Il mese scorso ho coperto una sfida Isole speciali. Il compito era identificare i periodi di attività per ciascun ID servizio, tollerando un intervallo fino a un numero di secondi di input (@allowedgap ). L'avvertenza era che la soluzione doveva essere compatibile prima del 2012, quindi non era possibile utilizzare funzioni come LAG e LEAD o aggregare le funzioni della finestra con una cornice. Ho ricevuto una serie di soluzioni molto interessanti pubblicate nei commenti di Toby Ovod-Everett, Peter Larsson e Kamil Kosno. Assicurati di esaminare le loro soluzioni poiché sono tutte piuttosto creative.
Curiosamente, alcune soluzioni hanno funzionato più lentamente con l'indice consigliato che senza di esso. In questo articolo vi propongo una spiegazione per questo.
Anche se tutte le soluzioni erano interessanti, qui volevo concentrarmi sulla soluzione di Kamil Kosno, che è uno sviluppatore ETL con Zopa. Nella sua soluzione, Kamil ha utilizzato una tecnica molto creativa per emulare LAG e LEAD senza LAG e LEAD. Probabilmente troverai la tecnica utile se hai bisogno di eseguire calcoli simili a LAG/LEAD usando codice compatibile prima del 2012.
Perché alcune soluzioni sono più veloci senza l'indice consigliato?
Come promemoria, ho suggerito di utilizzare il seguente indice per supportare le soluzioni alla sfida:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
La mia soluzione compatibile prima del 2012 era la seguente:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
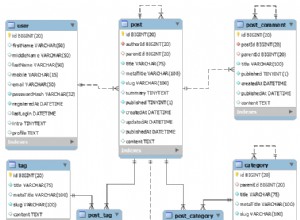
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; La figura 1 mostra il piano per la mia soluzione con l'indice consigliato in atto.
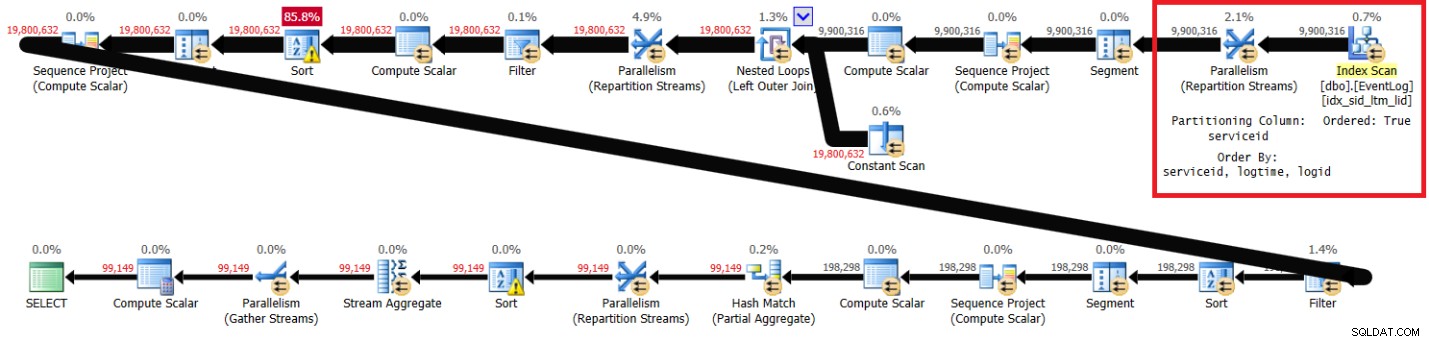 Figura 1:piano per la soluzione di Itzik con indice consigliato
Figura 1:piano per la soluzione di Itzik con indice consigliato
Si noti che il piano esegue la scansione dell'indice consigliato nell'ordine delle chiavi (la proprietà Ordered è True), suddivide i flussi in base a serviceid utilizzando uno scambio di conservazione dell'ordine e quindi applica il calcolo iniziale dei numeri di riga basandosi sull'ordine dell'indice senza la necessità di eseguire l'ordinamento. Di seguito sono riportate le statistiche sulle prestazioni che ho ottenuto per questa esecuzione di query sul mio laptop (tempo trascorso, tempo della CPU e attesa massima espressi in secondi):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
Ho quindi eliminato l'indice consigliato e ho eseguito nuovamente la soluzione:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Ho ottenuto il piano mostrato nella Figura 2.
