Ho scritto in precedenza sulla proprietà di lettura delle righe effettive. Ti dice quante righe vengono effettivamente lette da una ricerca indice, in modo da poter vedere quanto sia selettivo il predicato di ricerca, rispetto alla selettività del predicato di ricerca più predicato residuo combinati.
Ma diamo un'occhiata a cosa sta effettivamente succedendo all'interno dell'operatore Seek. Perché non sono convinto che "Righe effettive lette" sia necessariamente una descrizione accurata di ciò che sta accadendo.
Voglio guardare un esempio che interroga indirizzi di particolari tipi di indirizzi per un cliente, ma il principio qui si applicherebbe facilmente a molte altre situazioni se la forma della tua query si adatta, come cercare gli attributi in una tabella di coppia chiave-valore, per esempio.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
So di non averti mostrato nulla sui metadati:tornerò su questo tra un minuto. Pensiamo a questa query e al tipo di indice che vorremmo avere per essa.
In primo luogo, conosciamo esattamente il CustomerID. Una corrispondenza di uguaglianza come questa generalmente lo rende un ottimo candidato per la prima colonna in un indice. Se avessimo un indice su questa colonna, potremmo entrare direttamente negli indirizzi di quel cliente, quindi direi che è un presupposto sicuro.
La prossima cosa da considerare è quel filtro su AddressTypeID. Aggiungere una seconda colonna alle chiavi del nostro indice è perfettamente ragionevole, quindi facciamolo. Il nostro indice è ora attivo (CustomerID, AddressTypeID). E INCLUDE anche FullAddress, in modo da non dover eseguire ricerche per completare l'immagine.
E penso che abbiamo finito. Dovremmo essere in grado di presumere con sicurezza che l'indice ideale per questa query sia:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Potremmo potenzialmente dichiararlo come un indice univoco:ne esamineremo l'impatto in seguito.
Quindi creiamo una tabella (sto usando tempdb, perché non ho bisogno che persista oltre questo post del blog) e testiamola.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Non mi interessano i vincoli di chiave esterna o quali altre colonne potrebbero esserci. Mi interessa solo il mio Indice Ideale. Quindi crea anche quello, se non l'hai già fatto.
Il mio piano sembra perfetto.
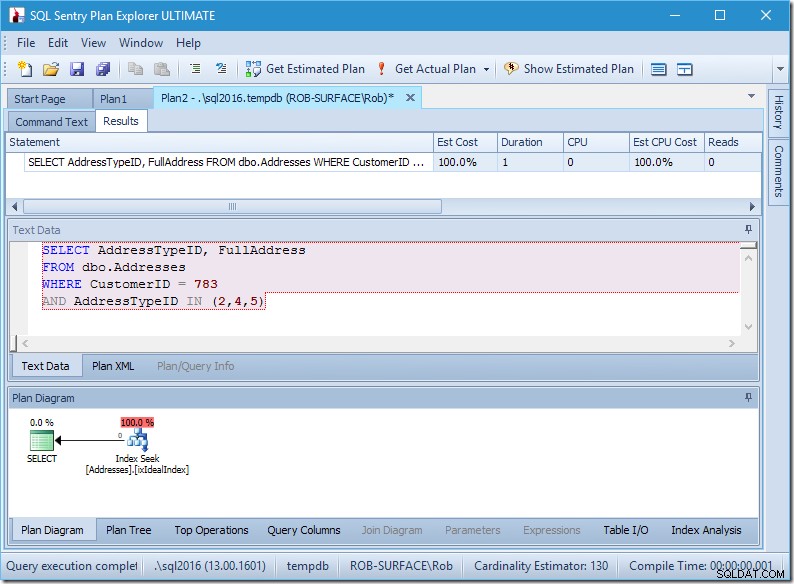
Ho un indice di ricerca, e basta.
Certo, non ci sono dati, quindi non ci sono letture, né CPU e funziona anche abbastanza rapidamente. Se solo tutte le query potessero essere ottimizzate in questo modo.
