L'elevata disponibilità è un requisito per quasi tutte le aziende del mondo che utilizzano PostgreSQL È risaputo che PostgreSQL utilizza Streaming Replication come metodo di replica. PostgreSQL Streaming Replication è asincrono per impostazione predefinita, quindi è possibile avere alcune transazioni impegnate nel nodo primario che non sono state ancora replicate sul server di standby. Ciò significa che esiste la possibilità di una potenziale perdita di dati.
Questo ritardo nel processo di commit dovrebbe essere molto piccolo... se il server di standby è abbastanza potente da tenere il passo con il carico. Se questo piccolo rischio di perdita di dati non è accettabile in azienda, puoi anche utilizzare la replica sincrona invece di quella predefinita.
Nella replica sincrona, ogni commit di una transazione di scrittura attenderà fino alla conferma che il commit è stato scritto sul disco del registro write-ahead sia del server primario che di quello di standby.
Questo metodo riduce al minimo la possibilità di perdita di dati. Affinché si verifichi una perdita di dati, è necessario che sia il primario che lo standby si interrompano contemporaneamente.
Lo svantaggio di questo metodo è lo stesso per tutti i metodi sincroni poiché con questo metodo aumenta il tempo di risposta per ogni transazione di scrittura. Ciò è dovuto alla necessità di attendere fino a quando tutte le conferme che la transazione è stata impegnata. Fortunatamente, le transazioni di sola lettura non saranno interessate da questo ma; solo le transazioni di scrittura.
In questo blog, mostri come installare un cluster PostgreSQL da zero, convertire la replica asincrona (predefinita) in una sincrona. Ti mostrerò anche come eseguire il rollback se il tempo di risposta non è accettabile poiché puoi facilmente tornare allo stato precedente. Vedrai come distribuire, configurare e monitorare facilmente una replica sincrona PostgreSQL utilizzando ClusterControl utilizzando un solo strumento per l'intero processo.
Installazione di un cluster PostgreSQL
Iniziamo a installare e configurare una replica PostgreSQL asincrona, ovvero la modalità di replica usuale utilizzata in un cluster PostgreSQL. Useremo PostgreSQL 11 su CentOS 7.
Installazione di PostgreSQL
Seguendo la guida all'installazione ufficiale di PostgreSQL, questa operazione è piuttosto semplice.
Per prima cosa, installa il repository:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstalla i pacchetti client e server PostgreSQL:
$ yum install postgresql11 postgresql11-serverInizializza il database:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11Sul nodo standby, puoi evitare l'ultimo comando (avviare il servizio database) poiché ripristinerai un backup binario per creare la replica in streaming.
Ora, vediamo la configurazione richiesta da una replica PostgreSQL asincrona.
Configurazione della replica PostgreSQL asincrona
Impostazione del nodo primario
Nel nodo primario PostgreSQL, devi utilizzare la seguente configurazione di base per creare una replica Async. I file che verranno modificati sono postgresql.conf e pg_hba.conf. In generale si trovano nella directory dei dati (/var/lib/pgsql/11/data/) ma puoi confermarlo lato database:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Modifica o aggiungi i seguenti parametri nel file di configurazione postgresql.conf.
Qui devi aggiungere gli indirizzi IP su cui ascoltare. Il valore predefinito è "localhost" e per questo esempio utilizzeremo "*" per tutti gli indirizzi IP nel server.
listen_addresses = '*' Imposta la porta del server su cui ascoltare. Per impostazione predefinita 5432.
port = 5432 Determina quante informazioni vengono scritte sui WAL. I valori possibili sono minimo, replica o logico. Il valore hot_standby è mappato alla replica e viene utilizzato per mantenere la compatibilità con le versioni precedenti.
wal_level = hot_standby Imposta il numero massimo di processi walsender, che gestiscono la connessione con un server in standby.
max_wal_senders = 16Imposta la quantità minima di file WAL da conservare nella directory pg_wal.
wal_keep_segments = 32La modifica di questi parametri richiede il riavvio del servizio database.
