Potresti aver sentito parlare del termine "cervello diviso". Cos'è? In che modo influisce sui tuoi cluster? In questo post del blog discuteremo di cosa si tratta esattamente, quale pericolo può rappresentare per il tuo database, come possiamo prevenirlo e, se tutto va storto, come recuperarlo.
Sono lontani i tempi delle singole istanze, al giorno d'oggi quasi tutti i database vengono eseguiti in gruppi o cluster di replica. Questo è ottimo per l'elevata disponibilità e scalabilità, ma un database distribuito introduce nuovi pericoli e limitazioni. Un caso che può essere mortale è una divisione della rete. Immagina un cluster di più nodi che, a causa di problemi di rete, è stato diviso in due parti. Per ovvi motivi (coerenza dei dati), entrambe le parti non dovrebbero gestire il traffico contemporaneamente poiché sono isolate l'una dall'altra e i dati non possono essere trasferiti tra di loro. È sbagliato anche dal punto di vista dell'applicazione, anche se, alla fine, ci sarebbe un modo per sincronizzare i dati (sebbene la riconciliazione di 2 set di dati non sia banale). Per un po', una parte dell'applicazione non sarebbe a conoscenza delle modifiche apportate da altri host dell'applicazione, che accedono all'altra parte del cluster di database. Questo può portare a seri problemi.
La condizione in cui il cluster è stato diviso in due o più parti disposte ad accettare le scritture è chiamata “cervello diviso”.
Il problema più grande con il cervello diviso è la deriva dei dati, poiché le scritture accadono su entrambe le parti del cluster. Nessuna delle versioni di MySQL fornisce mezzi automatizzati per unire set di dati divergenti. Non troverai tale funzionalità nella replica MySQL, nella replica di gruppo o in Galera. Una volta che i dati sono divergenti, l'unica opzione è utilizzare una delle parti del cluster come fonte di verità e scartare le modifiche eseguite sull'altra parte, a meno che non possiamo seguire un processo manuale per unire i dati.
Questo è il motivo per cui inizieremo con come impedire che si verifichi la divisione del cervello. È molto più semplice che dover correggere eventuali discrepanze nei dati.
Come prevenire la divisione del cervello
La soluzione esatta dipende dal tipo di database e dalla configurazione dell'ambiente. Daremo un'occhiata ad alcuni dei casi più comuni per Galera Cluster e MySQL Replication.
Galera Cluster
Galera ha un "interruttore automatico" integrato per gestire il cervello diviso:si basa su un meccanismo di quorum. Se nel cluster è disponibile la maggioranza (50% + 1) dei nodi, Galera funzionerà normalmente. Se non c'è la maggioranza, Galera smetterà di servire il traffico e passerà al cosiddetto stato "non primario". Questo è praticamente tutto ciò di cui hai bisogno per affrontare una situazione di cervello diviso durante l'utilizzo di Galera. Certo, ci sono metodi manuali per forzare Galera nello stato "primario" anche se non c'è la maggioranza. Il fatto è che, a meno che tu non lo faccia, dovresti essere al sicuro.
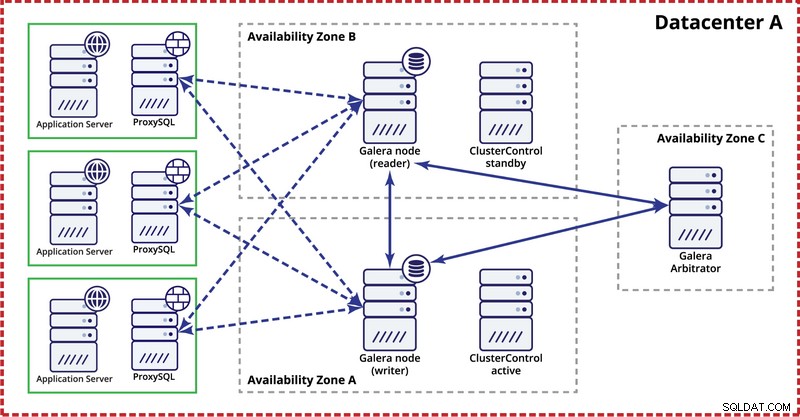
Il modo in cui viene calcolato il quorum ha importanti ripercussioni:a livello di singolo data center, si desidera avere un numero dispari di nodi. Tre nodi offrono una tolleranza per il guasto di un nodo (2 nodi soddisfano il requisito di disponibilità di oltre il 50% dei nodi nel cluster). Cinque nodi ti daranno una tolleranza per il fallimento di due nodi (5 - 2 =3 che è più del 50% da 5 nodi). D'altra parte, l'utilizzo di quattro nodi non migliorerà la tua tolleranza su un cluster di tre nodi. Gestirebbe comunque solo un errore di un nodo (4 - 1 =3, più del 50% da 4) mentre un errore di due nodi renderà il cluster inutilizzabile (4 - 2 =2, solo il 50%, non di più).
