Quando SQL Server 2012 era ancora in versione beta, ho scritto sul nuovo blog FORMAT() funzione:SQL Server v.Next (Denali):CTP3 Miglioramenti T-SQL:FORMAT().
A quel tempo, ero così entusiasta della nuova funzionalità che non pensavo nemmeno di fare alcun test delle prestazioni. L'ho affrontato in un post sul blog più recente, ma esclusivamente nel contesto dell'eliminazione del tempo da un datetime:Ritagliare il tempo da datetime:un follow-up.
La scorsa settimana, il mio buon amico Jason Horner (blog | @jasonhorner) mi ha trollato con questi tweet:
| |
Il mio problema con questo è solo che FORMAT() sembra conveniente, ma è estremamente inefficiente rispetto ad altri approcci (oh e quel AS VARCHAR anche la cosa è brutta). Se stai facendo questo onesy-twosy e per piccoli set di risultati, non me ne preoccuperei troppo; ma su larga scala, può diventare piuttosto costoso. Lasciatemi illustrare con un esempio. Per prima cosa, creiamo una piccola tabella con 1000 date pseudocasuali:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Ora, riempiamo la cache con i dati di questa tabella e illustriamo tre dei modi comuni in cui le persone tendono a presentare solo il tempo:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Ora, eseguiamo singole query che utilizzano queste diverse tecniche. Li eseguiremo ogni 5 volte ed eseguiremo le seguenti varianti:
- Selezione di tutte le 1.000 righe
- Selezionare TOP (1) ordinato in base alla chiave dell'indice cluster
- Assegnazione a una variabile (che forza una scansione completa, ma impedisce al rendering SSMS di interferire con le prestazioni)
Ecco lo script:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Ora possiamo misurare le prestazioni con la seguente query (il mio sistema è abbastanza silenzioso; sul tuo potrebbe essere necessario eseguire un filtraggio più avanzato rispetto al semplice execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
