In questo articolo, discuteremo degli errori tipici che gli sviluppatori principianti possono incontrare durante la progettazione del codice T-SQL. Inoltre, daremo uno sguardo alle best practice e ad alcuni suggerimenti utili che possono aiutarti quando lavori con SQL Server, oltre a soluzioni alternative per migliorare le prestazioni.
Contenuto:
1. Tipi di dati
2. *
3. Alias
4. Ordine delle colonne
5. NOT IN vs NULL
6. Formato data
7. Filtro data
8. Calcolo
9. Converti implicito
10. MI PIACE &Indice soppresso
11. Unicode vs ANSI
12. COLLEGA
13. COLLEZIONI BINARIE
14. Stile del codice
15. [var]char
16. Lunghezza dei dati
17. ISNULL vs COALESCE
18. Matematica
19. UNION vs UNION ALL
20. Rileggi
21. Sottointerrogazione
22. CASO QUANDO
23. Funzione scalare
24. VISUALIZZAZIONI
25. CURSORI
26. STRING_CONCAT
27. Iniezione SQL
Tipi di dati
Il problema principale che dobbiamo affrontare quando lavoriamo con SQL Server è una scelta errata dei tipi di dati.
Supponiamo di avere due tabelle identiche:
DECLARE @Employees1 TABLE (
EmployeeID BIGINT PRIMARY KEY
, IsMale VARCHAR(3)
, BirthDate VARCHAR(20)
)
INSERT INTO @Employees1
VALUES (123, 'YES', '2012-09-01')
DECLARE @Employees2 TABLE (
EmployeeID INT PRIMARY KEY
, IsMale BIT
, BirthDate DATE
)
INSERT INTO @Employees2
VALUES (123, 1, '2012-09-01') Eseguiamo una query per verificare qual è la differenza:
DECLARE @BirthDate DATE = '2012-09-01' SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate
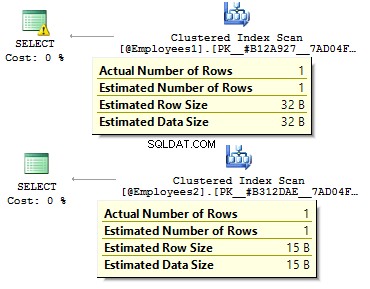
Nel primo caso, i tipi di dati sono più ridondanti di quanto potrebbero essere. Perché dovremmo memorizzare un valore bit come SI/NO riga? Perché dovremmo memorizzare una data come riga? Perché dovremmo usare BIGINT per i dipendenti nella tabella, anziché INT ?
Porta ai seguenti inconvenienti:
- Le tabelle possono occupare molto spazio sul disco;
- Dobbiamo leggere più pagine e inserire più dati in BufferPool per gestire i dati.
- Prestazioni scarse.
*
Ho affrontato la situazione in cui gli sviluppatori recuperano tutti i dati da una tabella e quindi sul lato client utilizzano DataReader per selezionare solo i campi obbligatori. Non consiglio di utilizzare questo approccio:
USE AdventureWorks2014
GO
SET STATISTICS TIME, IO ON
SELECT *
FROM Person.Person
SELECT BusinessEntityID
, FirstName
, MiddleName
, LastName
FROM Person.Person
SET STATISTICS TIME, IO OFF Ci sarà una differenza significativa nel tempo di esecuzione della query. Inoltre, l'indice di copertura può ridurre un numero di letture logiche.
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ... SQL Server Execution Times: CPU time = 31 ms, elapsed time = 1235 ms. Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 227 ms.
Alias
Creiamo una tabella:
USE AdventureWorks2014
GO
IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL
DROP TABLE Sales.UserCurrency
GO
CREATE TABLE Sales.UserCurrency (
CurrencyCode NCHAR(3) PRIMARY KEY
)
INSERT INTO Sales.UserCurrency
VALUES ('USD') Supponiamo di avere una query che restituisce la quantità di righe identiche in entrambe le tabelle:
SELECT COUNT_BIG(*)
FROM Sales.Currency
WHERE CurrencyCode IN (
SELECT CurrencyCode
FROM Sales.UserCurrency
) Tutto funzionerà come previsto, finché qualcuno non rinomina una colonna in Sales.UserCurrency tabella:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Successivamente, eseguiremo una query e vedremo di ottenere tutte le righe in Sales.Currency tabella, invece di 1 riga. Durante la creazione di un piano di esecuzione, nella fase di associazione, SQL Server controlla le colonne di Sales.UserCurrency, non troverà CurrencyCode lì e decide che questa colonna appartiene a Sales.Currency tavolo. Dopodiché, un ottimizzatore rilascerà CurrencyCode =CurrencyCode condizione.