Durante la distribuzione del cluster Galera in un singolo data center, tieni presente che, idealmente, vorresti distribuire i nodi su più zone di disponibilità (fonte di alimentazione separata, rete, ecc.) - purché esistano nel tuo data center, ovvero . Una semplice configurazione potrebbe essere simile alla seguente:
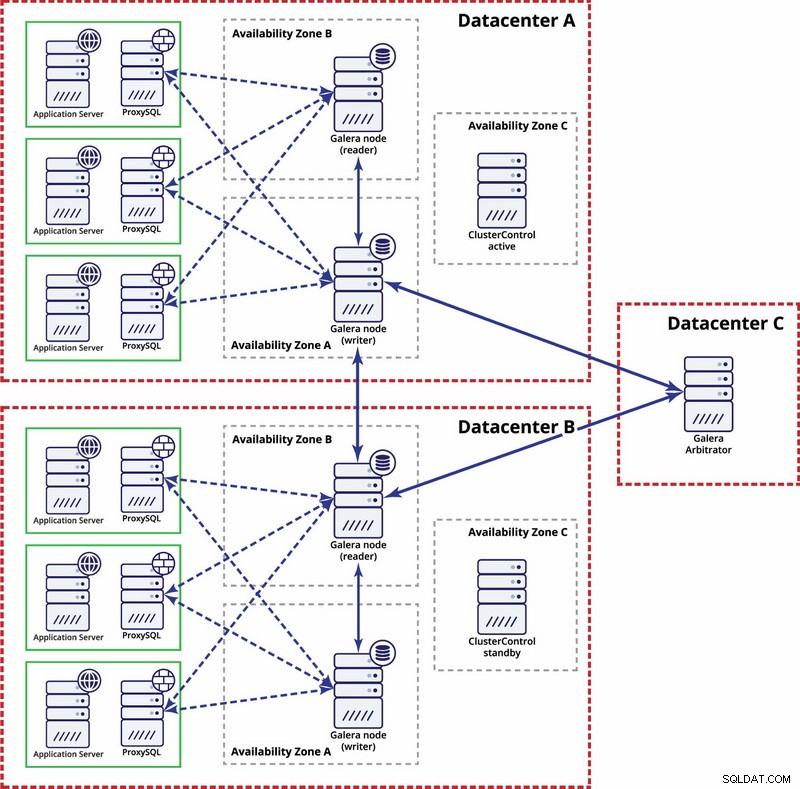
A livello di multi-datacenter, queste considerazioni sono applicabili anche. Se si desidera che il cluster Galera gestisca automaticamente gli errori del data center, è necessario utilizzare un numero dispari di data center. Per ridurre i costi, puoi utilizzare un arbitro Galera in uno di essi anziché in un nodo di database. L'arbitro Galera (garbd) è un processo che partecipa al calcolo del quorum ma non contiene alcun dato. Ciò consente di utilizzarlo anche su istanze molto piccole poiché non richiede molte risorse, sebbene la connettività di rete debba essere buona poiché "vede" tutto il traffico di replica. La configurazione di esempio potrebbe essere simile a un diagramma seguente:
Replica MySQL
Con la replica di MySQL il problema più grande è che non esiste un meccanismo di quorum integrato, come nel cluster Galera. Pertanto sono necessari più passaggi per garantire che la tua configurazione non sia influenzata da un cervello diviso.
