Questo articolo utilizza una semplice query per esplorare alcuni dettagli interni relativi alle query di aggiornamento.
Dati di esempio e configurazione
Lo script di creazione dei dati di esempio riportato di seguito richiede una tabella di numeri. Se non si dispone già di uno di questi, è possibile utilizzare lo script seguente per crearne uno in modo efficiente. La tabella dei numeri risultante conterrà una singola colonna intera con numeri da uno a un milione:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Lo script seguente crea una tabella di dati di esempio in cluster con 10.000 ID, con circa 100 date di inizio diverse per ID. La colonna della data di fine è inizialmente impostata sul valore fisso "99991231".
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Sebbene i punti illustrati in questo articolo si applichino in generale a tutte le versioni correnti di SQL Server, le informazioni di configurazione seguenti possono essere utilizzate per assicurarti di visualizzare piani di esecuzione ed effetti sulle prestazioni simili:
- SQL Server 2012 Service Pack 3 Edizione per sviluppatori x64
- Memoria massima del server impostata su 2048 MB
- Quattro processori logici disponibili per l'istanza
- Nessun flag di traccia abilitato
- Livello di isolamento di lettura commit predefinito
- Opzioni database RCSI e SI disabilitate
Sversamenti di hash aggregati
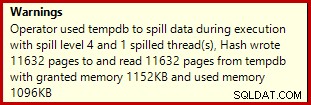
Se esegui lo script di creazione dei dati sopra con i piani di esecuzione effettivi abilitati, l'aggregato hash potrebbe riversarsi su tempdb, generando un'icona di avviso:

Quando viene eseguito su SQL Server 2012 Service Pack 3, nella descrizione comando vengono visualizzate ulteriori informazioni sullo spill:
Questa fuoriuscita potrebbe essere sorprendente, dato che le stime delle righe di input per l'Hash Match sono esattamente corrette:
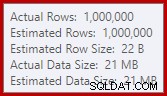
Siamo abituati a confrontare le stime sull'input per gli ordinamenti e gli hash join (solo input di compilazione), ma gli aggregati hash desiderosi sono diversi. Un aggregato hash funziona accumulando righe di risultati raggruppate nella tabella hash, quindi è il numero di output righe importanti:
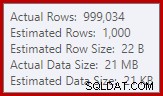
Lo stimatore di cardinalità in SQL Server 2012 fa un'ipotesi piuttosto scarsa sul numero di valori distinti previsti (1.000 contro 999.034 effettivi); di conseguenza, l'aggregato hash si riversa ricorsivamente al livello 4 in fase di esecuzione. Il "nuovo" stimatore di cardinalità disponibile in SQL Server 2014 in poi produce una stima più accurata per l'output hash in questa query, quindi in questo caso non vedrai uno spill di hash:

Il numero di righe effettive potrebbe essere leggermente diverso per te, dato l'uso di un generatore di numeri pseudo-casuali nello script. Il punto importante è che gli spill Hash Aggregate dipendono dal numero di valori univoci emessi, non dalla dimensione dell'input.
La specifica di aggiornamento
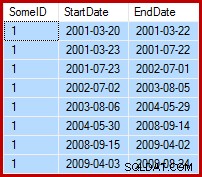
L'attività in questione è aggiornare i dati di esempio in modo tale che le date di fine siano impostate al giorno prima della data di inizio successiva (per SomeID). Ad esempio, le prime righe dei dati di esempio potrebbero avere questo aspetto prima dell'aggiornamento (tutte le date di fine impostate su 9999-12-31):

Quindi in questo modo dopo l'aggiornamento:
1. Query di aggiornamento di base
Un modo ragionevolmente naturale per esprimere l'aggiornamento richiesto in T-SQL è il seguente:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Il piano di esecuzione (effettivo) post-esecuzione è:
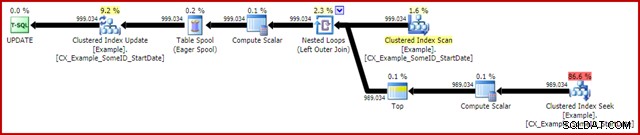
La caratteristica più notevole è l'uso di un Eager Table Spool per fornire la protezione di Halloween. Ciò è necessario per il corretto funzionamento qui a causa dell'auto join della tabella di destinazione dell'aggiornamento. L'effetto è che tutto a destra dello spool viene eseguito fino al completamento, archiviando tutte le informazioni necessarie per apportare modifiche in una tabella di lavoro tempdb. Una volta completata l'operazione di lettura, il contenuto della tabella di lavoro viene riprodotto per applicare le modifiche all'iteratore Clustered Index Update.
