Puppet è un software open source per la gestione e la distribuzione della configurazione. Fondato nel 2005, è multipiattaforma e dispone persino di un proprio linguaggio dichiarativo per la configurazione.

Le attività relative all'amministrazione e alla manutenzione di PostgreSQL (o altro software in realtà) consiste in processi quotidiani e ripetitivi che richiedono un monitoraggio. Questo vale anche per quelle attività gestite da script o comandi tramite uno strumento di pianificazione. La complessità di queste attività aumenta in modo esponenziale se eseguite su un'infrastruttura di grandi dimensioni, tuttavia, l'utilizzo di Puppet per questo tipo di attività può spesso risolvere questo tipo di problemi su larga scala poiché Puppet centralizza e automatizza le prestazioni di queste operazioni in modo molto agile.
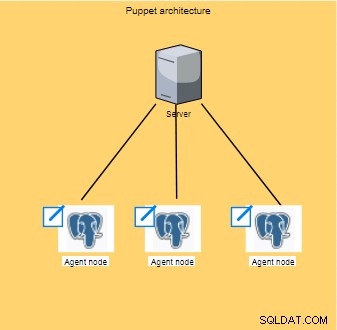
Il burattino funziona all'interno dell'architettura a livello client/server in cui viene eseguita la configurazione; queste operazioni vengono poi diffuse ed eseguite su tutti i client (detti anche nodi).
In genere eseguendo ogni 30 minuti, il nodo degli agent raccoglierà un insieme di informazioni (tipo di processore, architettura, indirizzo IP, ecc.), chiamate anche fact, quindi invia le informazioni al master che attende una risposta per vedere se ci sono nuove configurazioni da applicare.
Questi fatti consentiranno al master di personalizzare la stessa configurazione per ogni nodo.
In un modo molto semplicistico, Puppet è uno degli strumenti DevOps più importanti disponibile oggi. In questo blog daremo un'occhiata a quanto segue...
- Il caso d'uso per Puppet e PostgreSQL
- Installazione di Puppet
- Configurazione e programmazione del pupazzo
- Configurazione di Puppet per PostgreSQL
L'installazione e la configurazione di Puppet (versione 5.3.10) descritte di seguito sono state eseguite in un insieme di host utilizzando CentOS 7.0 come sistema operativo.
Il caso d'uso per Puppet e PostgreSQL
Supponiamo che ci sia un problema nel tuo firewall sulle macchine che ospitano tutti i tuoi server PostgreSQL, sarebbe quindi necessario negare tutte le connessioni in uscita a PostgreSQL e farlo il prima possibile.

Il burattino è lo strumento perfetto per questa situazione, soprattutto perché velocità ed efficienza sono essenziale. Parleremo di questo esempio presentato nella sezione “Configurazione di Puppet per PostgreSQL” gestendo il parametro listen_addresses.
Installazione del pupazzo
Esistono una serie di passaggi comuni da eseguire su host master o agent:
Fase uno
Aggiornamento del file /etc/hosts con i nomi host e il loro indirizzo IP
192.168.1.85 agent agent.severalnines.com
192.168.1.87 master master.severalnines.com puppetFase due
Aggiunta dei repository Puppet sul sistema
$ sudo rpm –Uvh https://yum.puppetlabs.com/puppet5/el/7/x86_64/puppet5-release-5.0.0-1-el7.noarch.rpmPer altri sistemi operativi o versioni di CentOS, il repository più appropriato può essere trovato in Puppet, Inc. Yum Repositories.
Fase tre
Configurazione del server NTP (Network Time Protocol)
$ sudo yum -y install chronyFase quattro
Il chrony viene utilizzato per sincronizzare l'orologio di sistema da diversi server NTP e quindi mantiene l'ora sincronizzata tra master e agent server.
Una volta installato chrony, deve essere abilitato e riavviato:
$ sudo systemctl enable chronyd.service
$ sudo systemctl restart chronyd.servicePasso Cinque
Disabilita il parametro SELinux
Sul file /etc/sysconfig/selinux il parametro SELINUX (Security-Enhanced Linux) deve essere disabilitato per non limitare l'accesso su entrambi gli host.
