Ti piace analizzare le stringhe? In tal caso, una delle funzioni di stringa indispensabili da utilizzare è SQL SUBSTRING. È una di quelle abilità che uno sviluppatore dovrebbe avere per qualsiasi lingua.
Allora, come si fa?
Punti importanti nell'analisi delle stringhe
Supponiamo che tu sia nuovo nell'analisi. Quali punti importanti devi ricordare?
- Scopri quali informazioni sono incorporate nella stringa.
- Ottieni le posizioni esatte di ogni informazione in una stringa. Potrebbe essere necessario contare tutti i caratteri all'interno della stringa.
- Conosci la dimensione o la lunghezza di ogni informazione in una stringa.
- Usa la giusta funzione di stringa in grado di estrarre facilmente ogni informazione nella stringa.
Conoscere tutti questi fattori ti preparerà all'utilizzo di SQL SUBSTRING() e al passaggio di argomenti.
Sintassi SUBSTRING SQL

La sintassi di SQL SUBSTRING è la seguente:
SUBSTRING(espressione stringa, inizio, lunghezza)
- espressione stringa – a stringa letterale o un'espressione SQL che restituisce una stringa.
- inizia – un numero da cui inizierà l'estrazione. È anche basato su 1:il primo carattere nell'argomento dell'espressione stringa deve iniziare con 1, non 0. In SQL Server, è sempre un numero positivo. In MySQL o Oracle, tuttavia, può essere positivo o negativo. Se negativo, la scansione parte dalla fine della stringa.
- lunghezza – la lunghezza dei caratteri da estrarre. SQL Server lo richiede. In MySQL o Oracle, è facoltativo.
4 Esempi di SOTTOSTRINGA SQL
1. Utilizzo di SQL SUBSTRING per estrarre da una stringa letterale
Iniziamo con un semplice esempio usando una stringa letterale. Usiamo il nome di un famoso gruppo di ragazze coreane, BlackPink, e la Figura 1 illustra come funzionerà SUBSTRING:

Il codice seguente mostra come lo estrarremo:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Ora, esaminiamo anche il set di risultati nella Figura 2:
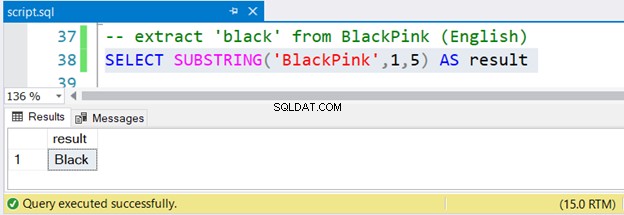
Non è facile?
Per estrarre nero da BlackPink , inizi dalla posizione 1 e finisci nella posizione 5. Poiché BlackPink è coreano, scopriamo se SUBSTRING funziona su caratteri coreani Unicode.
(RINUNCIA DI RESPONSABILITÀ :Non so parlare, leggere o scrivere in coreano, quindi ho ottenuto la traduzione in coreano da Wikipedia. Ho anche usato Google Traduttore per vedere quali caratteri corrispondono a Nero e Rosa . Per favore perdonami se è sbagliato. Spero comunque che venga il punto che sto cercando di chiarire і attraverso)
Prendiamo la stringa in coreano (vedi Figura 3). I caratteri coreani utilizzati si traducono in BlackPink:

Ora, guarda il codice qui sotto. Estrarremo due caratteri corrispondenti a Nero .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Hai notato la stringa coreana preceduta da N ? Utilizza caratteri Unicode e SQL Server presuppone NVARCHAR e dovrebbe essere preceduto da N . Questa è l'unica differenza nella versione inglese. Ma funzionerà bene? Vedi figura 4:
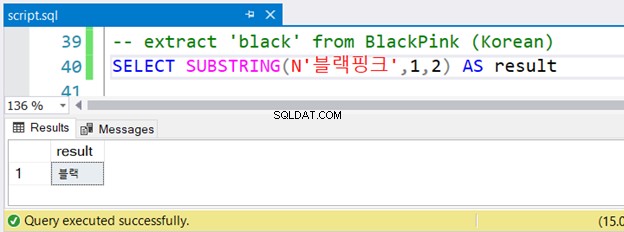
È stato eseguito senza errori.
2. Utilizzo di SQL SUBSTRING in MySQL con un argomento di inizio negativo
Avere un argomento di inizio negativo non funzionerà in SQL Server. Ma possiamo avere un esempio di questo usando MySQL. Questa volta estraiamo Rosa da BlackPink . Ecco il codice:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Ora, diamo il risultato nella Figura 5:
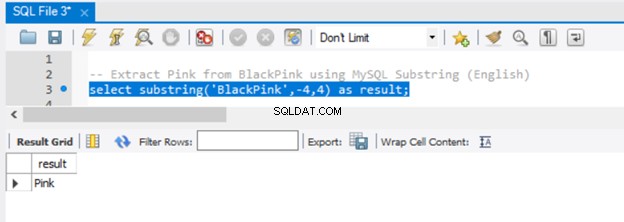
Poiché abbiamo passato -4 al parametro di inizio, l'estrazione è iniziata dalla fine della stringa, andando indietro di 4 caratteri. Per ottenere lo stesso risultato in SQL Server, utilizzare la funzione RIGHT().