Prestazioni
Per concentrarci sul potenziale massimo di prestazioni di questo piano di esecuzione, possiamo eseguire la stessa query di aggiornamento più volte. Chiaramente, solo la prima esecuzione comporterà eventuali modifiche ai dati, ma questa risulta essere una considerazione minore. Se questo ti infastidisce, sentiti libero di reimpostare la colonna della data di fine prima di ogni esecuzione utilizzando il codice seguente. I punti generali che esporrò non dipendono dal numero di modifiche ai dati effettivamente apportate.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Con la raccolta del piano di esecuzione disabilitata, tutte le pagine richieste nel buffer pool e nessun ripristino dei valori della data di fine tra le esecuzioni, questa query viene in genere eseguita in circa 5700 ms sul mio portatile. L'output IO delle statistiche è il seguente:(lettura in anticipo e contatori LOB erano zero e sono omessi per motivi di spazio)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Il conteggio delle scansioni rappresenta il numero di volte in cui è stata avviata un'operazione di scansione. Per la tabella di esempio, questo è 1 per la scansione dell'indice cluster e 999.034 per ogni volta che la ricerca dell'indice cluster correlato viene rimbalzata. Il tavolo di lavoro utilizzato da Eager Spool ha un'operazione di scansione iniziata una sola volta.
Letture logiche
L'informazione più interessante nell'output IO è il numero di letture logiche:oltre 6 milioni per la tabella Esempio e quasi 3 milioni per il tavolo di lavoro.
Le letture logiche della tabella di esempio sono per lo più associate alla ricerca e all'aggiornamento. Il Seek comporta 3 letture logiche per ogni iterazione:1 per i livelli radice, intermedio e foglia dell'indice. Allo stesso modo, l'aggiornamento costa 3 letture ogni volta una riga viene aggiornato, poiché il motore naviga lungo l'albero b per individuare la riga di destinazione. La scansione dell'indice cluster è responsabile solo di poche migliaia di letture, una per pagina leggi.
La tabella di lavoro Spool è anche strutturata internamente come un b-tree e conta più letture mentre lo spool individua la posizione di inserimento mentre consuma il suo input. Forse in modo controintuitivo, lo spool non conta letture logiche mentre viene letto per guidare l'aggiornamento dell'indice cluster. Questa è semplicemente una conseguenza dell'implementazione:una lettura logica viene conteggiata ogni volta che il codice esegue BPool::Get metodo. La scrittura nello spool chiama questo metodo a ogni livello dell'indice; la lettura dallo spool segue un percorso di codice diverso che non chiama BPool::Get affatto.
Si noti inoltre che l'output di I/O delle statistiche riporta un unico totale per la tabella Esempio, nonostante sia accessibile da tre diversi iteratori nel piano di esecuzione (Scansione, Ricerca e Aggiorna). Quest'ultimo fatto rende difficile correlare le letture logiche all'iteratore che le ha causate. Spero che questa limitazione venga affrontata in una versione futura del prodotto.
