"Ma ha funzionato bene sul nostro server di sviluppo!"
Quante volte l'ho sentito quando si sono verificati problemi di prestazioni delle query SQL qua e là? L'ho detto io stesso tempo fa. Ho presunto che una query in esecuzione in meno di un secondo sarebbe stata eseguita correttamente nei server di produzione. Ma mi sbagliavo.
Riesci a relazionarti con questa esperienza? Se sei ancora su questa barca oggi per qualsiasi motivo, questo post è per te. Ti fornirà una metrica migliore per ottimizzare le prestazioni delle query SQL. Parleremo di tre delle figure più critiche in STATISTICS IO.
Ad esempio, utilizzeremo il database di esempio AdventureWorks.
Prima di iniziare a eseguire le query seguenti, attivare STATISTICS IO. Ecco come farlo in una finestra di query:
USE AdventureWorks
GO
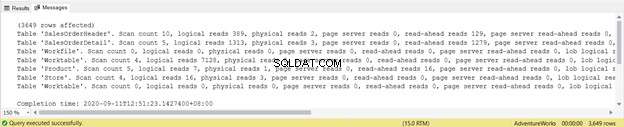
SET STATISTICS IO ONDopo aver eseguito una query con STATISTICS IO ON, appariranno diversi messaggi. Puoi vederli nella scheda Messaggi della finestra della query in SQL Server Management Studio (vedi Figura 1):
Ora che abbiamo finito con la breve introduzione, scaviamo più a fondo.
1. Letture logiche elevate
Il primo punto della nostra lista è il colpevole più comune:letture logiche elevate.
Le letture logiche sono il numero di pagine lette dalla cache di dati. Una pagina ha una dimensione di 8 KB. La cache dei dati, invece, si riferisce alla RAM utilizzata da SQL Server.
Le letture logiche sono fondamentali per l'ottimizzazione delle prestazioni. Questo fattore definisce la quantità di cui un SQL Server ha bisogno per produrre il set di risultati richiesto. Quindi, l'unica cosa da ricordare è:più alte sono le letture logiche, più a lungo è necessario che SQL Server funzioni. Significa che la tua query sarà più lenta. Riduci il numero di letture logiche e aumenterai le prestazioni della query.
Ma perché usare letture logiche invece del tempo trascorso?
- Il tempo trascorso dipende da altre operazioni eseguite dal server, non solo dalla tua query.
- Il tempo trascorso può cambiare dal server di sviluppo al server di produzione. Ciò accade quando entrambi i server hanno capacità e configurazioni hardware e software diverse.
Fare affidamento sul tempo trascorso ti farà dire:"Ma ha funzionato bene nel nostro server di sviluppo!" prima o poi.
Perché usare letture logiche invece di letture fisiche?
- Le letture fisiche sono il numero di pagine lette dai dischi alla cache di dati (in memoria). Una volta che le pagine necessarie in una query sono nella cache dei dati, non è necessario rileggerle dai dischi.
- Quando la stessa query viene rieseguita, le letture fisiche saranno zero.
Le letture logiche sono la scelta logica per ottimizzare le prestazioni delle query SQL.
Per vederlo in azione, procediamo con un esempio.
Esempio di letture logiche
Supponiamo di dover ottenere l'elenco dei clienti con ordini spediti lo scorso 11 luglio 2011. Ti viene in mente questa semplice query di seguito:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'È semplice. Questa query avrà il seguente output:

Quindi, controlli il risultato di STATISTICS IO di questa query:

