Uno dei termini più comuni nelle discussioni sull'ottimizzazione delle prestazioni di SQL Server è wait stats . Questo risale a molto tempo fa, anche prima di questo documento Microsoft del 2006, "SQL Server 2005 Waits and Queues".
Le attese non sono assolutamente tutto e questa metodologia non è l'unico modo per ottimizzare un'istanza, per non parlare di una singola query. In effetti, le attese sono spesso inutili quando tutto ciò che hai è la query che le ha subite e nessun contesto circostante, soprattutto molto tempo dopo il fatto. Questo perché, molto spesso, la cosa su cui una query è in attesa non è colpa di quella query . Come ogni cosa, ci sono delle eccezioni, ma se scegli uno strumento o uno script solo perché offre questa funzionalità molto specifica, penso che ti stai facendo un disservizio. Tendo a seguire un consiglio che Paul Randal mi ha dato tempo fa:
...in genere consiglio di iniziare con le attese dell'intera istanza. Non avrei mai iniziare risoluzione dei problemi osservando le attese delle singole query.
Occasionalmente, sì, potresti voler scavare più a fondo in una singola query e vedere cosa sta aspettando; infatti Microsoft ha recentemente aggiunto statistiche di attesa a livello di query a showplan per aiutare con questa analisi. Ma questi numeri in genere non ti aiuteranno a ottimizzare le prestazioni della tua istanza nel suo insieme, a meno che non ti aiutino a sottolineare qualcosa che incide anche sull'intero carico di lavoro. Se vedi una query di ieri che è stata eseguita per 5 minuti e noti che il suo tipo di attesa era LCK_M_S , cosa hai intenzione di fare adesso? Come rintracciare ciò che stava effettivamente bloccando la query e causando quel tipo di attesa? Potrebbe essere stato causato da una transazione che non si stava impegnando per qualche altro motivo, ma non puoi vederlo se non riesci a vedere lo stato dell'intero sistema e ti stai concentrando solo sulle singole query e sulle attese che hanno subito.
Jason Hall (@SQLSaurus) ha menzionato di sfuggita qualcosa che è stato interessante anche per me. Ha affermato che se le statistiche di attesa a livello di query fossero state una parte così importante degli sforzi di ottimizzazione, questa metodologia sarebbe stata incorporata in Query Store dall'inizio. È stato aggiunto di recente (in SQL Server 2017). Ma non ottieni ancora statistiche di attesa per esecuzione; ottieni medie nel tempo, come le statistiche della query e le statistiche delle procedure che vedi nei DMV. Pertanto, anomalie improvvise potrebbero essere evidenti sulla base di altre metriche acquisite per l'esecuzione della query, ma non sulla media dei tempi di attesa tracciati su tutti esecuzioni. Puoi personalizzare l'intervallo in cui vengono aggregate le attese, ma su sistemi occupati questo potrebbe non essere ancora abbastanza dettagliato per fare ciò che pensi possa fare per te.
Lo scopo di questo post è discutere alcuni dei tipi di attesa più comuni che vediamo nella nostra base di clienti e che tipo di azioni puoi (e non dovresti) intraprendere quando si verificano. Disponiamo di un database di statistiche di attesa anonime che raccogliamo dai nostri clienti Cloud Sync da un po' di tempo e da maggio 2017 mostriamo a tutti come appaiono nella libreria delle attese di SQLskills.
Paul parla del motivo alla base della libreria e anche della nostra integrazione con questo servizio gratuito. Fondamentalmente, cerchi un tipo di attesa che stai sperimentando o di cui sei curioso e lui spiega cosa significa e cosa puoi fare al riguardo. Integriamo queste informazioni qualitative con un grafico che mostra quanto sia prevalente l'attesa attuale nella nostra base di utenti, confrontandola con tutti gli altri tipi di attesa che vediamo, così puoi dire rapidamente se hai a che fare con un tipo di attesa comune o qualcosa di un po' più esotico. (Tieni presente che SQL Sentry non include le attese benigne, in background e in coda che equivalgono a rumore e che la maggior parte degli script là fuori filtra, come WAITFOR o LAZYWRITER_SLEEP:queste non sono semplicemente fonti di problemi di prestazioni.)