2. Aggiorna utilizzando i numeri di riga
Un altro modo per esprimere la query di aggiornamento prevede la numerazione delle righe per ID e l'unione di:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Il piano post-esecuzione è il seguente:
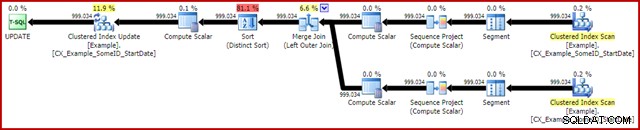
Questa query in genere viene eseguita in 2950 ms sul mio laptop, che si confronta favorevolmente con i 5700 ms (nelle stesse circostanze) visti per la dichiarazione di aggiornamento originale. L'output di I/O delle statistiche è:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Questo mostra due scansioni avviate per la tabella di esempio (una per ogni iteratore di scansione dell'indice cluster). Le letture logiche sono di nuovo un aggregato su tutti gli iteratori che accedono a questa tabella nel piano di query. Come prima, la mancanza di un breakdown rende impossibile determinare quale iteratore (delle due scansioni e dell'aggiornamento) fosse responsabile dei 3 milioni di letture.
Tuttavia, posso dirti che le scansioni dell'indice raggruppate contano solo poche migliaia di letture logiche ciascuna. La stragrande maggioranza delle letture logiche è causata dall'aggiornamento dell'indice cluster che scorre lungo l'albero b dell'indice per trovare la posizione di aggiornamento per ogni riga elaborata. Dovrai credermi sulla parola per il momento; ulteriori spiegazioni saranno disponibili a breve.
Gli svantaggi
Questa è praticamente la fine delle buone notizie per questa forma di query. Funziona molto meglio dell'originale, ma è molto meno soddisfacente per una serie di altri motivi. Il problema principale è causato da una limitazione dell'ottimizzatore, il che significa che non riconosce che l'operazione di numerazione delle righe produce un numero univoco per ogni riga all'interno di una partizione SomeID.
Questo semplice fatto porta a una serie di conseguenze indesiderabili. Per prima cosa, l'unione di unione è configurata per l'esecuzione in modalità di unione molti-a-molti. Questo è il motivo della tabella di lavoro (non utilizzata) nell'IO delle statistiche (l'unione molti-a-molti richiede una tabella di lavoro per riavvolgere la chiave di unione duplicata). Aspettarsi un join molti-a-molti significa anche che la stima della cardinalità per l'output del join è irrimediabilmente sbagliata:
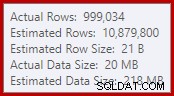
Di conseguenza, l'ordinamento richiede troppa concessione di memoria. Le proprietà del nodo radice mostrano che l'ordinamento avrebbe gradito 812.752 KB di memoria, sebbene gli siano stati concessi solo 379.440 KB a causa dell'impostazione della memoria massima del server limitata (2048 MB). L'ordinamento ha effettivamente utilizzato un massimo di 58.968 KB in fase di esecuzione:
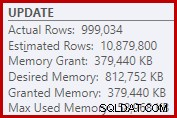
Le concessioni di memoria eccessive sottraggono memoria ad altri usi produttivi e possono portare a query in attesa fino a quando la memoria non diventa disponibile. Per molti aspetti, le concessioni di memoria eccessive possono essere più un problema che sottovalutare.
La limitazione dell'ottimizzatore spiega anche perché era necessario un suggerimento di unione di unione sulla query per ottenere prestazioni ottimali. Senza questo suggerimento, l'ottimizzatore valuta erroneamente che un join hash sarebbe più economico del join join molti-a-molti. Il piano di hash join viene eseguito in media in 3350 ms.
Come ultima conseguenza negativa, si noti che l'ordinamento nel piano è un ordinamento distinto. Ora ci sono un paio di ragioni per quell'ordinamento (non ultimo perché può fornire la protezione di Halloween richiesta) ma è solo un Distinto Ordina perché all'ottimizzatore mancano le informazioni sull'unicità. Nel complesso, è difficile apprezzare molto di questo piano di esecuzione oltre alle prestazioni.
