Nel mio ultimo post ("Amico, chi possiede quella tabella #temp?"), Ho suggerito che in SQL Server 2012 e versioni successive, potresti utilizzare gli eventi estesi per monitorare la creazione di tabelle #temp. Ciò consentirebbe di correlare oggetti specifici che occupano molto spazio in tempdb con la sessione che li ha creati (ad esempio, per determinare se la sessione può essere terminata per tentare di liberare spazio). Quello che non ho discusso è il sovraccarico di questo monitoraggio:ci aspettiamo che gli eventi estesi siano più leggeri della traccia, ma nessun monitoraggio è completamente gratuito.
Poiché la maggior parte delle persone lascia abilitata la traccia predefinita, la lasceremo al suo posto. Testeremo entrambi gli heap usando SELECT INTO (che la traccia predefinita non raccoglierà) e gli indici cluster (che lo farà) e cronometrare il batch da solo come linea di base, quindi eseguire nuovamente il batch con la sessione di eventi estesi in esecuzione. Verificheremo inoltre sia SQL Server 2012 che SQL Server 2014. Il batch stesso è piuttosto semplice:
SET NOCOUNT ON; SELECT SYSDATETIME(); GO -- run this portion for only the heap batch: SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #foo; -- run this portion for only the CIX batch: CREATE TABLE #bar(id INT PRIMARY KEY); INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #bar; GO 100000 SELECT SYSDATETIME();