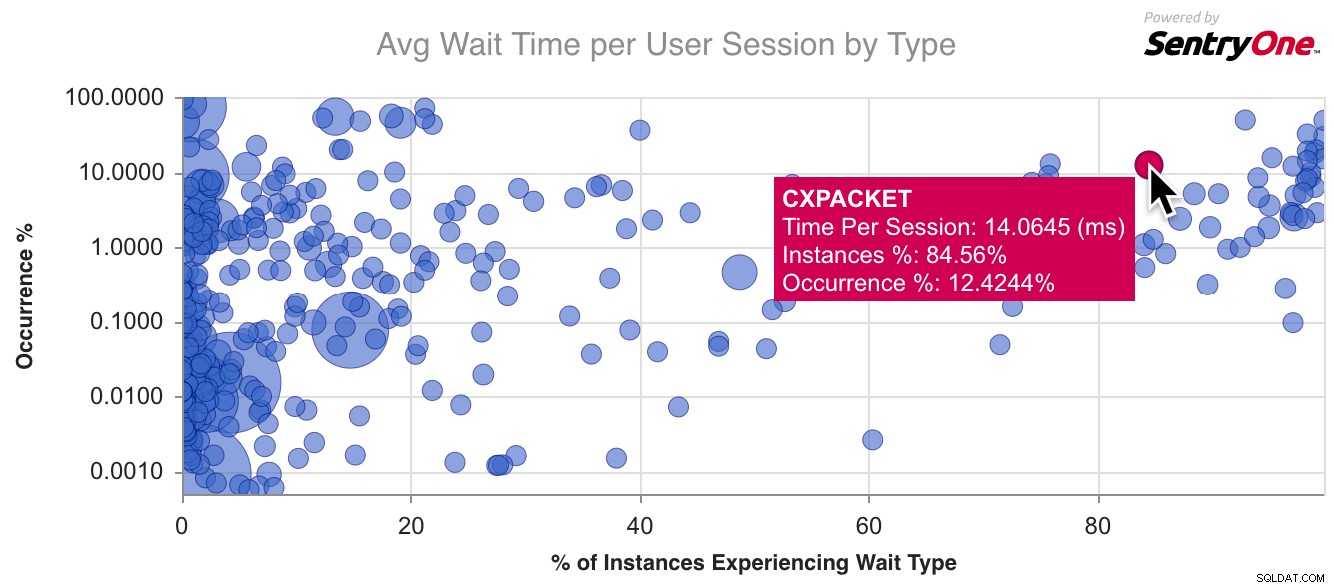
Ecco un grafico di esempio per CXPACKET , il tipo di attesa più comune in circolazione:
Ho iniziato ad andare un po' oltre, mappando alcuni dei tipi di attesa più comuni e annotando alcune delle proprietà che condividevano. Tradotto in domande che un sintonizzatore potrebbe avere su un tipo di attesa che sta riscontrando:
- Il tipo di attesa può essere risolto a livello di query?
- È probabile che il sintomo principale dell'attesa influisca su altre query?
- È probabile che tu abbia bisogno di più informazioni al di fuori del contesto di una singola query e dei tipi di attesa che ha riscontrato per "risolvere" il problema?
Quando ho deciso di scrivere questo post, il mio obiettivo era solo quello di raggruppare i tipi di attesa più comuni e quindi iniziare a prendere appunti su di essi relativi alle domande di cui sopra. Jason ha tirato fuori quelli più comuni dalla libreria, e poi ho disegnato un graffio di pollo su una lavagna, che in seguito ho riordinato un po'. Questa ricerca iniziale ha portato a un discorso che Jason ha tenuto sulla più recente TechOutbound SQL Cruise in Alaska. Sono un po' imbarazzato dal fatto che abbia messo insieme un discorso mesi prima che potessi finire questo post, quindi andiamo avanti. Ecco le principali attese che vediamo (che corrispondono ampiamente al sondaggio di Paul del 2014), le mie risposte alle domande di cui sopra e alcuni commenti su ciascuna:
Per interagire con i link nella tabella sottostante, visita questa pagina su uno schermo più ampio.
