Sebbene siano dotate di molte restrizioni e alcuni importanti avvertimenti sull'implementazione, le viste indicizzate sono ancora una funzionalità di SQL Server molto potente se utilizzate correttamente nelle giuste circostanze. Un uso comune è fornire una vista preaggregata dei dati sottostanti, offrendo agli utenti la possibilità di eseguire query direttamente sui risultati senza sostenere i costi di elaborazione dei join, dei filtri e degli aggregati sottostanti ogni volta che viene eseguita una query.
Sebbene le nuove funzionalità dell'edizione Enterprise come l'archiviazione a colonne e l'elaborazione in modalità batch abbiano trasformato le caratteristiche delle prestazioni di molte query di grandi dimensioni di questo tipo, non esiste ancora un modo più rapido per ottenere un risultato che evitare completamente l'elaborazione sottostante, indipendentemente dall'efficienza dell'elaborazione potrebbe essere diventato.
Prima che le viste indicizzate (e le loro cugine più limitate, le colonne calcolate) venissero aggiunte al prodotto, i professionisti del database a volte scrivevano un codice multi-trigger complesso per presentare i risultati di una query importante in una tabella reale. Questo tipo di disposizione è notoriamente difficile da ottenere in tutte le circostanze, in particolare quando le modifiche simultanee ai dati sottostanti sono frequenti.
La funzionalità delle viste indicizzate rende tutto questo molto più semplice, dove viene applicata in modo sensato e corretto. Il motore di database si occupa di tutto il necessario per garantire che i dati letti da una vista indicizzata corrispondano in ogni momento alla query sottostante e ai dati della tabella.
Manutenzione incrementale
SQL Server mantiene sincronizzati i dati di visualizzazione indicizzati con la query sottostante aggiornando automaticamente gli indici di visualizzazione in modo appropriato ogni volta che i dati cambiano nelle tabelle di base. Il costo di questa attività di manutenzione è a carico del processo di modifica dei dati di base. Le operazioni aggiuntive necessarie per mantenere gli indici di visualizzazione vengono aggiunte automaticamente al piano di esecuzione per l'operazione di inserimento, aggiornamento, eliminazione o unione originale. In background, SQL Server si occupa anche di problemi più sottili relativi all'isolamento delle transazioni, ad esempio garantendo la corretta gestione delle transazioni eseguite con snapshot o con l'isolamento dello snapshot con commit di lettura.
Costruire le operazioni extra del piano di esecuzione necessarie per mantenere correttamente gli indici di visualizzazione non è una questione banale, come saprà chiunque abbia tentato un'implementazione "tabella di riepilogo gestita dal codice trigger". La complessità dell'attività è uno dei motivi per cui le viste indicizzate hanno così tante restrizioni. Limitare la superficie supportata a giunti interni, proiezioni, selezioni (filtri) e aggregati SUM e COUNT_BIG riduce considerevolmente la complessità dell'implementazione.
Le viste indicizzate vengono mantenute in modo incrementale . Ciò significa che il Query Processor determina l'effetto netto delle modifiche della tabella di base sulla vista e applica solo le modifiche necessarie per aggiornare la vista. In casi semplici, può calcolare i delta necessari solo dalle modifiche della tabella di base e dai dati attualmente archiviati nella vista. Laddove la definizione della vista contiene join, anche la parte di manutenzione della vista indicizzata del piano di esecuzione dovrà accedere alle tabelle unite, ma in genere ciò può essere eseguito in modo efficiente, dati gli indici delle tabelle di base appropriati.
Per semplificare ulteriormente l'implementazione, SQL Server utilizza sempre la stessa forma del piano di base (come punto di partenza) per implementare le operazioni di manutenzione della vista indicizzata. Le normali funzionalità fornite da Query Optimizer vengono utilizzate per semplificare e ottimizzare la forma di manutenzione standard in modo appropriato. Passeremo ora a un esempio per aiutare a mettere insieme questi concetti.
