Prima di esaminare il problema delle prestazioni dei record inoltrati e risolverlo, è necessario esaminare la struttura delle tabelle di SQL Server.
Panoramica della struttura della tabella
In SQL Server, l'unità fondamentale dell'archiviazione dei dati sono le Pagine da 8 KB . Ogni pagina inizia con un'intestazione di 96 byte che memorizza le informazioni di sistema su quella pagina. Quindi, le righe della tabella verranno archiviate nelle pagine di dati in serie dopo l'intestazione. Alla fine della pagina, la tabella di offset delle righe, che contiene una voce per ogni riga, verrà archiviata di fronte alla sequenza delle righe nella pagina. Questa voce di offset di riga mostra quanto lontano si trova il primo byte di quella riga dall'inizio della pagina.
SQL Server ci fornisce due tipi di tabelle, in base alla struttura di quella tabella. Il raggruppato table archivia e ordina i dati nelle pagine di dati in base alla colonna o ai valori delle colonne della chiave dell'indice cluster predefinito. Inoltre, le pagine di dati all'interno della tabella Clustered vengono ordinate e collegate insieme in un elenco collegato basato sui valori della chiave dell'indice Clustered. L'albero B La struttura dell'indice cluster fornisce un metodo di accesso rapido ai dati basato sui valori della chiave dell'indice cluster. Se viene inserita una nuova riga o viene aggiornato un valore di chiave esistente nella tabella Cluster, SQL Server memorizzerà il nuovo valore nella posizione logica corretta che si adatta alle dimensioni della riga inserita senza interrompere i criteri di ordinamento. Se il valore inserito o aggiornato è maggiore dello spazio disponibile nella pagina dei dati, la pagina verrà divisa in due pagine per adattarsi al nuovo valore.
Il secondo tipo di tabelle è l'Heap tabella, in cui i dati non sono ordinati all'interno delle pagine di dati in alcun ordine e le pagine non sono collegate tra loro, poiché non esiste un indice cluster definito su quella tabella, per imporre criteri di ordinamento. Tenere traccia delle pagine che non sono ordinate in alcun criterio di ordinazione o collegate tra loro nella tabella heap non è una missione facile. Per semplificare il processo di rilevamento dell'allocazione delle pagine all'interno della tabella heap, SQL Server utilizza la Mappa di allocazione dell'indice (IAM), l'unica connessione logica tra le pagine di dati nella tabella heap, mantenendo una voce per ogni pagina di dati nella tabella o l'indice nella tabella IAM. Per recuperare i dati dalla tabella heap, SQL Server Engine esegue la scansione dell'IAM per individuare l'extent, che forma 8 pagine che archiviano i dati richiesti.
Problema di record inoltrati
Se viene inserita una nuova riga nella tabella heap, SQL Server Engine eseguirà la scansione dello Spazio disponibile nella pagina (PFS) per tenere traccia dello stato di allocazione e dell'utilizzo dello spazio su ciascuna pagina di dati al fine di trovare la prima posizione disponibile nelle pagine di dati che si adatta alla dimensione della riga inserita. Quindi, la riga verrà aggiunta alla pagina selezionata. Se il valore inserito è maggiore dello spazio disponibile nelle pagine dati, verrà aggiunta una nuova pagina a quella tabella per poter inserire il nuovo valore.
D'altra parte, se i dati esistenti nella tabella heap vengono modificati, ad esempio, abbiamo aggiornato una stringa di lunghezza variabile con una dimensione dei dati maggiore e lo spazio corrente non si adatta ai nuovi dati, i dati verranno spostati in una diversa posizione e il Registro inoltrato verrà inserito nella tabella heap nella posizione dei dati originale, per puntare alla nuova posizione di tali dati e per semplificare la posizione dei dati di tracciamento. La nuova posizione dei dati contiene anche un puntatore che punta al puntatore di inoltro per mantenerlo aggiornato in caso di spostamento dei dati dalla nuova posizione e per evitare la lunga catena di puntatori di inoltro o eliminarlo. Ciò potrebbe comportare anche la rimozione del record di inoltro.
Sebbene il metodo di reindirizzamento dei record inoltrati riduca la necessità di operazioni di ricostruzione delle tabelle e degli indici non in cluster a uso intensivo di risorse per aggiornare gli indirizzi dei dati ogni volta che viene modificata la posizione dei dati, raddoppia anche il numero di letture necessarie per recuperare i dati. SQL Server visiterà prima la vecchia posizione, dove troverà il record inoltrato che lo reindirizza alla nuova posizione dei dati. Quindi, leggerà i dati richiesti, eseguendo l'operazione di lettura due volte. Inoltre, il problema dei record inoltrati porta a modificare i dati sequenziali letti in dati letti casuali, influendo negativamente sulle prestazioni dell'operazione di recupero dei dati nel tempo.
Creiamo il seguente heap ForwardRecordDemo tabella utilizzando l'istruzione CREATE TABLE T-SQL di seguito:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Quindi, compila la tabella con record 3K a scopo di test, utilizzando l'istruzione INSERT INTO T-SQL di seguito:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identificazione del problema relativo ai record inoltrati
Le informazioni sul tipo di tabella e il numero di pagine utilizzate durante la memorizzazione dei dati della tabella, nonché la percentuale di frammentazione dell'indice e il numero di record inoltrati per una tabella specifica possono essere visualizzate interrogando il sys.dm_db_index_physical_stats> funzione di gestione dinamica del sistema e passando al DETTAGLIATO modalità per restituire il numero di record di inoltro. Per fare ciò, usa lo script T-SQL di seguito:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Come puoi vedere dal risultato della query, la tabella precedente è la tabella heap su cui non è stato creato alcun indice cluster per ordinare i dati nelle pagine e collegare le pagine tra loro. Le 3.000 righe inserite nella tabella vengono assegnate a 15 pagine di dati, senza record inoltrati e percentuale di frammentazione zero, come mostrato nel risultato seguente:

