripartizioni al nodo 5. La sequenza di Open le chiamate sono ora complete in questo ramo.
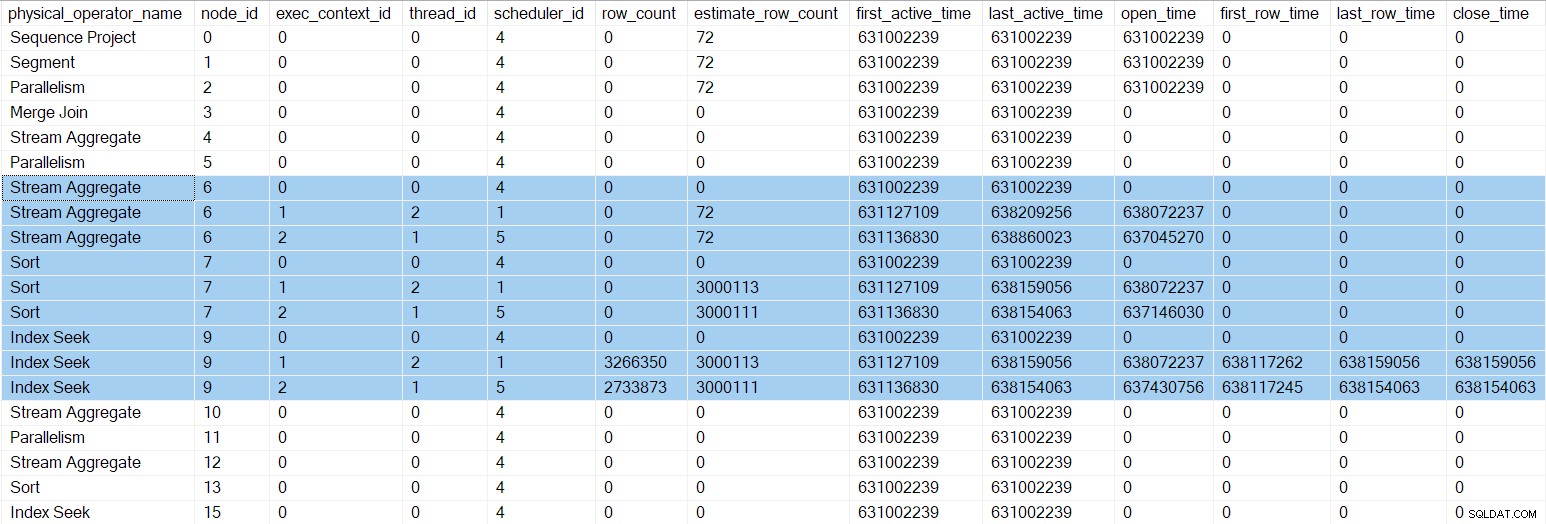
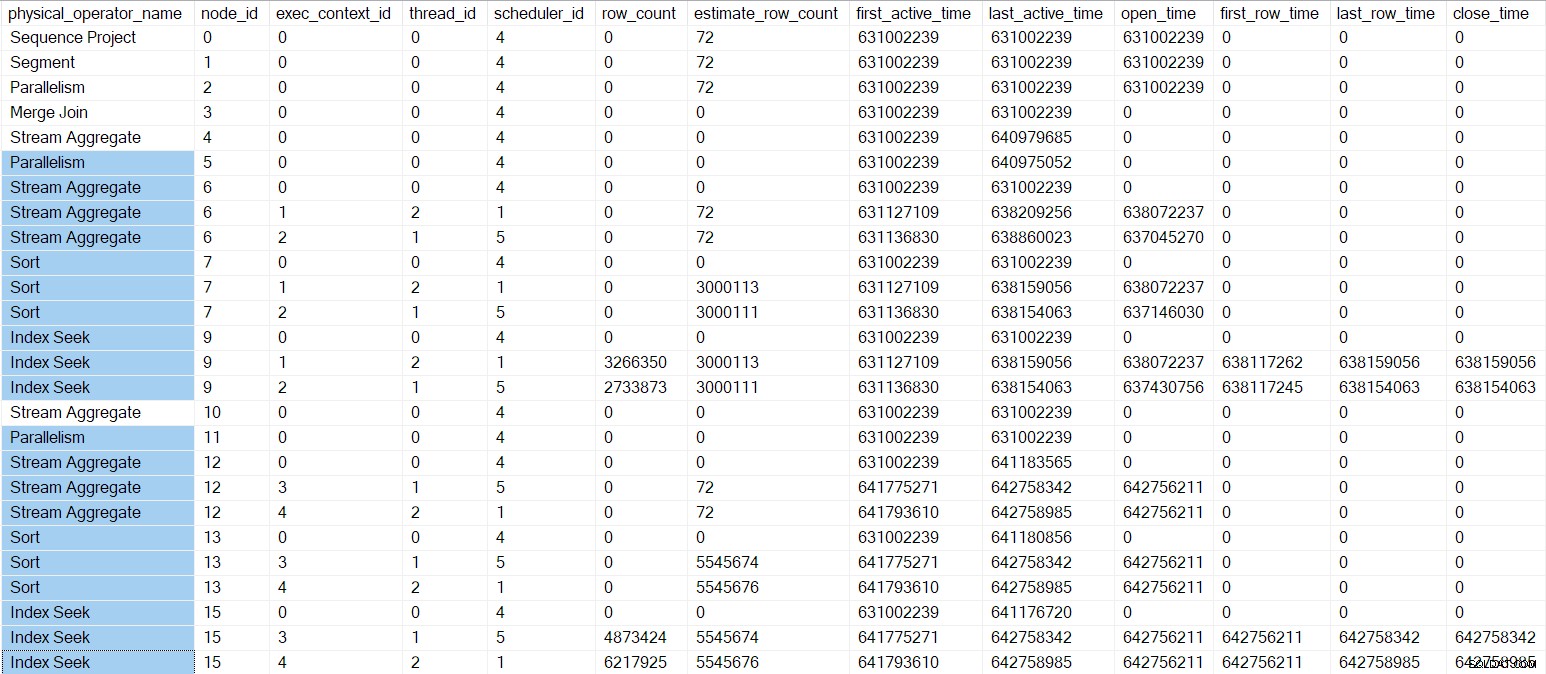
Il DMV di profilazione a questo punto mostra i numeri temporali aggiornati e i orari di chiusura per l'indice parallelo cerca:
Più sincronizzazione degli scambi
Richiama l'attività principale in attesa sul consumatore lato del nodo 5 per l'apertura di tutti i produttori. Un processo di sincronizzazione simile ora avviene tra le attività parallele sul produttore lato dello stesso scambio:
Ogni attività del produttore si sincronizza con le altre tramite CXTransLocal::Synchronize . I produttori chiamano CXPort::Open , quindi attendi CXPACKET per tutti lato consumatore attività parallele da aprire. Quando la prima attività parallela del ramo C torna sul lato produttore dello scambio e attende, la DMV delle attività in attesa ha il seguente aspetto:

Abbiamo ancora le attese lato consumatore dell'attività principale. Il nuovo CXPACKET evidenziato è la nostra prima attività parallela lato produttore in attesa di tutte le attività parallele lato consumatore per aprire la porta di scambio.
Le attività parallele lato consumatore (nel ramo B) non esistono ancora, quindi l'attività produttore visualizza NULL per il contesto di esecuzione da cui è bloccata. L'attività attualmente in attesa sul lato consumer dello scambio di flussi di ripartizione è l'attività padre (non un'attività parallela!) che esegue EarlyPhases codice, quindi non conta.
L'attesa dell'attività principale CXPACKET termina
Quando il secondo l'attività parallela nel ramo C torna sul lato produttore dello scambio dal suo Open chiamate, tutti i produttori hanno aperto la porta di scambio, quindi il attività principale dal lato dei consumatori dello scambio viene rilasciato dal suo CXPACKET aspetta.