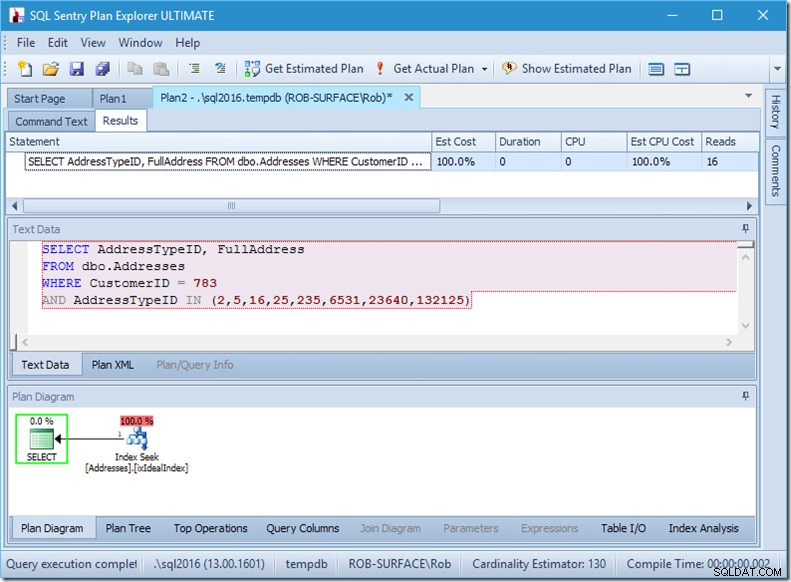
Vediamo cosa sta succedendo un po' più da vicino, osservando le proprietà del Seek.
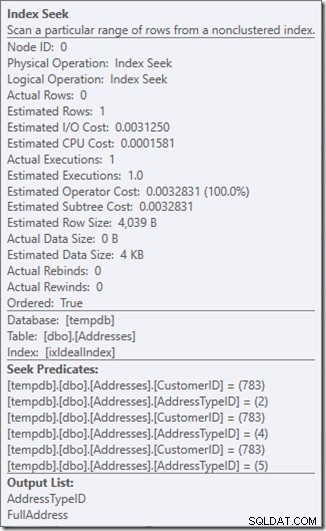
Possiamo vedere i Predicati di ricerca. Ce ne sono sei. Tre su CustomerID e tre su AddressTypeID. Quello che abbiamo in realtà qui sono tre insiemi di predicati di ricerca, che indicano tre operazioni di ricerca all'interno del singolo operatore Seek. La prima ricerca cerca Customer 783 e AddressType 2. La seconda cerca 783 e 4 e gli ultimi 783 e 5. Il nostro operatore Seek è apparso una volta, ma al suo interno c'erano tre ricerche in corso.
Non abbiamo nemmeno dati, ma possiamo vedere come verrà utilizzato il nostro indice.
Inseriamo alcuni dati fittizi, in modo da poter esaminare parte dell'impatto di questo. Inserirò gli indirizzi per i tipi da 1 a 6. Ogni cliente (oltre 2000, in base alla dimensione di master..spt_values ) avrà un indirizzo di tipo 1. Forse quello è l'indirizzo principale. Lascio che l'80% abbia un indirizzo di tipo 2, il 60% un tipo 3 e così via, fino al 20% per il tipo 5. La riga 783 riceverà indirizzi di tipo 1, 2, 3 e 4, ma non 5. Avrei preferito utilizzare valori casuali, ma voglio assicurarmi che siamo sulla stessa pagina per gli esempi.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Ora diamo un'occhiata alla nostra query con i dati. Stanno uscendo due file. È come prima, ma ora vediamo le due righe che escono dall'operatore Seek e vediamo sei letture (in alto a destra).
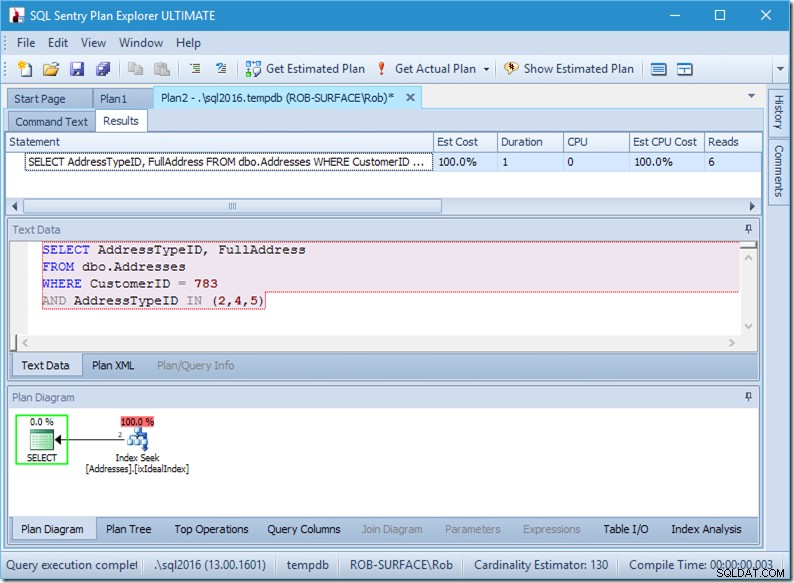
Sei letture hanno senso per me. Abbiamo un tavolino e l'indice si adatta solo a due livelli. Stiamo facendo tre ricerche (all'interno del nostro unico operatore), quindi il motore sta leggendo la pagina principale, scoprendo a quale pagina andare e leggendola, e lo fa tre volte.
