Sono in procinto di riordinare la mia casa (troppo tardi in estate per provare a farla passare per pulizie di primavera). Sai, pulire gli armadi, esaminare i giocattoli dei bambini e organizzare il seminterrato. È un processo doloroso. Quando ci siamo trasferiti a casa nostra 10 anni fa, avevamo così tanto spazio. Ora mi sembra che ci siano cose dappertutto e rende più difficile trovare ciò che sto veramente cercando e ci vuole sempre più tempo per ripulire e organizzare.
Ti sembra un database che gestisci?
Molti clienti con cui ho lavorato si occupano dell'eliminazione dei dati come ripensamento. Al momento dell'implementazione, tutti vogliono salvare tutto. "Non sappiamo mai quando potremmo averne bisogno." Dopo un anno o due qualcuno si rende conto che ci sono molte cose in più nel database, ma ora le persone hanno paura di sbarazzarsene. "Dobbiamo verificare con Legal per vedere se possiamo eliminarlo." Ma nessuno controlla con Legal, o se qualcuno lo fa, Legal torna dai proprietari degli affari per chiedere cosa tenere, e poi il progetto si ferma. “Non possiamo raggiungere un consenso su cosa può essere cancellato”. Il progetto viene dimenticato e dopo due o quattro anni il database diventa improvvisamente un terabyte, difficile da gestire e le persone incolpano tutti i problemi di prestazioni sulla dimensione del database. Senti le parole "partizionamento" e "database di archiviazione" in giro e, a volte, puoi semplicemente eliminare un mucchio di dati, il che ha i suoi problemi.
Idealmente, dovresti decidere la tua strategia di eliminazione prima dell'implementazione o entro i primi sei-dodici mesi dal go-live. Ma poiché abbiamo superato quella fase, diamo un'occhiata all'impatto che possono avere questi dati extra.
Metodologia di prova
Per preparare il terreno, ho preso una copia del database dei crediti e l'ho ripristinato nella mia istanza di SQL Server 2012. Ho eliminato i tre indici non cluster esistenti e ne ho aggiunti due miei:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Ho quindi aumentato il numero di righe nella tabella a 14,4 milioni, reinserindo più volte l'insieme di righe originale, modificando leggermente le date:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Infine, ho impostato un cablaggio di test per eseguire una serie di istruzioni sul database quattro volte ciascuna. Di seguito le dichiarazioni:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Prima di ogni istruzione che eseguivo
DBCC DROPCLEANBUFFERS; GO
per cancellare il pool di buffer. Ovviamente questo non è qualcosa da eseguire contro un ambiente di produzione. L'ho fatto qui per fornire un punto di partenza coerente per ogni test.
Dopo ogni esecuzione, ho aumentato la dimensione della tabella dbo.charge inserendo le 14,4 milioni di righe con cui ho iniziato, ma ho aumentato charge_dt di un anno per ogni esecuzione. Ad esempio:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Dopo l'aggiunta di 14,4 milioni di righe, ho eseguito nuovamente il cablaggio di prova. L'ho ripetuto sei volte, sommando essenzialmente sei "anni" di dati. La tabella dbo.charge è iniziata con i dati del 1999 e dopo i ripetuti inserimenti conteneva dati fino al 2005.