Entrambe le istanze hanno tempdb configurato con quattro file di dati e con TF 1117 e TF 1118 abilitati, in una macchina virtuale con quattro CPU, 16 GB di memoria e solo SSD. Ho creato intenzionalmente piccole tabelle #temp per amplificare qualsiasi impatto osservato sul batch stesso (che verrebbe soffocato se la creazione delle tabelle #temp richiedesse molto tempo o causasse eventi di crescita automatica eccessivi).
Ho eseguito questi batch in ogni scenario ed ecco i risultati, misurati in base alla durata del batch in secondi:
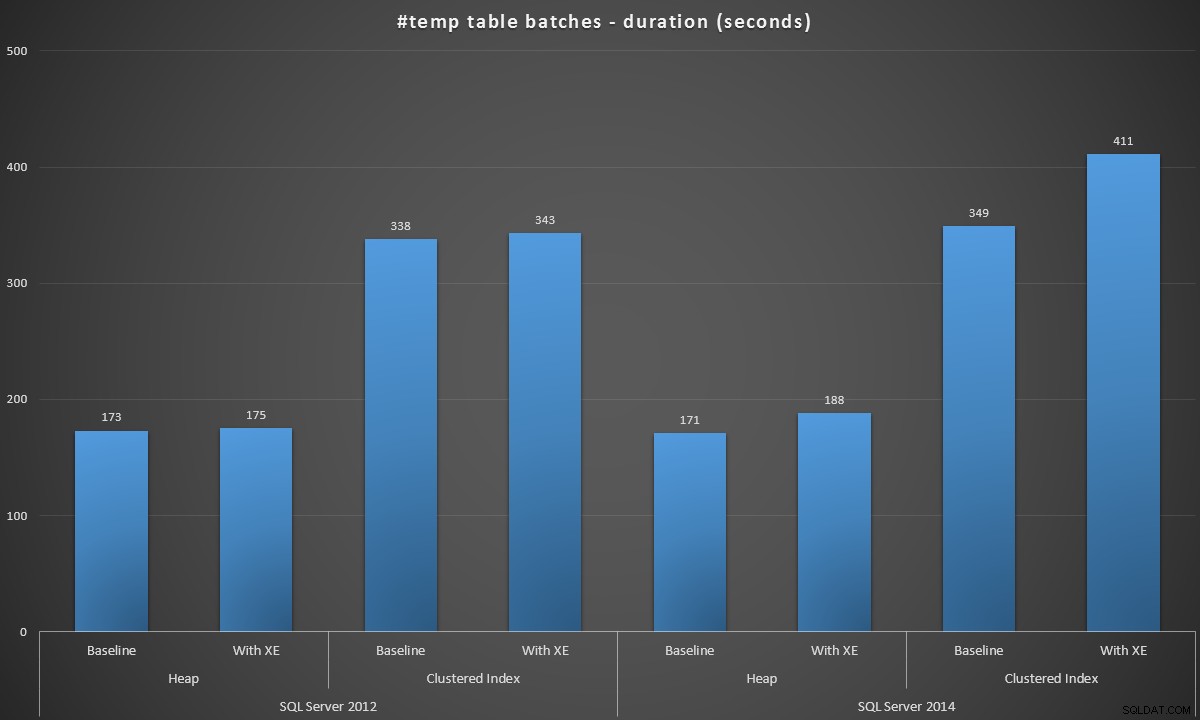
Durata batch, in secondi, della creazione di 100.000 tabelle #temp
Esprimendo i dati in modo leggermente diverso, se dividiamo 100.000 per la durata, possiamo mostrare il numero di tabelle #temp che possiamo creare al secondo in ogni scenario (leggi:throughput). Ecco i risultati:
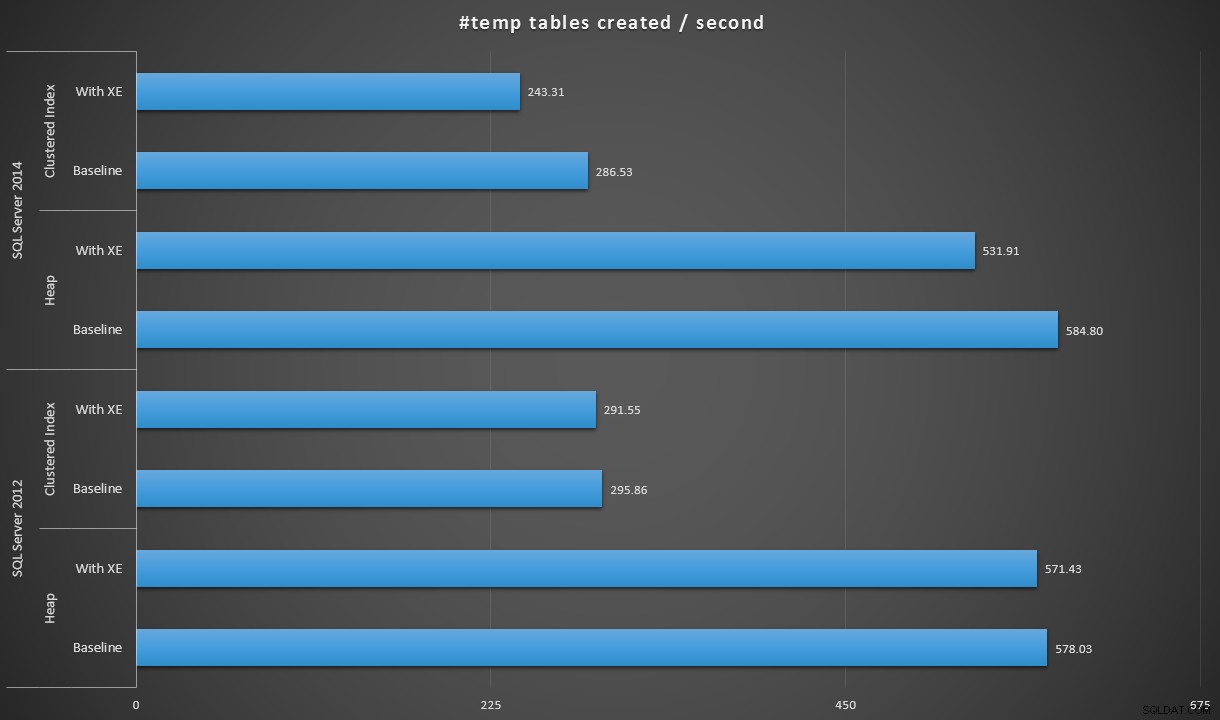
Tabelle #temp create al secondo in ogni scenario
I risultati sono stati un po' sorprendenti per me:mi aspettavo che, con i miglioramenti di SQL Server 2014 nella logica di scrittura ansiosa, la popolazione dell'heap come minimo sarebbe stata molto più veloce. L'heap nel 2014 è stato di due miseri secondi più veloce rispetto al 2012 nella configurazione di base, ma gli eventi estesi hanno aumentato un po' il tempo (circa un aumento del 10% rispetto alla baseline); mentre il tempo dell'indice raggruppato era paragonabile al 2012 alla linea di base, ma è aumentato di quasi il 18% con gli eventi estesi abilitati. Nel 2012 i delta degli heap e degli indici cluster sono stati molto più modesti, rispettivamente dell'1,1% e dell'1,5%. (E per essere chiari, non si sono verificati eventi di crescita automatica durante nessuno dei test.)