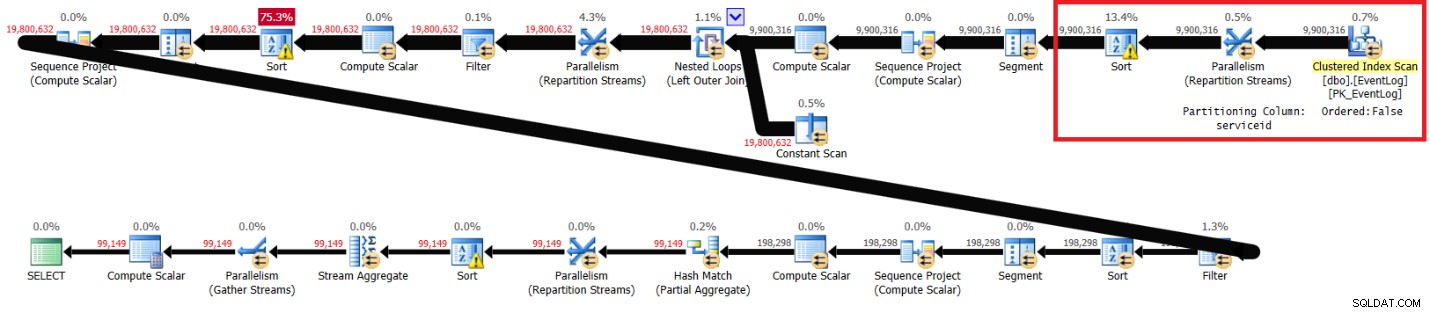 Figura 2:piano per la soluzione di Itzik senza indice consigliato
Figura 2:piano per la soluzione di Itzik senza indice consigliato
Le sezioni evidenziate nei due piani mostrano la differenza. Il piano senza l'indice consigliato esegue un'analisi non ordinata dell'indice cluster, partiziona i flussi per serviceid utilizzando uno scambio non di conservazione dell'ordine, quindi ordina le righe in base alle esigenze della funzione window (per serviceid, logtime, logid). Il resto del lavoro sembra essere lo stesso in entrambi i piani. Penseresti che il piano senza l'indice consigliato dovrebbe essere più lento poiché ha un ordinamento aggiuntivo che l'altro piano non ha. Ma ecco le statistiche sulle prestazioni che ho ottenuto per questo piano sul mio laptop:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
C'è più tempo di CPU coinvolto, che in parte è dovuto all'ordinamento extra; sono coinvolti più I/O, probabilmente a causa di ulteriori sversamenti di ordinamento; tuttavia, il tempo trascorso è circa il 30 percento più veloce. Cosa potrebbe spiegare questo? Un modo per provare a capirlo è eseguire la query in SSMS con l'opzione Statistiche query live abilitata. Quando ho eseguito questa operazione, l'operatore Parallelism (Repartition Streams) più a destra è terminato in 6 secondi senza l'indice consigliato e in 35 secondi con l'indice consigliato. La differenza fondamentale è che il primo ottiene i dati preordinati da un indice ed è uno scambio di conservazione dell'ordine. Quest'ultimo ottiene i dati non ordinati e non è uno scambio di conservazione degli ordini. Gli scambi di conservazione degli ordini tendono ad essere più costosi di quelli che non preservano gli ordini. Inoltre, almeno nella parte più a destra del piano fino al primo ordinamento, il primo fornisce le righe nello stesso ordine della colonna di partizionamento di scambio, quindi non si ottengono tutti i thread per elaborare davvero le righe in parallelo. Il successivo fornisce le righe non ordinate, in modo da ottenere tutti i thread per elaborare le righe veramente in parallelo. Puoi vedere che l'attesa principale in entrambi i piani è CXPACKET, ma nel primo caso il tempo di attesa è doppio rispetto al secondo, dicendoti che la gestione del parallelismo nel secondo caso è più ottimale. Potrebbero esserci altri fattori in gioco a cui non sto pensando. Se hai altre idee che potrebbero spiegare la sorprendente differenza di prestazioni, condividi.
Sul mio laptop ciò ha comportato l'esecuzione senza che l'indice consigliato fosse più veloce di quello con l'indice consigliato. Tuttavia, su un'altra macchina di prova, era il contrario. Dopotutto, hai un tipo in più, con potenziale di fuoriuscita.