I lavoratori sul lato produttore continuano ad attendere la creazione di attività parallele lato consumatore e l'apertura della porta di scambio:

Punto di controllo
A questo punto:
- Ci sono un totale di tre attività:due nel ramo C, più l'attività principale.
- Entrambi produttori allo scambio del nodo 5 si sono aperti e sono in attesa su
CXPACKETper l'apertura di attività parallele lato consumatore. Gran parte del meccanismo di scambio (compresi i buffer di riga) è creato dal lato del consumatore, quindi i produttori non hanno ancora un posto dove mettere le righe. - Gli tipi nel ramo C hanno consumato tutto il loro input e sono pronti a fornire un output ordinato.
- L'indice cerca nella Filiale C hanno ultimato i lavori e chiuso.
- L'attività principale è appena stato rilasciato dall'attesa su
CXPACKETsul lato consumer dello scambio di flussi di ripartizione del nodo 5. È ancora eseguendoEarlyPhasesnidificato chiamate.
Inizio attività parallele ramo D
Questo è il terzo passaggio nella sequenza di esecuzione:
- Ramo A (attività principale).
- Ramo C (attività parallele aggiuntive).
- Ramo D (attività parallele aggiuntive).
- Ramo B (attività parallele aggiuntive).
Rilasciato dal suo CXPACKET attendi sul lato consumer dello scambio di flussi di ripartizione al nodo 5, l'attività principale sale l'albero di scansione della query del ramo B. Ritorna da EarlyPhases annidato chiamate ai vari iteratori e profiler sull'input esterno (superiore) del join di unione.
Come accennato, crescente l'albero aggiorna i tempi trascorsi e CPU registrati dagli iteratori di profilazione invisibili. Stiamo eseguendo il codice utilizzando l'attività padre, quindi quei numeri vengono registrati rispetto al contesto di esecuzione zero. Questa è la fonte definitiva dei numeri di temporizzazione del "thread 0" a cui si fa riferimento nel mio precedente articolo, Capire i tempi dell'operatore del piano di esecuzione.