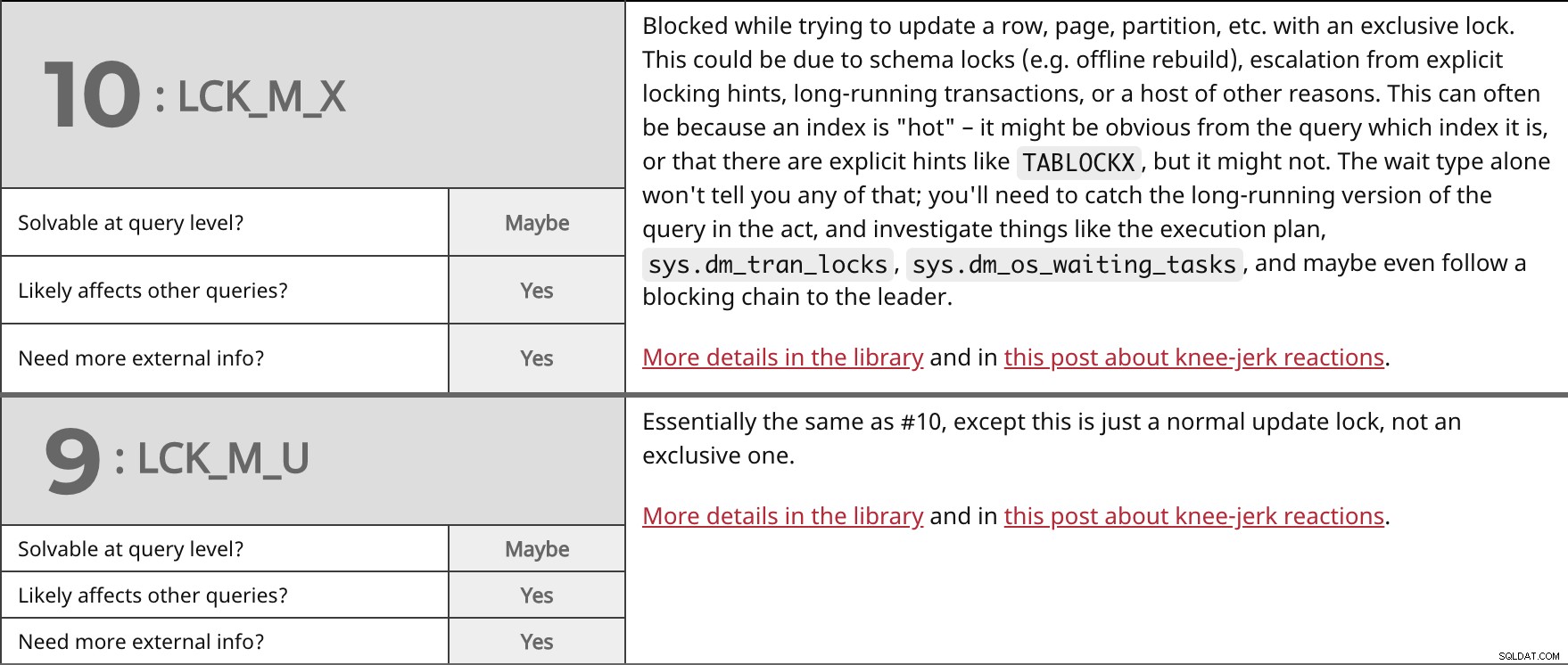
Bloccato durante il tentativo di aggiornare una riga, pagina, partizione, ecc. con un blocco esclusivo. Ciò potrebbe essere dovuto a blocchi dello schema (ad es. ricostruzione offline), escalation da suggerimenti di blocco espliciti, transazioni di lunga durata o una serie di altri motivi. Questo può essere spesso dovuto al fatto che un indice è "caldo" - potrebbe essere ovvio dalla query quale indice sia o che ci siano suggerimenti espliciti come TABLOCKX , ma potrebbe non esserlo. Il solo tipo di attesa non ti dirà nulla di tutto ciò; dovrai cogliere sul fatto la versione di lunga data della query e indagare su cose come il piano di esecuzione, sys.dm_tran_locks , sys.dm_os_waiting_tasks , e magari anche seguire una catena di blocco fino al leader. Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Sì | ||
| Hai bisogno di più informazioni esterne? | Sì | |
|
Essenzialmente uguale a #10, tranne per il fatto che questo è solo un normale blocco di aggiornamento, non esclusivo. Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Sì | ||
| Hai bisogno di più informazioni esterne? | Sì | |
|
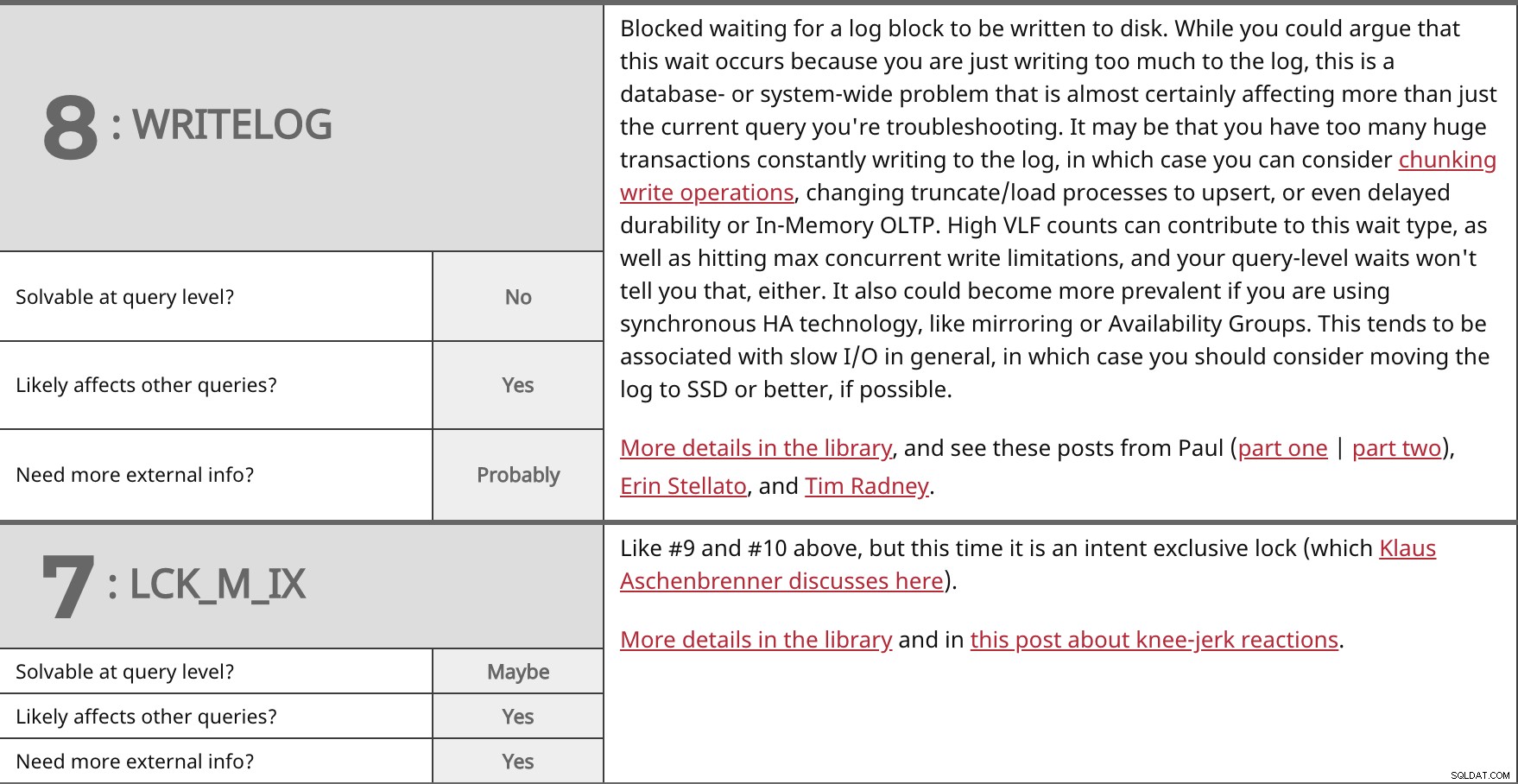
Bloccato in attesa che un blocco di log venga scritto su disco. Sebbene si possa obiettare che questa attesa si verifica perché si sta scrivendo troppo nel registro, si tratta di un problema a livello di database o di sistema che quasi sicuramente interessa più della query corrente che si sta risolvendo. È possibile che tu abbia troppe transazioni enormi che scrivono costantemente