I database che servono applicazioni aziendali dovrebbero spesso supportare dati temporali. Ad esempio, supponiamo che un contratto con un fornitore sia valido solo per un periodo di tempo limitato. Può essere valido da un momento specifico in poi, oppure può essere valido per un intervallo di tempo specifico, da un punto temporale iniziale a un punto temporale finale. Inoltre, molte volte è necessario controllare tutte le modifiche in una o più tabelle. Potrebbe anche essere necessario mostrare lo stato in un momento specifico o tutte le modifiche apportate a una tabella in un periodo di tempo specifico. Dal punto di vista dell'integrità dei dati, potrebbe essere necessario implementare molti vincoli temporali aggiuntivi specifici.
Introduzione ai dati temporali
In una tabella con supporto temporale, l'intestazione rappresenta un predicato con un parametro almeno una tantum che rappresenta l'intervallo quando il resto del predicato è valido, il predicato completo è, quindi, un predicato con timestamp. Le righe rappresentano proposte con timestamp e il periodo di tempo valido della riga è in genere espresso con due attributi:da e a o inizio e fine .
Tipi di tabelle temporali
Potresti aver notato durante la parte introduttiva che ci sono due tipi di problemi temporali. Il primo è il tempo di validità della proposizione - in quel periodo la proposizione che rappresenta una riga con timestamp in una tabella era effettivamente vera. Ad esempio, un contratto con un fornitore era valido solo dal punto temporale 1 al punto temporale 2. Questo tipo di tempo di validità è significativo per le persone, significativo per l'azienda. Il tempo di validità è anche chiamato tempo di applicazione o tempo umano . Possiamo avere più periodi validi per la stessa entità. Ad esempio, il suddetto contratto valido dal punto temporale 1 al punto temporale 2 potrebbe essere valido anche dal punto temporale 7 al punto temporale 9.
Il secondo problema temporale è il tempo di transazione . Una riga per il contratto di cui sopra è stata inserita al punto temporale 1 ed era l'unica versione della verità nota al database fino a quando qualcuno non l'ha cambiata, o anche alla fine dei tempi. Quando la riga viene aggiornata al punto temporale 2, la riga originale era nota come vera per il database dal punto temporale 1 al punto temporale 2. Viene inserita una nuova riga per la stessa proposizione con tempo valido per il database dal punto temporale 2 al punto temporale 2. la fine del tempo. Il tempo di transazione è anche noto come ora di sistema o ora del database .
Naturalmente, puoi anche implementare tabelle con versione sia dell'applicazione che del sistema. Tali tabelle sono chiamate bitemporali tabelle.
In SQL Server 2016, ottieni il supporto per il timeout del sistema pronto all'uso con tabelle temporali con versione del sistema . Se devi implementare il tempo di applicazione, devi sviluppare una soluzione da solo.
Operatori di intervallo di Allen
La teoria dei dati temporali in un modello relazionale ha iniziato ad evolversi più di trent'anni fa. Introdurrò alcuni utili operatori booleani e un paio di operatori che lavorano sugli intervalli e restituiscono un intervallo. Questi operatori sono noti come operatori di Allen, dal nome di J. F. Allen, che ne definì alcuni in un documento di ricerca del 1983 sugli intervalli temporali. Tutti loro sono ancora accettati come validi e necessari. Un sistema di gestione del database potrebbe aiutarti a gestire i tempi di applicazione implementando questi operatori fuori dagli schemi.
Vorrei prima introdurre la notazione che userò. Lavorerò su due intervalli, indicati con i1 e i2 . Il punto di inizio del primo intervallo è b1 e la fine è e1 ; il punto di inizio del secondo intervallo è b2 e la fine è e2 . Gli operatori booleani di Allen sono definiti nella tabella seguente.
[table id=2 /]
Oltre agli operatori booleani, ci sono i tre operatori di Allen che accettano intervalli come parametri di input e restituiscono un intervallo. Questi operatori costituiscono una semplice algebra degli intervalli . Nota che quegli operatori hanno lo stesso nome degli operatori relazionali con cui probabilmente hai già familiarità:Unione, Intersezione e Meno. Tuttavia, non si comportano esattamente come le loro controparti relazionali. In generale, utilizzando uno dei tre operatori di intervallo, se l'operazione risulta in un insieme vuoto di punti temporali o in un insieme che non può essere descritto da un intervallo, l'operatore deve restituire NULL. Un'unione di due intervalli ha senso solo se gli intervalli si incontrano o si sovrappongono. Un'intersezione ha senso solo se gli intervalli si sovrappongono. L'operatore Intervallo meno ha senso solo in alcuni casi. Ad esempio, (3:10) Meno (5:7) restituisce NULL perché il risultato non può essere descritto da un intervallo. La tabella seguente riassume la definizione degli operatori dell'algebra degli intervalli.