Quando si definisce il tipo di dati di una colonna come VARCHAR o NVARCHAR, il valore specificato nella definizione del tipo di dati è la dimensione massima consentita per quella stringa, senza riservare completamente tale importo durante il salvataggio dei valori nelle pagine di dati. Ad esempio, il Giovanni il nome del dipendente inserito in quella tabella riserverà solo 8 byte dei 100 byte massimi per quella colonna, tenendo conto che il salvataggio della stringa NVARCHAR raddoppierà i byte richiesti per la colonna VARCHAR, come mostrato nel DATALENGTH> risultato della funzione di seguito:
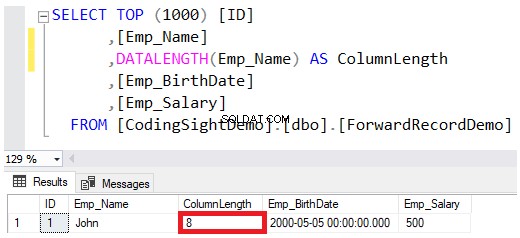
Se desideri aggiornare il valore della colonna Emp_Name in modo da includere il nome completo del dipendente John, utilizza l'istruzione UPDATE di seguito:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
Verifica la lunghezza della colonna aggiornata utilizzando DATALENGTH funzione. Vedrai che la lunghezza della colonna Emp_Name nelle righe aggiornate è stata espansa di 28 byte per ogni colonna, che è di circa 3,5 pagine di dati aggiuntive a quella tabella, come mostrato nel risultato di seguito:
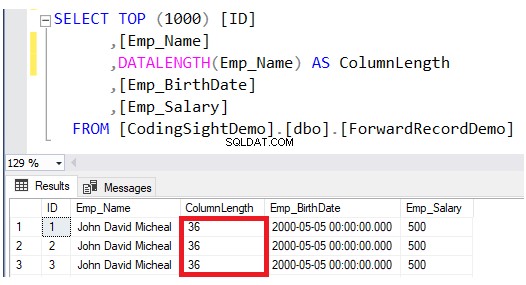
Quindi, controlla il numero di record inoltrati dopo l'operazione di aggiornamento eseguendo una query sulla funzione di gestione dinamica del sistema sys.dm_db_index_physical_stats. Per fare ciò, usa lo script T-SQL di seguito:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Come puoi vedere, l'aggiornamento della colonna Emp_Name su record da 1K con valori di stringa più grandi, senza aggiungere alcun nuovo record, assegnerà i 5 extra pagine a quella tabella, anziché 3,5 pagine come previsto in precedenza. Ciò avverrà a causa della generazione di 484 record inoltrati per puntare alle nuove posizioni dei dati spostati. Ciò potrebbe far sì che la tabella sia 33% frammentato, come mostrato chiaramente di seguito:

Anche in questo caso, se riesci ad aggiornare il valore della colonna Emp_Name per includere il nome completo del dipendente Zaid, utilizza l'istruzione UPDATE di seguito:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
Verifica la lunghezza della colonna aggiornata utilizzando DATALENGTH funzione. Vedrai che la lunghezza della colonna Emp_Name nelle righe aggiornate è stata ampliata di 22 byte per ogni colonna, che è di circa 2,7 pagine di dati aggiuntive aggiunte a quella tabella, come mostrato nel risultato seguente:
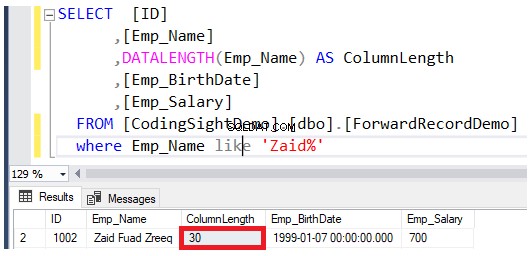
Verificare il numero di record inoltrati dopo aver eseguito l'operazione di aggiornamento. Puoi farlo interrogando la funzione di gestione dinamica del sistema sys.dm_db_index_physical_stats utilizzando lo stesso script T-SQL riportato di seguito:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Il risultato ti mostrerà che l'aggiornamento della colonna Emp_Name sugli altri record da 1K con valori di stringa più grandi senza inserire alcuna nuova riga ne assegnerà altri 4 pagine a quella tabella, anziché 2,7 pagine come previsto. Ciò avverrà a causa della generazione di ulteriori 417 record inoltrati per puntare alle nuove posizioni dei dati spostati e mantenendo lo stesso 33% percentuale di frammentazione, come mostrato di seguito:

Risoluzione del problema dei record inoltrati
Il modo più semplice per risolvere il problema dei record inoltrati è stimare la lunghezza massima della stringa che verrà archiviata nella colonna e assegnarla utilizzando la lunghezza fissa tipo di dati per quella colonna anziché utilizzare il tipo di dati a lunghezza variabile. Il modo ottimale per risolvere il problema dei record inoltrati consiste nell'aggiungere l'indice cluster a quel tavolo. In questo modo, la tabella verrà completamente convertita in una tabella Cluster, che viene ordinata in base ai valori della chiave dell'indice Clustered. Controllerà l'ordine dei dati esistenti, i dati appena inseriti e aggiornati che non si adattano allo spazio disponibile corrente nella pagina dei dati, come descritto in precedenza nell'introduzione di questo articolo.
Se l'aggiunta dell'indice cluster a quella tabella non è un'opzione per requisiti specifici, come le tabelle di staging o le tabelle ETL, è possibile superare temporaneamente il problema dei record inoltrati monitorando i record inoltrati e ricostruendo la tabella heap per rimuoverla, ciò lo farà aggiorna anche tutti gli indici non cluster su quella tabella heap. La funzionalità di ricostruzione della tabella heap è stata introdotta in SQL Server 2008, utilizzando ALTER TABLE…REBUILD Comando T-SQL.
Per vedere l'impatto sulle prestazioni dei record inoltrati sulle query di recupero dati, eseguiamo la query SELECT che esegue la ricerca in base ai valori della colonna Emp_Nameю Tuttavia, prima di eseguire la query, abilita le statistiche TIME e IO:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Di conseguenza, vedrai quel 925 vengono eseguite operazioni di lettura logica per recuperare i dati richiesti entro 84 ms come mostrato di seguito:

Per ricostruire la tabella heap in modo da rimuovere tutti i record inoltrati, utilizzare il comando ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Esegui di nuovo la stessa istruzione SELECT:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Le statistiche TIME e IO ti mostreranno che solo 21 operazioni di lettura logica rispetto a 925 le operazioni di lettura logica con i record inoltrati inclusi vengono eseguite per recuperare i dati richiesti entro 79 ms :

Per controllare il numero di record inoltrati dopo aver ricostruito la tabella heap, eseguire la funzione di gestione dinamica del sistema sys.dm_db_index_physical_stats, utilizzare lo stesso script T-SQL riportato di seguito:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Vedrai che solo 21 pagine, con le precedenti 3 le pagine consumate per i record inoltrati, vengono assegnate a quella tabella per memorizzare i dati, che è simile al risultato stimato che abbiamo ottenuto durante le operazioni di inserimento e aggiornamento dei dati (15+3,5+2,7). Dopo aver ricostruito la tabella heap, tutti i record inoltrati vengono ora rimossi. Di conseguenza, abbiamo una tabella senza frammentazione:

Il problema dei record inoltrati è un importante problema di prestazioni che gli amministratori del database dovrebbero considerare quando pianificano il manutenzione della tabella heap. I risultati precedenti vengono recuperati dalla nostra tabella di test che contiene solo 3.000 record. Puoi immaginare il numero di pagine che verranno sprecate dai record inoltrati e dal degrado delle prestazioni di I/O, a causa della lettura di un gran numero di record inoltrati durante la lettura da enormi tabelle!
Riferimenti:
- Guida all'architettura di pagine ed estensioni
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- Conoscere i "record inoltrati" può aiutare a diagnosticare problemi di prestazioni difficili da trovare