Le tue scelte sui tipi di dati del server SQL e le loro dimensioni contano?
La risposta sta nel risultato che hai ottenuto. Il tuo database si è gonfiato in breve tempo? Le tue domande sono lente? Hai avuto risultati sbagliati? Che ne dici di errori di runtime durante inserimenti e aggiornamenti?
Non è un compito così scoraggiante se sai cosa stai facendo. Oggi imparerai le 5 scelte peggiori che si possono fare con questi tipi di dati. Se sono diventati una tua abitudine, questa è la cosa che dovremmo aggiustare per il tuo bene e per i tuoi utenti.
Tanti tipi di dati in SQL, molta confusione
Quando ho appreso per la prima volta i tipi di dati di SQL Server, le scelte erano travolgenti. Tutti i tipi sono confusi nella mia mente come questa nuvola di parole nella Figura 1:

Tuttavia, possiamo organizzarlo in categorie:
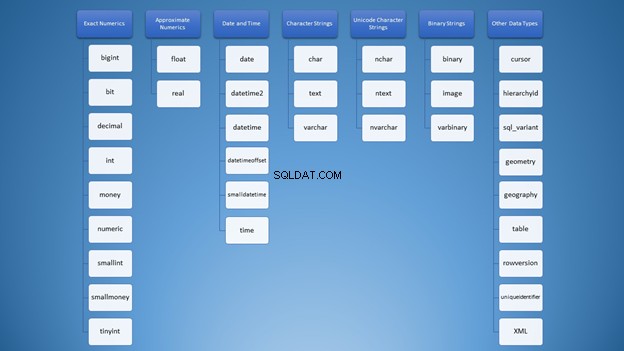
Tuttavia, per l'utilizzo di stringhe, hai molte opzioni che possono portare a un utilizzo errato. All'inizio pensavo che varchar e nvarchar erano proprio gli stessi. Inoltre, sono entrambi tipi di stringhe di caratteri. Usare i numeri non è diverso. Come sviluppatori, dobbiamo sapere quale tipo utilizzare in diverse situazioni.
Ma potresti chiederti, qual è la cosa peggiore che può succedere se faccio la scelta sbagliata? Lascia che te lo dica!
1. Scelta dei tipi di dati SQL errati
Questo oggetto utilizzerà stringhe e numeri interi per dimostrare il punto.
Utilizzo del tipo di dati SQL della stringa di caratteri errato
Per prima cosa, torniamo alle stringhe. C'è questa cosa chiamata stringhe Unicode e non Unicode. Entrambi hanno dimensioni di archiviazione diverse. Lo definisci spesso su colonne e dichiarazioni di variabili.
La sintassi è varchar (n)/char (n) o nvarchar (n)/nchar (n) dove n è la dimensione.
Tieni presente che n non è il numero di caratteri ma il numero di byte. È un malinteso comune che si verifica perché, in varchar , il numero di caratteri è uguale alla dimensione in byte. Ma non in nvarchar .
Per provare questo fatto, creiamo 2 tabelle e inseriamo alcuni dati in esse.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Ora controlliamo le dimensioni delle righe utilizzando DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
La figura 3 mostra che la differenza è duplice. Dai un'occhiata qui sotto.
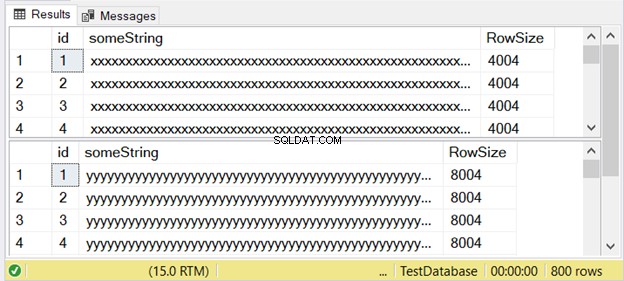
Notare il secondo set di risultati con una dimensione di riga di 8004. Questo utilizza nvarchar tipo di dati. È anche quasi il doppio della dimensione della riga del primo set di risultati. E questo usa il varchar tipo di dati.
