Entrare in produzione è un compito molto importante che deve essere attentamente pensato e pianificato in anticipo. Alcune decisioni non così buone possono essere facilmente corrette in seguito, ma altre no. Quindi è sempre meglio dedicare quel tempo extra a leggere i documenti ufficiali, i libri e le ricerche fatte da altri in anticipo, piuttosto che scusarsi più tardi. Questo è vero per la maggior parte delle distribuzioni di sistemi informatici e PostgreSQL non fa eccezione.
Pianificazione iniziale del sistema
Alcune decisioni devono essere prese in anticipo, prima che il sistema diventi attivo. Il DBA PostgreSQL deve rispondere a una serie di domande:il DB verrà eseguito su bare metal, macchine virtuali o anche containerizzato? Verrà eseguito nelle sedi dell'organizzazione o nel cloud? Quale sistema operativo verrà utilizzato? Lo spazio di archiviazione sarà di tipo a dischi rotanti o SSD? Per ogni scenario o decisione, ci sono pro e contro e la chiamata finale sarà effettuata in collaborazione con le parti interessate in base ai requisiti dell'organizzazione. Tradizionalmente le persone eseguivano PostgreSQL su bare metal, ma la situazione è cambiata radicalmente negli ultimi anni con sempre più provider di cloud che offrono PostgreSQL come opzione standard, il che è un segno dell'ampia adozione e il risultato della crescente popolarità di PostgreSQL. Indipendentemente dalla soluzione specifica, il DBA deve garantire che i dati siano al sicuro, il che significa che il database sarà in grado di sopravvivere agli arresti anomali, e questo è il criterio No1 quando si prendono decisioni su hardware e storage. Quindi questo ci porta al primo consiglio!
Suggerimento 1
Indipendentemente da ciò che pubblicizza il controller del disco o il produttore del disco o il provider di archiviazione cloud, dovresti sempre assicurarti che lo spazio di archiviazione non menta su fsync. Una volta che fsync ritorna OK, i dati dovrebbero essere al sicuro sul supporto, indipendentemente da ciò che accade in seguito (arresto anomalo, interruzione di corrente, ecc.). Un ottimo strumento che ti aiuterà a testare l'affidabilità della cache di write-back dei tuoi dischi è diskchecker.pl.
Basta leggere le note:https://brad.livejournal.com/2116715.html e fare il test.
Utilizzare una macchina per ascoltare gli eventi e la macchina vera e propria da testare. Dovresti vedere:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0al termine del report sulla macchina testata.
La seconda preoccupazione dopo l'affidabilità dovrebbe riguardare le prestazioni. Le decisioni sul sistema (CPU, memoria) erano molto più vitali poiché era piuttosto difficile cambiarle in seguito. Ma oggi, nell'era del cloud, possiamo essere più flessibili riguardo ai sistemi su cui gira il DB. Lo stesso vale per lo storage, soprattutto nei primi anni di vita di un sistema e mentre le dimensioni sono ancora piccole. Quando il DB supera la cifra TB in termini di dimensioni, diventa sempre più difficile modificare i parametri di archiviazione di base senza la necessità di copiare completamente il database o, peggio ancora, eseguire un pg_dump, pg_restore. Il secondo suggerimento riguarda le prestazioni del sistema.
Suggerimento 2
Analogamente a testare sempre le promesse dei produttori in merito all'affidabilità, lo stesso dovresti fare per le prestazioni dell'hardware. Bonnie++ è il benchmark delle prestazioni di archiviazione più popolare per i sistemi simili a Unix. Per il test generale del sistema (CPU, memoria e anche storage) nulla è più rappresentativo delle prestazioni del DB. Quindi il test di base delle prestazioni sul tuo nuovo sistema sarebbe l'esecuzione di pgbench, la suite di benchmark PostgreSQL ufficiale basata su TCP-B.
Iniziare con pgbench è abbastanza semplice, tutto ciò che devi fare è:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Dovresti sempre consultare pgbench dopo ogni cambiamento importante di cui desideri valutare e confrontare i risultati.
