L'argomento della memorizzazione nella cache è apparso in PostgreSQL già 22 anni fa ea quel tempo l'attenzione era rivolta all'affidabilità del database.
Avanti rapidamente fino al 2020, i dischi dei dischi sono nascosti ancora più in profondità negli ambienti virtualizzati, negli hypervisor e nei dispositivi di archiviazione associati. Inoltre, le applicazioni distribuite e interconnesse che operano su scala globale chiedono connessioni a bassa latenza e all'improvviso ottimizzano le cache dei server e le query SQL competono per garantire che i risultati vengano restituiti ai client in pochi millisecondi. Nascono le cache a livello di applicazione e in memoria e le query di lettura vengono ora salvate vicino ai server delle applicazioni. Di conseguenza, le operazioni di I/O vengono ridotte alle sole scritture e la latenza di rete viene notevolmente migliorata. Con una presa. Le implementazioni sono responsabili della propria gestione della cache, che a volte porta a un degrado delle prestazioni.
La memorizzazione nella cache delle scritture è una questione molto più complicata, come spiegato nel wiki di PostgreSQL.
Questo blog è una panoramica delle cache di query in memoria e dei bilanciatori di carico utilizzati con PostgreSQL.
Bilanciamento del carico PostgreSQL
L'idea del bilanciamento del carico è nata contemporaneamente alla memorizzazione nella cache, nel 1999, quando Bruce Momjiam scrisse:
[...] è possibile che potremmo diventare _molto_ popolari nel prossimo futuro.
Le basi per l'implementazione del bilanciamento del carico in PostgreSQL sono fornite dalla funzione Hot Standby incorporata. L'unico requisito è che l'applicazione gestisca il failover ed è qui che entrano in gioco le soluzioni di terze parti. Esamineremo alcune di queste soluzioni nelle prossime sezioni.
Le query con bilanciamento del carico possono restituire risultati coerenti solo a condizione che il ritardo di replica sincrona sia mantenuto basso. In pratica, anche un'infrastruttura di rete all'avanguardia come AWS può presentare ritardi di decine di millisecondi:
In genere osserviamo tempi di ritardo nell'ordine di 10 secondi di millisecondi. [...] Tuttavia, in condizioni tipiche, è comune un ritardo di replica inferiore a un minuto. [...]
Le repliche tra regioni che utilizzano la replica logica saranno influenzate dalla velocità di modifica/applicazione e dai ritardi nella comunicazione di rete tra le regioni specifiche selezionate. Le repliche tra regioni che utilizzano Aurora Global Database avranno un ritardo tipico di meno di un secondo.
Come affermato in precedenza, le soluzioni di terze parti si basano sulle funzionalità di base di PostgreSQL. Ad esempio, il bilanciamento del carico delle query di lettura si ottiene utilizzando più standby sincroni.
Soluzioni
pgpool-II
pgpool-II è un prodotto ricco di funzionalità che fornisce sia il bilanciamento del carico che la memorizzazione nella cache delle query in memoria. È un sostituto drop-in, non sono necessarie modifiche sul lato dell'applicazione.
Come bilanciatore del carico, pgpool-II esamina ogni query SQL:per essere bilanciate, le query SELECT devono soddisfare diverse condizioni.
La configurazione può essere semplice come un nodo, mostrato di seguito è un cluster a doppio nodo:
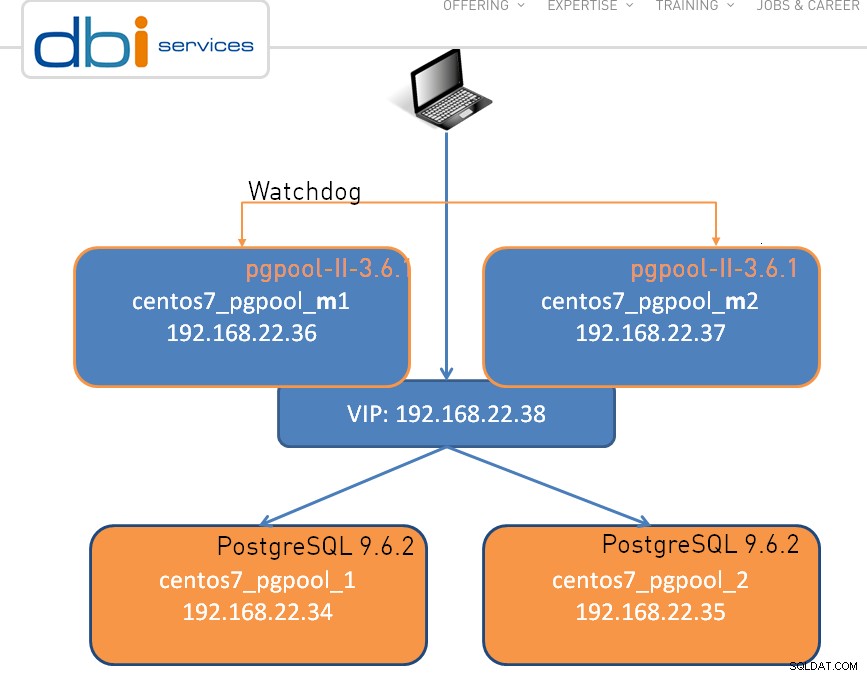
Come nel caso di qualsiasi grande software, ci sono alcune limitazioni e pgpool-II non fa eccezione:
- Non gestisce le query con più istruzioni.