I caratteri Unicode funzionano anche con MySQL SUBSTRING, come puoi vedere nella Figura 6:
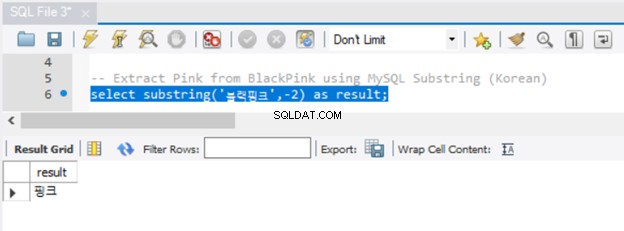
Ha funzionato bene. Ma hai notato che non era necessario far precedere la stringa con N? Inoltre, nota che ci sono diversi modi per ottenere una sottostringa in MySQL. Hai già visto SUBSTRING. Le funzioni equivalenti in MySQL sono SUBSTR() e MID().
3. Analisi di sottostringhe con argomenti di inizio e lunghezza variabili
Purtroppo, non tutte le estrazioni di stringhe utilizzano argomenti fissi di inizio e lunghezza. In tal caso, hai bisogno di CHARINDEX per ottenere la posizione di una stringa che stai prendendo di mira. Facciamo un esempio:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
Nel codice sopra, devi estrarre un nome in coreano, la data di nascita e l'account Instagram.
Iniziamo con la definizione di tre variabili per contenere queste informazioni. Successivamente, possiamo analizzare la stringa e assegnare i risultati a ciascuna variabile.
Potresti pensare che avere partenze e lunghezze fisse sia più semplice. Inoltre, possiamo individuarlo contando i caratteri manualmente. Ma cosa succede se ne hai molti su un tavolo?
Ecco la nostra analisi:
- L'unico elemento fisso nella stringa è @ personaggio nell'account Instagram. Possiamo ottenere la sua posizione nella stringa usando CHARINDEX. Quindi, utilizziamo quella posizione per ottenere l'inizio e le lunghezze del resto.
- La data di nascita è in un formato fisso utilizzando MM/gg/aaaa con 10 caratteri.
- Per estrarre il nome, partiamo da 1. Poiché la data di nascita ha 10 caratteri più @ carattere, puoi arrivare al carattere finale del nome nella stringa. Dalla posizione del @ personaggio, torniamo indietro di 11 caratteri. SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11) è la strada da percorrere.
- Per ottenere la data di nascita, applichiamo la stessa logica. Ottieni la posizione di @ carattere e sposta 10 caratteri indietro per ottenere il valore iniziale della data di nascita. 10 è una lunghezza fissa. SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10) ecco come ottenere la data di nascita.
- Infine, ottenere un account Instagram è semplice. Inizia dalla posizione di @ carattere usando CHARINDEX. Nota:30 è il limite del nome utente di Instagram.
Controlla i risultati nella Figura 7:
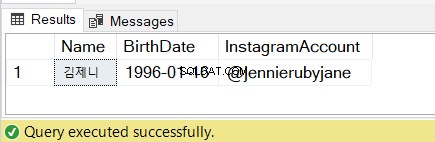
4. Utilizzo di SQL SUBSTRING in un'istruzione SELECT
Puoi anche utilizzare SUBSTRING nell'istruzione SELECT, ma prima dobbiamo disporre di dati di lavoro. Ecco il codice:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Il codice sopra forma una lunga stringa contenente il nome, l'indirizzo e-mail, la città e il codice postale. Vogliamo anche memorizzarlo nei PersonaContacts tabella.
Ora, disponiamo del codice per eseguire il reverse engineering utilizzando SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Poiché abbiamo utilizzato colonne di dimensioni fisse, non è necessario utilizzare CHARINDEX.
Utilizzo di SQL SUBSTRING in una clausola WHERE:una trappola per le prestazioni?
È vero. Nessuno può impedirti di utilizzare SUBSTRING in una clausola WHERE. È una sintassi valida. Ma cosa succede se causa problemi di prestazioni?
Ecco perché lo dimostriamo con un esempio e poi discutiamo su come risolvere questo problema. Ma prima, prepariamo i nostri dati:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Non posso rovinare il SalesOrderHeader table, quindi l'ho scaricato su un altro tavolo. Quindi, ho creato il SalesOrderID nei nuovi Ordini di vendita tabella una chiave primaria.