Quindi, ho pensato, e se avessi creato una sessione di eventi estesi più snella e cattiva? Sicuramente potrei rimuovere alcune di quelle colonne di azione, forse ho solo bisogno del nome di accesso e dello spid e posso ignorare il nome dell'app, il nome host e sql_text potenzialmente costoso. Forse potrei eliminare il filtro aggiuntivo contro il commit (raccogliendo il doppio degli eventi, ma meno CPU spesa per il filtraggio) e consentire la perdita di più eventi per ridurre il potenziale impatto sul carico di lavoro. Questa sessione più snella si presenta così:
CREATE EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER
ADD EVENT sqlserver.object_created
(
ACTION
(
sqlserver.server_principal_name,
sqlserver.session_id
)
WHERE
(
sqlserver.like_i_sql_unicode_string([object_name], N'#%')
)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = 'c:\temp\TempTableCreation2014_LeanerMeaner.xel',
MAX_FILE_SIZE = 32768,
MAX_ROLLOVER_FILES = 10
)
WITH
(
EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
);
GO
ALTER EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER STATE = START; Ahimè, no, stessi risultati. Poco più di tre minuti per l'heap e poco meno di sette minuti per l'indice cluster. Per approfondire dove veniva speso il tempo extra, ho guardato l'istanza 2014 con SQL Sentry ed ho eseguito solo il batch di indici cluster senza alcuna sessione di eventi estesi configurata. Quindi ho eseguito di nuovo il batch, questa volta con la sessione XE più leggera configurata. I tempi del batch erano 5:47 (347 secondi) e 6:55 (415 secondi), quindi molto in linea con il batch precedente (sono stato felice di vedere che il nostro monitoraggio non ha contribuito ulteriormente alla durata :-)) . Ho verificato che nessun evento è stato eliminato e ancora una volta che non si sono verificati eventi di crescita automatica.