Per curiosità, ho testato un'esecuzione seriale (con l'opzione MAXDOP 1) con l'indice consigliato e ho ottenuto le seguenti statistiche sulle prestazioni sul mio laptop:
elapsed: 42, CPU: 40, logical reads: 143,519
Come puoi vedere, il tempo di esecuzione è simile al tempo di esecuzione dell'esecuzione parallela con l'indice consigliato in atto. Ho solo 4 CPU logiche nel mio laptop. Naturalmente, il tuo chilometraggio può variare con hardware diverso. Il punto è che vale la pena testare diverse alternative, anche con e senza l'indicizzazione che potresti pensare che dovrebbe aiutare. I risultati a volte sono sorprendenti e controintuitivi.
La soluzione di Kamil
Sono stato davvero incuriosito dalla soluzione di Kamil e mi è piaciuto particolarmente il modo in cui ha emulato LAG e LEAD con una tecnica compatibile precedente al 2012.
Ecco il codice che implementa il primo passaggio della soluzione:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
Questo codice genera il seguente output (mostrando solo i dati per serviceid 1):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
Questo passaggio calcola due numeri di riga separati uno per ogni riga, partizionati per serviceid e ordinati per logtime. Il numero di riga corrente rappresenta l'ora di fine (chiamalo end_time) e il numero di riga corrente meno uno rappresenta l'ora di inizio (chiamalo start_time).
Il codice seguente implementa il secondo passaggio della soluzione:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; Questo passaggio genera il seguente output:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
Questo passaggio annulla il pivot di ogni riga in due righe, duplicando ogni voce di registro, una volta per il tipo ora inizio_ora e un'altra per ora_fine. Come puoi vedere, oltre ai numeri di riga minimo e massimo, ogni numero di riga viene visualizzato due volte, una con l'ora del registro dell'evento corrente (ora_di inizio) e un'altra con l'ora del registro dell'evento precedente (ora della fine).
Il codice seguente implementa il terzo passaggio della soluzione:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; Questo codice genera il seguente output:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
Questo passaggio ruota i dati, raggruppando coppie di righe con lo stesso numero di riga e restituendo una colonna per l'ora del registro eventi corrente (ora_inizio) e un'altra per l'ora del registro eventi precedente (ora_fine). Questa parte emula efficacemente una funzione LAG.
Il codice seguente implementa il quarto passaggio della soluzione:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; Questo codice genera il seguente output:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
Questo passaggio filtra le coppie in cui la differenza tra l'ora di fine precedente e l'ora di inizio corrente è maggiore dell'intervallo consentito e le righe con un solo evento. Ora devi collegare l'ora di inizio di ciascuna riga corrente con l'ora di fine della riga successiva. Ciò richiede un calcolo simile a LEAD. Per ottenere ciò, il codice, ancora una volta, crea numeri di riga che sono uno a parte, solo che questa volta il numero di riga corrente rappresenta l'ora di inizio (start_time_grp ) e il numero di riga corrente meno uno rappresenta l'ora di fine (end_time_grp).
Come prima, il passaggio successivo (numero 5) è annullare il pivot delle righe. Ecco il codice che implementa questo passaggio:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; Uscita:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
Come puoi vedere, la colonna grp è unica per ogni isola all'interno di un ID servizio.
Il passaggio 6 è l'ultimo passaggio della soluzione. Ecco il codice che implementa questo passaggio, che è anche il codice completo della soluzione:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); Questo passaggio genera il seguente output:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
Questo passaggio raggruppa le righe per serviceid e grp, filtra solo i gruppi rilevanti e restituisce l'ora di inizio minima come inizio dell'isola e l'ora di fine massima come fine dell'isola.
La figura 3 ha il piano che ho ottenuto per questa soluzione con l'indice consigliato in atto:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Pianifica con l'indice consigliato nella Figura 3.
