La funzione finestra ROW_NUMBER ha numerose applicazioni pratiche, ben oltre le ovvie esigenze di ranking. La maggior parte delle volte, quando si calcolano i numeri di riga, è necessario calcolarli in base a un ordine e fornire la specifica di ordinamento desiderata nella clausola dell'ordine della finestra della funzione. Tuttavia, ci sono casi in cui è necessario calcolare i numeri di riga senza un ordine particolare; in altre parole, basato su un ordine non deterministico. Questo potrebbe riguardare l'intero risultato della query o all'interno delle partizioni. Gli esempi includono l'assegnazione di valori univoci alle righe dei risultati, la deduplicazione dei dati e la restituzione di qualsiasi riga per gruppo.
Si noti che la necessità di assegnare numeri di riga in base a un ordine non deterministico è diverso dalla necessità di assegnarli in base a un ordine casuale. Con il primo, semplicemente non ti interessa in quale ordine vengono assegnati e se esecuzioni ripetute della query continuano ad assegnare gli stessi numeri di riga alle stesse righe o meno. Con quest'ultimo, ti aspetti che le esecuzioni ripetute continuino a cambiare quali righe vengono assegnate con quali numeri di riga. Questo articolo esplora diverse tecniche per calcolare i numeri di riga con ordine non deterministico. La speranza è di trovare una tecnica che sia allo stesso tempo affidabile e ottimale.
Un ringraziamento speciale a Paul White per il consiglio sul fold costante, per la tecnica di runtime constant e per essere sempre un'ottima fonte di informazioni!
Quando l'ordine conta
Inizierò con i casi in cui l'ordinamento del numero di riga è importante.
Userò una tabella chiamata T1 nei miei esempi. Utilizzare il codice seguente per creare questa tabella e popolarla con dati di esempio:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Considera la seguente query (la chiameremo Query 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Qui vuoi che i numeri di riga siano assegnati all'interno di ogni gruppo identificato dalla colonna grp, ordinato dalla colonna datacol. Quando ho eseguito questa query sul mio sistema, ho ottenuto il seguente output:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
I numeri di riga sono assegnati qui in un ordine parzialmente deterministico e parzialmente non deterministico. Ciò che intendo con questo è che hai la certezza che all'interno della stessa partizione, una riga con un valore datacol maggiore riceverà un valore del numero di riga maggiore. Tuttavia, poiché datacol non è univoco all'interno della partizione grp, l'ordine di assegnazione dei numeri di riga tra righe con gli stessi valori grp e datacol non è deterministico. Questo è il caso delle righe con id valori 2 e 11. Entrambi hanno il valore grp A e il valore datacol 50. Quando ho eseguito questa query sul mio sistema per la prima volta, la riga con id 2 ha ottenuto la riga numero 2 e il la riga con ID 11 ha ottenuto la riga numero 3. Non importa la probabilità che ciò avvenga in pratica in SQL Server; se eseguo nuovamente la query, in teoria, la riga con id 2 potrebbe essere assegnata con la riga numero 3 e la riga con id 11 potrebbe essere assegnata con la riga numero 2.
Se è necessario assegnare numeri di riga in base a un ordine completamente deterministico, garantendo risultati ripetibili tra le esecuzioni della query purché i dati sottostanti non cambino, è necessario che la combinazione di elementi nelle clausole di partizionamento e ordinamento delle finestre sia univoca. Ciò potrebbe essere ottenuto nel nostro caso aggiungendo l'id della colonna alla clausola dell'ordine della finestra come tiebreaker. La clausola OVER sarebbe quindi:
OVER (PARTITION BY grp ORDER BY datacol, id)
In ogni caso, quando si calcolano i numeri di riga in base ad alcune specifiche di ordinamento significative come nella query 1, SQL Server deve elaborare le righe ordinate in base alla combinazione di partizionamento della finestra e elementi di ordinamento. Ciò può essere ottenuto estraendo i dati preordinati da un indice o ordinando i dati. Al momento non esiste alcun indice su T1 per supportare il calcolo ROW_NUMBER nella query 1, quindi SQL Server deve optare per l'ordinamento dei dati. Questo può essere visto nel piano per la query 1 mostrato nella figura 1.
