In molti dei miei post nell'ultimo anno ho utilizzato il tema delle persone che vedono un particolare tipo di attesa e poi reagiscono in modo "a scatti" all'attesa. In genere questo significa seguire alcuni consigli di Internet scadenti e intraprendere un'azione drastica e inappropriata o saltare a una conclusione su quale sia la causa principale del problema e quindi perdere tempo e fatica in una caccia all'oca.
Uno dei tipi di attesa in cui le reazioni istintive sono più forti e in cui esistono alcuni dei consigli più scarsi, è l'attesa CXPACKET. È anche il tipo di attesa più comunemente l'attesa principale sui server delle persone (secondo i miei due sondaggi sui tipi di attesa più grandi del 2010 e del 2014 – vedi qui per i dettagli), quindi lo tratterò in questo post.
Cosa significa il tipo di attesa CXPACKET?
La spiegazione più semplice è che CXPACKET significa che hai query in esecuzione in parallelo e vedrai *sempre* che CXPACKET attende una query parallela. Le attese di CXPACKET NON significano che hai un parallelismo problematico:devi scavare più a fondo per determinarlo.
Come esempio di operatore parallelo, considera l'operatore Repartition Streams, che ha la seguente icona nei piani di query grafici:

Ed ecco un'immagine che mostra cosa sta succedendo in termini di thread paralleli per questo operatore, con grado di parallelismo (DOP) pari a 4:
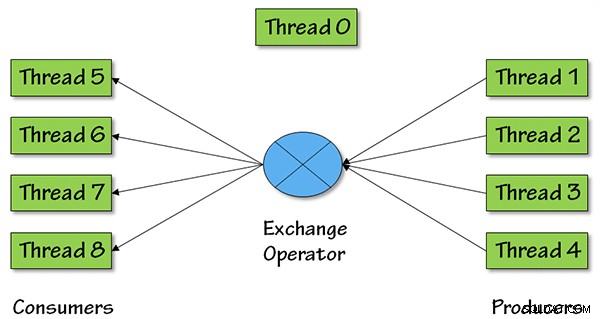
Per DOP =4, ci saranno quattro thread di produzione, che estraggono i dati da prima nel piano di query, quindi i dati tornano al resto del piano di query attraverso quattro thread di consumo.
Puoi vedere i vari thread in un operatore parallelo in attesa di una risorsa utilizzando sys.dm_os_waiting_tasks DMV, in exec_context_id colonna (questo post ha il mio script per farlo).
C'è sempre un thread di "controllo" per qualsiasi piano parallelo, che per errore storico è sempre l'ID thread 0. Il thread di controllo registra sempre un'attesa CXPACKET, con la durata uguale al tempo necessario per l'esecuzione del piano. Paul White ha un'ottima spiegazione dei thread nei piani paralleli qui.
L'unica volta in cui i thread non di controllo registreranno le attese di CXPACKET è se vengono completati prima degli altri thread nell'operatore. Questo può accadere se uno dei thread rimane bloccato in attesa di una risorsa per molto tempo, quindi cerca di vedere qual è il tipo di attesa del thread che non mostra CXPACKET (usando il mio script sopra) e risolvi i problemi in modo appropriato. Ciò può verificarsi anche a causa di una distribuzione distorta del lavoro tra i thread e approfondirò questo caso nel prossimo post qui (è causato da statistiche non aggiornate e altri problemi di stima della cardinalità).
Si noti che in SQL Server 2016 SP2 e SQL Server 2017 RTM CU3, i thread consumer non registrano più le attese di CXPACKET. Registrano le attese di CXCONSUMER, che sono benigne e possono essere ignorate. Questo serve a ridurre il numero di attese CXPACKET generate e le restanti hanno maggiori probabilità di essere attuabili.
Parallelismo imprevisto?
Dato che CXPACKET significa semplicemente che si sta verificando il parallelismo, la prima cosa da guardare è se ti aspetti il parallelismo per la query che lo sta utilizzando. La mia query ti fornirà l'ID del nodo del piano di query in cui si verifica il parallelismo (estrae l'ID del nodo dal piano di query XML se il tipo di attesa del thread è CXPACKET) quindi cerca quell'ID nodo e determina se il parallelismo ha senso .