Pertanto, consiglio di utilizzare gli alias:
SELECT COUNT_BIG(*)
FROM Sales.Currency c
WHERE c.CurrencyCode IN (
SELECT u.CurrencyCode
FROM Sales.UserCurrency u
) Ordine delle colonne
Supponiamo di avere una tabella:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL
DROP TABLE dbo.DatePeriod
GO
CREATE TABLE dbo.DatePeriod (
StartDate DATE
, EndDate DATE
) Inseriamo sempre i dati lì in base alle informazioni sull'ordine delle colonne.
INSERT INTO dbo.DatePeriod SELECT '2015-01-01', '2015-01-31'
Supponiamo che qualcuno modifichi l'ordine delle colonne:
CREATE TABLE dbo.DatePeriod (
EndDate DATE
, StartDate DATE
) I dati verranno inseriti in un ordine diverso. In questo caso, è una buona idea specificare esplicitamente le colonne nell'istruzione INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate) SELECT '2015-01-01', '2015-01-31'
Ecco un altro esempio:
SELECT TOP(1) * FROM dbo.DatePeriod ORDER BY 2 DESC
Su quale colonna ordineremo i dati? Dipenderà dall'ordine delle colonne in una tabella. Nel caso in cui si modifichi l'ordine otteniamo risultati errati.
NON IN vs NULL
Parliamo del NON IN dichiarazione.
Ad esempio, devi scrivere un paio di query:restituire i record della prima tabella, che non esistono nella seconda tabella e visa verse. Di solito, gli sviluppatori junior usano IN e NON IN :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1)) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2)) INSERT INTO @t2 VALUES (1) SELECT * FROM @t1 WHERE t1 NOT IN (SELECT t2 FROM @t2) SELECT * FROM @t1 WHERE t1 IN (SELECT t2 FROM @t2)
La prima query ha restituito 2, la seconda – 1. Inoltre, aggiungeremo un altro valore nella seconda tabella – NULL :
INSERT INTO @t2 VALUES (1), (NULL)
Quando si esegue la query con NON IN , non otterremo alcun risultato. Perché IN funziona e NON in no? Il motivo è che SQL Server utilizza TRUE , FALSO e SCONOSCIUTO logica quando si confrontano i dati.
Quando si esegue una query, SQL Server interpreta la condizione IN nel modo seguente:
a IN (1, NULL) == a=1 OR a=NULL
NON IN :
a NOT IN (1, NULL) == a<>1 AND a<>NULL
Quando si confronta un valore con NULL, SQL Server restituisce SCONOSCIUTO. O 1=NULL o NULL=NULL – entrambi risultano in SCONOSCIUTO. Per quanto abbiamo AND nell'espressione, entrambe le parti restituiscono SCONOSCIUTO.
Vorrei sottolineare che questo caso non è raro. Ad esempio, contrassegni una colonna come NON NULL. Dopo un po', un altro sviluppatore decide di consentire NULL per quella colonna. Ciò può portare alla situazione in cui un rapporto client smette di funzionare una volta inserito qualsiasi valore NULL nella tabella.
In questo caso, consiglierei di escludere i valori NULL:
SELECT *
FROM @t1
WHERE t1 NOT IN (
SELECT t2
FROM @t2
WHERE t2 IS NOT NULL
) Inoltre, è possibile utilizzare EXCEPT :
SELECT * FROM @t1 EXCEPT SELECT * FROM @t2
In alternativa, puoi utilizzare NON ESISTE :
SELECT *
FROM @t1
WHERE NOT EXISTS(
SELECT 1
FROM @t2
WHERE t1 = t2
) Quale opzione è più preferibile? Quest'ultima opzione con NON ESISTE sembra essere il più produttivo in quanto genera il predicato pushdown più ottimale operatore per accedere ai dati della seconda tabella.
In realtà, i valori NULL possono restituire un risultato imprevisto.