[id tabella=3 /]
Problema di prestazioni delle query sovrapposteUno degli operatori più complessi da implementare è la sovrapposizione operatore. Le query che devono trovare intervalli sovrapposti non sono semplici da ottimizzare. Tuttavia, tali query sono abbastanza frequenti sulle tabelle temporali. In questo e nei prossimi due articoli, ti mostrerò un paio di modi per ottimizzare tali query. Ma prima di introdurre le soluzioni, vorrei introdurre il problema.
Per spiegare il problema, ho bisogno di alcuni dati. Il codice seguente mostra un esempio di come creare una tabella con intervalli di validità espressi con b e e colonne, dove l'inizio e la fine di un intervallo sono rappresentati come numeri interi. La tabella viene popolata con i dati demo della tabella WideWorldImporters.Sales.OrderLines. Tieni presente che esistono più versioni di WideWorldImporters database, quindi potresti ottenere risultati leggermente diversi. Ho utilizzato il file di backup WideWorldImporters-Standard.bak da https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 per ripristinare questo database demo sulla mia istanza di SQL Server .
Creazione dei dati demo
Ho creato una tabella demo dbo.Intervals nella tempd database con il seguente codice.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Si prega di notare anche gli indici creato. I due indici sono ottimali per le ricerche all'inizio di un intervallo o alla fine di un intervallo. Puoi controllare l'inizio minimo e la fine massima di tutti gli intervalli con il codice seguente.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Puoi vedere nei risultati che il punto temporale minimo di inizio è 1 e il punto temporale massimo di fine è 1155.
Dare il contesto ai dati
Potresti notare che rappresento l'inizio e la fine dei punti temporali come numeri interi. Ora ho bisogno di dare agli intervalli un po' di contesto temporale. In questo caso, un singolo punto temporale rappresenta un giorno . Il codice seguente crea una tabella di ricerca della data e lo popola. Tieni presente che la data di inizio è il 1 luglio 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Ora puoi unire la tabella dbo.Intervals alla tabella dbo.DateNums due volte, per dare il contesto agli interi che rappresentano l'inizio e la fine degli intervalli.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Introduzione al problema delle prestazioni
Il problema con le query temporali è che durante la lettura da una tabella, SQL Server può utilizzare un solo indice ed eliminare correttamente le righe che non sono candidate per il risultato da un solo lato, quindi esegue la scansione del resto dei dati. Ad esempio, è necessario trovare nella tabella tutti gli intervalli che si sovrappongono a un determinato intervallo. Ricorda, due intervalli si sovrappongono quando l'inizio del primo è minore o uguale alla fine del secondo e l'inizio del secondo è minore o uguale alla fine del primo, oppure matematicamente quando (b1 ≤ e2) E (b2 ≤ e1).
La query seguente ha cercato tutti gli intervalli che si sovrappongono all'intervallo (10, 30). Si noti che la seconda condizione (b2 ≤ e1) viene trasformata in (e1 ≥ b2) per una lettura più semplice (l'inizio e la fine degli intervalli dalla tabella sono sempre sul lato sinistro della condizione). L'intervallo dato, o cercato, si trova all'inizio della sequenza temporale per tutti gli intervalli nella tabella.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
La query utilizzava 36 letture logiche. Se controlli il piano di esecuzione, puoi vedere che la query utilizzava l'indice di ricerca nell'indice idx_b con il predicato di ricerca [tempdb].[dbo].[Intervalli].b <=Operatore scalare((30)) e quindi scansiona le righe e selezionare le righe risultanti utilizzando il predicato residuo [tempdb].[dbo].[Intervals].[e]>=(10). Poiché l'intervallo cercato si trova all'inizio della sequenza temporale, il predicato di ricerca ha eliminato con successo la maggior parte delle righe; solo alcuni intervalli nella tabella hanno il punto iniziale inferiore o uguale a 30.
Si otterrebbe una query altrettanto efficiente se l'intervallo di ricerca fosse alla fine della sequenza temporale, solo che SQL Server utilizzerà l'indice idx_e per la ricerca. Tuttavia, cosa succede se l'intervallo cercato si trova al centro della sequenza temporale, come mostra la query seguente?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Questa volta, la query ha utilizzato 111 letture logiche. Con una tabella più grande, la differenza con la prima query sarebbe ancora maggiore. Se controlli il piano di esecuzione, puoi scoprire che SQL Server ha utilizzato l'indice idx_e con [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) seek predicate e [tempdb].[ dbo].[Intervalli].[b]<=(590) predicato residuo. Il predicato di ricerca esclude circa la metà delle righe da un lato, mentre la metà delle righe dall'altro lato viene scansionata e le righe risultanti estratte con il predicato residuo.
Soluzione T-SQL avanzata
Esiste una soluzione che utilizzerebbe quell'indice per l'eliminazione delle righe da entrambi i lati dell'intervallo cercato utilizzando un singolo indice. La figura seguente mostra questa logica.