Ho esaminato la dashboard di SQL Sentry in modalità cronologia, che mi ha permesso di visualizzare rapidamente le metriche delle prestazioni di entrambi i batch fianco a fianco:
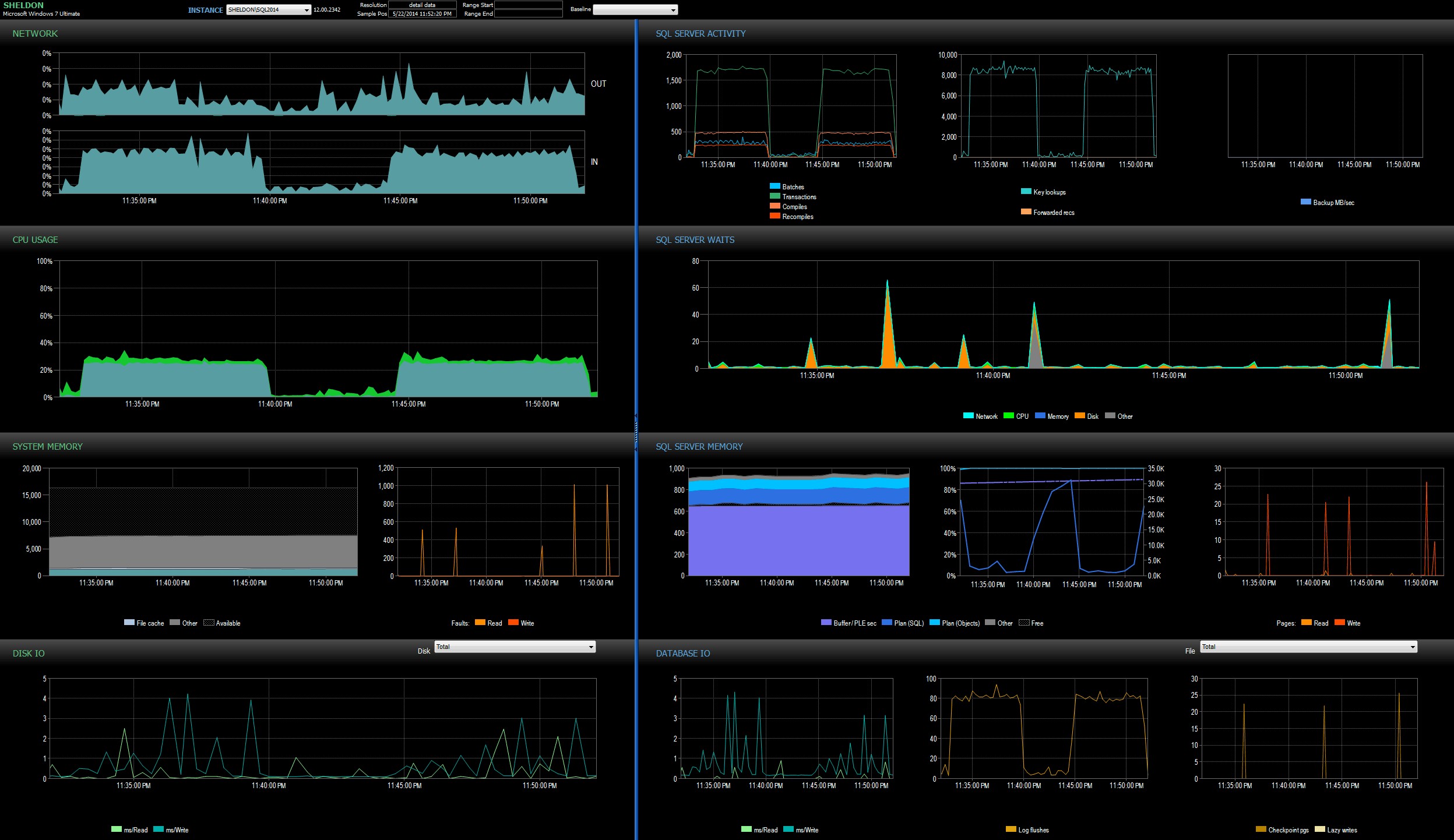
Dashboard di SQL Sentry, in modalità cronologia, che mostra entrambi i batch
Entrambi i batch erano praticamente identici in termini di rete, CPU, transazioni, compilazioni, ricerche di chiavi, ecc. C'è una leggera differenza nelle attese:i picchi durante il primo batch erano esclusivamente WRITELOG, mentre c'erano alcune attese CXPACKET minori trovate nel secondo lotto. La mia teoria di lavoro ben dopo la mezzanotte è che forse una buona parte del ritardo osservato era dovuto al cambio di contesto causato dal processo degli eventi estesi. Dal momento che non abbiamo alcuna visibilità su ciò che XE sta facendo esattamente sotto le coperte, né sappiamo quali meccanismi sottostanti sono cambiati in XE tra il 2012 e il 2014, questa è la storia su cui mi atterrò per ora, finché non sarò più a suo agio con xperf e/o WinDbg.
Conclusione
In ogni caso, è chiaro che il monitoraggio della creazione delle tabelle #temp non è gratuito e il costo può variare a seconda del tipo di tabelle #temp che stai creando, della quantità di informazioni che stai raccogliendo nelle tue sessioni XE e persino della versione di SQL Server in uso. Quindi puoi eseguire test simili a quelli che ho fatto qui e decidere quanto sia preziosa la raccolta di queste informazioni nel tuo ambiente.