Se dovessimo cercare solo due AddressTypeID, vedremmo solo 4 letture (e in questo caso, viene emessa una singola riga). Eccellente.
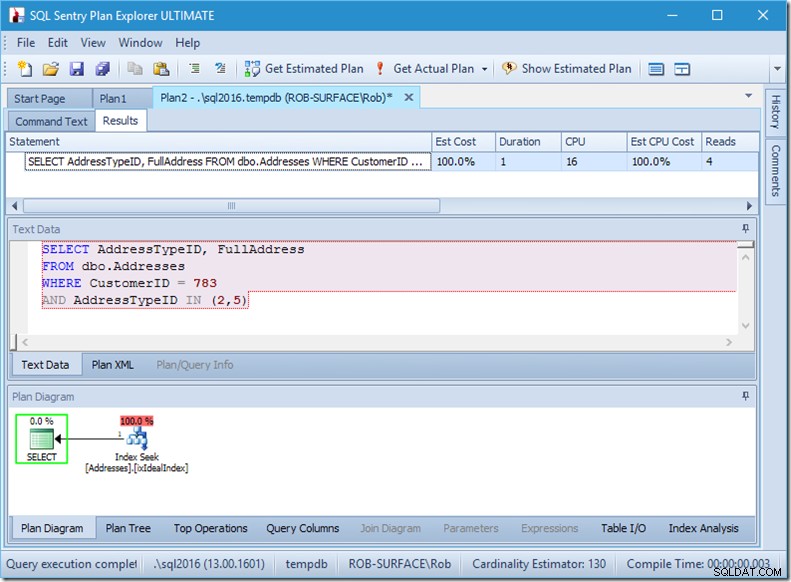
E se cercassimo 8 tipi di indirizzi, ne vedremmo 16.
Eppure ognuno di questi mostra che le righe effettive lette corrispondono esattamente alle righe effettive. Nessuna inefficienza!
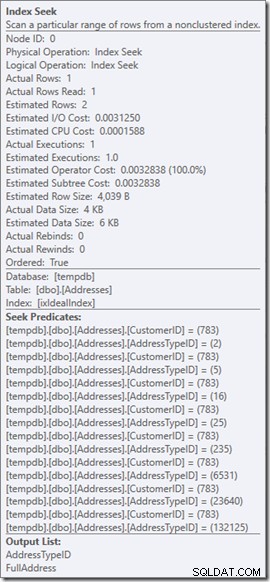
Torniamo alla nostra query originale, cercando i tipi di indirizzo 2, 4 e 5 (che restituisce 2 righe) e pensiamo a cosa sta succedendo all'interno della ricerca.
Presumo che il motore di query abbia già fatto il lavoro per capire che Index Seek è l'operazione giusta e che ha il numero di pagina della radice dell'indice a portata di mano.
A questo punto, carica quella pagina in memoria, se non è già presente. Questa è la prima lettura che viene conteggiata nell'esecuzione della ricerca. Quindi individua il numero di pagina per la riga che sta cercando e legge quella pagina. Questa è la seconda lettura.
Ma spesso sorvoliamo sul fatto che il bit "individua il numero di pagina".
Utilizzando DBCC IND(2, N'dbo.Address', 2); (il primo 2 è l'id del database perché sto usando tempdb; il secondo 2 è l'ID indice di ixIdealIndex ), posso scoprire che il 712 nel file 1 è la pagina con il più alto IndexLevel. Nello screenshot qui sotto, posso vedere che la pagina 668 è IndexLevel 0, che è la pagina principale.

Quindi ora posso usare DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); per vedere il contenuto di pagina 712. Sulla mia macchina, ottengo 84 righe di ritorno e posso dire che CustomerID 783 sarà a pagina 1004 del file 5.
