Troppo spesso vedo persone che si lamentano di come il loro registro delle transazioni abbia preso il controllo del loro disco rigido. Molte volte si scopre che stavano eseguendo un'operazione di eliminazione di grandi dimensioni, come l'eliminazione o l'archiviazione dei dati, in un'unica transazione di grandi dimensioni.
Volevo eseguire alcuni test per mostrare l'impatto, sia sulla durata che sul registro delle transazioni, dell'esecuzione della stessa operazione sui dati in blocchi rispetto a una singola transazione. Ho creato un database e l'ho popolato con una tabella ampia SalesOrderDetailEnlarged ,
Dopo aver popolato la tabella, ho eseguito il backup del database, il backup del registro ed ho eseguito un DBCC SHRINKFILE (non spararmi) in modo che l'impatto sul file di registro possa essere stabilito da una baseline (sapere bene che queste operazioni *faranno* crescere il registro delle transazioni).
Ho usato di proposito un disco meccanico anziché un SSD. Anche se potremmo iniziare a vedere una tendenza più popolare al passaggio a SSD, non è ancora successo su scala sufficientemente ampia; in molti casi è ancora troppo proibitivo in termini di costi farlo su dispositivi di archiviazione di grandi dimensioni.
Le prove
Quindi poi ho dovuto determinare cosa volevo testare per ottenere il massimo impatto. Dato che proprio ieri sono stato coinvolto in una discussione con un collega sull'eliminazione dei dati in blocchi, ho scelto le eliminazioni. E poiché l'indice cluster su questa tabella è su SalesOrderID , non volevo usarlo – sarebbe troppo facile (e molto raramente corrisponderebbe al modo in cui le eliminazioni vengono gestite nella vita reale). Così ho deciso invece di seguire una serie di ProductID valori, che mi assicurerebbero di raggiungere un numero elevato di pagine e di richiedere molta registrazione. Ho determinato quali prodotti eliminare dalla seguente query:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Ciò ha prodotto i seguenti risultati:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Ciò eliminerebbe 456.960 righe (circa il 10% della tabella), distribuite su molti ordini. Questa non è una modifica realistica in questo contesto, poiché rovinerà i totali degli ordini precalcolati e non puoi davvero rimuovere un prodotto da un ordine che è già stato spedito. Ma usare un database che tutti conosciamo e amiamo, è analogo, diciamo, all'eliminazione di un utente da un forum e anche all'eliminazione di tutti i suoi messaggi:uno scenario reale che ho visto in natura.
Quindi un test sarebbe quello di eseguire la seguente eliminazione in un colpo solo:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
So che questo richiederà una scansione massiccia e avrà un enorme tributo sul registro delle transazioni. Questo è il punto. :-)
Mentre era in esecuzione, ho messo insieme uno script diverso che eseguirà questa eliminazione in blocchi:25.000, 50.000, 75.000 e 100.000 righe alla volta. Ogni blocco verrà eseguito nella propria transazione (in modo che, se è necessario interrompere lo script, è possibile e tutti i blocchi precedenti saranno già salvati, invece di dover ricominciare da capo) e, a seconda del modello di ripristino, verrà seguito tramite un CHECKPOINT o un BACKUP LOG per ridurre al minimo l'impatto continuo sul registro delle transazioni. (Testerò anche senza queste operazioni.) Sembrerà qualcosa del genere (non mi preoccuperò della gestione degli errori e di altre sottigliezze per questo test, ma non dovresti essere così sprezzante):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Ovviamente, dopo ogni test, ripristinerei il backup originale del database WITH REPLACE, RECOVERY , imposta il modello di ripristino di conseguenza ed esegui il test successivo.
I risultati
Il risultato del primo test non è stato affatto sorprendente. Per eseguire l'eliminazione in una singola istruzione, sono stati necessari 42 secondi per intero e 43 secondi in modo semplice. In entrambi i casi il log è cresciuto fino a 579 MB.