Un metodo consiste nell'evitare i failover automatizzati tra datacenter. È possibile configurare la soluzione di failover (può essere tramite ClusterControl, MHA o Orchestrator) per il failover solo all'interno di un singolo data center. Se si verificasse un'interruzione completa del data center, spetterebbe all'amministratore decidere come eseguire il failover e come assicurarsi che i server nel data center guasto non vengano utilizzati.
Ci sono opzioni per renderlo più automatizzato. È possibile utilizzare Consul per archiviare i dati sui nodi nell'impostazione della replica e quale di essi è il master. Quindi spetterà all'amministratore (o tramite alcuni script) aggiornare questa voce e spostare le scritture nel secondo datacenter. Puoi trarre vantaggio da una configurazione Orchestrator/Raft in cui i nodi dell'orchestrator possono essere distribuiti su più data center e rilevare il cervello diviso. Sulla base di ciò potresti intraprendere diverse azioni come, come accennato in precedenza, aggiornare le voci nel nostro Console o ecc. Il punto è che questo è un ambiente molto più complesso da configurare e automatizzare rispetto al cluster Galera. Di seguito puoi trovare un esempio di configurazione multi-datacenter per la replica di MySQL.
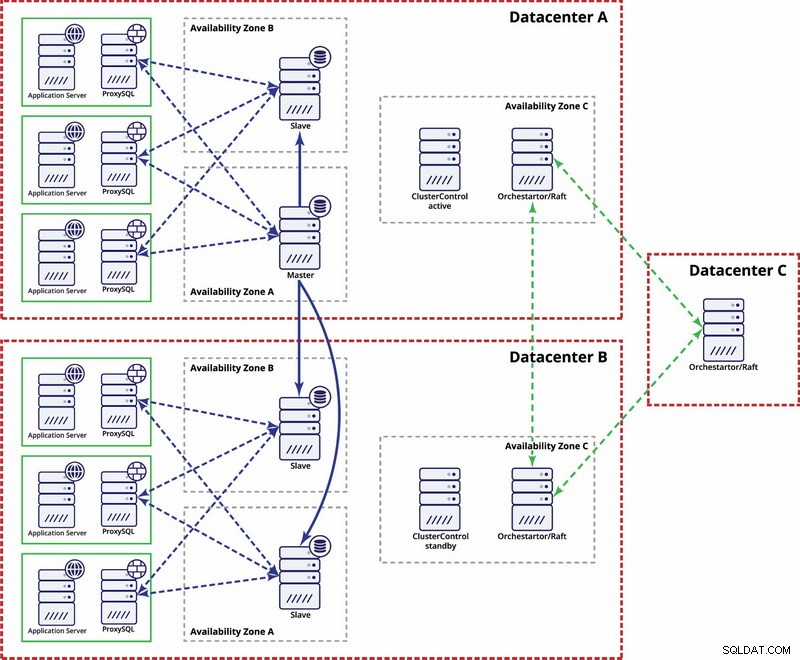
Tieni presente che devi ancora creare script per farlo funzionare, ad es. monitorare i nodi dell'orchestrator per un cervello diviso e intraprendere le azioni necessarie per implementare STONITH e garantire che il master nel datacenter A non venga utilizzato una volta che la rete converge e la connettività sarà essere ripristinato.
È successo il cervello diviso - Cosa fare dopo?
Si è verificato lo scenario peggiore e abbiamo una deriva dei dati. Cercheremo di darti alcuni suggerimenti su cosa si può fare qui. Sfortunatamente, i passaggi esatti dipenderanno principalmente dalla progettazione dello schema, quindi non sarà possibile scrivere una guida pratica precisa.
Quello che devi tenere a mente è che l'obiettivo finale sarà copiare i dati da un master all'altro e ricreare tutte le relazioni tra le tabelle.