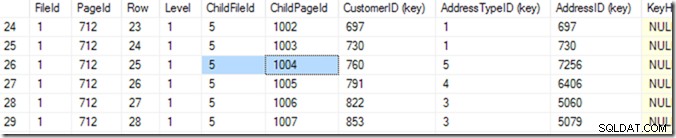
Ma lo so scorrendo la mia lista finché non vedo quello che voglio. Ho iniziato scorrendo un po' verso il basso e poi sono tornato su, finché non ho trovato la riga che volevo. Un computer la chiama ricerca binaria ed è un po' più precisa di me. Sta cercando la riga in cui la combinazione (CustomerID, AddressTypeID) è più piccola di quella che sto cercando, con la pagina successiva più grande o uguale a quella. Dico “uguale” perché potrebbero essercene due che corrispondono, distribuite su due pagine. Sa che ci sono 84 righe (da 0 a 83) di dati in quella pagina (lo legge nell'intestazione della pagina), quindi inizierà controllando la riga 41. Da lì, sa in quale metà cercare e (in questo esempio), leggerà la riga 20. Alcune letture in più (facendo 6 o 7 in totale)* e sa che la riga 25 (guarda la colonna chiamata 'Riga' per questo valore, non il numero di riga fornito da SSMS ) è troppo piccola, ma la riga 26 è troppo grande, quindi 25 è la risposta!
*In una ricerca binaria, la ricerca può essere leggermente più veloce se si ha fortuna quando divide il blocco in due se non c'è uno slot intermedio ea seconda che lo slot intermedio possa essere eliminato o meno.
Ora può andare a pagina 1004 nel file 5. Usiamo DBCC PAGE su quello.
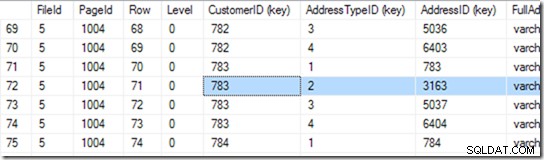
Questo mi dà 94 righe. Esegue un'altra ricerca binaria per trovare l'inizio dell'intervallo che sta cercando. Deve cercare attraverso 6 o 7 righe per trovarlo.
"Inizio della gamma?" Posso sentirti chiedere. Ma stiamo cercando l'indirizzo di tipo 2 del cliente 783.
Esatto, ma non abbiamo dichiarato questo indice come unico. Quindi potrebbero essercene due. Se è univoco, la ricerca può eseguire una ricerca singleton e potrebbe imbattersi in essa durante la ricerca binaria, ma in questo caso deve completare la ricerca binaria per trovare la prima riga nell'intervallo. In questo caso, è la riga 71.
Ma non ci fermiamo qui. Ora dobbiamo vedere se ce n'è davvero un secondo! Quindi legge anche la riga 72 e scopre che la coppia CustomerID+AddressTypeiD è davvero troppo grande e la sua ricerca è terminata.
E questo accade tre volte. La terza volta, non trova una riga per il cliente 783 e l'indirizzo di tipo 5, ma non lo sa in anticipo e deve comunque completare la ricerca.
Quindi le righe effettivamente lette su queste tre ricerche (per trovare due righe da generare) sono molto più del numero restituito. Ce ne sono circa 7 a livello di indice 1 e circa 7 in più a livello di foglia solo per trovare l'inizio dell'intervallo. Quindi legge la riga a cui teniamo e poi la riga successiva. A me suona più come 16, e lo fa tre volte, facendo circa 48 righe.
Ma le righe effettive lette non riguarda il numero di righe effettivamente lette, ma il numero di righe restituite dal predicato di ricerca, che vengono testate rispetto al predicato residuo. E in questo, sono solo le 2 righe che vengono trovate dalle 3 ricerche.
Potresti pensare a questo punto che c'è una certa inefficacia qui. Anche la seconda ricerca avrebbe letto la pagina 712, controllato le stesse 6 o 7 righe lì, quindi avrebbe letto la pagina 1004 e l'avrebbe cercata... come avrebbe fatto la terza ricerca.
Quindi forse sarebbe stato meglio ottenere questo in un'unica ricerca, leggendo pagina 712 e pagina 1004 solo una volta ciascuna. Dopotutto, se lo avessi fatto con un sistema cartaceo, avrei cercato di trovare il cliente 783 e poi avrei scansionato tutti i loro tipi di indirizzo. Perché so che un cliente tende a non avere molti indirizzi. Questo è un vantaggio che ho rispetto al motore di database. Il motore di database sa attraverso le sue statistiche che una ricerca sarà la cosa migliore, ma non sa che la ricerca dovrebbe solo scendere di un livello, quando può dire che ha quello che sembra l'indice ideale.