Risultati
I risultati delle esecuzioni possono essere visti qui:
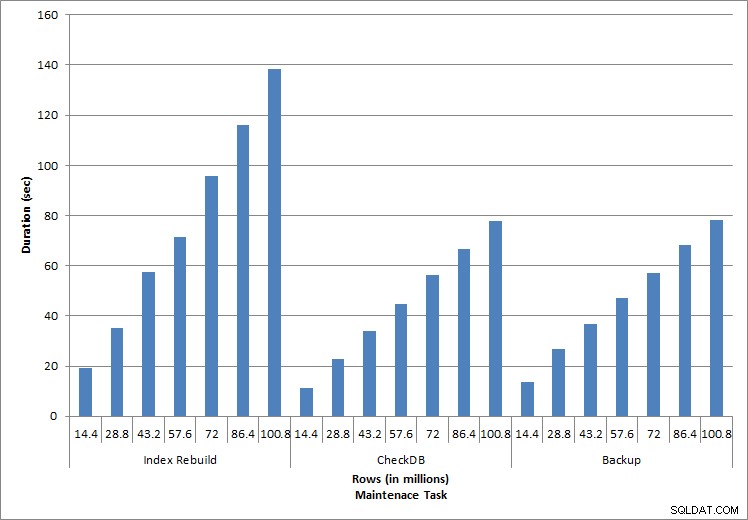
Durata delle attività di manutenzione
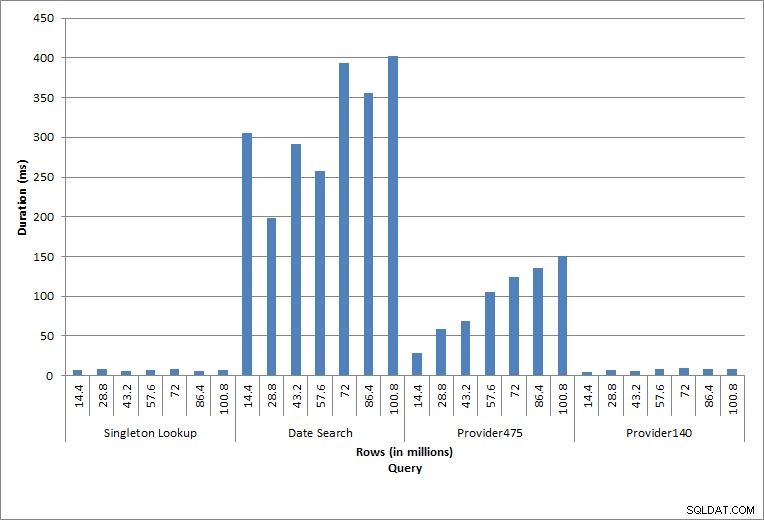
Durata delle query
Le singole istruzioni eseguite riflettono l'attività tipica del database. Ricostruzioni degli indici, controlli di integrità e backup fanno parte della normale manutenzione del database. Le query sulla tabella degli addebiti rappresentano una ricerca singleton e tre varianti di scansioni dell'intervallo specifiche per i dati nella tabella.
Rebuild, CHECKDB e backup dell'indice
Come previsto per le attività di manutenzione, i valori di durata e I/O sono aumentati con l'aggiunta di più righe al database. La dimensione del database è aumentata di un fattore 10 e, sebbene le durate non siano aumentate alla stessa velocità, è stato osservato un aumento consistente. Il completamento di ciascuna attività di manutenzione inizialmente richiedeva meno di 20 secondi, ma man mano che venivano aggiunte più righe, la durata delle attività aumentava a quasi 1 minuto e 20 secondi per 100 milioni di righe (e a oltre 2 minuti per la ricostruzione dell'indice). Ciò riflette il tempo aggiuntivo richiesto da SQL Server per completare l'attività a causa di dati aggiuntivi.
Ricerca singleton
La query contro dbo.charge per uno specifico charge_no ha sempre prodotto una riga e avrebbe prodotto una riga indipendentemente dal valore utilizzato, poiché charge_no è un'identità univoca. C'è una variazione minima per questa ricerca. Poiché le righe vengono aggiunte continuamente alla tabella, l'indice può aumentare in profondità di uno o due livelli (di più man mano che la tabella si allarga), aggiungendo quindi un paio di IO, ma questa è una ricerca singleton con pochissimi IO.
Scansioni a distanza
La query per un intervallo di date (charge_dt) è stata modificata dopo ogni inserimento per cercare i dati dell'anno più recente per luglio (ad es. da "01-07-2005" a "01-07-2005" per l'ultima serie di test), ma è stata restituita poco più di 1,2 milioni di righe ogni volta. In uno scenario reale, non ci si aspetterebbe che venga restituito lo stesso numero di righe per lo stesso mese, anno dopo anno, né ci si aspetterebbe che venga restituito lo stesso numero di righe per ogni mese di un anno. Ma il conteggio delle righe potrebbe rimanere all'interno dello stesso intervallo tra i mesi, con lievi aumenti nel tempo. Esistono fluttuazioni nella durata di questa query, ma una revisione dei dati IO acquisiti da sys.dm_io_virtual_file_stats mostra la coerenza nel numero di letture.