3. Aggiorna utilizzando la funzione analitica LEAD
Poiché questo articolo è destinato principalmente a SQL Server 2012 e versioni successive, possiamo esprimere la query di aggiornamento in modo abbastanza naturale utilizzando la funzione analitica LEAD. In un mondo ideale, potremmo usare una sintassi molto compatta come:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Sfortunatamente, questo non è legale. Risulta nel messaggio di errore 4108, "Le funzioni della finestra possono apparire solo nelle clausole SELECT o ORDER BY". Questo è un po' frustrante perché speravamo in un piano di esecuzione che potesse evitare un'adesione automatica (e l'aggiornamento associato Protezione di Halloween).
La buona notizia è che possiamo ancora evitare l'auto-unione utilizzando un'espressione di tabella comune o una tabella derivata. La sintassi è un po' più dettagliata, ma l'idea è più o meno la stessa:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Il piano post-esecuzione è:

Questo in genere viene eseguito in circa 3400 ms sul mio laptop, che è più lento della soluzione del numero di riga (2950 ms) ma comunque molto più veloce dell'originale (5700 ms). Una cosa che si distingue dal piano di esecuzione è lo sversamento di smistamento (di nuovo, informazioni aggiuntive sullo sversamento per gentile concessione dei miglioramenti in SP3):
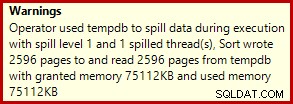
Questa è una piccola fuoriuscita, ma potrebbe comunque influire sulle prestazioni in una certa misura. La cosa strana è che la stima di input per l'ordinamento è esattamente corretta:
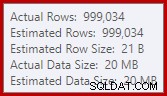
Fortunatamente, esiste una "correzione" per questa condizione specifica in SQL Server 2012 SP2 CU8 (e altre versioni:vedere l'articolo della Knowledge Base per i dettagli). L'esecuzione della query con la correzione e il flag di traccia richiesto 7470 abilitati significa che l'ordinamento richiede memoria sufficiente per garantire che non venga mai riversato sul disco se la dimensione di ordinamento dell'input stimata non viene superata.
Query di aggiornamento LEAD senza smistamento sversamento
Per varietà, la query abilitata alla correzione di seguito utilizza la sintassi della tabella derivata anziché un CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Il nuovo piano post-esecuzione è:

L'eliminazione della piccola fuoriuscita migliora le prestazioni da 3400 ms a 3250 ms . L'output di I/O delle statistiche è:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Se lo confronti con le letture logiche per la query numerata di riga, vedrai che le letture logiche sono diminuite da 3.001.808 a 2.999.455, una differenza di 2.353 letture. Ciò corrisponde esattamente alla rimozione di una singola scansione dell'indice cluster (una letta per pagina).
Potresti ricordare che ho menzionato che la stragrande maggioranza delle letture logiche per queste query di aggiornamento è associata all'aggiornamento dell'indice cluster e che le scansioni erano associate a "solo poche migliaia di letture". Ora possiamo vederlo un po' più direttamente eseguendo una semplice query di conteggio delle righe sulla tabella di esempio:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
L'output IO mostra esattamente la differenza di lettura logica di 2.353 tra il numero di riga e gli aggiornamenti dei lead:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Ulteriori miglioramenti?
La query sui lead con correzione dello spill (3250 ms) è ancora un po' più lenta della query numerata a doppia riga (2950 ms), il che potrebbe sorprendere un po'. Intuitivamente, ci si potrebbe aspettare che una singola scansione e una funzione analitica (Window Spool e Stream Aggregate) siano più veloci di due scansioni, due serie di numerazione delle righe e un join.
Indipendentemente da ciò, la cosa che salta fuori dal piano di esecuzione della query principale è l'ordinamento. Era presente anche nella query numerata di riga, dove ha contribuito alla protezione di Halloween e a un ordinamento ottimizzato per l'aggiornamento dell'indice cluster (che ha la proprietà DMLRequestSort impostata).