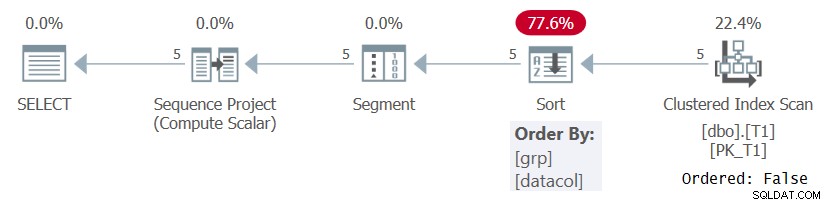 Figura 1:piano per la query 1 senza un indice di supporto
Figura 1:piano per la query 1 senza un indice di supporto
Si noti che il piano esegue la scansione dei dati dall'indice cluster con una proprietà Ordered:False. Ciò significa che la scansione non deve restituire le righe ordinate dalla chiave di indice. Questo è il caso poiché l'indice cluster viene utilizzato qui solo perché copre la query e non a causa del suo ordine delle chiavi. Il piano applica quindi un ordinamento, con conseguente costo aggiuntivo, ridimensionamento N Log N e tempo di risposta ritardato. L'operatore Segment produce un flag che indica se la riga è la prima nella partizione o meno. Infine, l'operatore Sequence Project assegna numeri di riga che iniziano con 1 in ciascuna partizione.
Se si desidera evitare la necessità di eseguire l'ordinamento, è possibile preparare un indice di copertura con un elenco di chiavi basato sugli elementi di partizionamento e ordinamento e un elenco di inclusione basato sugli elementi di copertura. Mi piace pensare a questo indice come a un indice POC (per il partizionamento , ordinare e copertura ). Ecco la definizione del POC che supporta la nostra query:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Esegui di nuovo la query 1:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Il piano per questa esecuzione è mostrato nella Figura 2.
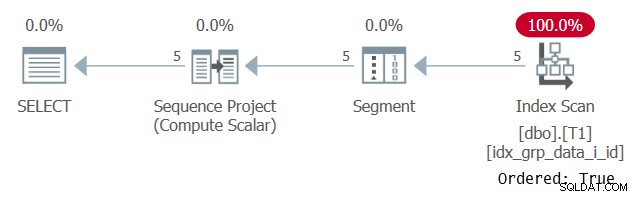 Figura 2:piano per la query 1 con un indice POC
Figura 2:piano per la query 1 con un indice POC
Osservare che questa volta il piano esegue la scansione dell'indice POC con una proprietà Ordered:True. Ciò significa che la scansione garantisce che le righe verranno restituite nell'ordine della chiave di indice. Poiché i dati vengono estratti dall'indice in base alle esigenze della funzione finestra, non è necessario un ordinamento esplicito. Il ridimensionamento di questo piano è lineare e il tempo di risposta è buono.
Quando l'ordine non conta
Le cose si complicano quando devi assegnare numeri di riga con un ordine completamente non deterministico. La cosa naturale da fare in questo caso è usare la funzione ROW_NUMBER senza specificare una clausola dell'ordine della finestra. Innanzitutto, controlliamo se lo standard SQL lo consente. Ecco la parte rilevante dello standard che definisce le regole di sintassi per le funzioni della finestra:
Regole di sintassi...
5) Sia WNS il
6) Se viene specificata
a) Se viene specificato
...
f) ROW_NUMBER() OVER WNS è equivalente alla
...
Si noti che l'elemento 6 elenca le funzioni
Quindi, proviamolo e proviamo a calcolare i numeri di riga senza l'ordinamento delle finestre in SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Questo tentativo genera il seguente errore:
Msg 4112, livello 15, stato 1, riga 53La funzione 'ROW_NUMBER' deve avere una clausola OVER con ORDER BY.
Infatti, se controlli la documentazione di SQL Server della funzione ROW_NUMBER, troverai il seguente testo:
"ordina_per_clausolaLa clausola ORDER BY determina la sequenza in cui alle righe viene assegnato il loro ROW_NUMBER univoco all'interno di una partizione specificata. È obbligatorio."
Quindi, a quanto pare, la clausola dell'ordine della finestra è obbligatoria per la funzione ROW_NUMBER in SQL Server. Questo è anche il caso di Oracle, tra l'altro.