Ora siamo pronti per la domanda. Sto usando dbForge Studio per SQL Server con Modalità di profilatura delle query ATTIVATA per analizzare le query.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Come vedi, la query sopra funziona correttamente. Ora, guarda il diagramma del piano del profilo di query nella Figura 8:
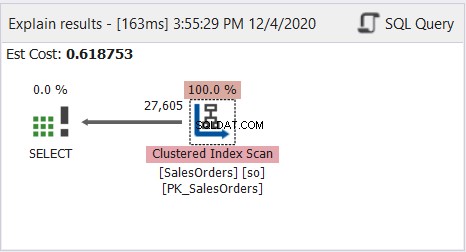
Il diagramma del piano sembra semplice, ma esaminiamo le proprietà del nodo Scansione indice cluster. In particolare, abbiamo bisogno delle informazioni sul runtime:
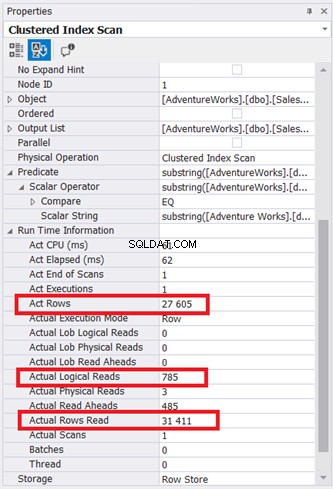
L'illustrazione 9 mostra 785 * 8 KB di pagine lette dal motore di database. Si noti inoltre che le righe effettive lette sono 31.411. È il numero totale di righe nella tabella. Tuttavia, la query ha restituito solo 27.605 righe effettive.
L'intera tabella è stata letta utilizzando l'indice cluster come riferimento.
Perché?
Il fatto è che SQL Server deve sapere se 4030 è una sottostringa di un numero di conto. Deve leggere e valutare ogni record. Scarta le righe che non sono uguali e restituisci le righe di cui abbiamo bisogno. Fa il lavoro ma non abbastanza velocemente.
Cosa possiamo fare per renderlo più veloce?
Evita di SUBSTRING nella clausola WHERE e ottieni lo stesso risultato più velocemente
Quello che vogliamo ora è ottenere lo stesso risultato senza usare SUBSTRING nella clausola WHERE. Segui i passaggi seguenti:
- Modifica la tabella aggiungendo una colonna calcolata con un SUBSTRING(AccountNumber, 4,4) formula. Chiamiamolo AccountCategory per mancanza di un termine migliore.
- Crea un indice non cluster per la nuova AccountCategory colonna. Includi la Data dell'ordine , Numero di conto e ID cliente colonne.
Questo è tutto.
Cambiamo la clausola WHERE della query per adattare la nuova AccountCategory colonna:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
Non c'è SUBSTRING nella clausola WHERE. Ora, controlliamo il diagramma del piano:
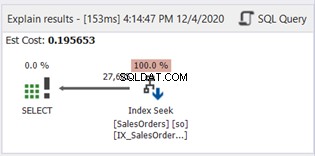
La scansione dell'indice è stata sostituita da Ricerca indice. Si noti inoltre che SQL Server ha utilizzato il nuovo indice nella colonna calcolata. Ci sono anche modifiche nelle letture logiche e nelle righe effettive lette? Vedi figura 11:
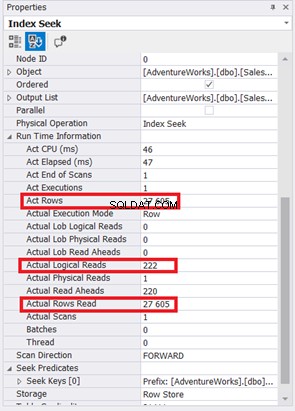
La riduzione da 785 a 222 letture logiche è un grande miglioramento, più di tre volte inferiore rispetto alle letture logiche originali. Ha anche ridotto al minimo le righe effettive Leggi solo le righe di cui abbiamo bisogno.
Pertanto, l'utilizzo di SUBSTRING nella clausola WHERE non è positivo per le prestazioni e vale per qualsiasi altra funzione a valori scalari utilizzata nella clausola WHERE.
Conclusione
- Gli sviluppatori non possono evitare di analizzare le stringhe. In un modo o nell'altro ne sorgerà la necessità.
- Nell'analisi delle stringhe, è essenziale conoscere le informazioni all'interno della stringa, le posizioni di ciascuna informazione e le loro dimensioni o lunghezze.
- Una delle funzioni di analisi è SUBSTRING SQL. Ha solo bisogno della stringa da analizzare, della posizione per iniziare l'estrazione e della lunghezza della stringa da estrarre.
- SUBSTRING può avere comportamenti diversi tra le versioni SQL come SQL Server, MySQL e Oracle.
- Puoi utilizzare SUBSTRING con stringhe letterali e stringhe nelle colonne della tabella.
- Abbiamo anche usato SUBSTRING con i caratteri Unicode.
- L'utilizzo di SUBSTRING o di qualsiasi funzione con valori scalari nella clausola WHERE può ridurre le prestazioni della query. Risolvi il problema con una colonna calcolata indicizzata.
Se trovi utile questo post, condividilo sulle tue piattaforme di social media preferite o condividi il tuo commento qui sotto?