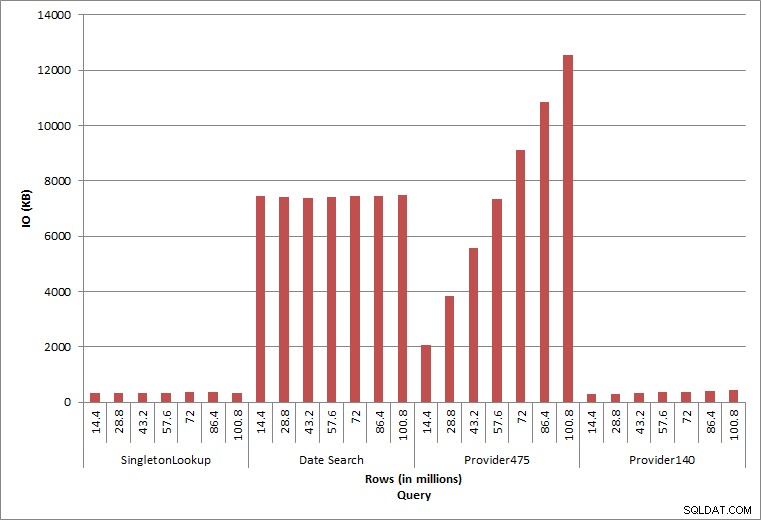
Query IO
Le ultime due query, per due diversi valori provider_no, mostrano il vero effetto della conservazione dei dati. Nella tabella iniziale dbo.charge, provider_no 475 aveva oltre 126.000 righe e provider_no 140 aveva oltre 1700 righe. Per ogni 14,4 milioni di righe aggiunte, è stato aggiunto all'incirca lo stesso numero di righe per ogni provider_no. In un ambiente di produzione, questo tipo di distribuzione dei dati non è raro e le query per questi dati possono funzionare bene nei primi anni della soluzione, ma possono peggiorare nel tempo man mano che vengono aggiunte più righe. La durata della query aumenta di un fattore cinque (da 31 ms a 153 ms) tra l'esecuzione iniziale e quella finale per provider_no 475. Sebbene questo impatto possa non sembrare significativo, si noti l'aumento parallelo di IO (sopra). Se si tratta di una query eseguita con frequenza elevata e/o se sono presenti query simili eseguite con frequenza regolare, il carico aggiuntivo può sommarsi e influire sull'utilizzo complessivo delle risorse. Inoltre, considera l'impatto quando lavori con tabelle che hanno miliardi di righe e vengono utilizzate in query con join complessi e l'impatto sulle tue attività di manutenzione regolari ed estremamente critiche. Infine, tenere conto del tempo di recuperabilità. Il piano di ripristino di emergenza deve essere basato sui tempi di ripristino e, con l'aumento delle dimensioni del database, il ripristino completo del database richiederà più tempo. Se non esegui regolarmente il test e la tempistica dei ripristini, il ripristino da un disastro potrebbe richiedere più tempo di quanto pensassi.
Riepilogo
Gli esempi mostrati qui sono semplici illustrazioni di cosa può accadere quando una strategia di archiviazione dei dati non viene determinata durante l'implementazione del database e ci sono molti altri scenari da esplorare e testare. I vecchi dati a cui si accede raramente, se non mai, hanno un impatto maggiore del semplice spazio su disco. Può influire sulle prestazioni delle query e sulla durata delle attività di manutenzione. In quanto DBA che gestisce più database su un'istanza, un database che contiene dati storici può influire sulle prestazioni e sulle attività di manutenzione di altri database. Inoltre, se i rapporti vengono eseguiti in base ai dati storici, ciò può devastare l'ambiente OLTP già occupato.
Fin dall'inizio, è fondamentale determinare la durata dei dati in un database e mettere in atto un piano d'azione. Per alcune soluzioni, è necessario conservare tutti i dati per sempre. In questo caso, utilizzare strategie per mantenere gestibili le dimensioni del database, ad esempio:archiviare i dati in una tabella separata o in un database separato su base regolare. Nel caso in cui i dati non debbano essere archiviati per anni e anni, implementare una strategia di eliminazione che rimuove i dati su base regolare. In questo modo, puoi buttare via i giocattoli con cui non si gioca più, i vestiti che non ti stanno più e le cianfrusaglie casuali che non usi ogni tre mesi... piuttosto che una volta ogni 10 anni.