Il fatto è che questo ordinamento non è completamente necessario nel piano di query principale. Non è necessario per la protezione di Halloween perché il self-join è scomparso. Non è nemmeno necessario per l'ordinamento di inserimento ottimizzato:le righe vengono lette nell'ordine delle chiavi raggruppate e non c'è nulla nel piano che possa disturbare quell'ordine. Il vero problema può essere visto osservando le proprietà di ordinamento:

Notare la sezione Ordina per lì. L'ordinamento è ordinato per SomeID e StartDate (le chiavi dell'indice cluster) ma anche per [Uniq1002], che è l'unificatore. Questa è una conseguenza della mancata dichiarazione dell'indice cluster come univoco, anche se nella query di popolamento di dati sono stati eseguiti passaggi per garantire che la combinazione di SomeID e StartDate fosse effettivamente univoca. (Questo è stato deliberato, quindi potrei parlarne.)
Anche così, questa è una limitazione. Le righe vengono lette dall'indice cluster in ordine ed esistono le garanzie interne necessarie in modo tale che l'ottimizzatore possa evitare in sicurezza questo ordinamento. È semplicemente una svista che l'ottimizzatore non riconosca che il flusso in entrata è ordinato per unificatore, nonché per SomeID e StartDate. Riconosce che l'ordine (SomeID, StartDate) potrebbe essere conservato, ma non (SomeID, StartDate, uniquifier). Ancora una volta, spero che questo problema venga affrontato in una versione futura.
Per ovviare a questo problema, possiamo fare ciò che avremmo dovuto fare in primo luogo:creare l'indice cluster come univoco:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
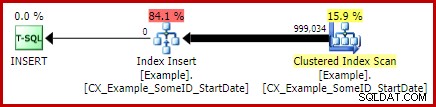
Lascerò come esercizio al lettore mostrare che le prime due query (non LEAD) non beneficiano di questa modifica dell'indicizzazione (omessa esclusivamente per motivi di spazio:c'è molto da coprire).
La forma finale della query di aggiornamento dei lead
Con l'unico indice cluster in atto, la stessa query LEAD (CTE o tabella derivata a piacere) produce il piano stimato (pre-esecuzione) che ci aspettiamo:

Questo sembra abbastanza ottimale. Una singola operazione di lettura e scrittura con un minimo di operatori intermedi. Certamente, sembra molto meglio della versione precedente con l'inutile Sort, che veniva eseguito in 3250 ms una volta rimosso lo spill evitabile (a costo di aumentare un po' la concessione di memoria).
Il piano post-esecuzione (effettivo) è quasi esattamente lo stesso del piano pre-esecuzione:

Tutte le stime sono esattamente corrette, tranne l'output di Window Spool, che è fuori di 2 righe. Le informazioni sull'IO delle statistiche sono esattamente le stesse di prima che l'ordinamento fosse rimosso, come ti aspetteresti:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Per riassumere brevemente, l'unica differenza apparente tra questo nuovo piano e quello immediatamente precedente è che il Sort (con un contributo di spesa stimato di quasi l'80%) è stato rimosso.
Potrebbe quindi sorprendere sapere che la nuova query, senza l'ordinamento, viene eseguita in 5000 ms . Questo è molto peggio dei 3250 ms con Sort e quasi quanto la query di join del loop originale di 5700 ms. La soluzione di numerazione a doppia riga è ancora molto avanti a 2950 ms.
Spiegazione
La spiegazione è alquanto esoterica e si riferisce al modo in cui vengono gestiti i latch per l'ultima query. Possiamo mostrare questo effetto in diversi modi, ma il più semplice è probabilmente guardare le statistiche di attesa e latch usando i DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Quando l'indice cluster non è univoco ed è presente un Sort nel piano, non ci sono attese significative, solo un paio di PAGEIOLATCH_UP attese e gli SOS_SCHEDULER_YIELD previsti.