SELINUX=disabledSesto passo
Prima dell'installazione di Puppet (master o agent) il firewall in questi host deve essere definito di conseguenza:
$ sudo firewall-cmd -–add-service=ntp -–permanent
$ sudo firewall-cmd –-reload Installazione del burattinaio master
Una volta che il repository del pacchetto puppet5-release-5.0.0-1-el7.noarch.rpm è stato aggiunto al sistema, l'installazione del puppetserver può essere eseguita:
$ sudo yum install -y puppetserverIl parametro di allocazione della memoria massima è un'impostazione importante per aggiornare il file /etc/sysconfig/puppetserver a 2 GB (o a 1 GB se il servizio non si avvia):
JAVA_ARGS="-Xms2g –Xmx2g "Nel file di configurazione /etc/puppetlabs/puppet/puppet.conf è necessario aggiungere la seguente parametrizzazione:
[master]
dns_alt_names=master.severalnines.com,puppet
[main]
certname = master.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hIl servizio puppetserver utilizza la porta 8140 per ascoltare le richieste del nodo, quindi è necessario assicurarsi che questa porta sia abilitata:
$ sudo firewall-cmd --add-port=8140/tcp --permanent
$ sudo firewall-cmd --reloadUna volta effettuate tutte le impostazioni in burattinaio, è ora di avviare questo servizio:
$ sudo systemctl start puppetserver
$ sudo systemctl enable puppetserver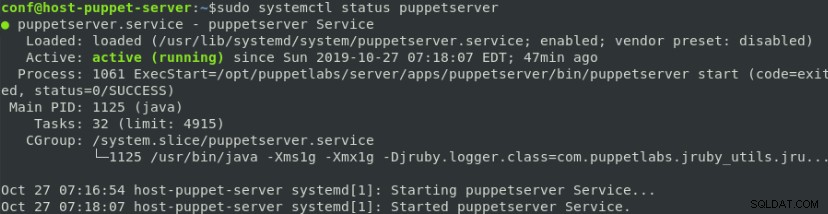
Installazione dell'agente pupazzo
Anche l'agente Puppet nel repository del pacchetto puppet5-release-5.0.0-1-el7.noarch.rpm è stato aggiunto al sistema, l'installazione dell'agente puppet può essere eseguita immediatamente:
$ sudo yum install -y puppet-agentIl file di configurazione dell'agente puppet /etc/puppetlabs/puppet/puppet.conf deve anche essere aggiornato aggiungendo il seguente parametro:
[main]
certname = agent.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hIl passaggio successivo consiste nel registrare il nodo agente sull'host master eseguendo il comando seguente:
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable=true
service { ‘puppet’:
ensure => ‘running’,
enable => ‘true’
}In questo momento, sull'host master, c'è una richiesta in sospeso da parte dell'agente fantoccio di firmare un certificato:

Deve essere firmato eseguendo uno dei seguenti comandi:
$ sudo /opt/puppetlabs/bin/puppet cert sign agent.severalnines.como
$ sudo /opt/puppetlabs/bin/puppet cert sign --allInfine (e una volta che il burattinaio ha firmato il certificato) è il momento di applicare le configurazioni all'agente recuperando il catalogo dal burattinaio:
$ sudo /opt/puppetlabs/bin/puppet agent --testIn questo comando, il parametro --test non significa un test, le impostazioni recuperate dal master verranno applicate all'agente locale. Per testare/verificare le configurazioni da master è necessario eseguire il seguente comando:
$ sudo /opt/puppetlabs/bin/puppet agent --noopConfigurazione e programmazione del pupazzo
Puppet utilizza un approccio di programmazione dichiarativo il cui scopo è specificare cosa fare e non importa come ottenerlo!
La parte più elementare di codice su Puppet è la risorsa che specifica una proprietà di sistema come comando, servizio, file, directory, utente o pacchetto.