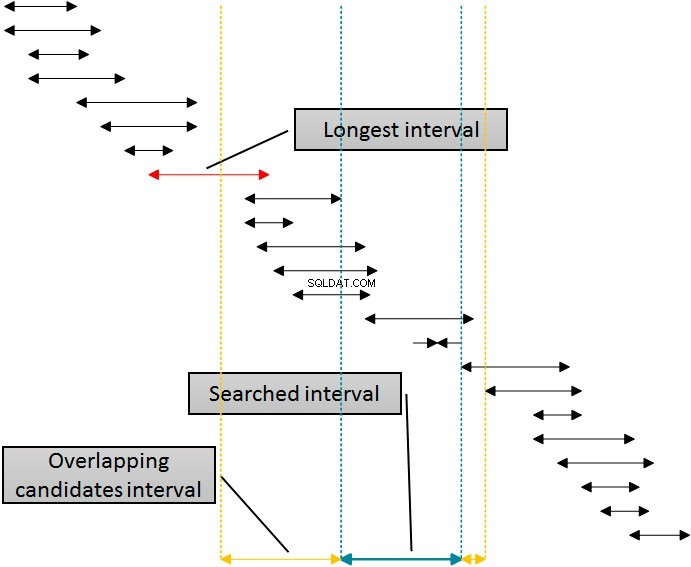
Gli intervalli nella figura sono ordinati in base al limite inferiore, che rappresenta l'utilizzo dell'indice idx_b da parte di SQL Server. Eliminare gli intervalli dal lato destro dell'intervallo dato (cercato) è semplice:basta eliminare tutti gli intervalli in cui l'inizio è almeno un'unità più grande (più a destra) della fine dell'intervallo dato. Puoi vedere questo confine nella figura indicata con la linea tratteggiata più a destra. Tuttavia, eliminare da sinistra è più complesso. Per utilizzare lo stesso indice, l'indice idx_b per l'eliminazione da sinistra, è necessario utilizzare l'inizio degli intervalli nella tabella nella clausola WHERE della query. Devo andare sul lato sinistro lontano dall'inizio dell'intervallo dato (cercato) almeno per la lunghezza dell'intervallo più lungo nella tabella, che è contrassegnato da un callout nella figura. Gli intervalli che iniziano prima della linea gialla sinistra non possono sovrapporsi all'intervallo (blu) indicato.
Poiché so già che la lunghezza dell'intervallo più lungo è 20, posso scrivere una query avanzata in un modo abbastanza semplice.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Questa query recupera le stesse righe della precedente con 20 sole letture logiche. Se controlli il piano di esecuzione, puoi vedere che è stato utilizzato idx_b, con il predicato di ricerca Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Operatore scalare((550)) , Fine:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), che ha eliminato correttamente le righe da entrambi i lati della sequenza temporale, e quindi il predicato residuo [tempdb].[dbo]. [Intervals].[e]>=(570) AND [tempdb].[dbo].[Intervals].[e]<=(610) è stato utilizzato per selezionare le righe da una scansione parziale molto limitata.
Naturalmente, la cifra potrebbe essere invertita per coprire i casi in cui l'indice idx_e sarebbe più utile. Con questo indice, l'eliminazione da sinistra è semplice:elimina tutti gli intervalli che terminano almeno un'unità prima dell'inizio dell'intervallo dato. Questa volta, l'eliminazione da destra è più complessa:la fine degli intervalli nella tabella non può essere più a destra della fine dell'intervallo dato più la lunghezza massima di tutti gli intervalli nella tabella.
Si prega di notare che questa performance è la conseguenza dei dati specifici della tabella. La lunghezza massima di un intervallo è 20. In questo modo, SQL Server può eliminare in modo molto efficiente gli intervalli da entrambi i lati. Tuttavia, se ci fosse un solo intervallo lungo nella tabella, il codice diventerebbe molto meno efficiente, perché SQL Server non sarebbe in grado di eliminare molte righe da un lato, sia a sinistra che a destra, a seconda dell'indice che userebbe . Ad ogni modo, nella vita reale, la lunghezza dell'intervallo non varia molte volte, quindi questa tecnica di ottimizzazione potrebbe essere molto utile, soprattutto perché è semplice.
Conclusione
Si prega di notare che questa è solo una possibile soluzione. È possibile trovare una soluzione più complessa, ma con prestazioni prevedibili, indipendentemente dalla lunghezza dell'intervallo più lungo nell'articolo Interval Query in SQL Server di Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-query). Tuttavia, mi piace molto il T-SQL avanzato soluzione che ho presentato in questo articolo. La soluzione è molto semplice; tutto ciò che devi fare è aggiungere due predicati alla clausola WHERE delle tue query sovrapposte. Tuttavia, questa non è la fine delle possibilità. Resta sintonizzato, nei prossimi due articoli ti mostrerò altre soluzioni, così avrai un ricco set di possibilità nella tua cassetta degli strumenti di ottimizzazione.
Strumento utile:
dbForge Query Builder per SQL Server:consente agli utenti di creare query SQL complesse in modo rapido e semplice tramite un'interfaccia visiva intuitiva senza la scrittura manuale del codice.