Devo dire che non sono sicuro di aver compreso il ragionamento alla base di questo requisito. Ricorda che stai permettendo di definire i numeri di riga in base a un ordine parzialmente non deterministico, come nella query 1. Quindi perché non consentire il non determinismo fino in fondo? Forse c'è qualche motivo a cui non sto pensando. Se ti viene in mente un motivo del genere, condividi.
Ad ogni modo, si potrebbe obiettare che se non ti interessa l'ordine, dato che la clausola dell'ordine finestra è obbligatoria, puoi specificare qualsiasi ordine. Il problema con questo approccio è che se si ordina per alcune colonne dalle tabelle interrogate, ciò potrebbe comportare un'inutile penalizzazione delle prestazioni. Quando non è disponibile un indice di supporto, pagherai per l'ordinamento esplicito. Quando è presente un indice di supporto, stai limitando il motore di archiviazione a una strategia di scansione dell'ordine dell'indice (seguendo l'elenco collegato all'indice). Non gli concedi una maggiore flessibilità come accade di solito quando l'ordine non ha importanza nella scelta tra una scansione dell'ordine dell'indice e una scansione dell'ordine di allocazione (basata sulle pagine IAM).
Un'idea che vale la pena provare è specificare una costante, come 1, nella clausola dell'ordine della finestra. Se supportato, speri che l'ottimizzatore sia abbastanza intelligente da rendersi conto che tutte le righe hanno lo stesso valore, quindi non c'è una reale rilevanza per l'ordine e quindi non è necessario forzare un ordinamento o una scansione dell'ordine dell'indice. Ecco una query che tenta questo approccio:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Sfortunatamente, SQL Server non supporta questa soluzione. Genera il seguente errore:
Msg 5308, livello 16, stato 1, riga 56Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano gli indici interi come espressioni della clausola ORDER BY.
Apparentemente, SQL Server presuppone che se stai usando una costante intera nella clausola dell'ordine della finestra, rappresenti una posizione ordinale di un elemento nell'elenco SELECT, come quando specifichi un numero intero nella clausola ORDER BY della presentazione. In tal caso, un'altra opzione che vale la pena provare è specificare una costante non intera, in questo modo:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Si scopre che anche questa soluzione non è supportata. SQL Server genera il seguente errore:
Msg 5309, livello 16, stato 1, riga 65Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano le costanti come espressioni della clausola ORDER BY.
Apparentemente, la clausola dell'ordine della finestra non supporta alcun tipo di costante.
Finora abbiamo appreso quanto segue sulla rilevanza dell'ordinamento delle finestre della funzione ROW_NUMBER in SQL Server:
La conclusione è che dovresti ordinare in base a espressioni che non sono costanti. Ovviamente, puoi ordinare in base a un elenco di colonne dalle tabelle interrogate. Ma siamo alla ricerca di una soluzione efficiente in cui l'ottimizzatore possa rendersi conto che non c'è alcuna rilevanza nell'ordine.
Piegatura costante
La conclusione finora è che non è possibile utilizzare le costanti nella clausola dell'ordine della finestra di ROW_NUMBER, ma per quanto riguarda le espressioni basate su costanti, come nella seguente query:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Tuttavia, questo tentativo è vittima di un processo noto come ripiegamento costante, che normalmente ha un impatto positivo sulle prestazioni delle query. L'idea alla base di questa tecnica è di migliorare le prestazioni della query piegando alcune espressioni basate sulle costanti alle costanti dei risultati in una fase iniziale dell'elaborazione della query. Puoi trovare i dettagli su quali tipi di espressioni possono essere piegati in modo costante qui. La nostra espressione 1+0 è piegata a 1, risultando nello stesso errore che hai ottenuto specificando direttamente la costante 1:
Msg 5308, livello 16, stato 1, riga 79Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano gli indici interi come espressioni della clausola ORDER BY.
Dovresti affrontare una situazione simile quando tenti di concatenare due stringhe di caratteri letterali, in questo modo:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
Ottieni lo stesso errore che hai ottenuto specificando direttamente il letterale "Nessun ordine":
Msg 5309, livello 16, stato 1, riga 55Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano le costanti come espressioni della clausola ORDER BY.