$ systemctl restart postgresql-11Pg_hba.conf
Modifica o aggiungi i seguenti parametri nel file di configurazione pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Come puoi vedere, qui devi aggiungere il permesso di accesso dell'utente. La prima colonna è il tipo di connessione, che può essere host o locale. Quindi, è necessario specificare il database (replica), l'utente, l'indirizzo IP di origine e il metodo di autenticazione. La modifica di questo file richiede un ricaricamento del servizio di database.
$ systemctl reload postgresql-11Dovresti aggiungere questa configurazione sia nel nodo primario che in quello standby, poiché ti servirà se il nodo standby viene promosso a master in caso di errore.
Ora devi creare un utente di replica.
Ruolo di replica
Il RUOLO (utente) deve disporre del privilegio REPLICAZIONE per utilizzarlo nella replica in streaming.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEDopo aver configurato i file corrispondenti e aver creato l'utente, è necessario creare un backup coerente dal nodo primario e ripristinarlo sul nodo di standby.
Impostazione del nodo di standby
Sul nodo standby, vai alla directory /var/lib/pgsql/11/ e sposta o rimuovi la datadir corrente:
$ cd /var/lib/pgsql/11/
$ mv data data.bkQuindi, esegui il comando pg_basebackup per ottenere la datadir primaria corrente e assegnare il proprietario corretto (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataOra è necessario utilizzare la seguente configurazione di base per creare una replica Async. Il file che verrà modificato è postgresql.conf ed è necessario creare un nuovo file recovery.conf. Entrambi si troveranno in /var/lib/pgsql/11/.
Recovery.conf
Specificare che questo server sarà un server di standby. Se è acceso, il server continuerà il ripristino recuperando nuovi segmenti WAL quando viene raggiunta la fine del WAL archiviato.
standby_mode = 'on'Specifica una stringa di connessione da utilizzare affinché il server di standby si connetta al nodo primario.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Specifica il recupero in una sequenza temporale particolare. L'impostazione predefinita prevede il ripristino lungo la stessa sequenza temporale corrente quando è stato eseguito il backup di base. Impostandolo su "più recente" viene ripristinata l'ultima sequenza temporale trovata nell'archivio.
recovery_target_timeline = 'latest'Specificare un file trigger la cui presenza termina il ripristino in standby.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Modifica o aggiungi i seguenti parametri nel file di configurazione postgresql.conf.
Determina quante informazioni vengono scritte sui WAL. I valori possibili sono minimo, replica o logico. Il valore hot_standby viene mappato alla replica e viene utilizzato per mantenere la compatibilità con le versioni precedenti. La modifica di questo valore richiede il riavvio del servizio.
wal_level = hot_standbyConsenti le query durante il ripristino. La modifica di questo valore richiede il riavvio del servizio.
hot_standby = onAvvio del nodo standby
Ora hai tutta la configurazione richiesta, devi solo avviare il servizio database sul nodo di standby.
$ systemctl start postgresql-11E controlla i log del database in /var/lib/pgsql/11/data/log/. Dovresti avere qualcosa del genere:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Puoi anche controllare lo stato della replica nel nodo primario eseguendo la seguente query:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Come puoi vedere, stiamo usando una replica asincrona.
Conversione della replica postgreSQL asincrona in replica sincrona
Ora è il momento di convertire questa replica asincrona in una di sincronizzazione e, per questo, dovrai configurare sia il nodo primario che quello di standby.
Nodo primario
Nel nodo primario di PostgreSQL, devi utilizzare questa configurazione di base in aggiunta alla precedente configurazione asincrona.