Esempio 1 – Inserimento riga singola
Supponiamo di avere la seguente tabella semplice e vista indicizzata:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Dopo che lo script è stato eseguito, i dati nella tabella di esempio avranno il seguente aspetto:

E la vista indicizzata contiene:

L'esempio più semplice di un piano di manutenzione della vista indicizzata per questa configurazione si verifica quando aggiungiamo una singola riga alla tabella di base:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Il piano di esecuzione di questo inserto è mostrato di seguito:
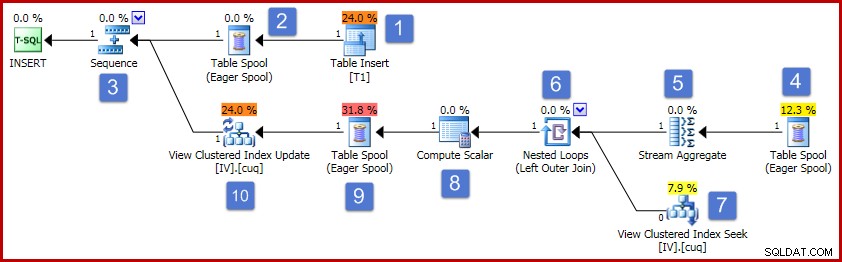
Seguendo i numeri del diagramma, il funzionamento di questo piano di esecuzione procede come segue:
- L'operatore Table Insert aggiunge la nuova riga alla tabella di base. Questo è l'unico operatore di piano associato all'inserto della tabella di base; tutti gli altri operatori si occupano del mantenimento della vista indicizzata.
- The Eager Table Spool salva i dati delle righe inserite nella memoria temporanea.
- L'operatore della sequenza assicura che il ramo superiore del piano venga completato prima che venga attivato il ramo successivo della sequenza. In questo caso particolare (inserendo una sola riga), sarebbe valido rimuovere la Sequence (e gli spool alle posizioni 2 e 4), collegando direttamente l'ingresso Stream Aggregate all'uscita del Table Insert. Questa possibile ottimizzazione non è implementata, quindi la Sequenza e gli Spool rimangono.
- Questo Eager Table Spool è associato allo spool in posizione 2 (ha una proprietà Primary Node ID che fornisce questo collegamento in modo esplicito). Lo spool riproduce le righe (una riga nel caso di specie) dalla stessa memoria temporanea scritta dallo spool primario. Come accennato in precedenza, gli spool e le posizioni 2 e 4 non sono necessari e sono presenti semplicemente perché esistono nel modello generico per la manutenzione della vista indicizzata.
- Lo Stream Aggregate calcola la somma dei dati della colonna Valore nel set inserito e conta il numero di righe presenti per gruppo di chiavi di visualizzazione. L'output è costituito dai dati incrementali necessari per mantenere la vista sincronizzata con i dati di base. Nota, Stream Aggregate non ha un elemento Raggruppa per perché Query Optimizer sa che viene elaborato solo un singolo valore. Tuttavia, l'ottimizzatore non applica una logica simile per sostituire gli aggregati con le proiezioni (la somma di un singolo valore è solo il valore stesso e il conteggio sarà sempre uno per l'inserimento di una singola riga). Calcolare la somma e il conteggio aggregati per una singola riga di dati non è un'operazione costosa, quindi questa mancata ottimizzazione non è molto di cui preoccuparsi.
- Il join mette in relazione ogni modifica incrementale calcolata con una chiave esistente nella vista indicizzata. Il join è un outer join perché i dati appena inseriti potrebbero non corrispondere ai dati esistenti nella vista.
- Questo operatore individua la riga da modificare nella vista.
- Il calcolo scalare ha due importanti responsabilità. Innanzitutto, determina se ogni modifica incrementale influirà su una riga esistente nella vista o se dovrà essere creata una nuova riga. Lo fa controllando se il join esterno ha prodotto un valore nullo dal lato della vista del join. Il nostro inserto di esempio è per il gruppo 3, che attualmente non esiste nella vista, quindi verrà creata una nuova riga. La seconda funzione di Compute Scalar consiste nel calcolare nuovi valori per le colonne della vista. Se una nuova riga deve essere aggiunta alla vista, questo è semplicemente il risultato della somma incrementale dello Stream Aggregate. Se una riga esistente nella vista deve essere aggiornata, il nuovo valore è il valore esistente nella riga della vista più la somma incrementale dallo Stream Aggregate.
- Questa bobina da tavolo desiderosa è per la protezione di Halloween. È necessario per correttezza quando un'operazione di inserimento interessa una tabella a cui si fa riferimento anche sul lato di accesso ai dati della query. Non è tecnicamente necessario se l'operazione di manutenzione su riga singola comporta l'aggiornamento di una riga di visualizzazione esistente, ma rimane comunque nel piano.