Mondo bizzarro:errori che prevengono gli errori
La vita è piena di sorprese...
Una cosa che impedisce la piegatura costante è quando l'espressione normalmente risulterebbe in un errore. Ad esempio, l'espressione 2147483646+1 può essere piegata in modo costante poiché risulta in un valore di tipo INT valido. Di conseguenza, un tentativo di eseguire la query seguente non riesce:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, livello 16, stato 1, riga 109
Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano gli indici interi come espressioni della clausola ORDER BY.
Tuttavia, l'espressione 2147483647+1 non può essere piegata in modo costante perché tale tentativo avrebbe comportato un errore di overflow INT. L'implicazione sull'ordinazione è piuttosto interessante. Prova la seguente query (la chiameremo Query 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Stranamente, questa query viene eseguita correttamente! Quello che succede è che da un lato, SQL Server non riesce ad applicare la piegatura costante e quindi l'ordinamento si basa su un'espressione che non è una singola costante. D'altra parte, l'ottimizzatore calcola che il valore di ordinamento è lo stesso per tutte le righe, quindi ignora del tutto l'espressione di ordinamento. Ciò viene confermato durante l'esame del piano per questa query, come mostrato nella Figura 3.
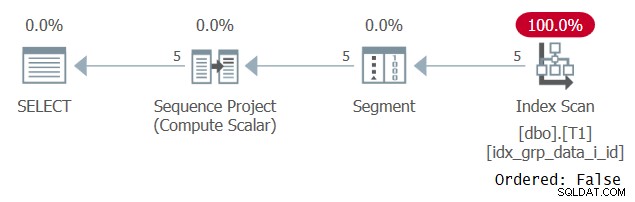 Figura 3:piano per la query 2
Figura 3:piano per la query 2
Osservare che il piano esegue la scansione di alcuni indici di copertura con una proprietà Ordered:False. Questo era esattamente il nostro obiettivo di rendimento.
In modo simile, la query seguente implica un tentativo di piegatura costante riuscito e pertanto non riesce:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, livello 16, stato 1, riga 123
Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano gli indici interi come espressioni della clausola ORDER BY.
La query seguente implica un tentativo di ripiegamento costante fallito e quindi riesce, generando il piano mostrato in precedenza nella Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
La query seguente implica un tentativo di piegatura costante riuscito (il valore letterale VARCHAR '1' viene convertito in modo implicito in INT 1 e quindi 1 + 1 viene piegato a 2) e pertanto non riesce:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, livello 16, stato 1, riga 134
Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano gli indici interi come espressioni della clausola ORDER BY.
La query seguente implica un tentativo di piegatura costante fallito (non è possibile convertire 'A' in INT) e quindi riesce, generando il piano mostrato in precedenza nella Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
Ad essere onesti, anche se questa tecnica bizzarra raggiunge il nostro obiettivo di prestazione originale, non posso dire di considerarla sicura e quindi non mi sento così a mio agio a fare affidamento su di essa.
Costanti di runtime basate su funzioni
Continuando la ricerca di una buona soluzione per calcolare i numeri di riga con ordine non deterministico, ci sono alcune tecniche che sembrano più sicure dell'ultima soluzione bizzarra:usare costanti di runtime basate su funzioni, usare una sottoquery basata su una costante, usare una colonna con alias basata su una costante e usando una variabile.
Come spiego in T-SQL bug, insidie e best practice - determinismo, la maggior parte delle funzioni in T-SQL vengono valutate solo una volta per riferimento nella query, non una volta per riga. Questo è il caso anche con la maggior parte delle funzioni non deterministiche come GETDATE e RAND. Ci sono pochissime eccezioni a questa regola, come le funzioni NEWID e CRYPT_GEN_RANDOM, che vengono valutate una volta per riga. La maggior parte delle funzioni, come GETDATE, @@SPID e molte altre, vengono valutate una volta all'inizio della query e i loro valori vengono quindi considerati costanti di runtime. Un riferimento a tali funzioni non viene piegato in modo costante. Queste caratteristiche rendono una costante di runtime basata su una funzione una buona scelta come elemento di ordinamento delle finestre e, in effetti, sembra che T-SQL la supporti. Allo stesso tempo, l'ottimizzatore si rende conto che in pratica non c'è pertinenza nell'ordine, evitando inutili penalizzazioni delle prestazioni.
