Devono esserci molti potenti strumenti disponibili come opzione di backup e ripristino per PostgreSQL in generale; Barman, PgBackRest, BART sono solo per citarne alcuni in questo contesto. Ciò che ha attirato la nostra attenzione è stato il fatto che Barman è uno strumento che si sta rapidamente adeguando all'implementazione della produzione e alle tendenze del mercato.
Che si tratti di un'implementazione basata su docker, della necessità di archiviare il backup in un archivio cloud diverso o di un'architettura di ripristino di emergenza altamente personalizzabile, Barman è un concorrente molto forte in tutti questi casi.
Questo blog esplora Barman con poche ipotesi sull'implementazione, tuttavia in nessun caso questo dovrebbe essere considerato solo un possibile set di funzionalità. Barman è ben oltre ciò che possiamo catturare in questo blog e deve essere ulteriormente esplorato se si considera il "backup e ripristino dell'istanza PostgreSQL".
Presupposto per la distribuzione pronta di DR
RPO=0 generalmente ha un costo:l'implementazione sincrono del server di standby spesso raggiunge questo obiettivo, ma poi influisce abbastanza spesso sul TPS del server primario.
Come PostgreSQL, Barman offre numerose opzioni di implementazione per soddisfare le tue esigenze in termini di RPO e prestazioni. Pensa alla semplicità di implementazione, RPO=0 o impatto sulle prestazioni prossimo allo zero; Barman si adatta a tutto.
Abbiamo preso in considerazione la seguente implementazione per stabilire una soluzione di ripristino di emergenza per la nostra architettura di backup e ripristino.
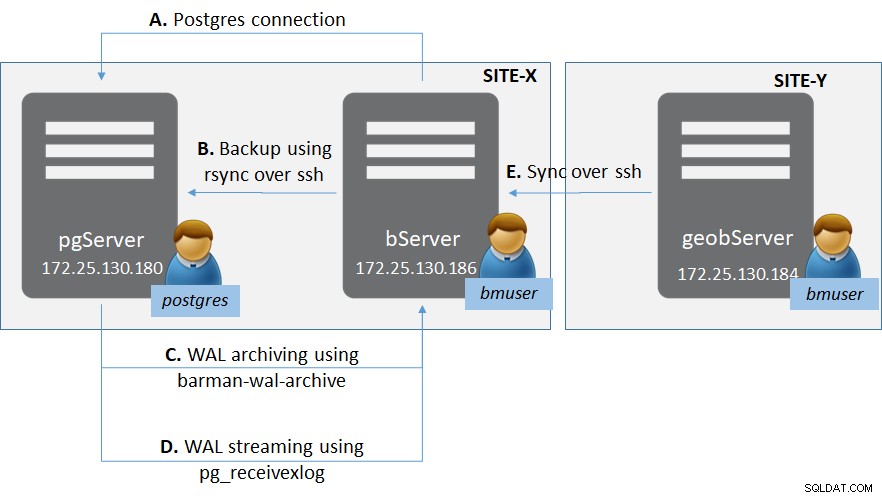 Figura 1:distribuzione di PostgreSQL con Barman
Figura 1:distribuzione di PostgreSQL con BarmanCi sono due siti (come in generale per i siti di ripristino di emergenza) - Sito-X e Sito-Y.
In Site-X c'è:
- Un server "pgServer" che ospita un'istanza del server PostgreSQL pgServer e un utente del sistema operativo "postgres"
- Istanza PostgreSQL anche per ospitare un ruolo di superutente 'bmuser'
- Un server 'bServer' che ospita i binari di Barman e un utente del sistema operativo 'bmuser'
In Site-Y c'è:
- Un server 'geobServer' che ospita i binari di Barman e un utente del sistema operativo 'bmuser'
Ci sono più tipi di connessione coinvolti in questa configurazione.
- Tra 'bServer' e 'pgServer':
- Connettività del piano di gestione da Barman all'istanza PostgreSQL
- connettività rsync per eseguire il backup di base effettivo da Barman all'istanza PostgreSQL
- Archiviazione WAL utilizzando barman-wal-archive dall'istanza PostgreSQL a Barman
- Streaming WAL utilizzando pg_receivexlog su Barman
- Tra 'bServer' e 'geobserver':
- Sincronizzazione tra i server Barman per fornire geo-replica
Connettività prima di tutto
Le esigenze di connettività primaria tra i server sono tramite ssh. Per farlo, vengono utilizzate chiavi ssh senza password. Stabiliamo le chiavi ssh e scambiamole.
Su pgServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Su bServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Su geobServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Configurazione dell'istanza PostgreSQL
Ci sono due cose principali di cui abbiamo bisogno per ricostituire un'istanza postgres:la directory di base ei log WAL / Transactions generati successivamente. Il server Barman ne tiene traccia in modo intelligente. Ciò di cui abbiamo bisogno è garantire che vengano generati feed adeguati affinché Barman raccolga questi artefatti.
Aggiungi le seguenti righe a postgresql.conf:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'Il comando Archivia garantisce che quando WAL deve essere archiviato dall'istanza postgres, l'utilità barman-wal-archive lo invii al Barman Server. Va notato che il pacchetto barman-cli dovrebbe quindi essere reso disponibile su 'pgServer'. C'è un'altra opzione per usare rsync se non vogliamo usare l'utilità barman-wal-archive.