- L'operatore finale nel piano è etichettato come operatore di aggiornamento, ma eseguirà un inserimento o un aggiornamento per ogni riga che riceve a seconda del valore della colonna "codice azione" aggiunta da Compute Scalar al nodo 8 Più in generale, questo operatore di aggiornamento è in grado di inserire, aggiornare ed eliminare.
C'è un bel po' di dettagli lì, quindi per riassumere:
- I dati aggregati dei gruppi cambiano in base alla chiave cluster univoca della vista. Calcola l'effetto netto delle modifiche della tabella di base su ciascuna colonna per chiave.
- Il join esterno collega le modifiche incrementali per chiave alle righe esistenti nella vista.
- Il calcolo scalare calcola se è necessario aggiungere una nuova riga alla vista o aggiornare una riga esistente. Calcola i valori finali della colonna per l'operazione di inserimento o aggiornamento della vista.
- L'operatore di aggiornamento della vista inserisce una nuova riga o ne aggiorna una esistente come indicato dal codice azione.
Esempio 2:inserimento a più righe
Che ci crediate o no, il piano di esecuzione dell'inserimento della tabella di base a riga singola discusso sopra è stato soggetto a una serie di semplificazioni. Sebbene alcune possibili ulteriori ottimizzazioni siano state perse (come notato), Query Optimizer è comunque riuscito a rimuovere alcune operazioni dal modello di manutenzione della vista indicizzata generale e ridurre la complessità di altre.
Molte di queste ottimizzazioni sono state consentite perché stavamo inserendo solo una singola riga, ma altre sono state abilitate perché l'ottimizzatore è stato in grado di vedere i valori letterali aggiunti alla tabella di base. Ad esempio, l'ottimizzatore potrebbe vedere che il valore del gruppo inserito passerebbe il predicato nella clausola WHERE della vista.
Se ora inseriamo due righe, con i valori "nascosti" nelle variabili locali, otteniamo un piano leggermente più complesso:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
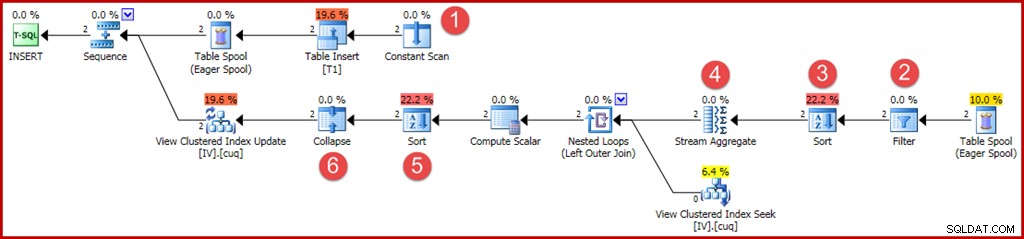
Gli operatori nuovi o modificati vengono annotati come prima:
- The Constant Scan fornisce i valori da inserire. In precedenza, un'ottimizzazione per gli inserti a riga singola consentiva di omettere questo operatore.
- Ora è necessario un operatore Filter esplicito per verificare che i gruppi inseriti nella tabella di base corrispondano alla clausola WHERE nella vista. In effetti, entrambe le nuove righe supereranno il test, ma l'ottimizzatore non può vedere i valori nelle variabili per saperlo in anticipo. Inoltre, non sarebbe sicuro memorizzare nella cache un piano che ha ignorato questo filtro perché un futuro riutilizzo del piano potrebbe avere valori diversi nelle variabili.
- Ora è necessario un ordinamento per garantire che le righe arrivino allo Stream Aggregate in ordine di gruppo. L'ordinamento è stato precedentemente rimosso perché è inutile ordinare una riga.
- Lo Stream Aggregate ora ha una proprietà "raggruppa per", che corrisponde alla chiave cluster univoca della vista.
- Questo ordinamento è necessario per presentare le righe in ordine di codice di azione e chiave di visualizzazione, necessario per il corretto funzionamento dell'operatore Comprimi. Sort è un operatore di blocco completo, quindi non c'è più bisogno di una bobina da tavolo desiderosa per la protezione di Halloween.