Distribuzione, automazione e monitoraggio del sistema
Una volta avviato, è molto importante avere i componenti principali del sistema documentati e riproducibili, disporre di procedure automatizzate per la creazione di servizi e attività ricorrenti e anche disporre degli strumenti per eseguire il monitoraggio continuo.
Suggerimento 3
Un modo pratico per iniziare a utilizzare PostgreSQL con tutte le sue funzionalità aziendali avanzate è ClusterControl di Multiplenines. Si può avere un cluster PostgreSQL di classe enterprise, semplicemente premendo pochi clic. ClusterControl fornisce tutti i suddetti servizi e molti altri. Configurare ClusterControl è abbastanza semplice, basta seguire le istruzioni sulla documentazione ufficiale. Una volta che hai preparato i tuoi sistemi (tipicamente uno per l'esecuzione di CC e uno per PostgreSQL per una configurazione di base) e hai eseguito la configurazione SSH, devi inserire i parametri di base (IP, Port no, ecc.) e se tutto va bene dovresti vedere un output come il seguente:
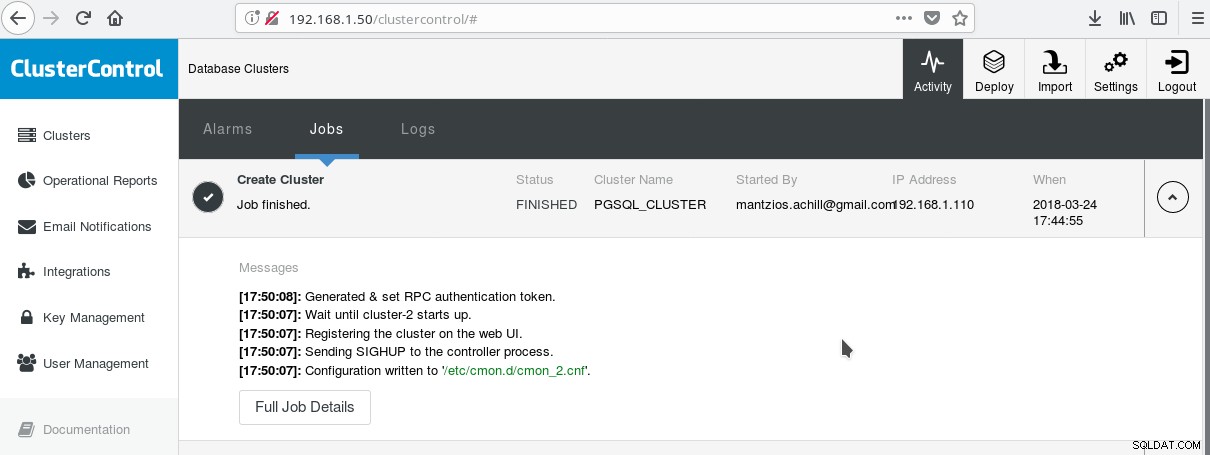
E nella schermata dei cluster principali:
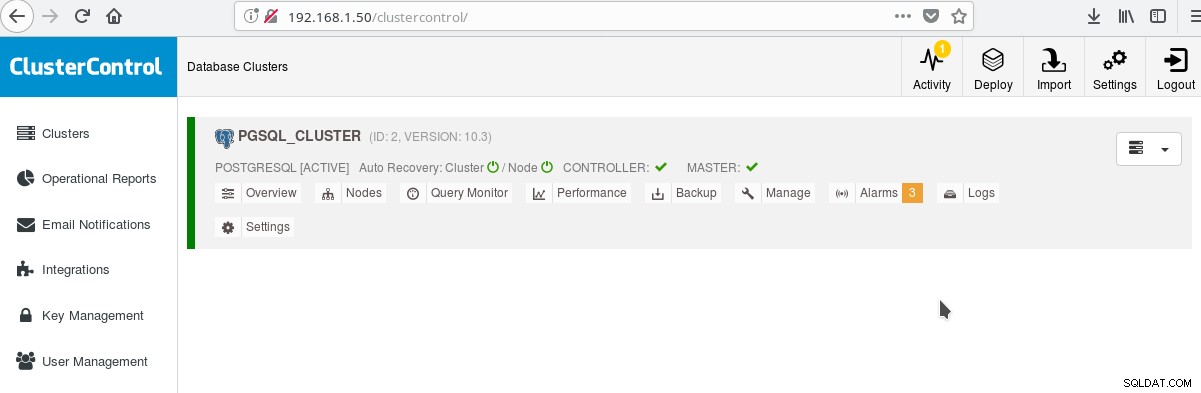
Puoi accedere al tuo server principale e iniziare a creare il tuo schema! Ovviamente puoi usare come base il cluster che hai appena creato per costruire ulteriormente la tua infrastruttura (topologia). Una buona idea generalmente è avere un layout del file system del server stabile e una configurazione finale sul tuo server PostgreSQL e database utente/app prima di iniziare a creare cloni e standby (slave) basati sul tuo nuovo server appena creato.