Quando l'indice cluster è univoco e l'ordinamento viene rimosso, le attese sono:
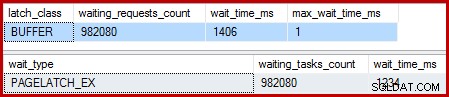
Ci sono 982.080 latch di pagina esclusivi lì, con un tempo di attesa che spiega praticamente tutto il tempo di esecuzione extra. Per enfatizzare, è quasi un'attesa di latch per riga aggiornata! Potremmo aspettarci un latch per cambio di riga, ma non un latch attendere , soprattutto quando la query di test è l'unica attività sull'istanza. I tempi di attesa sono brevi, ma ce ne sono moltissimi.
Chiusure pigre
Dopo l'esecuzione della query con un debugger e un analizzatore allegati, la spiegazione è la seguente.
La scansione dell'indice cluster utilizza latch latch – un'ottimizzazione che significa che i latch vengono rilasciati solo quando un altro thread richiede l'accesso alla pagina. Normalmente, i fermi vengono rilasciati immediatamente dopo la lettura o la scrittura. Lazy latch ottimizza il caso in cui la scansione di un'intera pagina acquisirebbe e rilascerebbe lo stesso latch di pagina per ogni riga. Quando si utilizza il latch lazy senza contese, viene utilizzato un solo latch per l'intera pagina.
Il problema è che la natura pipeline del piano di esecuzione (nessun operatore di blocco) significa che le letture si sovrappongono alle scritture. Quando l'aggiornamento dell'indice cluster tenta di acquisire un latch EX per modificare una riga, scoprirà quasi sempre che la pagina è già bloccata SH (il latch pigro preso dalla scansione dell'indice cluster). Questa situazione si traduce in un'attesa di latch.
Come parte della preparazione per attendere e passare all'elemento eseguibile successivo nello scheduler, il codice fa attenzione a rilasciare eventuali latch lazy. Il rilascio del fermo pigro segnala il primo cameriere idoneo, che sembra essere se stesso. Quindi, abbiamo la strana situazione in cui un thread si blocca, rilascia il suo pigro latch, quindi si segnala che è di nuovo eseguibile. Il thread riprende, e continua, ma solo dopo che tutto quello spreco di sospendere e cambiare, segnalare e riprendere il lavoro è stato fatto. Come dicevo prima, le attese sono brevi, ma sono tante.
Per quanto ne so, questa strana sequenza di eventi è stata progettata e per buoni motivi interni. Anche così, non si può sfuggire al fatto che qui ha un effetto abbastanza drammatico sulle prestazioni. Farò alcune domande al riguardo e aggiornerò l'articolo se c'è una dichiarazione pubblica da fare. Nel frattempo, le attese di auto-latch eccessive potrebbero essere qualcosa a cui prestare attenzione con le query di aggiornamento pipeline, anche se non è chiaro cosa dovrebbe essere fatto al riguardo dal punto di vista di chi scrive la query.
Questo significa che l'approccio alla doppia numerazione delle righe è il meglio che possiamo fare per questa query? Non proprio.
4. Protezione manuale di Halloween
Quest'ultima opzione potrebbe suonare e sembrare un po' folle. L'idea generale è scrivere tutte le informazioni necessarie per apportare le modifiche a una variabile di tabella, quindi eseguire l'aggiornamento come passaggio separato.
In mancanza di una descrizione migliore, lo chiamo l'approccio "HP manuale" perché è concettualmente simile alla scrittura di tutte le informazioni sulle modifiche su un Eager Table Spool (come visto nella prima query) prima di guidare l'aggiornamento da quello Spool.
Ad ogni modo, il codice è il seguente:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Quel codice usa deliberatamente una variabile di tabella per evitare il costo delle statistiche create automaticamente che comporterebbe l'utilizzo di una tabella temporanea. Qui va bene perché conosco la forma del piano che voglio e non dipende dalle stime dei costi o dalle informazioni statistiche.
L'unico aspetto negativo della variabile tabella (senza flag di traccia) è che l'ottimizzatore in genere stima una singola riga e sceglie i cicli nidificati per l'aggiornamento. Per evitare ciò, ho utilizzato un suggerimento di unione di unione. Ancora una volta, questo è guidato dalla conoscenza esatta della forma del piano da raggiungere.