L'output mostra le letture logiche di ciascuna delle quattro tabelle utilizzate nella query. In totale, la somma delle letture logiche è 729. Puoi anche visualizzare letture fisiche con una somma totale di 21. Tuttavia, prova a eseguire nuovamente la query e sarà zero.
Dai un'occhiata più da vicino alle letture logiche di SalesOrderHeader . Ti chiedi perché ha 689 letture logiche? Forse hai pensato di esaminare il piano di esecuzione della query seguente:
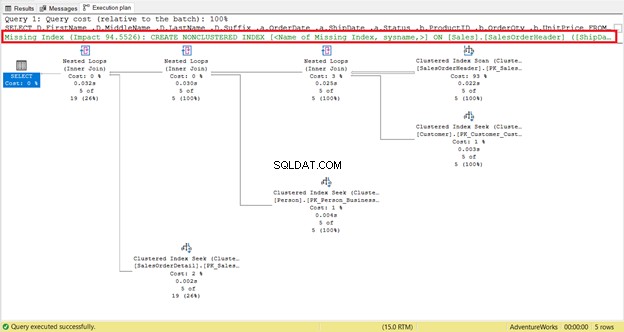
Per prima cosa, c'è una scansione dell'indice avvenuta in SalesOrderHeader con un costo del 93%. Cosa potrebbe succedere? Supponi di aver controllato le sue proprietà:
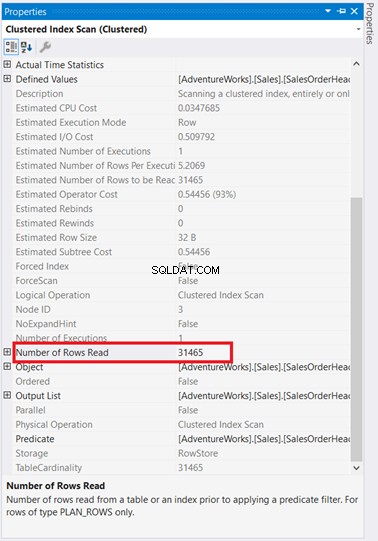
Whoa! 31.465 righe lette per sole 5 righe restituite? È assurdo!
Ridurre il numero di letture logiche
Non è così difficile ridurre quelle 31.465 righe lette. SQL Server ci ha già fornito un indizio. Procedi come segue:
PASSAGGIO 1:segui la raccomandazione di SQL Server e aggiungi l'indice mancante
Hai notato la raccomandazione sull'indice mancante nel piano di esecuzione (figura 4)? Risolverà il problema?
C'è un modo per scoprirlo:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Eseguire nuovamente la query e visualizzare le modifiche nelle letture logiche di STATISTICS IO.

Come puoi vedere in STATISTICS IO (Figura 6), c'è un'enorme diminuzione delle letture logiche da 689 a 17. Le nuove letture logiche complessive sono 57, che è un miglioramento significativo rispetto a 729 letture logiche. Ma per essere sicuri, esaminiamo di nuovo il piano di esecuzione.
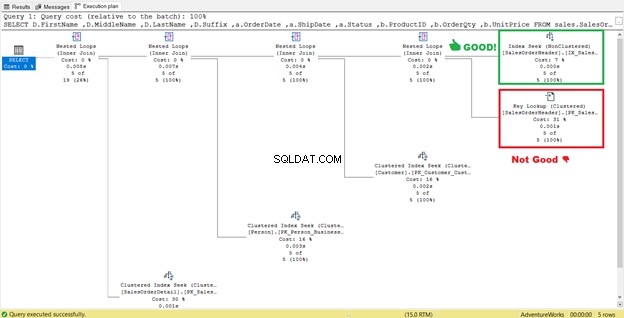
Sembra che ci sia un miglioramento nel piano con conseguente riduzione delle letture logiche. La scansione dell'indice è ora una ricerca dell'indice. SQL Server non dovrà più esaminare riga per riga per ottenere i record con Shipdate='07/11/2011′ . Ma qualcosa è ancora in agguato in quel piano e non è giusto.
È necessario il passaggio 2.
PASSAGGIO 2:Modifica l'indice e aggiungi alle colonne incluse:OrderDate, Status e CustomerID
Vedi quell'operatore di ricerca chiave nel piano di esecuzione (Figura 7)? Significa che l'indice non cluster creato non è sufficiente:il Query Processor deve utilizzare nuovamente l'indice cluster.
Verifichiamo le sue proprietà.
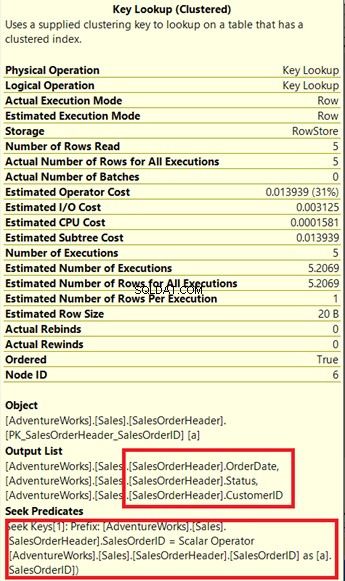
Nota il riquadro allegato sotto l'Elenco di output . Succede che abbiamo bisogno di OrderDate , Stato e ID cliente nel set di risultati. Per ottenere questi valori, il Query Processor ha utilizzato l'indice cluster (consultare Cerca predicati ) per arrivare al tavolo.
Dobbiamo rimuovere quella ricerca chiave. La soluzione è includere OrderDate , Stato e ID cliente colonne nell'indice creato in precedenza.
- Fai clic con il pulsante destro del mouse su IX_SalesOrderHeader_ShipDate in SSMS.
- Seleziona Proprietà .
- Fai clic sulle colonne incluse tab.
- Aggiungi Data ordine , Stato e ID cliente .
- Fai clic su OK .
Dopo aver ricreato l'indice, eseguire nuovamente la query. Questo rimuoverà Ricerca chiave e ridurre le letture logiche?