nel registro, nel qual caso puoi prendere in considerazione operazioni di scrittura in blocchi, modifica dei processi di troncamento/caricamento per upsert o persino durabilità ritardata o OLTP in memoria. Un numero elevato di VLF può contribuire a questo tipo di attesa, oltre a raggiungere i limiti massimi di scrittura simultanea e nemmeno le attese a livello di query te lo diranno. Potrebbe anche diventare più diffuso se si utilizza la tecnologia HA sincrona, come il mirroring o i gruppi di disponibilità. Questo tende ad essere associato a un I/O lento in generale, nel qual caso dovresti considerare di spostare il registro su SSD o migliore, se possibile. Maggiori dettagli nella libreria e guarda questi post di Paul (prima parte | seconda parte), Erin Stellato e Tim Radney. | ||
| Risolvibile a livello di query? | No | |
| Sì | ||
| Hai bisogno di più informazioni esterne? | Probabilmente | |
|
Come il n. 9 e il n. 10 sopra, ma questa volta è un blocco esclusivo dell'intento (di cui Klaus Aschenbrenner discute qui). Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Sì | ||
| Hai bisogno di più informazioni esterne? | Sì | |
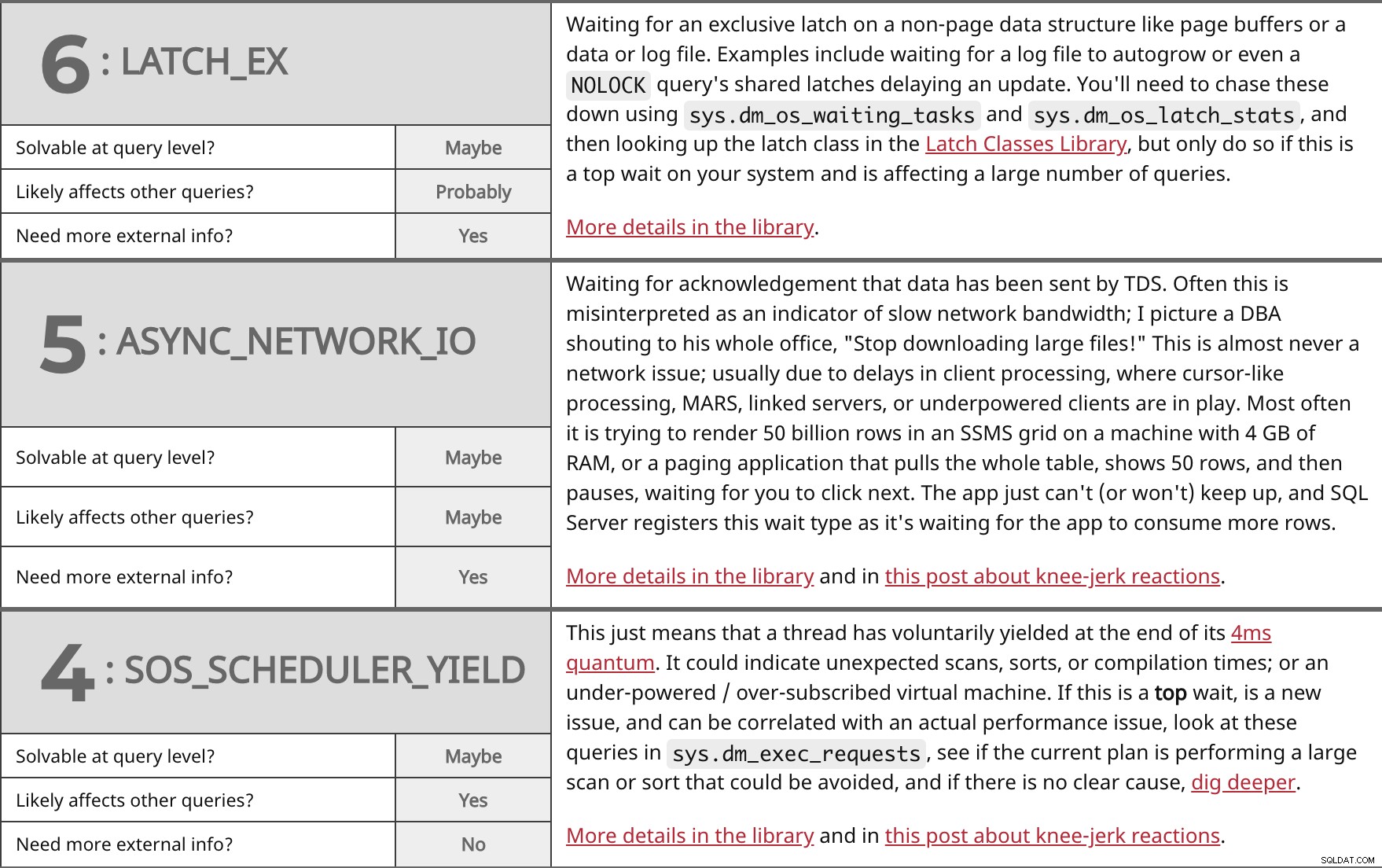
In attesa di un latch esclusivo su una struttura di dati non di pagina come i buffer di pagina o un file di dati o di registro. Gli esempi includono l'attesa che un file di registro cresca automaticamente o anche un NOLOCK i latch condivisi della query ritardano un aggiornamento. Dovrai inseguirli usando sys.dm_os_waiting_tasks e sys.dm_os_latch_stats , e quindi cercare la classe latch nella Libreria classi latch, ma fallo solo se questa è una top wait sul tuo sistema e sta interessando un gran numero di query. Maggiori dettagli in libreria. | ||