I risultati nel mio caso sono stati abbastanza coerenti:
| Query (troncata) | Durata (microsecondi) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| SELEZIONARE 1.000 righe | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time output (clicca per ingrandire):
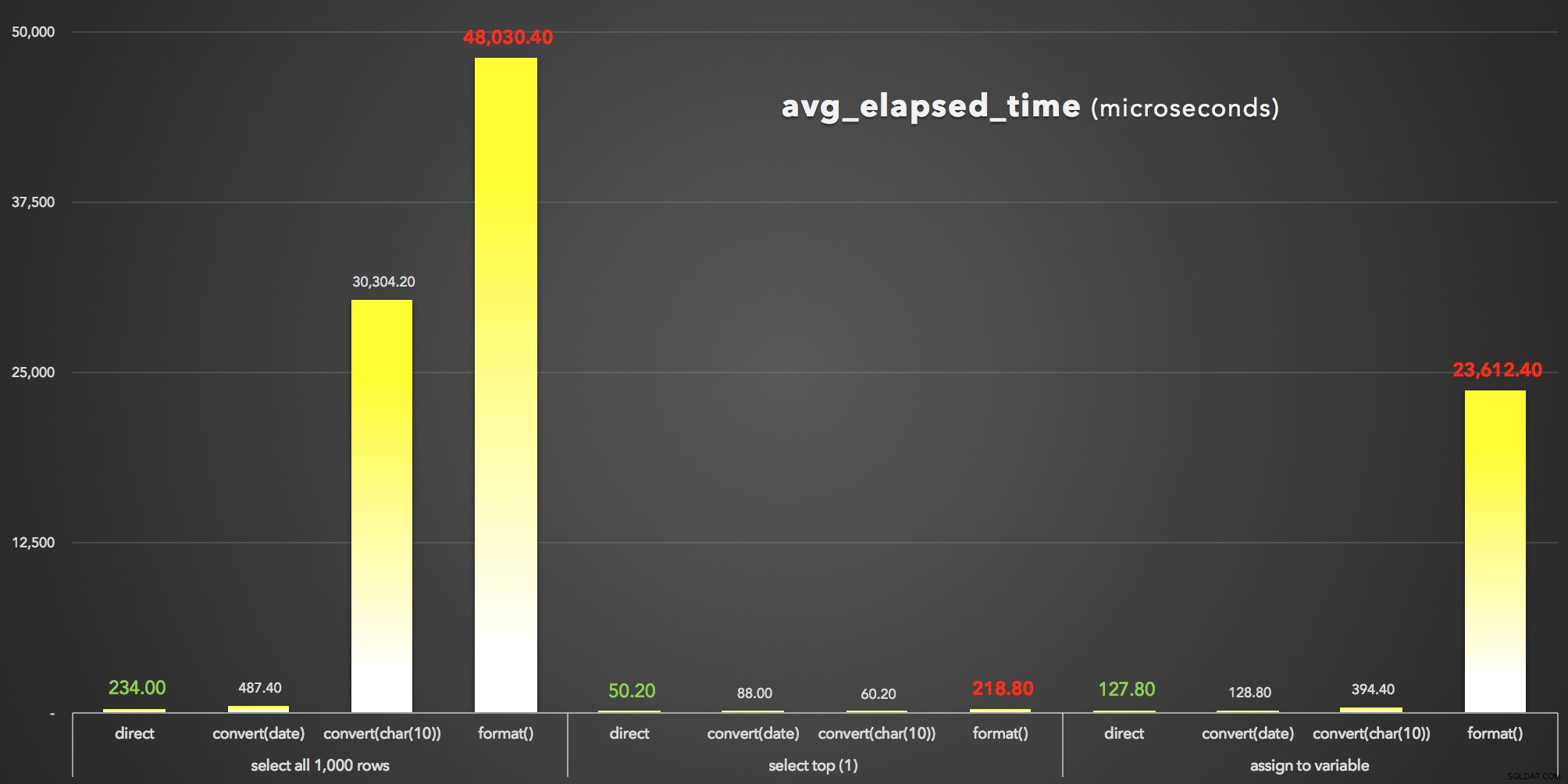 FORMAT() è chiaramente il perdente:avg_elapsed_time results (microsecondi)
FORMAT() è chiaramente il perdente:avg_elapsed_time results (microsecondi)
Cosa possiamo imparare da questi risultati (di nuovo):
- In primo luogo,
FORMAT()è costoso . FORMAT()può, certamente, fornire maggiore flessibilità e fornire metodi più intuitivi coerenti con quelli in altri linguaggi come C#. Tuttavia, oltre al suo sovraccarico, e whileCONVERT()i numeri di stile sono criptici e meno esaustivi, potresti dover comunque utilizzare l'approccio precedente, poichéFORMAT()è valido solo in SQL Server 2012 e versioni successive.- Anche lo standby
CONVERT()il metodo può essere drasticamente costoso (anche se solo gravemente nel caso in cui SSMS dovesse eseguire il rendering dei risultati - gestisce chiaramente le stringhe in modo diverso dai valori di data). - È sempre stato più efficiente estrarre il valore datetime direttamente dal database. Dovresti profilare il tempo aggiuntivo necessario alla tua applicazione per formattare la data come desiderato al livello di presentazione:è molto probabile che non vorrai affatto che SQL Server sia coinvolto con il formato grazioso (e infatti molti sosterrebbero che è qui che appartiene sempre quella logica).
Stiamo parlando solo di microsecondi qui, ma stiamo anche parlando solo di 1.000 righe. Ridimensionalo in base alle dimensioni effettive della tabella e l'impatto della scelta dell'approccio di formattazione errato potrebbe essere devastante.
Se vuoi provare questo esperimento sulla tua macchina, ho caricato uno script di esempio:FormatIsNiceAndAllBut.sql_.zip