- Il nuovo operatore Comprimi combina un inserimento e un'eliminazione adiacenti sullo stesso valore di chiave in un'unica operazione di aggiornamento. Questo operatore non è effettivamente richiesto in questo caso, perché non è possibile generare codici di azione di cancellazione (solo inserimenti e aggiornamenti). Questa sembra essere una svista, o forse qualcosa lasciato per motivi di sicurezza. Le parti generate automaticamente di un piano di query di aggiornamento possono diventare estremamente complesse, quindi è difficile saperlo con certezza.
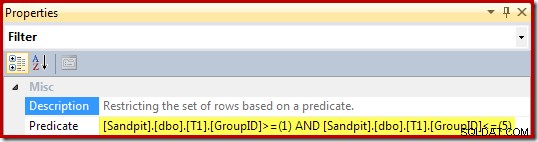
Le proprietà del filtro (derivate dalla clausola WHERE della vista) sono:
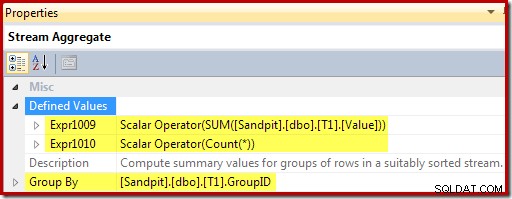
Stream Aggregate raggruppa in base alla chiave di visualizzazione e calcola la somma e il conteggio aggregati per gruppo:
Il calcolo scalare identifica l'azione da intraprendere per riga (in questo caso, inserisci o aggiorna) e calcola il valore da inserire o aggiornare nella vista:
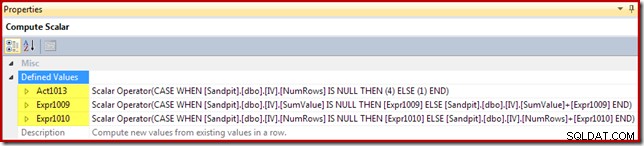
Al codice dell'azione viene assegnata un'etichetta di espressione di [Act1xxx]. I valori validi sono 1 per un aggiornamento, 3 per un'eliminazione e 4 per un inserimento. Questa espressione di azione risulta in un inserimento (codice 4) se non è stata trovata alcuna riga corrispondente nella vista (ovvero il join esterno ha restituito un valore nullo per la colonna NumRows). Se è stata trovata una riga corrispondente, il codice azione è 1 (aggiornamento).
Si noti che NumRows è il nome assegnato alla colonna COUNT_BIG(*) richiesta nella vista. In un piano che potrebbe comportare eliminazioni dalla vista, Compute Scalar rileva quando questo valore diventa zero (nessuna riga per il gruppo corrente) e genera un codice di azione di eliminazione (3).
Le restanti espressioni mantengono la somma e il conteggio aggregati nella vista. Si noti tuttavia che le etichette delle espressioni [Espr1009] e [Espr1010] non sono nuove; si riferiscono alle etichette create dallo Stream Aggregate. La logica è semplice:se non è stata trovata una riga corrispondente, il nuovo valore da inserire è solo il valore calcolato sull'aggregato. Se è stata trovata una riga corrispondente nella vista, il valore aggiornato è il valore corrente nella riga più l'incremento calcolato dall'aggregato.
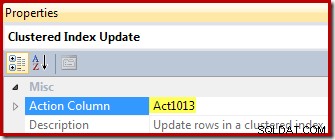
Infine, l'operatore di aggiornamento della vista (mostrato come aggiornamento dell'indice cluster in SSMS) mostra il riferimento alla colonna dell'azione ([Act1013] definita da Compute Scalar):
Esempio 3 – Aggiornamento su più righe
Finora abbiamo esaminato solo gli inserti nella tabella di base. I piani di esecuzione per una cancellazione sono molto simili, con solo alcune piccole differenze nei calcoli dettagliati. Questo prossimo esempio passa quindi a esaminare il piano di manutenzione per un aggiornamento della tabella di base:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Come in precedenza, questa query utilizza le variabili per nascondere i valori letterali dall'ottimizzatore, impedendo l'applicazione di alcune semplificazioni. Presta inoltre attenzione ad aggiornare due gruppi separati, impedendo le ottimizzazioni che possono essere applicate quando l'ottimizzatore sa che solo un singolo gruppo (una singola riga della vista indicizzata) sarà interessato. Il piano di esecuzione annotato per la query di aggiornamento è il seguente:
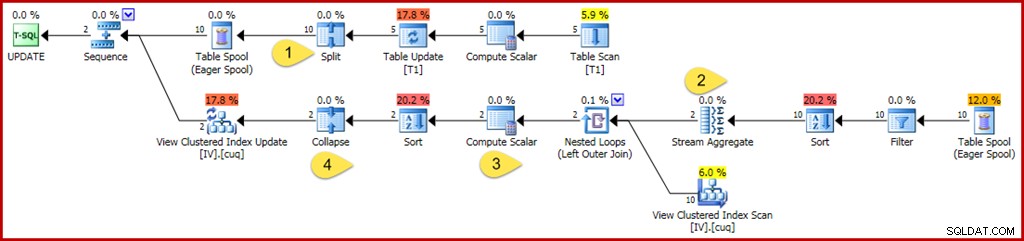
Le modifiche e i punti di interesse sono:
- Il nuovo operatore Dividi trasforma ogni aggiornamento di riga della tabella di base in un'operazione di eliminazione e inserimento separata. Ogni riga di aggiornamento viene suddivisa in due righe separate, raddoppiando il numero di righe dopo questo punto nel piano. La suddivisione fa parte del modello split-sort-comprimi necessario per la protezione da errori temporanei di violazione della chiave univoca errati.