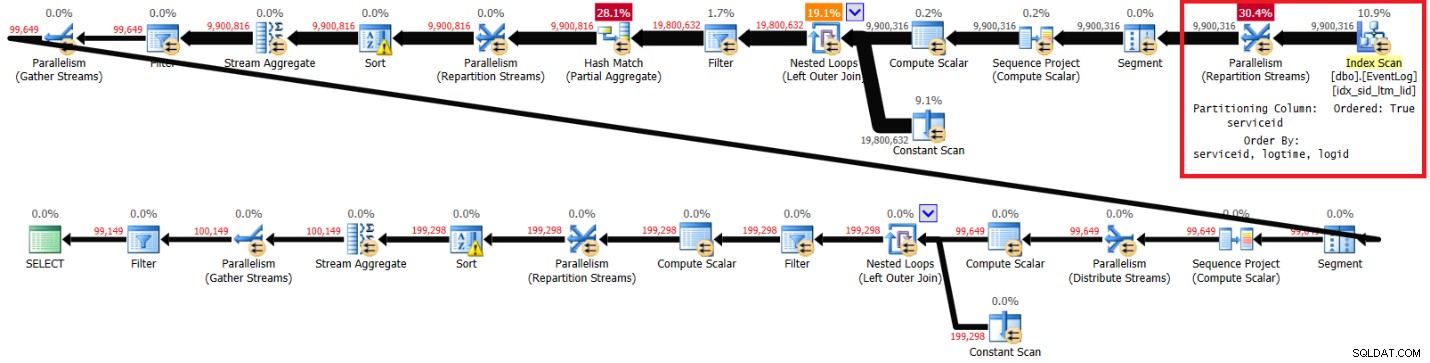 Figura 3:piano per la soluzione di Kamil con indice consigliato
Figura 3:piano per la soluzione di Kamil con indice consigliato
Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione sul mio laptop:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
Ho quindi eliminato l'indice consigliato e ho eseguito nuovamente la soluzione:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Ho ottenuto il piano mostrato nella Figura 4 per l'esecuzione senza l'indice consigliato.
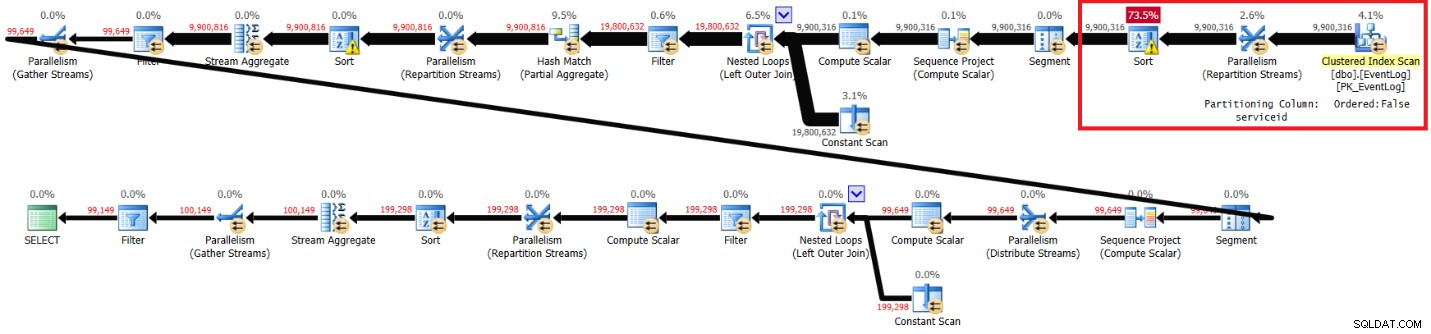 Figura 4:piano per la soluzione di Kamil senza indice consigliato
Figura 4:piano per la soluzione di Kamil senza indice consigliato
Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
I tempi di esecuzione, i tempi della CPU e i tempi di attesa di CXPACKET sono molto simili alla mia soluzione, sebbene le letture logiche siano inferiori. La soluzione di Kamil funziona anche più velocemente sul mio laptop senza l'indice consigliato e sembra che sia dovuto a ragioni simili.
Conclusione
Le anomalie sono una buona cosa. Ti rendono curioso e ti spingono a cercare la causa principale del problema e, di conseguenza, a imparare cose nuove. È interessante notare che alcune query, su determinate macchine, vengono eseguite più velocemente senza l'indicizzazione consigliata.
Grazie ancora a Toby, Peter e Kamil per le vostre soluzioni. In questo articolo ho trattato la soluzione di Kamil, con la sua tecnica creativa per emulare LAG e LEAD con numeri di riga, unpivoting e pivoting. Troverai questa tecnica utile quando avrai bisogno di calcoli simili a LAG e LEAD che devono essere supportati in ambienti precedenti al 2012.