Aggiungi quanto segue a pg_hba.conf:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5Sostanzialmente consente una replica e una normale connessione da 'bmserver' a questa istanza postgres.
Ora riavvia l'istanza e crea un ruolo super utente chiamato bmuser:
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser Se richiesto, possiamo evitare di usare bmuser anche come superutente; che richiederebbero i privilegi assegnati a questo utente. Per l'esempio sopra, abbiamo usato anche bmuser come password. Ma questo è praticamente tutto, per quanto riguarda la configurazione di un'istanza PostgreSQL.
Configurazione Barman
Barman ha tre componenti di base nella sua configurazione:
- Configurazione globale
- Configurazione a livello di server
- Utente che gestirà il barman
Nel nostro caso, poiché Barman viene installato utilizzando rpm, i nostri file di configurazione globale sono stati archiviati in:
/etc/barman.confVolevamo memorizzare la configurazione a livello di server nella home directory di bmuser, quindi il nostro file di configurazione globale aveva il seguente contenuto:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOConfigurazione del server Barman primario
Nella distribuzione sopra, abbiamo deciso di mantenere il server Barman primario nello stesso data-center/sito in cui è conservata l'istanza PostgreSQL. Il vantaggio dello stesso è che c'è meno ritardo e un recupero più rapido in caso di necessità. Inutile dire che anche sul server PostgreSQL sono necessarie meno esigenze di elaborazione e/o larghezza di banda di rete.
Per consentire a Barman di gestire l'istanza PostgreSQL sul pgServer, dobbiamo aggiungere un file di configurazione (abbiamo chiamato pgserver.conf) con il seguente contenuto:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoE un file .pgpass contenente le credenziali per bmuser nell'istanza PostgreSQL:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Per comprendere un po' di più gli elementi di configurazione importanti:
- ssh_command :utilizzato per stabilire la connessione su cui verrà eseguita la rsync
- conninfo :Stringa di connessione per consentire a Barman di stabilire una connessione con il server postgres
- riutilizzo_backup :per consentire il backup incrementale con meno spazio di archiviazione
- backup_method :metodo per eseguire il backup della directory di base
- prefisso_percorso :posizione in cui sono archiviati i binari di pg_receivexlog
- streaming_conninfo :stringa di connessione utilizzata per lo streaming WAL
- create_slot :per assicurarsi che gli slot siano stati creati dall'istanza di postgres
Configurazione server Barman passivo
La configurazione di un sito di replica geografica è piuttosto semplice. Tutto ciò di cui ha bisogno è un'informazione di connessione ssh su cui questo sito del nodo passivo eseguirà la replica.
Ciò che è interessante è che un tale nodo passivo può funzionare in modalità mix; in altre parole, possono fungere da server Barman attivi per eseguire backup per i siti PostgreSQL e, in parallelo, fungere da sito di replica/a cascata per altri server Barman.
Poiché, nel nostro caso, questa istanza di Barman (su Site-Y) deve essere solo un nodo passivo, tutto ciò di cui abbiamo bisogno è creare il file /home/bmuser/barman.d/pgserver.conf con la seguente configurazione:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comPresupponendo che le chiavi siano state scambiate e che la configurazione globale su questo nodo sia eseguita come accennato in precedenza, abbiamo praticamente finito con la configurazione.
Ed ecco il nostro primo backup e ripristino
Sul bserver assicurarsi che il processo in background per ricevere WAL sia stato attivato; e poi controlla la configurazione del server:
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverIl controllo dovrebbe essere OK per tutti i passaggi secondari. In caso contrario, fare riferimento a /home/bmuser/barman.log.
Emettere il comando di backup su Barman per assicurarsi che esista un DATO di base su cui applicare WAL:
example@sqldat.com$ barman backup pgserverSu 'geobmserver' assicurati che la replica avvenga eseguendo i seguenti comandi:
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverIl cron dovrebbe essere inserito nel file crontab (se non presente). Per semplicità non l'ho mostrato qui. L'ultimo comando mostrerà che anche la cartella di backup è stata creata sul geobmserver.
Ora sull'istanza Postgres, creiamo dei dati fittizi:
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"La replica del WAL dall'istanza PostgreSQL può essere vista usando il comando seguente:
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”Per ricreare un'istanza su Site-Y, assicurati innanzitutto che i record WAL siano invertiti. o questo esempio, per creare un ripristino pulito:
example@sqldat.com$ barman switch-xlog --force --archive pgserverSu Site-X, apriamo un'istanza PostgreSQL autonoma per verificare se il backup è corretto:
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataOra, modifica i file postgresql.conf e postgresql.auto.conf secondo le esigenze. Di seguito spiega le modifiche apportate per questo esempio:
- postgresql.conf :listen_addresses commentato in modo da essere predefinito su localhost
- postgresql.auto.conf :rimosso sudo bmuser da restore_command
Richiama questi DATI in /tmp/data e verifica l'esistenza dei tuoi record.
Conclusione
Questa era solo la punta di un iceberg. Barman è molto più profondo di questo grazie alle funzionalità che fornisce, ad es. fungendo da standby sincronizzato, hook script e così via. Inutile dire che la documentazione nella sua totalità dovrebbe essere esplorata per configurarla secondo le esigenze del proprio ambiente di produzione.