- Lo Stream Aggregate viene modificato per tenere conto delle righe in entrata che possono specificare un'eliminazione o un inserimento (a causa della divisione e determinata da una colonna del codice di azione nella riga). Una riga di inserimento fornisce il valore originale in aggregati di somma; il segno è invertito per le righe di azione di eliminazione. Allo stesso modo, l'aggregato del conteggio delle righe qui conta le righe di inserimento come +1 ed elimina le righe come –1.
- Anche la logica di calcolo scalare viene modificata per riflettere che l'effetto netto delle modifiche per gruppo potrebbe richiedere un'eventuale azione di inserimento, aggiornamento o eliminazione rispetto alla vista materializzata. In realtà non è possibile che questa particolare query di aggiornamento comporti l'inserimento o l'eliminazione di una riga rispetto a questa visualizzazione, ma la logica richiesta per dedurre che va oltre le attuali capacità di ragionamento dell'ottimizzatore. Una query di aggiornamento o una definizione di vista leggermente diversa potrebbe effettivamente comportare una combinazione di azioni di inserimento, eliminazione e aggiornamento della vista.
- L'operatore Collapse è evidenziato esclusivamente per il suo ruolo nel modello split-sort-collapse menzionato sopra. Si noti che comprime solo eliminazioni e inserimenti sulla stessa chiave; eliminazioni e inserimenti senza pari dopo il Collasso sono perfettamente possibili (e abbastanza usuali).
Come in precedenza, le proprietà dell'operatore chiave da esaminare per comprendere il lavoro di manutenzione della vista indicizzata sono il filtro, l'aggregazione di flusso, l'unione esterna e il calcolo scalare.
Esempio 4:aggiornamento su più righe con join
Per completare la panoramica dei piani di esecuzione della manutenzione della vista indicizzata, avremo bisogno di una nuova vista di esempio che unisca più tabelle insieme e includa una proiezione nell'elenco di selezione:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Per garantire la correttezza, uno dei requisiti della vista indicizzata è che un aggregato sum non può operare su un'espressione che potrebbe restituire null. La definizione della vista sopra utilizza ISNULL per soddisfare tale requisito. Di seguito viene mostrata una query di aggiornamento di esempio che produce un componente del piano di manutenzione dell'indice piuttosto completo, insieme al piano di esecuzione che produce:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
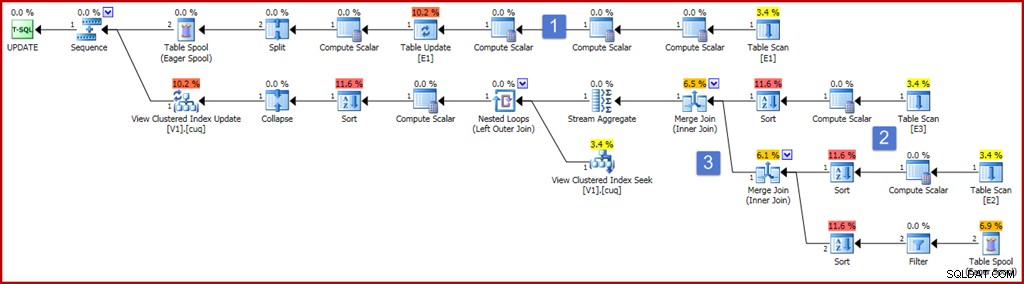
Il piano ora sembra piuttosto ampio e complicato, ma la maggior parte degli elementi è esattamente come abbiamo già visto. Le differenze principali sono:
- Il ramo più alto del piano include una serie di operatori Compute Scalar aggiuntivi. Questi potrebbero essere disposti in modo più compatto, ma essenzialmente sono presenti per acquisire i valori di pre-aggiornamento delle colonne non di raggruppamento. Il calcolo scalare a sinistra dell'aggiornamento tabella acquisisce il valore post-aggiornamento della colonna "a", con la proiezione ISNULL applicata.