Se cambio la mia query per acquisire un intervallo di tipi di indirizzi, da 2 a 5, ottengo quasi il comportamento che desidero:
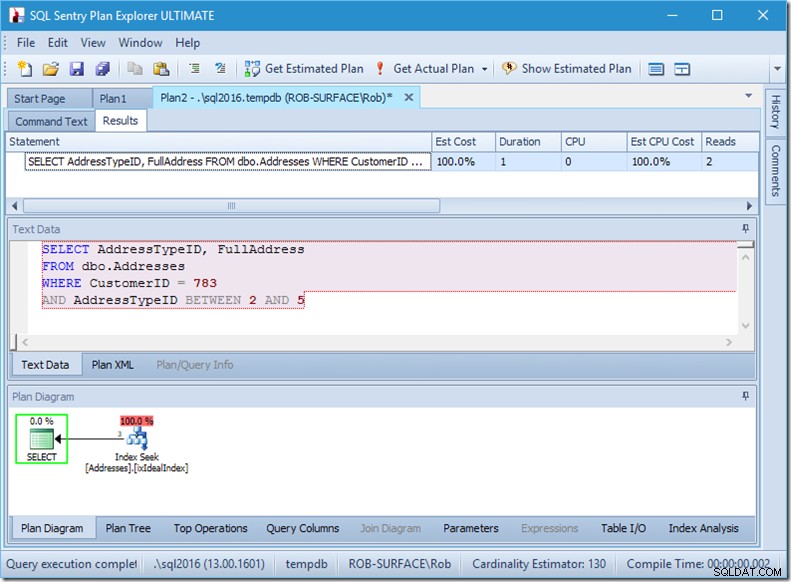
Guarda:le letture sono scese a 2 e so quali pagine sono...
...ma i miei risultati sono sbagliati. Perché voglio solo indirizzi di tipo 2, 4 e 5, non 3. Devo dirgli di non avere 3, ma devo stare attento a come lo faccio. Guarda i prossimi due esempi.
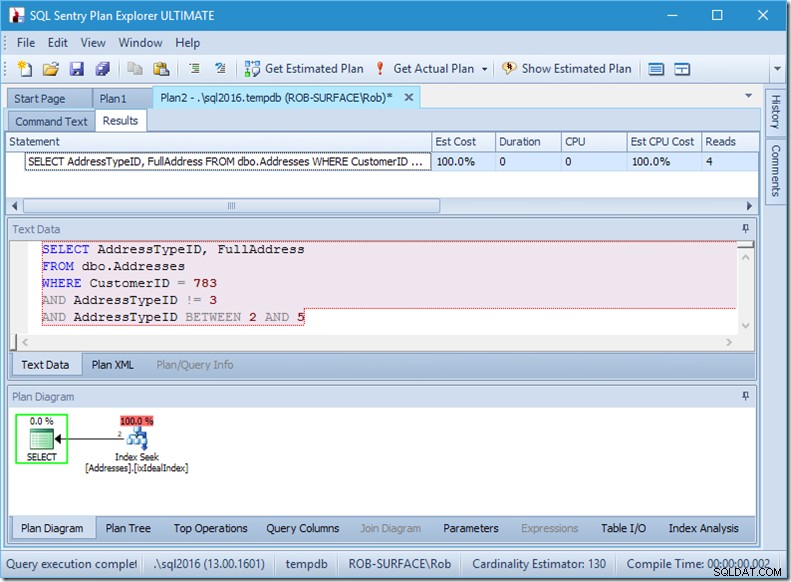
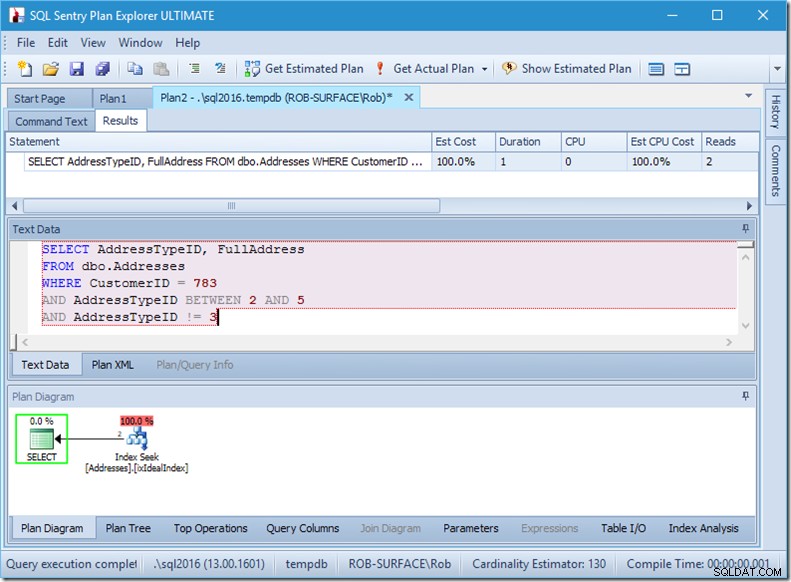
Posso assicurarti che l'ordine dei predicati non ha importanza, ma qui lo è chiaramente. Se mettiamo prima il "non 3", esegue due ricerche (4 letture), ma se mettiamo il secondo "non 3", esegue una sola ricerca (2 letture).