Postgresql.conf
Specificare un elenco di server in standby che possono supportare la replica sincrona. Questo nome del server di standby è l'impostazione del nome_applicazione nel file recovery.conf di standby.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Specifica se il commit della transazione attende la scrittura dei record WAL su disco prima che il comando restituisca un'indicazione di "successo" al client. I valori validi sono on, remote_apply, remote_write, local e off. Il valore predefinito è attivo.
synchronous_commit = onImpostazione del nodo di standby
Nel nodo standby di PostgreSQL, devi modificare il file recovery.conf aggiungendo il valore 'application_name nel parametro primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Riavvia il servizio database sia nel nodo primario che in quello standby:
$ service postgresql-11 restartOra dovresti avere la replica dello streaming di sincronizzazione attiva e funzionante:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Rollback dalla replica sincrona a quella asincrona di PostgreSQL
Se è necessario tornare alla replica asincrona di PostgreSQL, è sufficiente eseguire il rollback delle modifiche eseguite nel file postgresql.conf sul nodo primario:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onE riavvia il servizio database.
$ service postgresql-11 restartQuindi ora dovresti avere di nuovo la replica asincrona.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Come distribuire una replica sincrona PostgreSQL utilizzando ClusterControl
Con ClusterControl puoi eseguire tutte le attività di distribuzione, configurazione e monitoraggio dallo stesso lavoro e sarai in grado di gestirlo dalla stessa interfaccia utente.
Supponiamo che ClusterControl sia installato e che possa accedere ai nodi del database tramite SSH. Per ulteriori informazioni su come configurare l'accesso ClusterControl fare riferimento alla nostra documentazione ufficiale.