- I nuovi scalari di calcolo in quest'area del piano calcolano il valore prodotto dall'espressione ISNULL su ciascuna tabella di origine. In generale, le proiezioni sulle tabelle unite nella vista saranno rappresentate da Compute Scalars qui. Gli ordinamenti in quest'area del piano sono presenti esclusivamente perché l'ottimizzatore ha scelto una strategia di unione di unione per motivi di costo (ricorda, l'unione richiede l'input ordinato della chiave di unione).
- I due operatori di join sono nuovi e implementano semplicemente i join nella definizione della vista. Questi join vengono sempre visualizzati prima di Stream Aggregate che calcola l'effetto incrementale delle modifiche sulla vista. Si noti che una modifica a una tabella di base può comportare la mancata unione di una riga che prima soddisfaceva i criteri di unione e viceversa. Tutte queste potenziali complessità vengono gestite correttamente (date le restrizioni di visualizzazione indicizzata) da Stream Aggregate producendo un riepilogo delle modifiche per chiave di visualizzazione dopo che i join sono stati eseguiti.
Pensieri finali
Quest'ultimo piano rappresenta praticamente il modello completo per il mantenimento di una vista indicizzata, sebbene l'aggiunta di indici non cluster alla vista aggiungerebbe operatori aggiuntivi prelevati anche dall'output dell'operatore di aggiornamento della vista. A parte una divisione aggiuntiva (e una combinazione di ordinamento e compressione se l'indice non cluster della vista è univoco), non c'è nulla di molto speciale in questa possibilità. L'aggiunta di una clausola di output alla query della tabella di base può anche produrre alcuni interessanti operatori aggiuntivi, ma, ancora una volta, questi non sono particolari per la manutenzione della vista indicizzata di per sé.
Per riassumere la strategia complessiva completa:
- Le modifiche alla tabella di base vengono applicate normalmente; i valori di pre-aggiornamento possono essere acquisiti.
- Un operatore di divisione può essere utilizzato per trasformare gli aggiornamenti in coppie di eliminazione/inserimento.
- Uno spool ansioso salva le informazioni sulla modifica della tabella di base nella memoria temporanea.
- Si accede a tutte le tabelle nella vista, ad eccezione della tabella di base aggiornata (che viene letta dallo spool).
- Le proiezioni nella vista sono rappresentate da Compute Scalars.
- I filtri nella vista vengono applicati. I filtri possono essere inseriti nelle scansioni o ricercati come residui.
- I join specificati nella vista vengono eseguiti.
- Un aggregato calcola le modifiche incrementali nette raggruppate per chiave di visualizzazione cluster.
- Il set di modifiche incrementali è unito esternamente alla vista.
- Un calcolo scalare calcola un codice azione (inserisci/aggiorna/elimina rispetto alla vista) per ogni modifica e calcola i valori effettivi da inserire o aggiornare. La logica di calcolo si basa sull'output dell'aggregato e sul risultato dell'outer join alla vista.
- Le modifiche vengono ordinate in base alla chiave di visualizzazione e all'ordine del codice di azione e ridotte agli aggiornamenti a seconda dei casi.
- Infine, le modifiche incrementali vengono applicate alla vista stessa.
Come abbiamo visto, il normale insieme di strumenti a disposizione di Query Optimizer viene ancora applicato alle parti del piano generate automaticamente, il che significa che uno o più dei passaggi precedenti possono essere semplificati, trasformati o rimossi del tutto. Tuttavia, la forma e il funzionamento di base del piano rimangono intatti.
Se hai seguito gli esempi di codice, puoi utilizzare il seguente script per ripulire:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;