Il problema è che AddressTypeID !=3 viene convertito in (AddressTypeID> 3 OR AddressTypeID <3), che viene quindi visto come due predicati di ricerca molto utili.
Quindi la mia preferenza è usare un predicato non sargable per dirgli che voglio solo i tipi di indirizzi 2, 4 e 5. E posso farlo modificando AddressTypeID in qualche modo, ad esempio aggiungendo zero ad esso.
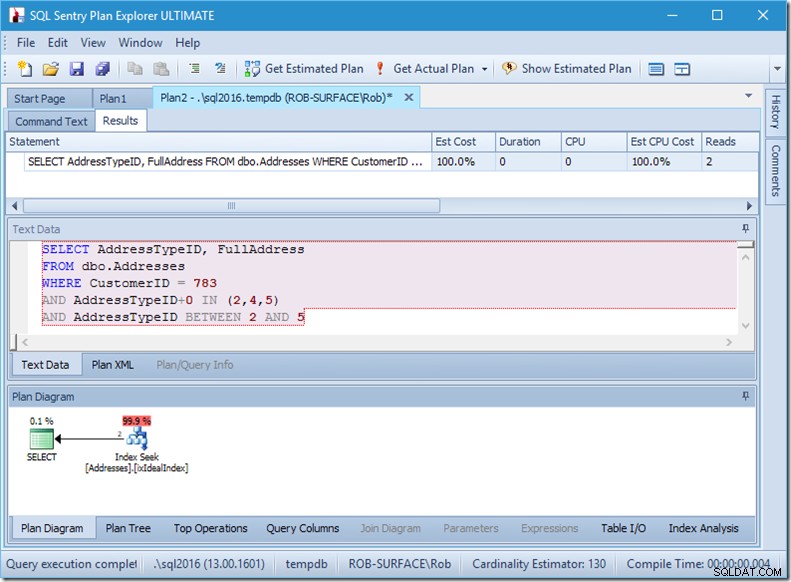
Ora ho una scansione piacevole e ristretta all'interno di una singola ricerca e mi sto ancora assicurando che la mia query restituisca solo le righe che voglio.
Oh, ma quella proprietà Actual Rows Read? Ora è superiore alla proprietà Righe effettive, perché il predicato di ricerca trova il tipo di indirizzo 3, che il predicato residuo rifiuta.
Ho scambiato tre ricerche perfette per una singola ricerca imperfetta, che sto aggiustando con un predicato residuo.
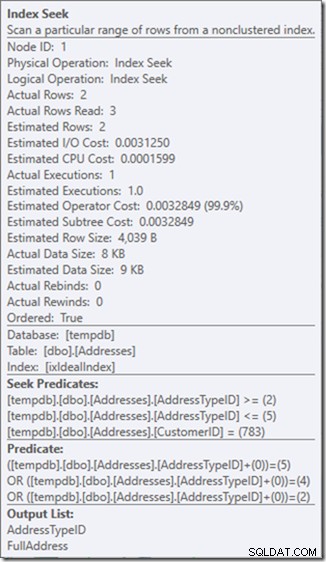
E per me, a volte è un prezzo che vale la pena pagare, procurarmi un piano di query di cui sono molto più felice. Non è molto più economico, anche se ha solo un terzo delle letture (perché ci sarebbero sempre solo due letture fisiche), ma quando penso al lavoro che sta facendo, sono molto più a mio agio con quello che gli sto chiedendo per fare in questo modo.