| Risolvibile a livello di query? | Forse | |
| Probabilmente | ||
| Hai bisogno di più informazioni esterne? | Sì | |
|
In attesa di conferma che i dati sono stati inviati da TDS. Spesso questo viene interpretato erroneamente come un indicatore di larghezza di banda di rete lenta; Immagino un DBA che grida a tutto il suo ufficio:"Smettila di scaricare file di grandi dimensioni!" Questo non è quasi mai un problema di rete; di solito a causa di ritardi nell'elaborazione del client, in cui sono in gioco l'elaborazione simile a un cursore, MARS, server collegati o client sottodimensionati. Molto spesso sta tentando di eseguire il rendering di 50 miliardi di righe in una griglia SSMS su una macchina con 4 GB di RAM o un'applicazione di paging che estrae l'intera tabella, mostra 50 righe e quindi si ferma, in attesa che tu faccia clic su Avanti. L'app semplicemente non riesce (o non vuole) tenere il passo e SQL Server registra questo tipo di attesa mentre attende che l'app consumi più righe. Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Forse | ||
| Hai bisogno di più informazioni esterne? | Sì | |
Questo significa semplicemente che un thread ha ceduto volontariamente alla fine del suo quantum di 4 ms. Potrebbe indicare scansioni, ordinamenti o tempi di compilazione imprevisti; o una macchina virtuale sottodimensionata/sottoscritta. Se questo è un top wait, è un