Consideralo su questo esempio particolare:
USE AdventureWorks2014 GO SELECT COUNT_BIG(*) FROM Production.Product SELECT COUNT_BIG(*) FROM Production.Product WHERE Color = 'Grey' SELECT COUNT_BIG(*) FROM Production.Product WHERE Color <> 'Grey'
Come puoi vedere, non hai ottenuto il risultato atteso perché i valori NULL hanno operatori di confronto separati:
SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NULL SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NOT NULL
Ecco un altro esempio con CHECK vincoli:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (
Color VARCHAR(15) --NULL
, CONSTRAINT CK CHECK (Color IN ('Black', 'White'))
) Creiamo una tabella con il permesso di inserire solo i colori bianco e nero:
INSERT INTO #temp VALUES ('Black')
(1 row(s) affected) Tutto funziona come previsto.
INSERT INTO #temp VALUES ('Red')
The INSERT statement conflicted with the CHECK constraint...
The statement has been terminated. Ora aggiungiamo NULL:
INSERT INTO #temp VALUES (NULL) (1 row(s) affected)
Perché il vincolo CHECK ha superato il valore NULL? Bene, il motivo è che c'è abbastanza il NON FALSO condizione per fare un record. La soluzione alternativa consiste nel definire esplicitamente una colonna come NON NULL oppure usa NULL nel vincolo.
Formato data
Molto spesso potresti avere difficoltà con i tipi di dati.
Ad esempio, è necessario ottenere la data corrente. Per fare ciò, puoi utilizzare la funzione GETDATE:
SELECT GETDATE()
Quindi copia semplicemente il risultato restituito in una query richiesta ed elimina l'ora:
SELECT * FROM sys.objects WHERE create_date < '2016-11-14'
È corretto?
La data è specificata da una costante stringa:
SET LANGUAGE English
SET DATEFORMAT DMY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4 Tutti i valori hanno un'interpretazione a un valore:
----------- ----------- ----------- ----------- 2016-12-05 2016-05-12 2016-05-12 2016-12-05
Non causerà alcun problema fino a quando la query con questa logica aziendale non verrà eseguita su un altro server in cui le impostazioni potrebbero differire:
SET DATEFORMAT MDY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4 Tuttavia, queste opzioni possono portare a un'interpretazione errata della data:
----------- ----------- ----------- ----------- 2016-05-12 2016-12-05 2016-12-05 2016-12-05
Inoltre, questo codice può portare sia a un bug visibile che latente.
Considera il seguente esempio. Abbiamo bisogno di inserire i dati in una tabella di test. Su un server di prova tutto funziona perfettamente:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016') Tuttavia, sul lato client questa query avrà problemi poiché le impostazioni del nostro server differiscono:
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016') Msg 242, Level 16, State 3, Line 28 The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
Quindi, quale formato dovremmo usare per dichiarare le costanti di data? Per rispondere a questa domanda, esegui questa query:
SET DATEFORMAT YMD
SET LANGUAGE English
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
GO
SET LANGUAGE Deutsch
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
L'interpretazione delle costanti può variare a seconda della lingua installata:
----------- ----------- ----------- -----------
2016-01-12 2016-01-12 2016-01-12 2016-01-12
----------- ----------- ----------- -----------
2016-12-01 2016-12-01 2016-01-12 2016-01-12 Pertanto, è meglio utilizzare le ultime due opzioni. Inoltre, vorrei aggiungere che specificare esplicitamente la data non è una buona idea:
SET LANGUAGE French DECLARE @d DATETIME = '12-jan-2016' Msg 241, Level 16, State 1, Line 29 Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Pertanto, se vuoi che le costanti con le date vengano interpretate correttamente, devi specificarle nel seguente formato AAAAMMGG.