La prossima serie di test ha avuto un paio di sorprese per me. Uno è che, mentre questi metodi di chunking hanno ridotto significativamente l'impatto sul file di registro, solo un paio di combinazioni si sono avvicinate alla durata e nessuna è stata effettivamente più veloce. Un altro è che, in generale, il chunking nel ripristino completo (senza eseguire un backup del registro tra i passaggi) ha funzionato meglio delle operazioni equivalenti nel ripristino semplice. Di seguito sono riportati i risultati per durata e impatto sul registro:
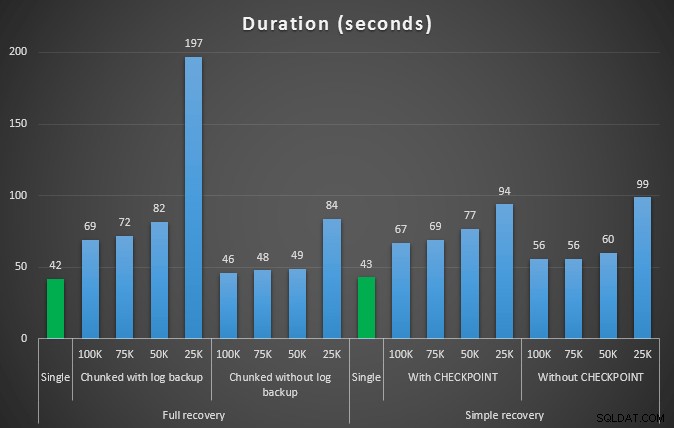
Durata, in secondi, di varie operazioni di eliminazione rimuovendo 457.000 righe
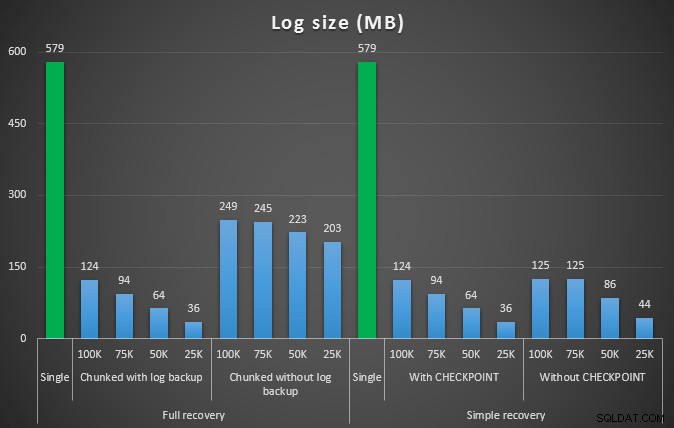
La dimensione del registro, in MB, dopo varie operazioni di eliminazione rimuovendo 457.000 righe
Anche in questo caso, in generale, mentre la dimensione del registro è significativamente ridotta, la durata è aumentata. È possibile utilizzare questo tipo di scala per determinare se è più importante ridurre l'impatto sullo spazio su disco o ridurre al minimo la quantità di tempo trascorso. Per un piccolo colpo di durata (e dopotutto, la maggior parte di questi processi viene eseguita in background), puoi avere un risparmio significativo (fino al 94%, in questi test) nell'utilizzo dello spazio di registro.
Nota che non ho provato nessuno di questi test con la compressione abilitata (possibilmente un test futuro!) e ho lasciato le impostazioni di aumento automatico del registro ai valori predefiniti terribili (10%) - in parte per pigrizia e in parte perché molti ambienti là fuori sono stati mantenuti questa impostazione terribile.
E se avessi più dati?
Successivamente ho pensato di testarlo su un database leggermente più grande. Quindi ho creato un altro database e ho creato una nuova copia più grande di dbo.SalesOrderDetailEnlarged . Circa dieci volte più grande, in effetti. Questa volta invece di una chiave primaria su SalesOrderID, SalesorderDetailID , l'ho appena creato un indice cluster (per consentire i duplicati) e l'ho popolato in questo modo:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); A causa dei limiti di spazio su disco, ho dovuto allontanarmi dalla VM del mio laptop per questo test (e ho scelto una scatola da 40 core, con 128 GB di RAM, che era quasi inattiva :-)), e comunque non è stato affatto un processo rapido. Il popolamento della tabella e la creazione degli indici hanno richiesto circa 24 minuti.
La tabella ha 48,5 milioni di righe e occupa 7,9 GB su disco (4,9 GB di dati e 2,9 GB di indice).
Questa volta, la mia domanda per determinare un buon insieme di ProductID candidati valori da eliminare:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Ha prodotto i seguenti risultati:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Quindi elimineremo 4.455.360 righe, poco meno del 10% della tabella. Seguendo uno schema simile al test precedente, elimineremo tutto in un colpo, quindi in blocchi di 500.000, 250.000 e 100.000 righe.