Layout PostgreSQL, parametri e impostazioni
Nella fase di inizializzazione del cluster la decisione più importante è se utilizzare o meno i checksum dei dati sulle pagine di dati. Se vuoi la massima sicurezza dei dati per i tuoi dati preziosi (futuri), allora questo è il momento di farlo. Se c'è la possibilità che tu possa volere questa funzione in futuro e trascuri di farlo in questa fase, non sarai in grado di cambiarla in seguito (senza pg_dump/pg_restore che è). Questo è il prossimo consiglio:
Suggerimento 4
Per abilitare i checksum dei dati, esegui initdb come segue:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Nota che questo dovrebbe essere fatto al momento del suggerimento 3 che abbiamo descritto sopra. Se hai già creato il cluster con ClusterControl dovrai eseguire nuovamente pg_createcluster a mano, poiché al momento in cui scrivo non c'è modo di dire al sistema o al CC di includere questa opzione.
Un altro passaggio molto importante prima di passare alla produzione è la pianificazione del layout del file system del server. La maggior parte delle moderne distribuzioni Linux (almeno quelle basate su debian) montano tutto su / ma con PostgreSQL normalmente non lo vuoi. È utile avere i propri tablespace su volumi separati, avere un volume dedicato ai file WAL e un altro per il registro pg. Ma la cosa più importante è spostare il WAL sul proprio disco. Questo ci porta al prossimo suggerimento.
Suggerimento 5
Con PostgreSQL 10 su Debian Stretch, puoi spostare il tuo WAL su un nuovo disco con i seguenti comandi (supponendo che il nuovo disco sia chiamato /dev/sdb ):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlÈ estremamente importante impostare correttamente la localizzazione e la codifica dei database. Trascuralo nella fase di creazioneb e te ne pentirai profondamente, poiché la tua app/DB si sposta nei territori i18n, l10n. Il prossimo suggerimento mostra come farlo.
Suggerimento 6
Dovresti leggere i documenti ufficiali e decidere le tue impostazioni COLLATE e CTYPE (createdb --locale=) (responsabili dell'ordinamento e della classificazione dei caratteri) così come l'impostazione charset (createdb --encoding=). Specificare UTF8 come codifica consentirà al database di archiviare testo multilingue.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperAlta disponibilità PostgreSQL
A partire da PostgreSQL 9.0, quando la replica in streaming è diventata una funzionalità standard, è diventato possibile avere uno o più hot standby di sola lettura, consentendo così la possibilità di indirizzare il traffico di sola lettura verso uno qualsiasi degli slave disponibili. Esistono nuovi piani per la replica multimaster, ma al momento in cui scrivo (10.3) è possibile avere un solo master di lettura-scrittura, almeno nel prodotto open source ufficiale. Per il prossimo consiglio che si occupa esattamente di questo.