Inoltre, vorrei attirare la vostra attenzione sul comportamento di alcuni tipi di dati:
SET LANGUAGE English
SET DATEFORMAT YMD
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
GO
SET LANGUAGE Deutsch
SET DATEFORMAT DMY
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2 A differenza di DATETIME, la DATE type viene interpretato correttamente con varie impostazioni su un server:
---------- ---------- 2016-01-12 2016-01-12 ---------- ---------- 2016-01-12 2016-12-01
Filtro data
Per andare avanti, considereremo come filtrare i dati in modo efficace. Cominciamo da loro DATETIME/DATE:
USE AdventureWorks2014 GO UPDATE TOP(1) dbo.DatabaseLog SET PostTime = '20140716 12:12:12'
Ora proveremo a scoprire quante righe restituisce la query per un giorno specificato:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime = '20140716'
La query restituirà 0. Durante la creazione di un piano di esecuzione, SQL Server tenta di eseguire il cast di una stringa costante sul tipo di dati della colonna che dobbiamo filtrare:
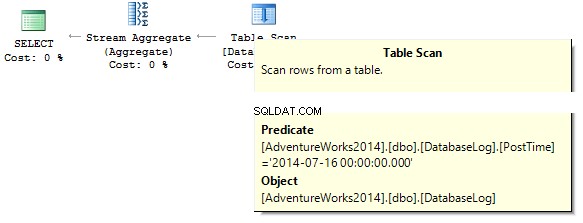
Crea un indice:
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)
Esistono opzioni corrette e non corrette per l'output dei dati. Ad esempio, devi eliminare la colonna dell'ora:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CAST(PostTime AS DATE) = '20140716'
Oppure dobbiamo specificare un intervallo:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140716' AND PostTime < '20140717'
Tenendo conto dell'ottimizzazione, posso dire che queste due query sono le più corrette. Il punto è che tutte le conversioni e i calcoli delle colonne dell'indice che vengono filtrate possono ridurre drasticamente le prestazioni e aumentare il tempo delle letture logiche:
Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 2, ...
Il PostTime campo non era stato incluso nell'indice prima e non abbiamo potuto vedere alcuna efficienza nell'utilizzo di questo approccio corretto nel filtraggio. Un'altra cosa è quando dobbiamo produrre dati per un mese:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE DATEPART(YEAR, PostTime) = 2014
AND DATEPART(MONTH, PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE YEAR(PostTime) = 2014
AND MONTH(PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE EOMONTH(PostTime) = '20140731'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801' Ancora una volta, quest'ultima opzione è più preferibile:
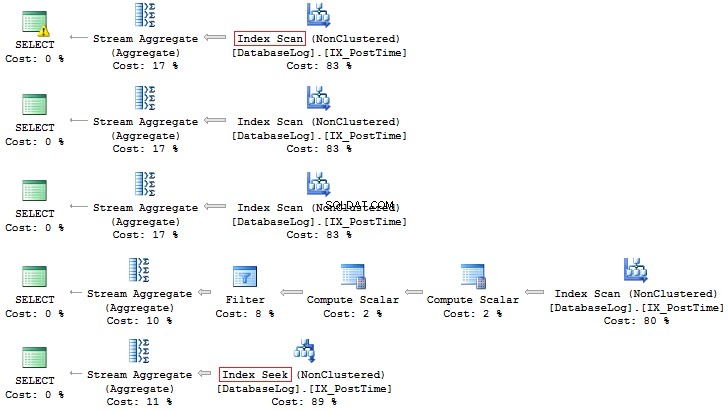
Inoltre, puoi sempre creare un indice basato su un campo calcolato:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL
ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay
GO
ALTER TABLE dbo.DatabaseLog
ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED
GO
CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay) Rispetto alla query precedente, la differenza nelle letture logiche può essere significativa (se sono in questione tabelle di grandi dimensioni):
SET STATISTICS IO ON SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140701' AND PostTime < '20140801' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE MonthLastDay = '20140731' SET STATISTICS IO OFF Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 3, ...
Calcolo
Come è già stato discusso, qualsiasi calcolo sulle colonne dell'indice diminuisce le prestazioni e aumenta il tempo di lettura logica:
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID * 2 = 10000 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 2500 * 2 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 5000 Table 'Person'. Scan count 1, logical reads 67, ... Table 'Person'. Scan count 0, logical reads 3, ...