problema nuovo e può essere correlato a un problema di prestazioni effettivo, guarda queste query in sys.dm_exec_requests , controlla se il piano corrente sta eseguendo una scansione di grandi dimensioni o un ordinamento che potrebbe essere evitato e, se non c'è una causa chiara, approfondisci. Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Sì | ||
| Hai bisogno di più informazioni esterne? | No | |
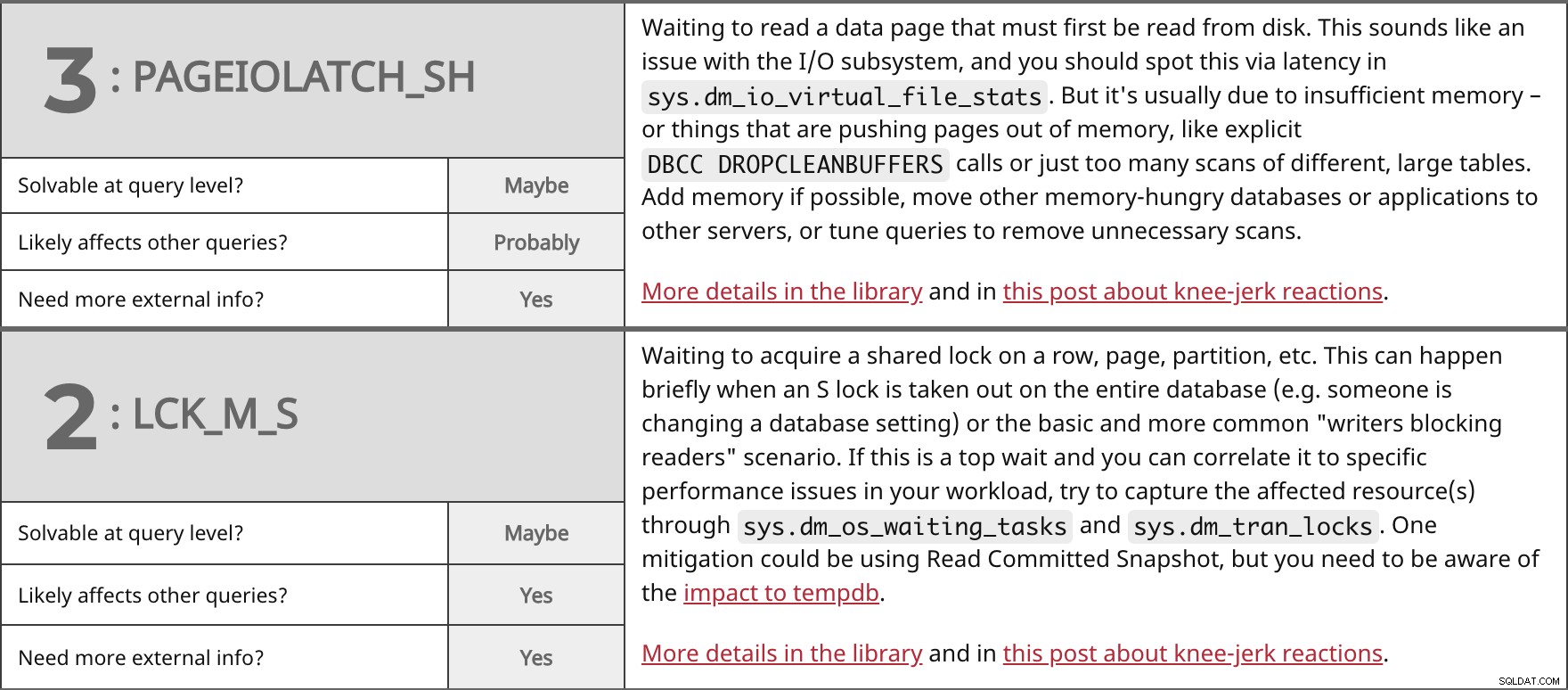
In attesa di leggere una pagina di dati che deve essere prima letta dal disco. Sembra un problema con il sottosistema di I/O e dovresti individuarlo tramite la latenza in sys.dm_io_virtual_file_stats . Ma di solito è dovuto a memoria insufficiente o cose che stanno spingendo le pagine fuori dalla memoria, come esplicito DBCC DROPCLEANBUFFERS chiamate o semplicemente troppe scansioni di tabelle diverse e di grandi dimensioni. Aggiungi memoria se possibile, sposta altri database o applicazioni che richiedono molta memoria su altri server o ottimizza le query per rimuovere scansioni non necessarie. Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Probabilmente | ||
| Hai bisogno di più informazioni esterne? | Sì | |
In attesa di acquisire un blocco condiviso su una riga, pagina, partizione, ecc. Questo può accadere brevemente quando un blocco S viene rimosso dall'intero database (ad es. qualcuno sta cambiando un'impostazione del database) o lo scenario di base e più comune "scrittori che bloccano i lettori". Se si tratta di un'attesa massima e puoi correlarla a problemi di prestazioni specifici