- Le query SELECT su tabelle temporanee richiedono il commento /*NO LOAD BALANCE*/ SQL.
Le applicazioni eseguite in ambienti ad alte prestazioni trarranno vantaggio da una configurazione mista in cui pgBouncer è il pool di connessioni e pgpool-II gestisce il bilanciamento del carico e la memorizzazione nella cache. Il risultato è un impressionante aumento del throughput di 4 volte e una riduzione della latenza del 40%:
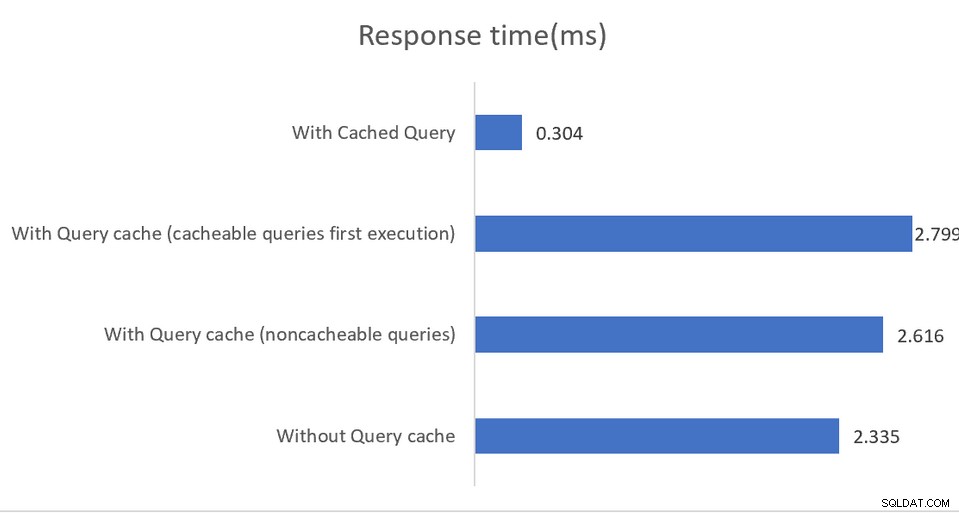
Il caching in memoria funziona, ancora una volta, solo su query di lettura, con cache i dati vengono salvati nella memoria condivisa o in un'installazione memorizzata esternamente. Sebbene la documentazione sia abbastanza efficace nello spiegare le varie opzioni di configurazione, suggerisce indirettamente che le implementazioni devono monitorare l'output di SHOW POOL CACHE per avvisare se i rapporti di successo scendono al di sotto del 70%, a quel punto il guadagno di prestazioni fornito dalla memorizzazione nella cache viene perso.
Bucardo
Bucardo è uno strumento di replica PostgreSQL scritto in Perl e PL/Perl.
Ho menzionato Bucardo, perché il bilanciamento del carico è una delle sue caratteristiche, secondo il wiki di PostgreSQL, tuttavia, una ricerca su Internet non fornisce risultati rilevanti. Per chiarire sono andato alla documentazione ufficiale che entra nei dettagli di come funziona effettivamente il software:

Questo rende abbastanza chiaro, Bucardo non è un sistema di bilanciamento del carico, proprio come è stato indicato dalle persone di Database Soup.
HAProxy
HAProxy è un sistema di bilanciamento del carico generico che opera a livello TCP (ai fini delle connessioni al database). I controlli di integrità assicurano che le query vengano inviate solo ai nodi attivi.
Rispetto a pgpool-II, le applicazioni che utilizzano HAProxy come sistema di bilanciamento del carico devono essere informate delle richieste di invio degli endpoint ai nodi di lettura.
Apache Ignite
Apache Ignite è una cache di secondo livello che comprende ANSI-99 SQL e fornisce supporto per le transazioni ACID. Apache Ignite non comprende il protocollo PostgreSQL Frontend/Backend e pertanto le applicazioni devono utilizzare un livello di persistenza come Hibernate ORM. In alternativa alla modifica delle applicazioni, Apache Ignite fornisce `memcached integration`_ che richiede l'estensione memcached PostgreSQL. Sfortunatamente, quest'ultima opzione non è compatibile con le versioni recenti di PostgreSQL, poiché l'estensione pgmemcache è stata aggiornata l'ultima volta nel 2017.
Dati Heimdall
Come prodotto commerciale, Heimdall Data seleziona entrambe le caselle:bilanciamento del carico e memorizzazione nella cache. È un prodotto maturo, essendo stato presentato alle conferenze PostgreSQL fin dal PGCon 2017:

Ulteriori dettagli e una demo del prodotto sono disponibili nel blog di Azure per PostgreSQL .
Conclusione
Nell'informatica distribuita di oggi, la memorizzazione nella cache delle query e il bilanciamento del carico sono importanti per l'ottimizzazione delle prestazioni di PostgreSQL quanto i noti GUC, il kernel del sistema operativo, l'archiviazione e l'ottimizzazione delle query. Sebbene pgpool-II e Heimdall Data siano le soluzioni open source e, rispettivamente, quelle commerciali preferite, ci sono casi in cui strumenti appositamente realizzati possono essere utilizzati come elementi costitutivi per ottenere risultati simili.