Se esaminiamo i piani di esecuzione, nel primo SQL Server esegue IndexScan :
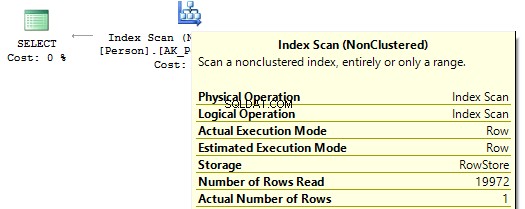
Quindi, quando non ci sono calcoli sulle colonne dell'indice, vedremo IndexSeek :

Convertire implicito
Diamo un'occhiata a queste due query che filtrano per lo stesso valore:
USE AdventureWorks2014 GO SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 30845 SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = '30845'
I piani di esecuzione forniscono le seguenti informazioni:
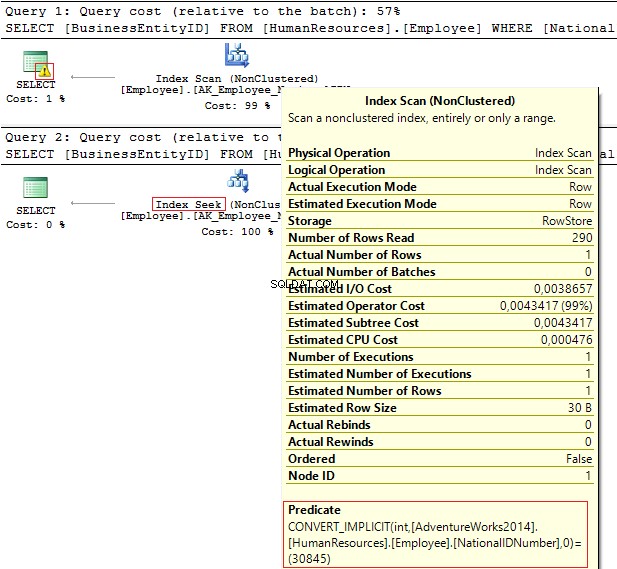
- Avviso e IndexScan al primo piano
- Ricerca indice – sul secondo.
Table 'Employee'. Scan count 1, logical reads 4, ... Table 'Employee'. Scan count 0, logical reads 2, ...
Il Numero ID Nazionale la colonna contiene NVARCHAR(15) tipo di dati. La costante che utilizziamo per filtrare i dati è impostata come INT che ci porta a una conversione implicita del tipo di dati. A sua volta, potrebbe ridurre le prestazioni. Puoi monitorarlo quando qualcuno modifica il tipo di dati nella colonna, tuttavia, le query non vengono modificate.
È importante comprendere che una conversione implicita del tipo di dati può causare errori in fase di esecuzione. Ad esempio, prima che il campo PostalCode fosse numerico, si è scoperto che un codice postale poteva contenere lettere. Pertanto, il tipo di dati è stato aggiornato. Tuttavia, se inseriamo un codice postale alfabetico, la vecchia query non funzionerà più:
SELECT AddressID FROM Person.[Address] WHERE PostalCode = 92700 SELECT AddressID FROM Person.[Address] WHERE PostalCode = '92700' Msg 245, Level 16, State 1, Line 16 Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
Un altro esempio è quando devi usare EntityFramework sul progetto, che per impostazione predefinita interpreta tutti i campi riga come Unicode:
SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = N'AW00000009' SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = 'AW00000009'
Pertanto, vengono generate query errate:

Per risolvere questo problema, assicurati che i tipi di dati corrispondano.
MI PIACE e indice soppresso
Infatti, avere un indice di copertura non significa che lo utilizzerai in modo efficace.
Controlliamolo su questo particolare esempio. Supponiamo di dover restituire tutte le righe che iniziano con...
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT AddressLine1 FROM Person.[Address] WHERE SUBSTRING(AddressLine1, 1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE LEFT(AddressLine1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE CAST(AddressLine1 AS CHAR(3)) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '100%'
Otterremo le seguenti letture logiche e piani di esecuzione:
Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 4, ...
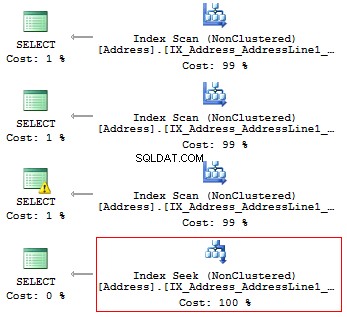
Pertanto, se esiste un indice, non dovrebbe contenere calcoli o conversioni di tipi, funzioni, ecc.
Ma cosa fai se devi trovare l'occorrenza di una sottostringa in una stringa?
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'v
Torneremo su questa domanda più avanti.
Unicode vs ANSI
È importante ricordare che ci sono gli UNICODE e ANSI stringhe. Il tipo UNICODE include NVARCHAR/NCHAR (2 byte per un simbolo). Per memorizzare ANSI stringhe, è possibile utilizzare VARCHAR/CHAR (da 1 byte a 1 simbolo). C'è anche TESTO/NEXT , ma non consiglio di usarli in quanto potrebbero ridurre le prestazioni.