Suggerimento 7
Useremo il nostro ClusterControl PGSQL_CLUSTER creato nel Tip 3. Per prima cosa creiamo una seconda macchina che fungerà da nostro slave di sola lettura (hot standby nella terminologia di PostgreSQL). Quindi facciamo clic su Aggiungi replica slave e selezioniamo il nostro master e il nuovo slave. Al termine del lavoro dovresti vedere questo output:
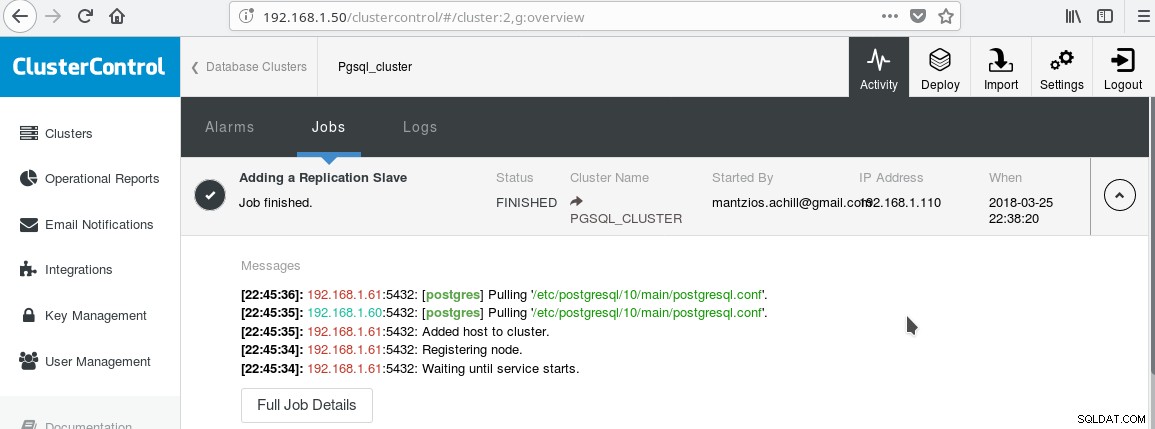
E il cluster ora dovrebbe assomigliare a:
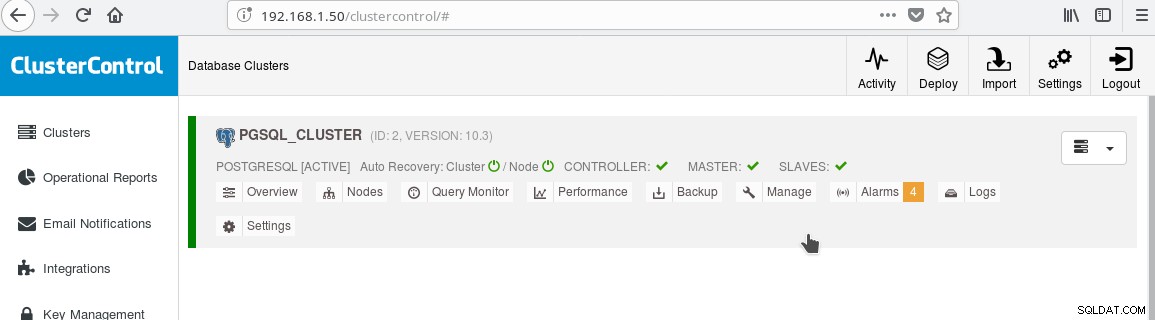
Notare l'icona verde "spuntata" sull'etichetta "SLAVES" accanto a "MASTER". Puoi verificare che la replica in streaming funzioni, creando un oggetto database (database, tabella, ecc.) oppure inserendo alcune righe in una tabella sul master e vedere la modifica in standby.
La presenza dello standby di sola lettura ci consente di eseguire il bilanciamento del carico per i client effettuando query di sola selezione tra i due server disponibili, il master e lo slave. Questo ci porta al suggerimento 8.