Uno dei casi comuni di parallelismo imprevisto è quando si verifica una scansione della tabella in cui ti aspetti una ricerca o una scansione dell'indice più piccole. Lo vedrai nel piano di query o vedrai molte attese PAGEIOLATCH_SH (discusse in dettaglio qui) insieme alle attese CXPACKET (un classico modello di statistiche di attesa a cui prestare attenzione). Esistono diverse cause di scansioni di tabelle impreviste, tra cui:
- Manca l'indice non cluster, quindi una scansione della tabella è l'unica alternativa
- Statistiche non aggiornate, quindi Query Optimizer ritiene che la scansione di una tabella sia il miglior metodo di accesso ai dati da utilizzare
- Una conversione implicita, a causa di una mancata corrispondenza del tipo di dati tra una colonna della tabella e una variabile o parametro, il che significa che non è possibile utilizzare un indice non cluster
- L'aritmetica viene eseguita su una colonna della tabella anziché su una variabile o un parametro, il che significa che non è possibile utilizzare un indice non cluster
In tutti questi casi, la soluzione è dettata da quale sia la causa principale.
Ma cosa succede se non esiste un caso principale evidente e la query è considerata abbastanza costosa da giustificare un piano parallelo?
Prevenire il parallelismo
Tra le altre cose, Query Optimizer decide di produrre un piano di query parallele se il piano seriale ha un costo superiore alla cost threshold for parallelism , un'impostazione sp_configure per l'istanza. La soglia di costo per il parallelismo (o CTFP) è impostata su cinque per impostazione predefinita, il che significa che un piano non deve essere molto costoso per attivare la creazione di un piano parallelo.
Uno dei modi più semplici per prevenire il parallelismo indesiderato è aumentare il CTFP a un numero molto più alto, con maggiore è impostato, meno è probabile che vengano creati piani paralleli. Alcune persone consigliano di impostare CTFP tra 25 e 50, ma come per tutte le impostazioni modificabili, è meglio testare vari valori e vedere cosa funziona meglio per il tuo ambiente. Se desideri un metodo un po' più programmatico per aiutarti a scegliere un buon valore CTFP, Jonathan ha scritto un post sul blog che mostra una query per analizzare la cache del piano e produrre un valore suggerito per CTFP. A titolo di esempio, abbiamo un client con CTFP impostato su 200 e un altro impostato sul massimo, 32767, per impedire con la forza qualsiasi parallelismo.
Potresti chiederti perché il secondo client ha dovuto usare CTFP come metodo di mazza per prevenire il parallelismo quando penseresti che potrebbero semplicemente impostare il "grado massimo di parallelismo" del server (o MAXDOP) su 1. Bene, chiunque abbia qualsiasi livello di autorizzazione può specificare un suggerimento MAXDOP per la query e sovrascrivere l'impostazione MAXDOP del server, ma non è possibile sovrascrivere CTFP.
E questo è un altro metodo per limitare il parallelismo:impostare un suggerimento MAXDOP sulla query che non vuoi andare in parallelo.
Potresti anche abbassare l'impostazione MAXDOP del server, ma questa è una soluzione drastica in quanto può impedire a tutto di utilizzare il parallelismo. Al giorno d'oggi è comune per i server avere carichi di lavoro misti, ad esempio con alcune query OLTP e alcune query di reporting. Se abbassi il MAXDOP del server, rallenterai le prestazioni delle query di reporting.
Una soluzione migliore quando c'è un carico di lavoro misto sarebbe usare CTFP come ho descritto sopra o utilizzare Resource Governor (che è solo Enterprise, temo). Puoi utilizzare Resource Governor per separare i carichi di lavoro in gruppi di carichi di lavoro, quindi impostare un MAX_DOP (il carattere di sottolineatura non è un errore di battitura) per ciascun gruppo di carichi di lavoro. E l'aspetto positivo dell'utilizzo di Resource Governor è che MAX_DOP non può essere sovrascritto da un suggerimento per la query MAXDOP.
Riepilogo
Non cadere nella trappola di pensare che CXPACKET attenda automaticamente significa che si sta verificando un pessimo parallelismo e di certo non seguire alcuni dei consigli su Internet che ho visto di sbattere il server impostando MAXDOP su 1. Prenditi il tempo per indagare sul motivo per cui vedi CXPACKET attese e se si tratta di qualcosa da affrontare o solo un artefatto di un carico di lavoro che funziona correttamente.
Per quanto riguarda le statistiche generali sull'attesa, puoi trovare ulteriori informazioni sull'utilizzo per la risoluzione dei problemi relativi alle prestazioni in:
- Le mie serie di post sul blog SQLskills, a partire dalle statistiche di attesa, o per favore dimmi dove fa male
- La mia libreria Tipi di attesa e classi Latch qui
- Corso di formazione online My Pluralsight SQL Server:risoluzione dei problemi relativi alle prestazioni utilizzando le statistiche di attesa
- Consigliere prestazioni SQL Sentry
Nel prossimo articolo della serie, parlerò del parallelismo distorto e ti darò un modo semplice per vederlo accadere. Fino ad allora, buona risoluzione dei problemi!