Ecco un esempio usando la funzione GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Questa query ottiene lo stesso piano mostrato in precedenza nella Figura 3.
Ecco un altro esempio che utilizza la funzione @@SPID (restituendo l'ID della sessione corrente):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
E la funzione PI? Prova la seguente query:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Questo non riesce con il seguente errore:
Msg 5309, livello 16, stato 1, riga 153Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano le costanti come espressioni della clausola ORDER BY.
Funzioni come GETDATE e @@SPID vengono rivalutate una volta per esecuzione del piano, quindi non possono essere costantemente piegate. PI rappresenta sempre la stessa costante e quindi viene piegata in modo costante.
Come accennato in precedenza, ci sono pochissime funzioni che vengono valutate una volta per riga, come NEWID e CRYPT_GEN_RANDOM. Questo li rende una cattiva scelta come elemento di ordinamento delle finestre se hai bisogno di un ordine non deterministico, da non confondere con l'ordine casuale. Perché pagare una sanzione di smistamento non necessaria?
Ecco un esempio di utilizzo della funzione NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Il piano per questa query è mostrato nella Figura 4, a conferma che SQL Server ha aggiunto l'ordinamento esplicito in base al risultato della funzione.
 Figura 4:piano per la query 3
Figura 4:piano per la query 3
Se vuoi che i numeri di riga vengano assegnati in ordine casuale, questa è la tecnica che vuoi usare. Devi solo essere consapevole del fatto che comporta il costo di ordinamento.
Utilizzo di una sottoquery
È inoltre possibile utilizzare una sottoquery basata su una costante come espressione di ordinamento delle finestre (ad es. ORDER BY (SELECT 'No Order')). Anche con questa soluzione, l'ottimizzatore di SQL Server riconosce che non c'è alcuna rilevanza per l'ordine e quindi non impone un ordinamento non necessario né limita le scelte del motore di archiviazione a quelle che devono garantire l'ordine. Prova a eseguire la seguente query come esempio:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
Ottieni lo stesso piano mostrato in precedenza nella Figura 3.
Uno dei grandi vantaggi di questa tecnica è che puoi aggiungere il tuo tocco personale. Forse ti piacciono molto i NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Forse ti piace molto un certo numero:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Forse vuoi mandare un messaggio a qualcuno:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Hai capito.
Fattibile, ma imbarazzante
Ci sono un paio di tecniche che funzionano, ma sono un po' imbarazzanti. Uno consiste nel definire un alias di colonna per un'espressione basata su una costante, quindi utilizzare quell'alias di colonna come elemento di ordinamento della finestra. Puoi farlo usando un'espressione di tabella o con l'operatore CROSS APPLY e un costruttore di valori di tabella. Ecco un esempio per quest'ultimo:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); Ottieni lo stesso piano mostrato in precedenza nella Figura 3.
Un'altra opzione consiste nell'usare una variabile come elemento di ordinamento delle finestre:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Questa query ottiene anche il piano mostrato in precedenza nella Figura 3.
Cosa succede se utilizzo la mia UDF?
Potresti pensare che usare la tua UDF che restituisce una costante potrebbe essere una buona scelta come elemento di ordinamento della finestra quando desideri un ordine non deterministico, ma non lo è. Considera la seguente definizione UDF come esempio:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Prova a utilizzare l'UDF come clausola di ordinamento delle finestre, in questo modo (la chiameremo Query 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Prima di SQL Server 2019 (o livello di compatibilità parallela <150), le funzioni definite dall'utente vengono valutate per riga. Anche se restituiscono una costante, non vengono allineati. Di conseguenza, da un lato è possibile utilizzare tale UDF come elemento di ordinamento delle finestre, ma dall'altro ciò si traduce in una penalità di ordinamento. Ciò è confermato esaminando il piano per questa query, come mostrato nella Figura 5.