Vengono visualizzate le implicazioni su storage e I/O. La figura 4 mostra le letture logiche delle 2 query.
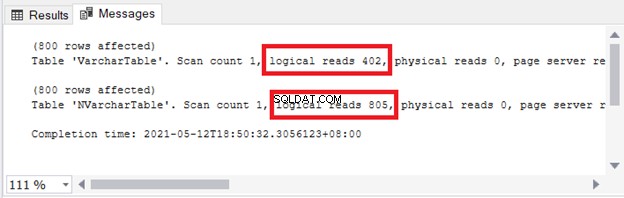
Vedere? Anche le letture logiche sono duplici quando si usa nvarchar rispetto a varchar .
Quindi, non puoi semplicemente usarli in modo intercambiabile. Se devi archiviare multilingue caratteri, usa nvarchar . Altrimenti, usa varchar .
Ciò significa che se usi nvarchar solo per i caratteri a byte singolo (come l'inglese), la dimensione di archiviazione è maggiore . Le prestazioni delle query sono anche più lente con letture logiche più elevate.
In SQL Server 2019 (e versioni successive), puoi archiviare l'intera gamma di dati di caratteri Unicode utilizzando varchar o char con una qualsiasi delle opzioni di confronto UTF-8.
Utilizzo del tipo di dati numerico errato SQL
Lo stesso concetto si applica a bigint rispetto a int – le loro dimensioni possono significare notte e giorno. Come nvarchar e varchar , grande è il doppio di int (8 byte per bigint e 4 byte per int ).
Tuttavia, un altro problema è possibile. Se non ti dispiace le loro dimensioni, possono verificarsi degli errori. Se usi un int colonna e memorizzare un numero maggiore di 2.147.483.647, si verificherà un overflow aritmetico:
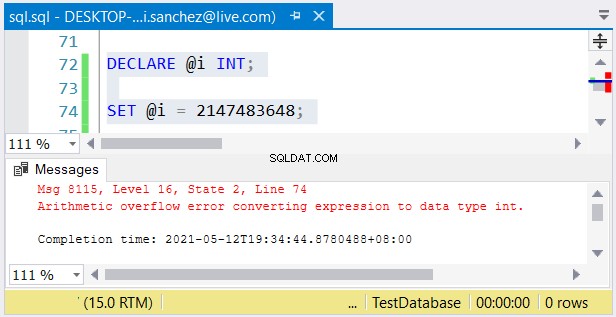
Quando scegli i tipi di numeri interi, assicurati che i dati con il valore massimo si adattino . Ad esempio, potresti progettare una tabella con dati storici. Prevedi di utilizzare numeri interi come valore della chiave primaria. Pensi che non raggiungerà 2.147.483.647 righe? Quindi usa int invece di bigint come tipo di colonna della chiave primaria.
La cosa peggiore che può succedere
La scelta dei tipi di dati sbagliati può influire sulle prestazioni della query o causare errori di runtime. Pertanto, scegli il tipo di dati adatto ai dati.
2. Creazione di righe di tabelle di grandi dimensioni utilizzando i tipi di Big Data per SQL
Il nostro prossimo articolo è correlato al primo, ma amplierà ulteriormente il punto con esempi. Inoltre, ha qualcosa a che fare con le pagine e varchar di grandi dimensioni o nvarchar colonne.
Che cos'è con le pagine e le dimensioni delle righe?
Il concetto di pagine in SQL Server può essere paragonato alle pagine di un quaderno a spirale. Ogni pagina di un taccuino ha la stessa dimensione fisica. Scrivi parole e disegna immagini su di esse. Se una pagina non è sufficiente per un insieme di paragrafi e immagini, si continua alla pagina successiva. A volte strappi anche una pagina e ricominci da capo.
Allo stesso modo, i dati delle tabelle, le voci di indice e le immagini in SQL Server vengono archiviate in pagine.