Suggerimento 8
È possibile abilitare il bilanciamento del carico tra i due server utilizzando HAProxy. Con ClusterControl questo è abbastanza facile da fare. Fai clic su Gestisci-> Bilanciatore di carico. Dopo aver scelto il server HAProxy, ClusterControl installerà tutto per te:xinetd su tutte le istanze specificate e HAProxy sul server HAProxy designato. Dopo che il lavoro è stato completato con successo dovresti vedere:
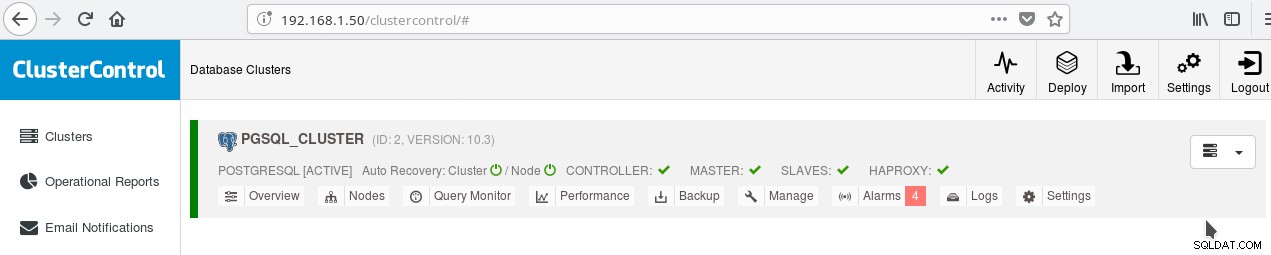
Nota il segno di spunta verde HAPROXY accanto agli SCHIAVI. Ora puoi verificare che HAProxy funzioni:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Suggerimento 9
Oltre alla configurazione per HA e al bilanciamento del carico, è sempre vantaggioso avere una sorta di pool di connessioni davanti al server PostgreSQL. Pgpool e Pgbouncer sono due progetti provenienti dalla comunità di PostgreSQL. Molti server delle applicazioni aziendali forniscono anche i propri pool. Pgbouncer è stato molto popolare per la sua semplicità, velocità e per la funzionalità di “transaction pooling”, grazie alla quale la connessione al server viene liberata una volta terminata la transazione, rendendolo riutilizzabile per transazioni successive che potrebbero provenire dalla stessa sessione o da una diversa . L'impostazione del pool di transazioni interrompe alcune funzionalità di pool di sessioni, ma in generale la conversione a un'impostazione pronta per il "pooling di transazioni" è facile e i contro non sono così importanti nel caso generale. Una configurazione comune consiste nel configurare il pool del server delle app con connessioni semipersistenti:un pool piuttosto più ampio di connessioni per utente o per app (che si connettono a pgbouncer) con lunghi timeout di inattività. In questo modo il tempo di connessione dall'app è minimo mentre pgbouncer aiuta a mantenere le connessioni al server il meno possibile.
Una cosa che molto probabilmente sarà di preoccupazione una volta che avrai attivato PostgreSQL è la comprensione e la correzione delle query lente. Gli strumenti di monitoraggio che abbiamo menzionato nel blog precedente come pg_stat_statements e anche le schermate di strumenti come ClusterControl ti aiuteranno a identificare e possibilmente suggerire idee per correggere le query lente. Tuttavia, una volta identificata la query lenta, dovrai eseguire EXPLAIN o EXPLAIN ANALYZE per vedere esattamente i costi e i tempi coinvolti nel piano di query. Il prossimo suggerimento riguarda uno strumento molto utile per farlo.
Suggerimento 10
È necessario eseguire EXPLAIN ANALYZE sul database, quindi copiare l'output e incollarlo sullo strumento online di analisi spiegato di depesz e fare clic su Invia. Quindi vedrai tre schede:HTML, TESTO e STATISTICHE. L'HTML contiene il costo, il tempo e il numero di cicli per ogni nodo del piano. La scheda STATS mostra le statistiche per tipo di nodo. Dovresti osservare la colonna "% della query", in modo da sapere dove soffre esattamente la tua query.
Man mano che acquisirai familiarità con PostgreSQL, troverai molti altri suggerimenti per conto tuo!