Di seguito è presentata la sintassi di una risorsa per creare un utente:
user { 'admin_postgresql':
ensure => present,
uid => '1000',
gid => '1000',
home => '/home/admin/postresql'
}Diverse risorse potrebbero essere unite alla prima classe (nota anche come manifest) di file con estensione “pp” (sta per Puppet Program), tuttavia, diversi manifest e dati (come fatti, file e modelli) comporranno un modulo. Tutte le gerarchie logiche e le regole sono rappresentate nel diagramma seguente:
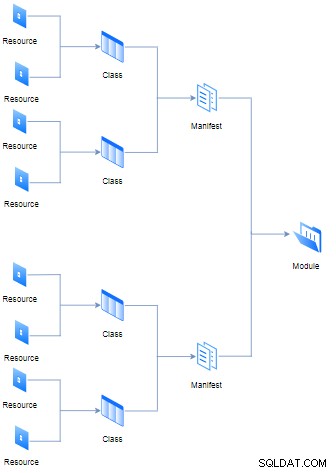
Lo scopo di ogni modulo è di contenere tutti i manifesti necessari per eseguire singoli compiti in modo modulare. D'altra parte, il concetto di classe non è lo stesso dei linguaggi di programmazione orientati agli oggetti, in Puppet funziona come un aggregatore di risorse.
L'organizzazione di questi file ha una struttura di directory specifica da seguire:
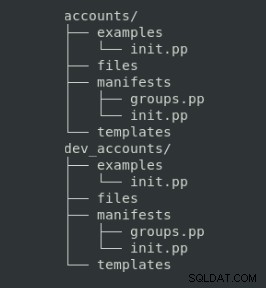
Su cui lo scopo di ciascuna cartella è il seguente:
| Cartella | Descrizione |
| manifesta | Codice fantoccio |
| file | File statici da copiare sui nodi |
| modelli | File modello da copiare sui nodi gestiti (può essere personalizzato con variabili) |
| esempi | Manifesto per mostrare come utilizzare il modulo |
class dev_accounts {
$rootgroup = $osfamily ? {
'Debian' => 'sudo',
'RedHat' => 'wheel',
default => warning('This distribution is not supported by the Accounts module'),
}
include accounts::groups
user { 'username':
ensure => present,
home => '/home/admin/postresql',
shell => '/bin/bash',
managehome => true,
gid => 'admin_db',
groups => "$rootgroup",
password => '$1$7URTNNqb$65ca6wPFDvixURc/MMg7O1'
}
}Nella prossima sezione, ti mostreremo come generare il contenuto della cartella degli esempi e i comandi per testare e pubblicare ogni modulo.
Configurazione di Puppet per PostgreSQL
Prima di presentare i numerosi esempi di configurazione per implementare e mantenere un database PostgreSQL è necessario installare il modulo puppet PostgreSQL (sul server host) per utilizzare tutte le sue funzionalità:
$ sudo /opt/puppetlabs/bin/puppet module install puppetlabs-postgresqlAttualmente, migliaia di moduli pronti per l'uso su Puppet sono disponibili nel repository di moduli pubblico Puppet Forge.
Fase uno
Configura e distribuisci una nuova istanza PostgreSQL. Ecco tutta la programmazione e la configurazione necessarie per installare una nuova istanza PostgreSQL in tutti i nodi.
Il primo passo è creare una nuova directory della struttura del modulo condivisa in precedenza:
$ cd /etc/puppetlabs/code/environments/production/modules
$ mkdir db_postgresql_admin
$ cd db_postgresql_admin; mkdir{examples,files,manifests,templates}Quindi, nel file manifest manifests/init.pp, devi includere la classe postgresql::server fornita dal modulo installato:
class db_postgresql_admin{
include postgresql::server
}Per controllare la sintassi del manifest, è buona norma eseguire il seguente comando:
$ sudo /opt/puppetlabs/bin/puppet parser validate init.ppSe non viene restituito nulla, significa che la sintassi è corretta
Per mostrarti come utilizzare questo modulo nella cartella di esempio, è necessario creare un nuovo file manifest init.pp con il seguente contenuto:
include db_postgresql_adminLa posizione dell'esempio nel modulo deve essere testata e applicata al catalogo principale:
$ sudo /opt/puppetlabs/bin/puppet apply --modulepath=/etc/puppetlabs/code/environments/production/modules --noop init.ppInfine, è necessario definire a quale modulo ogni nodo ha accesso nel file “/etc/puppetlabs/code/environments/production/manifests/site.pp” :
node ’agent.severalnines.com’,’agent2.severalnines.com’{
include db_postgresql_admin
}O una configurazione predefinita per tutti i nodi:
node default {
include db_postgresql_admin
}Di solito ogni 30min i nodi controllano il catalogo principale, tuttavia questa query può essere forzata lato nodo con il seguente comando:
$ /opt/puppetlabs/bin/puppet agent -tOppure se lo scopo è quello di simulare le differenze tra la configurazione master e le impostazioni del nodo corrente, potrebbe essere utilizzato il parametro nopp (nessuna operazione):
$ /opt/puppetlabs/bin/puppet agent -t --noopFase due
Aggiorna l'istanza PostgreSQL per ascoltare tutte le interfacce. L'installazione precedente definisce un'impostazione di istanza in modalità molto restrittiva:consente solo connessioni su localhost come può essere confermato dagli host associati alla porta 5432 (definita per PostgreSQL):
$ sudo netstat -ntlp|grep 5432
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 3237/postgres
tcp6 0 0 ::1:5432 :::* LISTEN 3237/postgres Per consentire l'ascolto di tutte le interfacce, è necessario avere il seguente contenuto nel file /etc/puppetlabs/code/environments/production/modules/db_postgresql_admin/manifests/init.pp
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
}Nell'esempio sopra è dichiarata la classe postgresql::server e impostando il parametro listen_addresses su “*” ciò significa tutte le interfacce.