Una pagina ha la stessa dimensione di 8 KB. Se una riga di dati è molto grande, non si adatterà alla pagina da 8 KB. Una o più colonne verranno scritte in un'altra pagina sotto l'unità di allocazione ROW_OVERFLOW_DATA. Contiene un puntatore alla riga originale nella pagina sotto l'unità di allocazione IN_ROW_DATA.
Sulla base di ciò, non puoi semplicemente adattare molte colonne in una tabella durante la progettazione del database. Ci saranno conseguenze sull'I/O. Inoltre, se esegui molte query su questi dati di overflow di riga, il tempo di esecuzione è più lento . Questo può essere un incubo.
Si verifica un problema quando si esauriscono al massimo tutte le colonne di dimensioni variabili. Quindi, i dati passeranno alla pagina successiva in ROW_OVERFLOW_DATA. aggiorna le colonne con dati di dimensioni inferiori e deve essere rimosso in quella pagina. La nuova riga di dati più piccola verrà scritta nella pagina in IN_ROW_DATA insieme alle altre colonne. Immagina l'I/O coinvolto qui.
Esempio di riga grande
Prepariamo prima i nostri dati. Utilizzeremo tipi di dati di stringhe di caratteri con dimensioni grandi.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Ottenere la dimensione della riga
Dai dati generati, esaminiamo le dimensioni delle righe in base a DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
I primi 300 record si adatteranno alle pagine IN_ROW_DATA perché ogni riga ha meno di 8060 byte o 8 KB. Ma le ultime 100 righe sono troppo grandi. Controlla il set di risultati nella Figura 6.
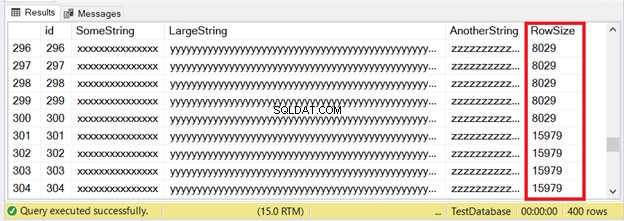
Vedi parte delle prime 300 righe. I successivi 100 superano il limite delle dimensioni della pagina. Come facciamo a sapere che le ultime 100 righe si trovano nell'unità di allocazione ROW_OVERFLOW_DATA?
Ispezione di ROW_OVERFLOW_DATA
Useremo sys.dm_db_index_physical_stats . Restituisce le informazioni sulla pagina sulle voci di tabella e indice.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Il set di risultati è nella Figura 7.

Eccolo. La Figura 7 mostra 100 righe in ROW_OVERFLOW_DATA. Ciò è coerente con la Figura 6 quando esistono righe di grandi dimensioni a partire dalle righe da 301 a 400.
La prossima domanda è quante letture logiche otteniamo quando interroghiamo queste 100 righe. Proviamo.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Vediamo 102 letture logiche e 100 letture logiche lob di LargeTable . Lascia questi numeri per ora:li confronteremo più tardi.
Ora vediamo cosa succede se aggiorniamo le 100 righe con dati più piccoli.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Questa istruzione di aggiornamento utilizzava le stesse letture logiche e letture logiche lob della Figura 8. Da ciò, sappiamo che è successo qualcosa di più grande a causa delle letture logiche lob di 100 pagine.
Ma per essere sicuri, controlliamolo con sys.dm_db_index_physical_stats come abbiamo fatto prima. La figura 9 mostra il risultato:

Andato! Le pagine e le righe di ROW_OVERFLOW_DATA sono diventate zero dopo aver aggiornato 100 righe con dati più piccoli. Ora sappiamo che lo spostamento dei dati da ROW_OVERFLOW_DATA a IN_ROW_DATA avviene quando le righe di grandi dimensioni vengono ridotte. Immagina se ciò accadesse spesso per migliaia o addirittura milioni di record. Pazzesco, vero?
Nella Figura 8, abbiamo visto 100 letture logiche lob. Ora, vedere la Figura 10 dopo aver eseguito nuovamente la query:

È diventato zero!