nel tuo carico di lavoro, prova ad acquisire le risorse interessate tramite sys.dm_os_waiting_tasks e sys.dm_tran_locks . Una mitigazione potrebbe essere l'utilizzo di Read Committed Snapshot, ma è necessario essere consapevoli dell'impatto su tempdb. Maggiori dettagli in libreria e in questo post sulle reazioni istintive. | ||
| Risolvibile a livello di query? | Forse | |
| Sì | ||
| Hai bisogno di più informazioni esterne? | Sì | |
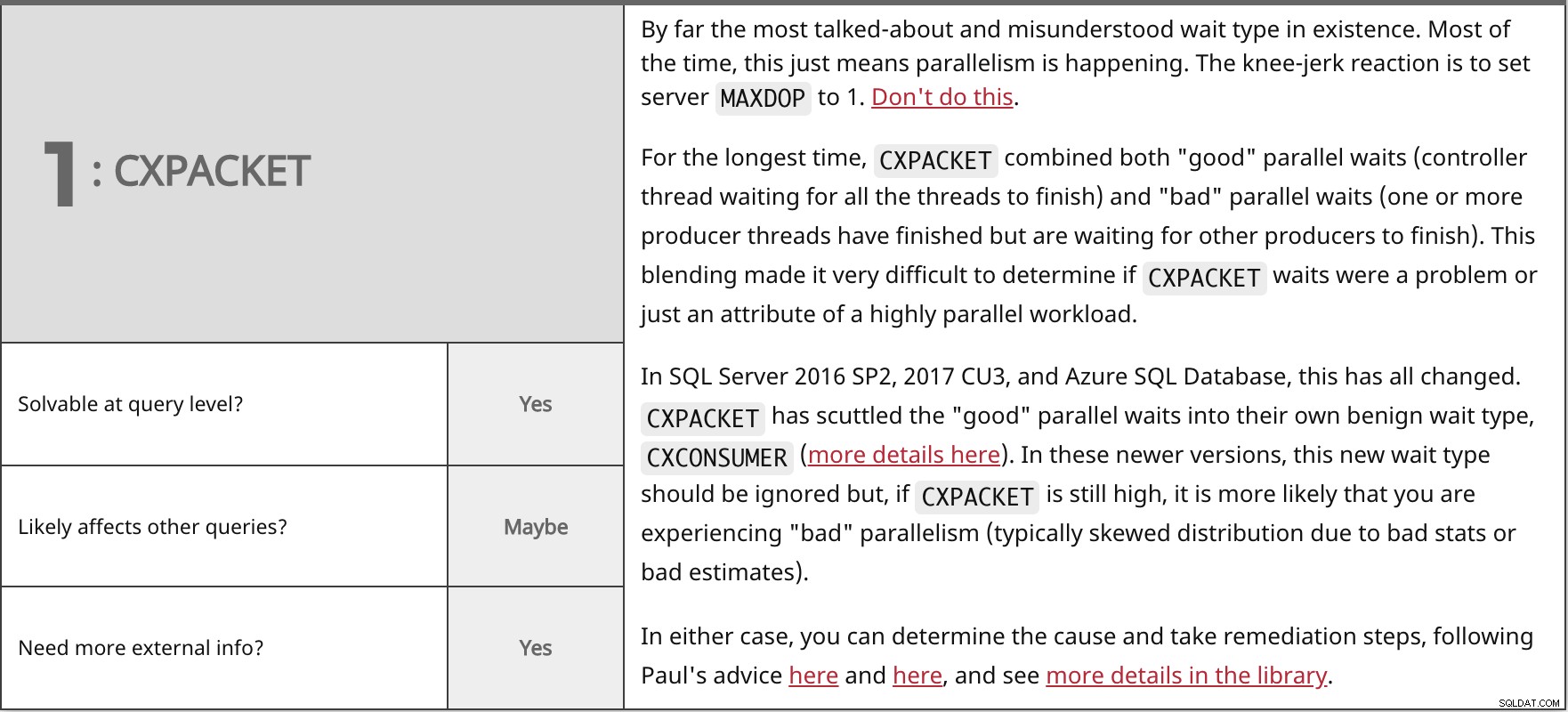
Di gran lunga il tipo di attesa più discusso e frainteso esistente. Il più delle volte, questo significa solo che si sta verificando un parallelismo. La reazione istintiva è di impostare il server MAXDOP a 1. Non farlo.
Per molto tempo,
In SQL Server 2016 SP2, 2017 CU3 e database SQL di Azure, tutto è cambiato. In entrambi i casi, puoi determinare la causa e adottare misure correttive, seguendo i consigli di Paul qui e qui, e vedere maggiori dettagli nella libreria. | ||
| Risolvibile a livello di query? | Sì | |
| Forse | ||
| Hai bisogno di più informazioni esterne? | Sì | |
Riepilogo
Nella maggior parte di questi casi, è meglio esaminare le attese a livello di istanza e concentrarsi solo sulle attese a livello di query durante la risoluzione dei problemi di query specifiche che presentano problemi di prestazioni indipendentemente dal tipo di attesa. Queste sono cose che emergono per altri motivi, come lunga durata, CPU elevata o I/O elevato, e non possono essere spiegate da cose più semplici (come una scansione dell'indice cluster quando ti aspettavi una ricerca).