Risultati:
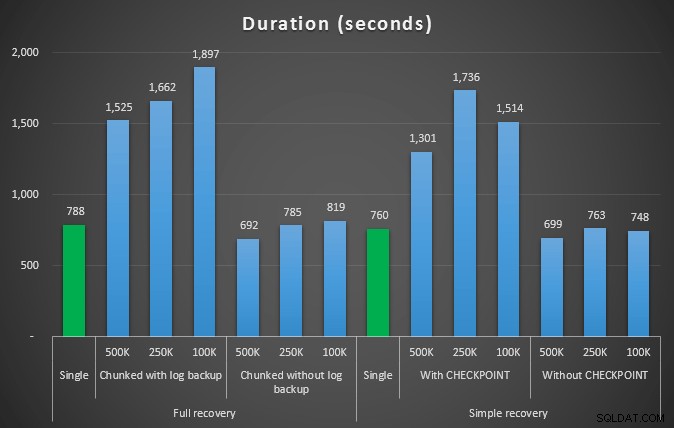 Durata, in secondi, di varie operazioni di eliminazione rimuovendo 4,5 MM di righe
Durata, in secondi, di varie operazioni di eliminazione rimuovendo 4,5 MM di righe
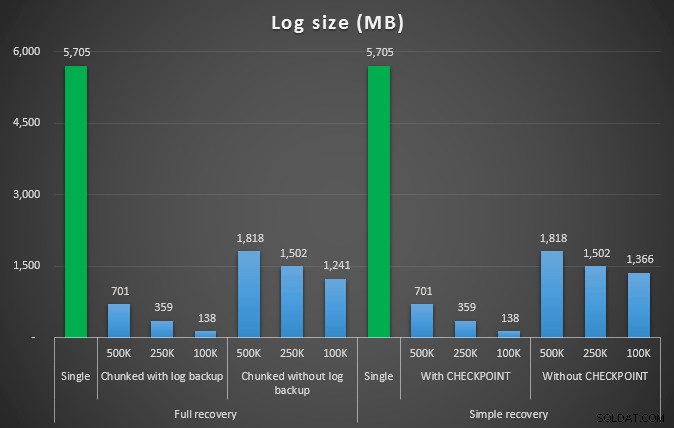 La dimensione del registro, in MB, dopo varie operazioni di eliminazione che hanno rimosso 4,5 MM di righe
La dimensione del registro, in MB, dopo varie operazioni di eliminazione che hanno rimosso 4,5 MM di righe
Quindi, ancora una volta, vediamo una significativa riduzione delle dimensioni del file di registro (oltre il 97% nei casi con la dimensione del blocco più piccola di 100 K); tuttavia, a questa scala, vediamo alcuni casi in cui eseguiamo anche l'eliminazione in meno tempo, anche con tutti gli eventi di crescita automatica che devono essersi verificati. Mi sembra davvero una vittoria per tutti!
Questa volta con un registro più grande
Ora, ero curioso di sapere come si sarebbero confrontate queste diverse eliminazioni con un file di registro predimensionato per adattarsi a operazioni così grandi. Rimanendo con il nostro database più grande, ho pre-espanso il file di registro a 6 GB, ne ho eseguito il backup, quindi ho eseguito di nuovo i test:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Risultati, confrontando la durata con un file di registro fisso al caso in cui il file doveva crescere automaticamente continuamente:
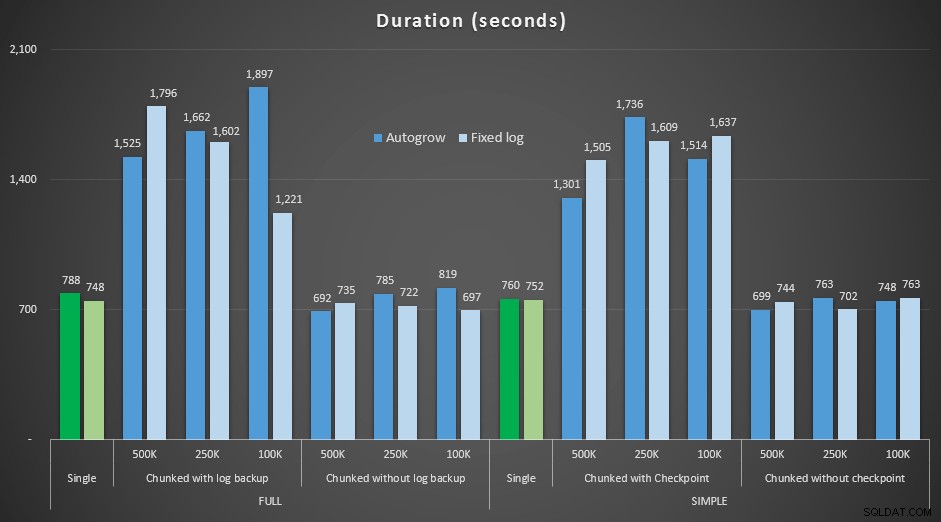
Durata, in secondi, di varie operazioni di eliminazione rimuovendo 4,5 MM di righe , confrontando la dimensione del registro fissa e la crescita automatica
Ancora una volta vediamo che i metodi che eliminano il blocco in batch e *non* eseguono un backup del registro o un checkpoint dopo ogni passaggio, rivaleggiano con la singola operazione equivalente in termini di durata. In effetti, vedi che la maggior parte delle prestazioni effettivamente in meno tempo complessivo, con il bonus aggiuntivo che altre transazioni saranno in grado di entrare e uscire tra i passaggi. Il che è positivo a meno che tu non voglia che questa operazione di eliminazione blocchi tutte le transazioni non correlate.
Conclusione