Ha funzionato! Da 17 letture logiche fino a 2 (Figura 9).
E la Ricerca chiave ?
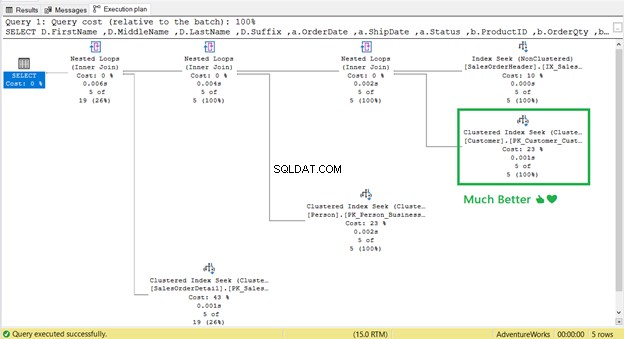
È andato! Ricerca di indice cluster ha sostituito Ricerca chiave.
Il cibo da asporto
Allora, cosa abbiamo imparato?
Uno dei modi principali per ridurre le letture logiche e migliorare le prestazioni delle query SQL consiste nel creare un indice appropriato. Ma c'è un problema. Nel nostro esempio, ha ridotto le letture logiche. A volte, sarà giusto il contrario. Potrebbe influire anche sulle prestazioni di altre query correlate.
Pertanto, controllare sempre STATISTICS IO e il piano di esecuzione dopo aver creato l'indice.
2. Letture logiche ad alto lob
È più o meno lo stesso del punto 1, ma tratterà i tipi di dati testo , ntesto , immagine , varchar (massimo ), nvarchar (massimo ), variabile (massimo ), o Colonnestore pagine di indice.
Facciamo un esempio:generare letture logiche lob.
Esempio di letture logiche Lob
Si supponga di voler visualizzare un prodotto con il prezzo, il colore, l'immagine in miniatura e un'immagine più grande su una pagina Web. Pertanto, ti viene in mente una query iniziale come quella mostrata di seguito:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorQuindi, eseguilo e vedi l'output come quello di seguito:

Dato che sei un ragazzo (o una ragazza) così orientato alle prestazioni, controlli immediatamente STATISTICS IO. Eccolo:

Sembra un po' di sporco nei tuoi occhi. 665 letture logiche lob? Non puoi accettare questo. Per non parlare di 194 letture logiche ciascuna da ProductPhoto e ProdottoProdottoFoto tavoli. Pensi davvero che questa query abbia bisogno di alcune modifiche.
Riduzione delle letture logiche Lob
La query precedente aveva 97 righe restituite. Tutte le 97 biciclette. Pensi che questo sia utile da visualizzare su una pagina web?
Un indice può aiutare, ma perché non semplificare prima la query? In questo modo, puoi essere selettivo su ciò che SQL Server restituirà. Puoi ridurre le letture logiche lob.
- Aggiungi un filtro per la Sottocategoria Prodotto e lascia che il cliente scelga. Quindi includilo nella clausola WHERE.
- Rimuovi la Sottocategoria Prodotto colonna poiché aggiungerai un filtro per la sottocategoria del prodotto.
- Rimuovi la Foto grande colonna. Interroga questa opzione quando l'utente seleziona un prodotto specifico.
- Usa la paginazione. Il cliente non potrà visualizzare tutte le 97 biciclette contemporaneamente.
Sulla base di queste operazioni sopra descritte, modifichiamo la query come segue:
- Rimuovi Sottocategoria Prodotto e Foto grande colonne dal set di risultati.
- Utilizzare OFFSET e FETCH per adattare il paging nella query. Interroga solo 10 prodotti alla volta.
- Aggiungi ProductSubcategoryID nella clausola WHERE in base alla scelta del cliente.
- Rimuovi la Sottocategoria Prodotto colonna nella clausola ORDER BY.
La query ora sarà simile a questa:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Con le modifiche apportate, le letture logiche lob miglioreranno? STATISTICHE IO ora riporta:

Foto del prodotto la tabella ora ha 0 letture logiche lob – da 665 letture logiche lob fino a nessuna. Questo è un certo miglioramento.
Asporto
Uno dei modi per ridurre le letture logiche lob consiste nel riscrivere la query per semplificarla.
Rimuovi le colonne non necessarie e riduci le righe restituite al minimo necessario. Se necessario, usa OFFSET e FETCH per il paging.
Per garantire che le modifiche alla query abbiano migliorato le letture logiche lob e le prestazioni della query SQL, controlla sempre STATISTICS IO.
3. Elevate letture logiche di Worktable/Workfile
Infine, è una lettura logica di Worktable e File di lavoro . Ma cosa sono questi tavoli? Perché vengono visualizzati quando non li usi nella tua query?
Avere un Tavolo da lavoro e File di lavoro apparire in STATISTICS IO significa che SQL Server ha bisogno di molto più lavoro per ottenere i risultati desiderati. Ricorre all'utilizzo di tabelle temporanee in tempdb , ovvero Tavoli da lavoro e File di lavoro . Non è necessariamente dannoso averli nell'output di STATISTICS IO, purché le letture logiche siano zero e non causi problemi al server.
Queste tabelle possono apparire quando c'è un ORDER BY, GROUP BY, CROSS JOIN o DISTINCT, tra gli altri.
Esempio di letture logiche di Worktable/Workfile
Si supponga di dover interrogare tutti i negozi senza vendita di determinati prodotti.
Inizialmente ti viene in mente quanto segue:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDQuesta query ha restituito 3649 righe:
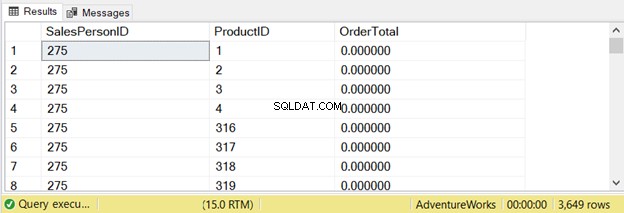
Controlliamo cosa dice STATISTICS IO:

Vale la pena notare che il Worktable le letture logiche sono 7128. Le letture logiche complessive sono 8853. Se controlli il piano di esecuzione, vedrai molti parallelismi, corrispondenze hash, spool e scansioni di indici.
Riduzione delle letture logiche di Worktable/Workfile
Non ho potuto costruire una singola istruzione SELECT con un risultato soddisfacente. Pertanto l'unica scelta è suddividere l'istruzione SELECT in più query. Vedi sotto:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsÈ più lungo di diverse righe e utilizza tabelle temporanee. Ora, vediamo cosa rivela STATISTICS IO:
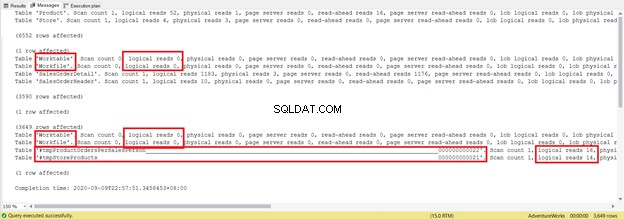
Cerca di non concentrarti sulla lunghezza del rapporto statistico:è solo frustrante. Invece, aggiungi letture logiche da ciascuna tabella.
Per un totale di 1279, è una diminuzione significativa, poiché erano 8853 letture logiche dalla singola istruzione SELECT.
Non abbiamo aggiunto alcun indice alle tabelle temporanee. Potresti averne bisogno se vengono aggiunti molti più record a SalesOrderHeader e SalesOrderDetail . Ma hai capito.
Asporto
A volte 1 istruzione SELECT sembra buona. Tuttavia, dietro le quinte, è vero il contrario. Tavoli da lavoro e File di lavoro con letture logiche elevate ritardano le prestazioni delle query SQL.
Se non riesci a pensare a un altro modo per ricostruire la query e gli indici sono inutili, prova l'approccio "divide et impera". I Tavoli da lavoro e File di lavoro potrebbe ancora apparire nella scheda Messaggio di SSMS, ma le letture logiche saranno zero. Pertanto, il risultato complessivo sarà letture meno logiche.
Il risultato finale delle prestazioni delle query SQL e di STATISTICS IO
Qual è il problema con queste 3 brutte statistiche di I/O?
La differenza nelle prestazioni delle query SQL sarà come notte e giorno se presti attenzione a questi numeri e li riduci. Abbiamo presentato solo alcuni modi per ridurre le letture logiche come:
- creare indici appropriati;
- Semplificare le query:rimuovere le colonne non necessarie e ridurre al minimo il set di risultati;
- suddividere una query in più query.
Ci sono più come aggiornare le statistiche, deframmentare gli indici e impostare il corretto FILLFACTOR. Puoi aggiungere altro nella sezione commenti?
Se ti piace questo post, condividilo con i tuoi social media preferiti.