Anche a livello di istanza, non inseguire ogni attesa che diventa l'attesa principale sul tuo sistema:lo farai SEMPRE aspetta il massimo e non sarai mai in grado di smettere di inseguirlo. Assicurati di ignorare le attese benigne (Paul tiene un elenco) e di preoccuparti solo delle attese che puoi associare a un problema di prestazioni effettivo che stai riscontrando. Se CXPACKET le attese sono alte, e allora? Ci sono altri sintomi oltre al fatto che quel numero è "alto" o si trova in cima alla lista?
Tutto si riduce al motivo per cui stai risolvendo i problemi in primo luogo. Un singolo utente si lamenta di una singola istanza di una query canaglia? Il tuo server è in ginocchio? Qualcosa in mezzo? Nel primo caso, certo, sapere perché una query è lenta può essere utile, ma è piuttosto costoso tenere traccia (non importa tenerlo all'infinito) tutte le attese associate a ogni singola query, tutto il giorno, tutti i giorni, nella strana possibilità che tu voglio tornare e rivederli più tardi. Se si tratta di un problema pervasivo isolato per quella query, dovresti essere in grado di determinare cosa rallenta la query eseguendola di nuovo e raccogliendo il piano di esecuzione, il tempo di compilazione e altre metriche di runtime. Se è successa una cosa una tantum martedì scorso, indipendentemente dal fatto che tu abbia o meno le attese per quella singola istanza della query, potresti non essere in grado di risolvere il problema senza più contesto. Forse c'era un blocco, ma non saprai da cosa, o forse c'è stato un picco di I/O, ma dovrai rintracciare quel problema separatamente. Il tipo wait da solo di solito non fornisce informazioni sufficienti tranne, nella migliore delle ipotesi, un puntatore a qualcos'altro.
Certo, devo guadagnarmi da vivere anche qui. Il nostro prodotto di punta, SQL Sentry, adotta un approccio olistico al monitoraggio. Raccogliamo statistiche di attesa a livello di istanza, le classifichiamo per te e le rappresentiamo graficamente sulla nostra dashboard:
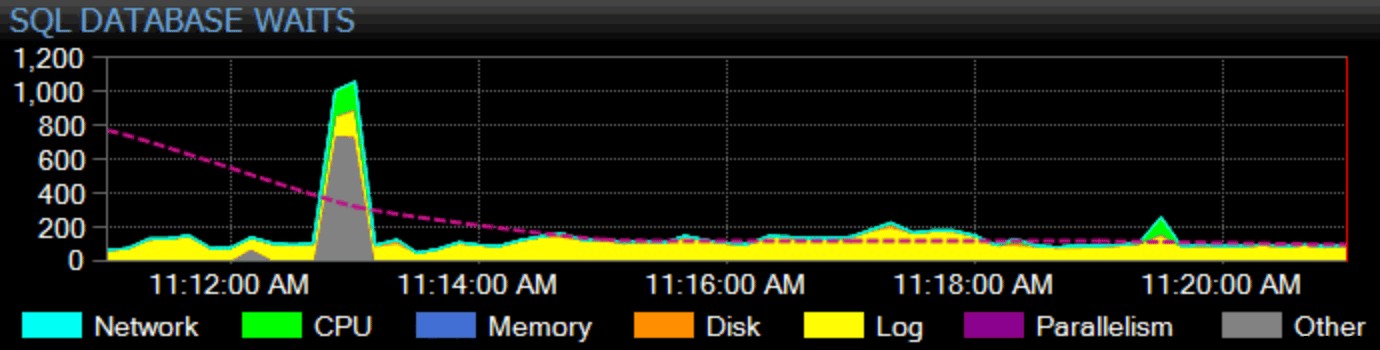
Puoi personalizzare il modo in cui ogni singola attesa viene classificata e se quella categoria viene visualizzata o meno sulla dashboard. Puoi confrontare le statistiche di attesa correnti con linee di base integrate o personalizzate e persino impostare avvisi o azioni quando superano una certa deviazione definita dalla linea di base. E, cosa forse più importante, puoi guardare un punto dati del passato e sincronizzare l'intera dashboard in quel momento, in modo da poter catturare tutto il contesto circostante e qualsiasi altra situazione che potrebbe aver influenzato il problema. Quando trovi elementi più granulari su cui concentrarti, come il blocco, la latenza del disco elevata o le query con I/O elevato o lunga durata, puoi approfondire queste metriche e arrivare alla radice del problema piuttosto rapidamente.
Per ulteriori informazioni su entrambi gli approcci generali alle statistiche di attesa e sulla nostra soluzione in particolare, puoi guardare il white paper di Kevin Kline, Risoluzione dei problemi di SQL Server Wait Stats, e puoi scaricare un webinar in due parti presentato da Paul Randal, Andy Yun (@SQLBek), e Andy Mallon (@AMtwo):
- Parte 1:Risoluzione dei problemi delle prestazioni utilizzando le statistiche di attesa
- Parte 2:Analisi rapida delle statistiche di attesa con SentryOne
E se vuoi dare un giro alla piattaforma SentryOne, puoi iniziare qui con un'offerta a tempo limitato:
Scarica una prova gratuita di 15 giorni