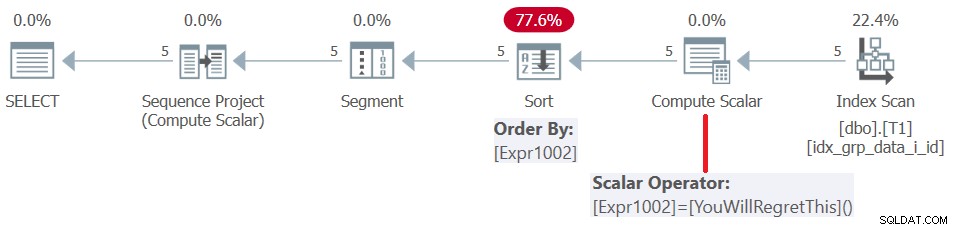 Figura 5:piano per la query 4
Figura 5:piano per la query 4
A partire da SQL Server 2019, con livello di compatibilità>=150, tali funzioni definite dall'utente vengono integrate, il che è principalmente un'ottima cosa, ma nel nostro caso si verifica un errore:
Msg 5309, livello 16, stato 1, riga 217Le funzioni Window, gli aggregati e le funzioni NEXT VALUE FOR non supportano le costanti come espressioni della clausola ORDER BY.
Pertanto, l'utilizzo di una UDF basata su una costante come elemento di ordinamento della finestra forza un ordinamento o un errore a seconda della versione di SQL Server in uso e del livello di compatibilità del database. In breve, non farlo.
Numeri di riga partizionati con ordine non deterministico
Un caso d'uso comune per i numeri di riga partizionati in base all'ordine non deterministico restituisce qualsiasi riga per gruppo. Dato che per definizione esiste un elemento di partizionamento in questo scenario, si potrebbe pensare che una tecnica sicura in tal caso sarebbe quella di utilizzare l'elemento di partizionamento della finestra anche come elemento di ordinamento delle finestre. Come primo passo, calcoli i numeri di riga in questo modo:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Il piano per questa query è mostrato nella Figura 6.
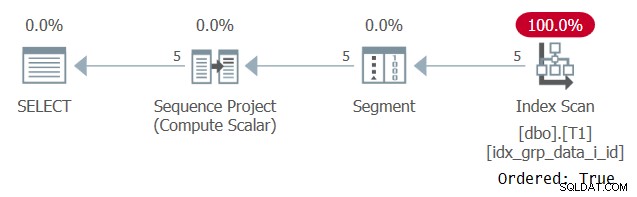 Figura 6:piano per la query 5
Figura 6:piano per la query 5
Il motivo per cui il nostro indice di supporto viene scansionato con una proprietà Ordered:True è perché SQL Server deve elaborare le righe di ogni partizione come una singola unità. Questo è il caso prima del filtraggio. Se filtri solo una riga per partizione, hai come opzioni sia gli algoritmi basati sugli ordini che quelli basati sugli hash.
Il secondo passaggio consiste nel posizionare la query con il calcolo del numero di riga in un'espressione di tabella e nella query esterna filtrare la riga con il numero di riga 1 in ciascuna partizione, in questo modo:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Teoricamente questa tecnica dovrebbe essere sicura, ma Paul White ha trovato un bug che mostra che usando questo metodo puoi ottenere attributi da diverse righe di origine nella riga dei risultati restituita per partizione. L'uso di una costante di runtime basata su una funzione o di una sottoquery basata su una costante come elemento di ordinamento sembra essere sicuro anche in questo scenario, quindi assicurati di utilizzare invece una soluzione come la seguente:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Nessuno passerà da questa parte senza il mio permesso
Cercare di calcolare i numeri di riga in base a un ordine non deterministico è un'esigenza comune. Sarebbe stato bello se T-SQL avesse semplicemente reso facoltativa la clausola dell'ordine della finestra per la funzione ROW_NUMBER, ma non è così. In caso contrario, sarebbe stato bello se almeno consentisse l'utilizzo di una costante come elemento di ordinamento, ma nemmeno questa è un'opzione supportata. Ma se chiedi gentilmente, sotto forma di una sottoquery basata su una costante o una costante di runtime basata su una funzione, SQL Server lo consentirà. Queste sono le due opzioni con cui sono più a mio agio. Non mi sento davvero a mio agio con le strane espressioni errate che sembrano funzionare, quindi non posso raccomandare questa opzione.