È chiaro che non esiste una risposta univoca e corretta a questo problema:ci sono molte variabili intrinseche "dipende". Potrebbero essere necessari alcuni esperimenti per trovare il tuo numero magico, poiché ci sarà un equilibrio tra il sovraccarico necessario per eseguire il backup del registro e quanto lavoro e tempo risparmierai con dimensioni di blocchi diverse. Ma se hai intenzione di eliminare o archiviare un gran numero di righe, è molto probabile che, nel complesso, starai meglio eseguendo le modifiche in blocchi, piuttosto che in una, massiccia transazione, anche se i numeri di durata sembrano fare che un'operazione meno attraente. Non si tratta solo di durata:se non si dispone di un file di registro sufficientemente preallocato e non si dispone dello spazio per ospitare una transazione così massiccia, probabilmente è molto meglio ridurre al minimo la crescita del file di registro a scapito della durata, nel qual caso vorrai ignorare i grafici della durata sopra e prestare attenzione ai grafici delle dimensioni del registro.
Se puoi permetterti lo spazio, potresti comunque voler predimensionare il tuo registro delle transazioni di conseguenza. A seconda dello scenario, a volte l'utilizzo delle impostazioni di aumento automatico predefinite è risultato leggermente più veloce nei miei test rispetto all'utilizzo di un file di registro fisso con molto spazio. Inoltre, potrebbe essere difficile indovinare esattamente quanto ti servirà per ospitare una transazione di grandi dimensioni che non hai ancora eseguito. Se non puoi testare uno scenario realistico, fai del tuo meglio per immaginare lo scenario peggiore, quindi, per sicurezza, raddoppialo. Kimberly Tripp (blog | @KimberlyLTripp) ha alcuni ottimi consigli in questo post:8 passaggi per migliorare il throughput del registro delle transazioni:in questo contesto, in particolare, guarda il punto n. 6. Indipendentemente da come decidi di calcolare i tuoi requisiti di spazio di registro, se hai comunque bisogno dello spazio, è meglio prenderlo in modo controllato con largo anticipo, piuttosto che interrompere i tuoi processi aziendali mentre aspettano un aumento automatico ( non importa più!).
Un altro aspetto molto importante di questo che non ho misurato in modo esplicito è l'impatto sulla concorrenza:un mucchio di transazioni più brevi, in teoria, avranno un impatto minore sulle operazioni simultanee. Sebbene una singola eliminazione richiedesse un tempo leggermente inferiore rispetto alle operazioni in batch più lunghe, manteneva tutti i suoi blocchi per l'intera durata, mentre le operazioni in blocchi avrebbero consentito ad altre transazioni in coda di intrufolarsi tra ogni transazione. In un prossimo post cercherò di dare un'occhiata più da vicino a questo impatto (e ho in programma anche altre analisi più approfondite).