La cosa peggiore che può succedere
Le prestazioni lente delle query sono il sottoprodotto dei dati di overflow delle righe. Prendi in considerazione di spostare le colonne di grandi dimensioni in un'altra tabella per evitarlo. Oppure, se applicabile, riduci la dimensione del varchar o nvarchar colonna.
3. Usando ciecamente la conversione implicita
SQL non ci consente di utilizzare i dati senza specificare il tipo. Ma è clemente se facciamo una scelta sbagliata. Prova a convertire il valore nel tipo previsto, ma con una penalità. Questo può accadere in una clausola WHERE o JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Il Numero Carta la colonna non è di tipo numerico. È nvarchar . Quindi, il primo SELECT causerà una conversione implicita. Tuttavia, entrambi funzioneranno perfettamente e produrranno lo stesso set di risultati.
Verifichiamo il piano di esecuzione in Figura 11.
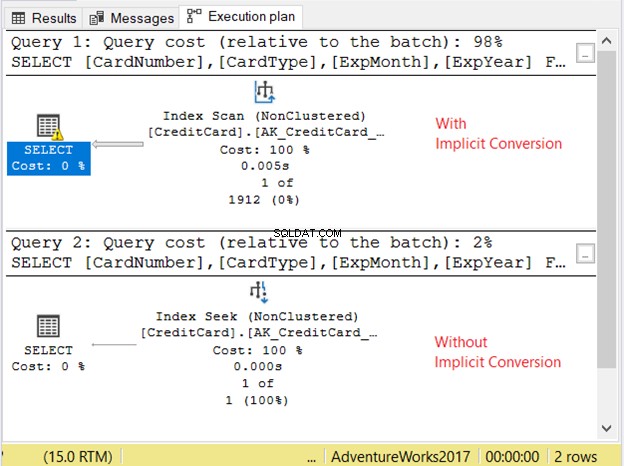
Le 2 query sono state eseguite molto rapidamente. Nella Figura 11, sono zero secondi. Ma guarda i 2 piani. Quello con la conversione implicita aveva una scansione dell'indice. C'è anche un'icona di avviso e una freccia grossa che punta all'operatore SELECT. Ci dice che è brutto.
Ma non finisce qui. Se passi il mouse sopra l'operatore SELECT, vedrai qualcos'altro:

L'icona di avviso nell'operatore SELECT riguarda la conversione implicita. Ma quanto è grande l'impatto? Controlliamo le letture logiche.
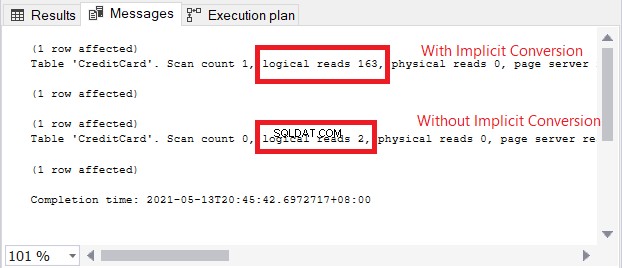
Il confronto delle letture logiche nella Figura 13 è come il cielo e la terra. Nella query per le informazioni sulla carta di credito, la conversione implicita ha causato più di cento volte le letture logiche. Molto male!
La cosa peggiore che può succedere
Se una conversione implicita ha causato letture logiche elevate e un piano errato, aspettarsi prestazioni di query lente su set di risultati di grandi dimensioni. Per evitare ciò, utilizza il tipo di dati esatto nella clausola WHERE e JOINs in corrispondenza delle colonne che confronti.
4. Utilizzo di numeri approssimativi e arrotondamento
Controlla di nuovo la figura 2. I tipi di dati del server SQL appartenenti a valori numerici approssimativi sono float e reale . Le colonne e le variabili composte da esse memorizzano una stretta approssimazione di un valore numerico. Se prevedi di arrotondare questi numeri per eccesso o per difetto, potresti ricevere una grande sorpresa. Ho un articolo che ne ha discusso in dettaglio qui. Guarda come 1 + 1 si traduce in 3 e come puoi gestire i numeri arrotondati.