Vai su ClusterControl e usa l'opzione "Distribuisci" per creare un nuovo cluster PostgreSQL.
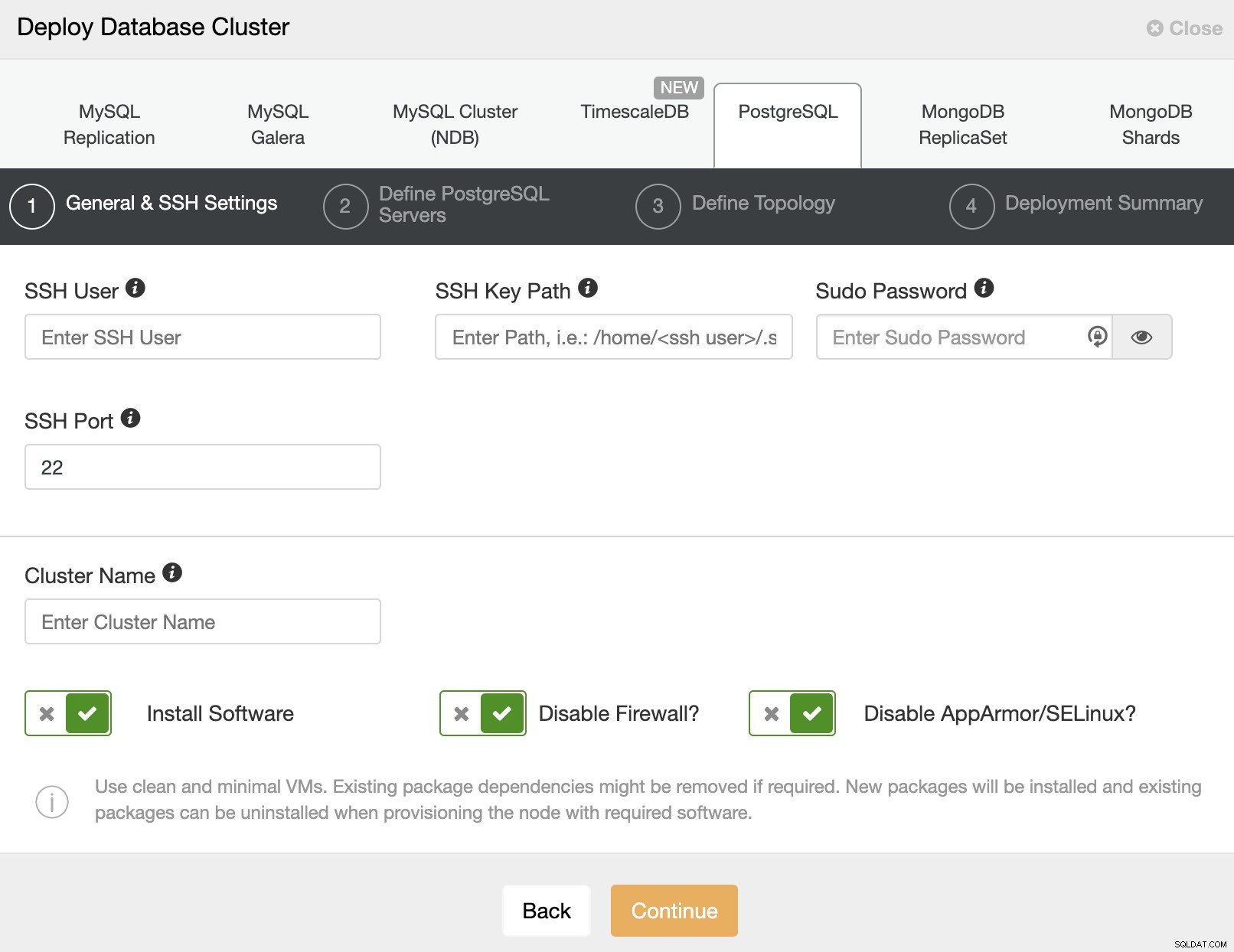
Quando si seleziona PostgreSQL, è necessario specificare Utente, Chiave o Password e un porta per connettersi tramite SSH ai nostri server. Hai anche bisogno di un nome per il tuo nuovo cluster e se vuoi che ClusterControl installi il software e le configurazioni corrispondenti per te.
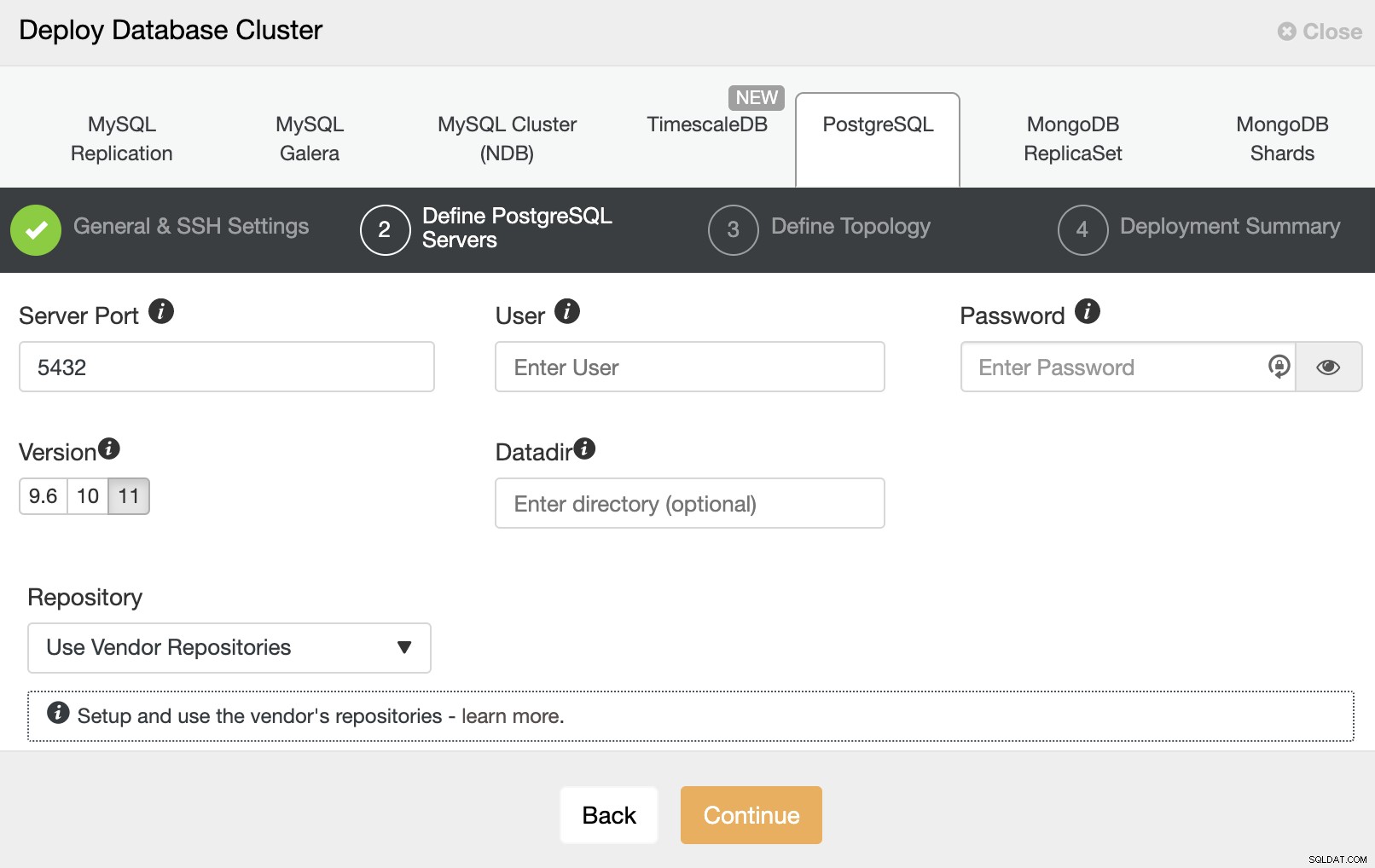
Dopo aver impostato le informazioni di accesso SSH, è necessario inserire i dati per accedere il tuo database. Puoi anche specificare quale repository utilizzare.