Ora la porta 5432 è associata a tutte le interfacce, può essere confermata con il seguente indirizzo/porta IP:“0.0.0.0:5432”
$ sudo netstat -ntlp|grep 5432
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 1232/postgres
tcp6 0 0 :::5432 :::* LISTEN 1232/postgres Per ripristinare l'impostazione iniziale:consentire connessioni al database solo da localhost il parametro listen_addresses deve essere impostato su "localhost" o specificando un elenco di host, se lo si desidera:
listen_addresses = 'agent2.severalnines.com,agent3.severalnines.com,localhost'Per recuperare la nuova configurazione dall'host master è sufficiente richiederla sul nodo:
$ /opt/puppetlabs/bin/puppet agent -tFase tre
Crea un database PostgreSQL. L'istanza PostgreSQL può essere creata con un nuovo database e un nuovo utente (con password) per utilizzare questo database e una regola sul file pg_hab.conf per consentire la connessione al database per questo nuovo utente:
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
postgresql::server::db{‘nines_blog_db’:
user => ‘severalnines’, password=> postgresql_password(‘severalnines’,’passwd12’)
}
postgresql::server::pg_hba_rule{‘Authentication for severalnines’:
Description =>’Open access to severalnines’,
type => ‘local’,
database => ‘nines_blog_db’,
user => ‘severalnines’,
address => ‘127.0.0.1/32’
auth_method => ‘md5’
}
}Quest'ultima risorsa ha il nome di "Authentication for manynines" e il file pg_hba.conf avrà un'altra regola aggiuntiva:
# Rule Name: Authentication for severalnines
# Description: Open access for severalnines
# Order: 150
local nines_blog_db severalnines 127.0.0.1/32 md5Per recuperare la nuova configurazione dall'host master è sufficiente richiederla sul nodo:
$ /opt/puppetlabs/bin/puppet agent -tFase quattro
Crea un utente di sola lettura. Per creare un nuovo utente, con privilegi di sola lettura, è necessario aggiungere le seguenti risorse al manifest precedente:
postgresql::server::role{‘Creation of a new role nines_reader’:
createdb => false,
createrole => false,
superuser => false, password_hash=> postgresql_password(‘nines_reader’,’passwd13’)
}
postgresql::server::pg_hba_rule{‘Authentication for nines_reader’:
description =>’Open access to nines_reader’,
type => ‘host’,
database => ‘nines_blog_db’,
user => ‘nines_reader’,
address => ‘192.168.1.10/32’,
auth_method => ‘md5’
}Per recuperare la nuova configurazione dall'host master è sufficiente richiederla sul nodo:
$ /opt/puppetlabs/bin/puppet agent -tConclusione
In questo post del blog, ti abbiamo mostrato i passaggi di base per distribuire e iniziare a configurare il tuo database PostgreSQL in modo automatico e personalizzato su più nodi (che potrebbero anche essere macchine virtuali).
Questi tipi di automazione possono aiutarti a diventare più efficace rispetto a farlo manualmente e la configurazione di PostgreSQL può essere facilmente eseguita utilizzando molte delle classi disponibili nel repository di puppetforge