Una volta tornato al join di unione, l'attività padre chiama EarlyPhases per gli iteratori e i profiler nell'input interno (inferiore) al join di unione. Questi sono nodi da 10 a 15 (escluso 14, che è differito):
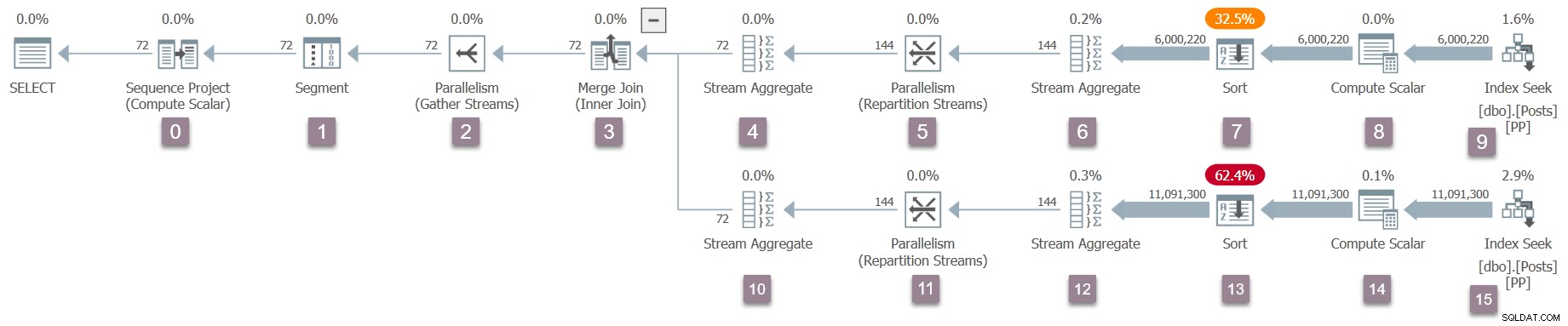
Una volta che le chiamate delle prime fasi dell'attività padre raggiungono l'indice di ricerca al nodo 15, inizia di nuovo a salire sull'albero (impostando i tempi di profilatura) fino a raggiungere lo scambio di flussi di ripartizione al nodo 11.
Quindi, proprio come ha fatto con l'input esterno (superiore) all'unione di unione, avvia il lato produttore dello scambio al nodo 11 , creando due nuove attività parallele .
Ciò mette in moto il ramo D (mostrato sotto). Il ramo D esegue esattamente come già descritto in dettaglio per il ramo C.
Immediatamente dopo l'avvio delle attività per il ramo D, l'attività principale attende su CXPACKET al nodo 11 affinché i nuovi produttori aprano la porta di scambio:

Il nuovo CXPACKET le attese sono evidenziate. Si noti che l'ID del nodo segnalato potrebbe essere un po' fuorviante. L'attività padre è davvero in attesa sul lato consumer del nodo 11 (stream di ripartizione), non sul nodo 2 (stream di raccolta). Questa è una stranezza dell'elaborazione in fase iniziale.
Nel frattempo, i thread dei produttori nel ramo C continuano ad attendere su CXPACKET per l'apertura dello scambio di flussi di ripartizione del nodo 5 lato consumer.
Apertura filiale D
Subito dopo che l'attività principale ha avviato i produttori per il ramo D, il profilo della query DMV mostra i nuovi contesti di esecuzione (3 e 4):
Le due nuove attività parallele nel Ramo D procedono esattamente come facevano quelli del Ramo C. Gli ordinamenti consumano tutto il loro input e le attività del ramo D tornano allo scambio. Questo rilascia l'attività padre dal suo CXPACKET aspettare. I lavoratori della filiale D attendono quindi CXPACKET sul lato produttore del nodo 11 per l'apertura delle attività parallele lato consumatore. Quei lavoratori paralleli (nella Filiale B) non esistono ancora.
Punto di controllo
Le attività in attesa a questo punto sono mostrate di seguito:

Entrambi i gruppi di attività parallele nei rami C e D sono in attesa su CXPACKET per l'apertura dei consumatori di attività parallele, nei flussi di ripartizione si scambiano rispettivamente i nodi 5 e 11. L'unica attività eseguibile nell'intera query in questo momento c'è l'attività principale .
Il DMV del profilatore di query a questo punto è mostrato di seguito, con gli operatori nei rami C e D evidenziati:
Le uniche attività parallele che non abbiamo ancora iniziato sono nella filiale B. Tutto il lavoro nella filiale B finora è stato fasi iniziali chiamate eseguite dall'attività principale .
Fine della parte 4
Nella parte finale di questa serie, descriverò come si avvia il resto di questo particolare piano di esecuzione parallela e tratterò brevemente come il piano restituisce i risultati. Concluderò con una descrizione più generale che si applica a piani paralleli di complessità arbitraria.