La cosa peggiore che può succedere
Arrotondare un virgola mobile o reale può avere risultati pazzeschi. Se desideri valori esatti dopo l'arrotondamento, utilizza decimale o numerico invece.
5. Impostazione dei tipi di dati stringa di dimensioni fisse su NULL
Rivolgiamo la nostra attenzione ai tipi di dati a dimensione fissa come char e nchar . A parte gli spazi riempiti, impostandoli su NULL avrà ancora una dimensione di archiviazione uguale alla dimensione del carattere colonna. Quindi, impostando un char (500) la colonna su NULL avrà una dimensione di 500, non zero o 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
Nel codice sopra, i dati vengono massimizzati in base alla dimensione di char e varchar colonne. Il controllo delle dimensioni delle righe mediante DATALENGTH mostrerà anche la somma delle dimensioni di ciascuna colonna. Ora impostiamo le colonne su NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Successivamente, interroghiamo le righe utilizzando DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Quali pensi saranno le dimensioni dei dati di ciascuna colonna? Dai un'occhiata alla Figura 14.
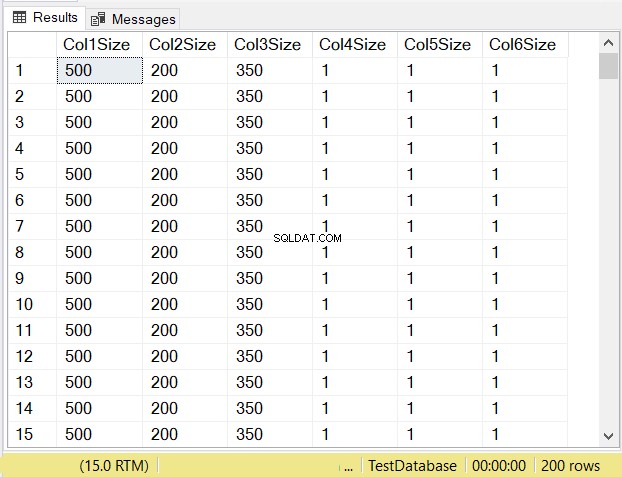
Guarda le dimensioni delle colonne delle prime 3 colonne. Quindi confrontali con il codice sopra quando è stata creata la tabella. La dimensione dei dati delle colonne NULL è uguale alla dimensione della colonna. Nel frattempo, il varchar colonne quando NULL hanno una dimensione dei dati di 1.
La cosa peggiore che può succedere
Durante le tabelle di progettazione, nullable char le colonne, se impostate su NULL, avranno ancora la stessa dimensione di archiviazione. Utilizzeranno anche le stesse pagine e RAM. Se non riempi l'intera colonna di caratteri, considera l'utilizzo di varchar invece.
Cosa c'è dopo?
Quindi, le tue scelte nei tipi di dati del server SQL e le loro dimensioni contano? I punti qui presentati dovrebbero essere sufficienti per fare un punto. Allora, cosa puoi fare adesso?
- Ritagliati del tempo per rivedere il database che supporti. Inizia con quello più semplice se ne hai diversi nel piatto. E sì, trova il tempo, non trova il tempo. Nel nostro lavoro è quasi impossibile trovare il tempo.
- Esaminare le tabelle, le stored procedure e tutto ciò che riguarda i tipi di dati. Notare l'impatto positivo quando si identificano i problemi. Ne avrai bisogno quando il tuo capo ti chiederà perché devi lavorare su questo.
- Pianifica di attaccare ciascuna delle aree problematiche. Segui tutte le metodologie o le politiche che la tua azienda ha per affrontare i problemi.
- Una volta che i problemi saranno risolti, festeggia.
Sembra facile, ma sappiamo tutti che non lo è. Sappiamo anche che c'è un lato positivo alla fine del viaggio. Ecco perché sono chiamati problemi – perché c'è una soluzione. Quindi, rallegrati.
Hai qualcos'altro da aggiungere su questo argomento? Facci sapere nella sezione commenti. E se questo post ti ha dato un'idea brillante, condividila sulle tue piattaforme di social media preferite.