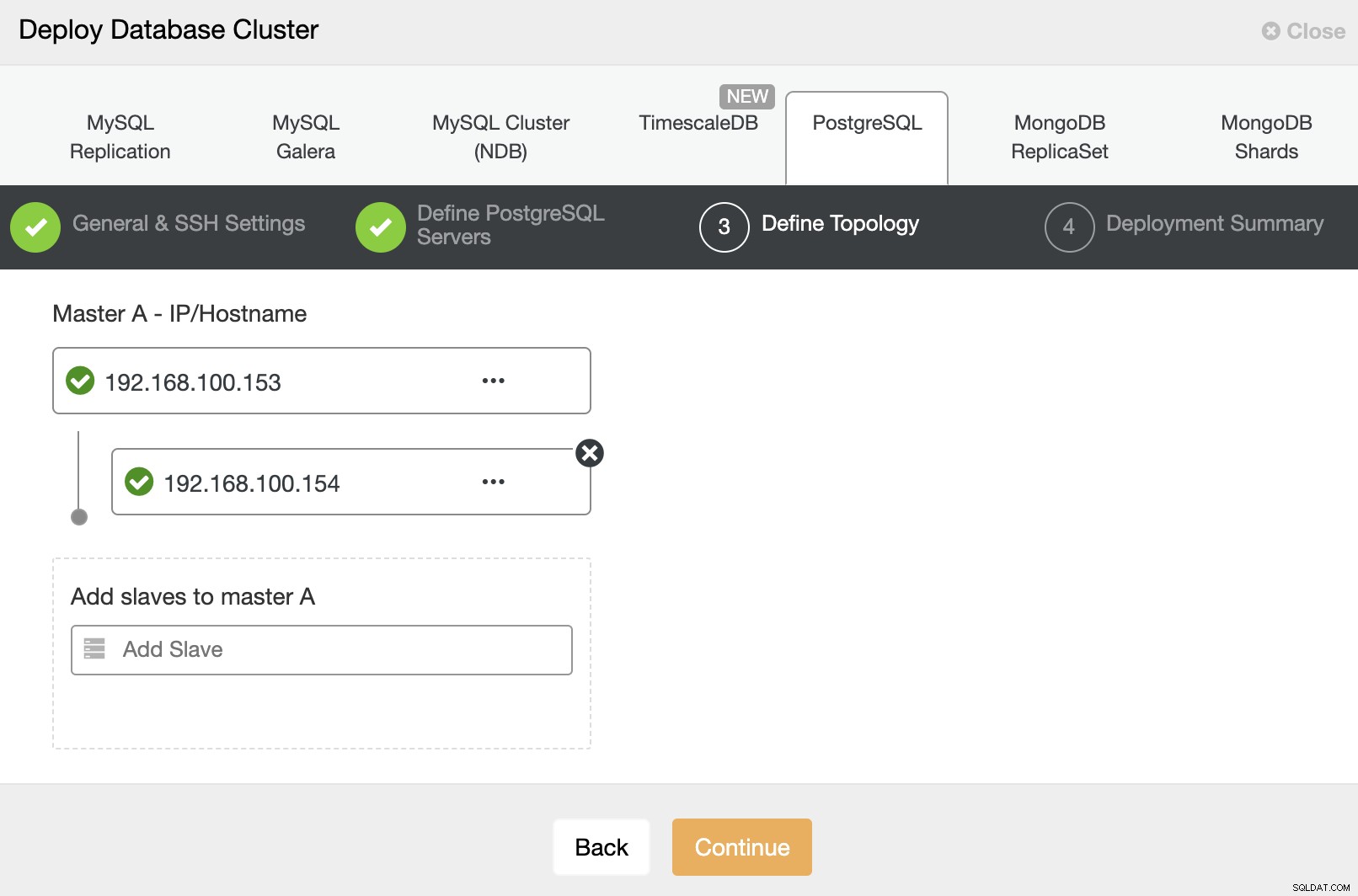
Nel passaggio successivo, devi aggiungere i tuoi server al cluster che stai per creare. Quando aggiungi i tuoi server, puoi inserire IP o nome host.
E infine, nell'ultimo passaggio, puoi scegliere il metodo di replica, che può essere una replica asincrona o sincrona.
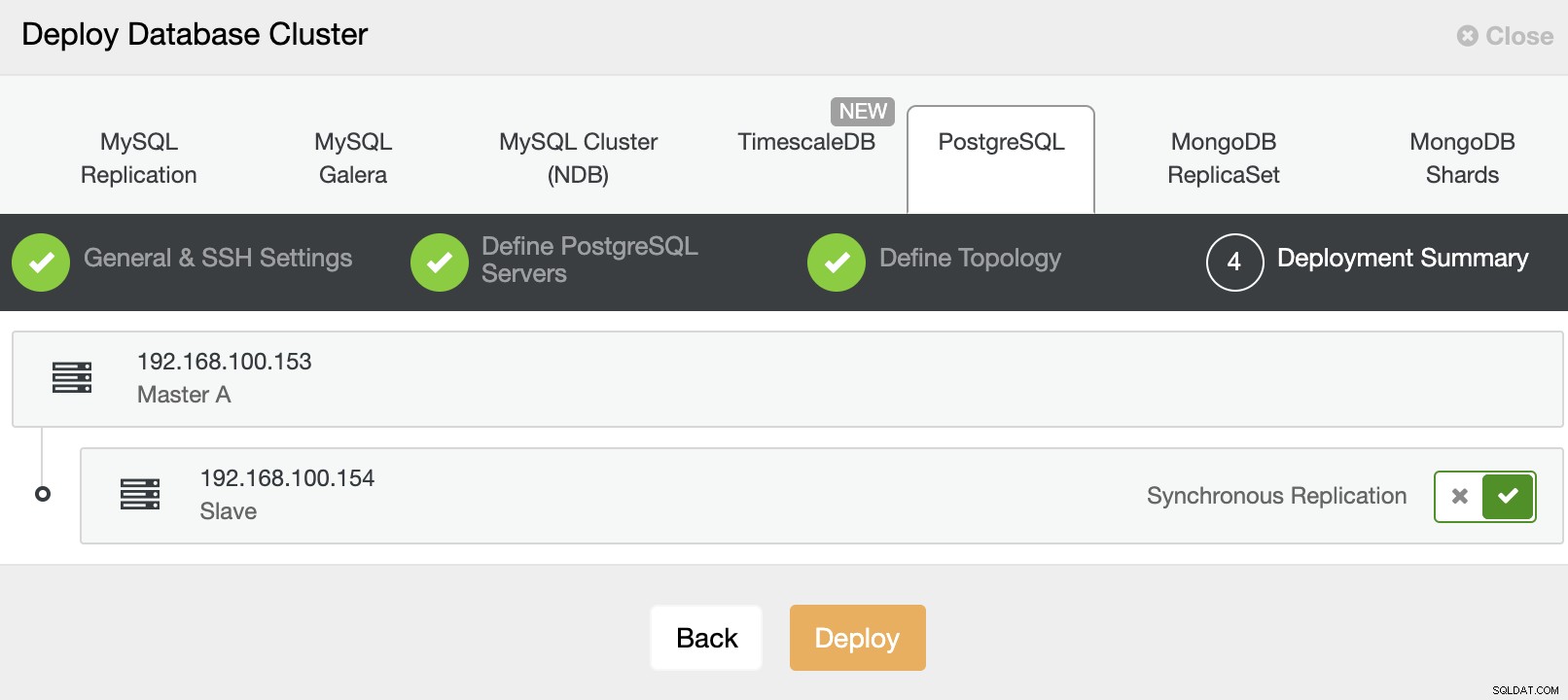
Ecco fatto. Puoi monitorare lo stato del lavoro nella sezione delle attività di ClusterControl.
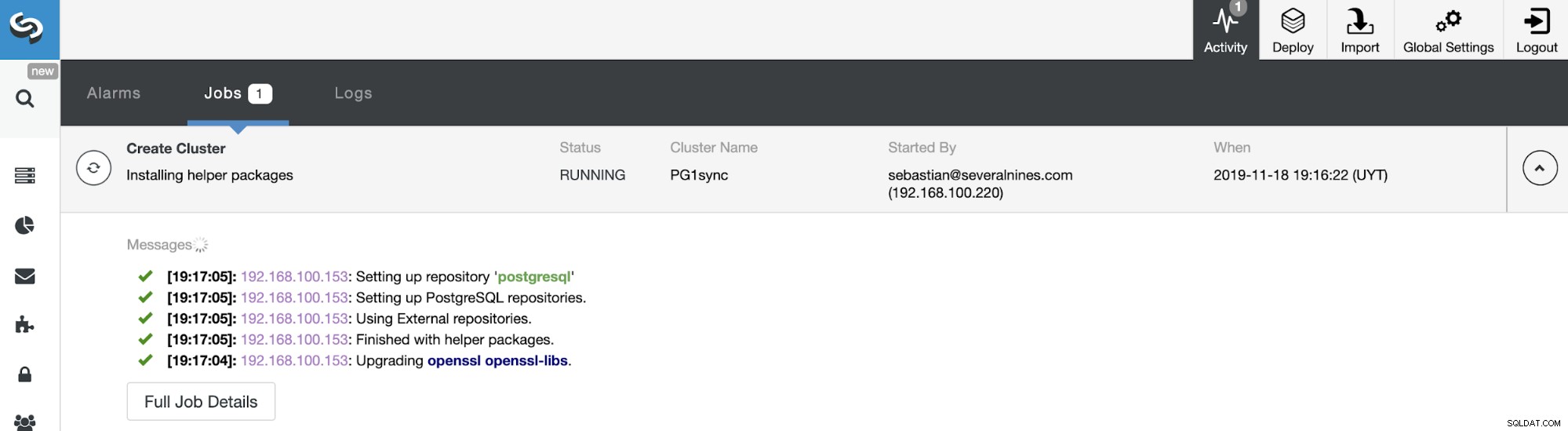
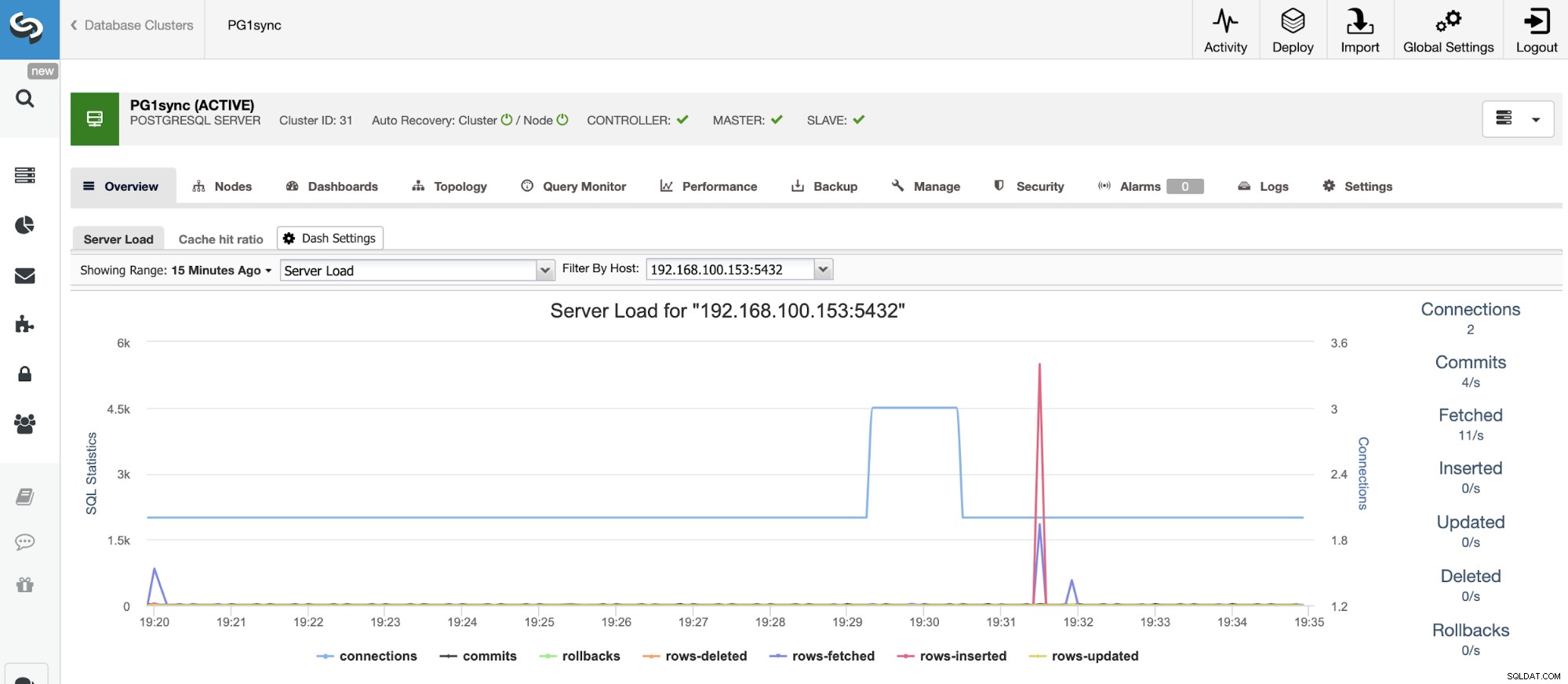
E al termine di questo lavoro, avrai installato il tuo cluster sincrono PostgreSQL, configurato e monitorato da ClusterControl.
Conclusione
Come accennato all'inizio di questo blog, l'alta disponibilità è un requisito per tutte le aziende, quindi dovresti conoscere le opzioni disponibili per ottenerla per ciascuna tecnologia in uso. Per PostgreSQL, puoi utilizzare la replica di streaming sincrona come il modo più sicuro per implementarla, ma questo metodo non funziona per tutti gli ambienti e carichi di lavoro.
Fai attenzione alla latenza generata aspettando la conferma di ogni transazione che potrebbe essere un problema invece di una soluzione ad alta disponibilità.