Prima di tutto, devi identificare quale nodo continuerà a servire i dati come master. Questo è un set di dati a cui unirete i dati archiviati nell'altra istanza "master". Una volta fatto, devi identificare i dati del vecchio master che mancano sul master corrente. Questo sarà un lavoro manuale. Se hai timestamp nelle tue tabelle, puoi sfruttarli per individuare i dati mancanti. In definitiva, i registri binari conterranno tutte le modifiche ai dati in modo che tu possa fare affidamento su di essi. Potrebbe anche essere necessario fare affidamento sulla propria conoscenza della struttura dei dati e delle relazioni tra le tabelle. Se i tuoi dati sono normalizzati, un record in una tabella potrebbe essere correlato a record in altre tabelle. Ad esempio, l'applicazione può inserire dati nella tabella "utente" correlata alla tabella "indirizzo" utilizzando user_id. Dovrai trovare tutte le righe correlate ed estrarle.
Il prossimo passo sarà caricare questi dati nel nuovo master. Qui arriva la parte difficile:se hai preparato le tue configurazioni in anticipo, potrebbe trattarsi semplicemente di eseguire un paio di inserti. In caso contrario, questo potrebbe essere piuttosto complesso. Si tratta di chiave primaria e valori di indice univoci. Se i valori della tua chiave primaria vengono generati come univoci su ciascun server utilizzando una sorta di generatore UUID o utilizzando le impostazioni auto_increment_increment e auto_increment_offset in MySQL, puoi essere sicuro che i dati del vecchio master che devi inserire non causeranno la chiave primaria o univoca chiave in conflitto con i dati sul nuovo master. In caso contrario, potrebbe essere necessario modificare manualmente i dati del vecchio master per assicurarsi che possano essere inseriti correttamente. Sembra complesso, quindi diamo un'occhiata a un esempio.
Immaginiamo di inserire righe usando auto_increment sul nodo A, che è un master. Per semplicità, ci concentreremo solo su una singola riga. Ci sono colonne 'id' e 'value'.
Se lo inseriamo senza alcuna configurazione particolare, vedremo voci come di seguito:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Quelli si replicheranno allo schiavo (B). Se si verifica lo split brain e le scritture verranno eseguite sia sul vecchio che sul nuovo master, ci ritroveremo con la seguente situazione:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Come puoi vedere, non c'è modo di scaricare semplicemente i record con ID 1004, 1005 e 1006 dal nodo A e archiviarli sul nodo B perché ci ritroveremo con voci di chiave primaria duplicate. Ciò che è necessario fare è modificare i valori della colonna id nelle righe che verranno inserite in un valore maggiore del valore massimo della colonna id dalla tabella. Questo è tutto ciò che serve per le singole righe. Per relazioni più complesse, in cui sono coinvolte più tabelle, potrebbe essere necessario apportare le modifiche in più posizioni.
D'altra parte, se avessimo previsto questo potenziale problema e configurato i nostri nodi per memorizzare ID dispari sul nodo A e ID pari sul nodo B, il problema sarebbe stato molto più facile da risolvere.
Il nodo A è stato configurato con auto_increment_offset =1 e auto_increment_increment =2
Il nodo B è stato configurato con auto_increment_offset =2 e auto_increment_increment =2
Ecco come apparirebbero i dati sul nodo A prima del cervello diviso:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Quando si è verificato lo split brain, apparirà come di seguito.
Nodo A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Nodo B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Ora possiamo facilmente copiare i dati mancanti dal nodo A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’E caricalo sul nodo B finendo con il seguente set di dati:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Certo, le righe non sono nell'ordine originale, ma questo dovrebbe essere ok. Nella peggiore delle ipotesi dovrai ordinare per colonna "valore" nelle query e magari aggiungere un indice su di essa per rendere veloce l'ordinamento.
Ora, immagina centinaia o migliaia di righe e una struttura di tabella altamente normalizzata:ripristinare una riga potrebbe significare che dovrai ripristinarne molte in tabelle aggiuntive. Con la necessità di modificare gli ID (perché non avevi impostazioni di protezione in atto) su tutte le righe correlate e tutto questo è un lavoro manuale, puoi immaginare che questa non sia la situazione migliore in cui trovarsi. Ci vuole tempo per recuperare e è un processo soggetto a errori. Fortunatamente, come abbiamo discusso all'inizio, ci sono mezzi per ridurre al minimo le possibilità che il cervello diviso abbia un impatto sul tuo sistema o per ridurre il lavoro che deve essere fatto per sincronizzare i tuoi nodi. Assicurati di usarli e preparati.