Il piano di post-esecuzione per la variabile di tabella insert ha lo stesso aspetto della query che ha avuto il problema con il latch waits:

Il vantaggio di questo piano è che non sta cambiando la stessa tabella da cui sta leggendo. Non è richiesta alcuna protezione di Halloween e non vi è alcuna possibilità di interferenza del fermo. Inoltre, sono disponibili significative ottimizzazioni interne per gli oggetti tempdb (blocco e registrazione) e vengono applicate anche altre normali ottimizzazioni del caricamento in blocco. Ricorda che le ottimizzazioni collettive sono disponibili solo per inserimenti, non aggiornamenti o eliminazioni.
Il piano post-esecuzione per la dichiarazione di aggiornamento è:
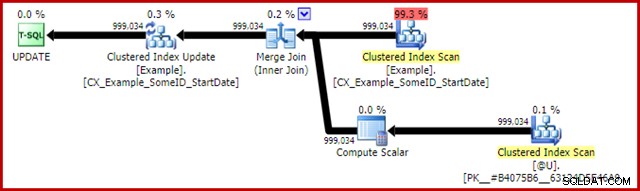
Il Merge Join qui è il tipo efficiente uno-a-molti. Inoltre, questo piano si qualifica per un'ottimizzazione speciale che significa che la scansione dell'indice in cluster e l'aggiornamento dell'indice in cluster condividono lo stesso set di righe. L'importante conseguenza è che l'aggiornamento non deve più individuare la riga da aggiornare:è già posizionato correttamente dalla lettura. Ciò consente di risparmiare un sacco di letture logiche (e altre attività) durante l'aggiornamento.
Non c'è nulla nei normali piani di esecuzione per mostrare dove viene applicata questa ottimizzazione del set di righe condiviso, ma l'abilitazione del flag di traccia non documentato 8666 espone proprietà aggiuntive sull'aggiornamento e sulla scansione che mostrano che la condivisione del set di righe è in uso e che vengono prese misure per garantire che l'aggiornamento sia sicuro dal problema di Halloween.
L'output di I/O delle statistiche per le due query è il seguente:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Entrambe le letture della tabella di esempio implicano una singola scansione e una lettura logica per pagina (vedere la semplice query di conteggio delle righe in precedenza). La tabella #B9C034B8 è il nome dell'oggetto tempdb interno che supporta la variabile della tabella. Le letture logiche totali per entrambe le query sono 3 * 2353 =7.059. Il tavolo di lavoro è la memoria interna in memoria utilizzata da Window Spool.
Il tempo di esecuzione tipico per questa query è 2300 ms . Infine, abbiamo qualcosa che supera la doppia query di numerazione delle righe (2950 ms), per quanto improbabile possa sembrare.
Pensieri finali
Potrebbero esserci modi ancora migliori per scrivere questo aggiornamento che funzionano anche meglio della soluzione "HP manuale" di cui sopra. I risultati delle prestazioni possono anche essere diversi sull'hardware e sulla configurazione di SQL Server, ma nessuno di questi è il punto principale di questo articolo. Questo non vuol dire che non mi interessi vedere query migliori o confronti delle prestazioni:lo sono.
Il punto è che all'interno di SQL Server sta succedendo molto di più di quanto non venga esposto nei piani di esecuzione. Si spera che alcuni dei dettagli discussi in questo articolo piuttosto lungo siano interessanti o addirittura utili per alcune persone.
È bene avere aspettative sulle prestazioni e sapere quali forme e proprietà del piano sono generalmente vantaggiose. Quel tipo di esperienza e conoscenza ti servirà bene per il 99% o più delle domande che ti verrà mai chiesto di mettere a punto. A volte, però, è bene provare qualcosa di un po' strano o insolito solo per vedere cosa succede e per convalidare queste aspettative.