Se si specifica una costante Unicode in una query, è necessario precederla con il simbolo N. Per verificarlo, esegui la seguente query:
SELECT '文本 ANSI'
, N'文本 UNICODE'
------- ------------
?? ANSI 文本 UNICODE Se N non precede la costante, SQL Server tenterà di trovare un simbolo adatto nella codifica ANSI. Se non riesce a trovare, mostrerà un punto interrogativo.
COLLEGA
Molto spesso, quando viene intervistato per la posizione di sviluppatore DB Medio/Senior, un intervistatore fa spesso la seguente domanda:questa query restituirà i dati?
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b Dipende. In primo luogo, il simbolo N non precede una costante stringa, quindi verrà interpretato come ANSI. In secondo luogo, molto dipende dal valore COLLATE corrente, che è un insieme di regole, quando si seleziona e si confrontano i dati della stringa.
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b Questa dichiarazione COLLATE restituirà punti interrogativi poiché i loro simboli sono uguali:
---- ---- ? ?
Se cambiamo l'istruzione COLLATE con un'altra istruzione:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
In questo caso, la query non restituirà nulla, poiché i caratteri cirillici verranno interpretati correttamente.
Pertanto, se una costante stringa occupa UNICODE, è necessario impostare N prima di una costante stringa. Tuttavia, non consiglierei di impostarlo ovunque per i motivi di cui abbiamo discusso sopra.
Un'altra domanda da porsi nell'intervista riguarda il confronto delle righe.
Considera il seguente esempio:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a = @b, 'TRUE', 'FALSE') Queste righe sono uguali? Per verificarlo, dobbiamo specificare esplicitamente COLLATE:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE') Poiché ci sono le COLLATE con distinzione tra maiuscole e minuscole (CS) e senza distinzione tra maiuscole e minuscole (CI) quando si confrontano e si selezionano le righe, non possiamo dire con certezza se sono uguali. Inoltre, ci sono varie COLLATE sia su un server di prova che su un lato client.
C'è un caso in cui COLLATEs di una base di destinazione e tempdb non corrispondono.
Crea un database con COLLATE:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT c = CAST('a' AS CHAR(1))
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t Quando si crea una tabella, eredita COLLATE da un database. L'unica differenza per la prima tabella temporanea, per la quale determiniamo esplicitamente una struttura senza COLLATE, è che eredita COLLATE dal tempdb banca dati.
------ -------------------------- tempdb Cyrillic_General_CI_AS test Albanian_100_CS_AS t Albanian_100_CS_AS #t1 Cyrillic_General_CI_AS #t2 Albanian_100_CS_AS #t3 Albanian_100_CS_AS @t Albanian_100_CS_AS
Descriverò il caso in cui COLLATEs non corrisponde nell'esempio particolare con #t1.
Ad esempio, i dati non vengono filtrati correttamente, poiché COLLATE potrebbe non tenere conto di un caso:
SELECT * FROM #t1 WHERE c = 'A'
In alternativa, potremmo avere un conflitto per connettere tabelle con COLLATE differenti:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c
Tutto sembra funzionare perfettamente su un server di prova, mentre su un server client viene visualizzato un errore:
Msg 468, Level 16, State 9, Line 93 Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.
Per aggirare il problema, dobbiamo impostare hack ovunque:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c COLLATE database_default
RACCOLTA BINARIA
Ora scopriremo come utilizzare COLLATE a tuo vantaggio.
Considera l'esempio con l'occorrenza di una sottostringa in una stringa:
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
È possibile ottimizzare questa query e ridurne il tempo di esecuzione.
All'inizio, dobbiamo generare una tabella di grandi dimensioni:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NOT NULL
, unicod NVARCHAR(100) NOT NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) t Crea colonne calcolate con COLLATE binari e indici:
ALTER TABLE t
ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2
ALTER TABLE t
ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2
CREATE NONCLUSTERED INDEX ansi ON t (ansi)
CREATE NONCLUSTERED INDEX unicod ON t (unicod)
CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin)
CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin) Eseguire il processo di filtraggio:
SET STATISTICS TIME, IO ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME, IO OFF
Come puoi vedere, questa query restituisce il seguente risultato:
SQL Server Execution Times: CPU time = 350 ms, elapsed time = 354 ms. SQL Server Execution Times: CPU time = 335 ms, elapsed time = 355 ms. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 18 ms. SQL Server Execution Times: CPU time = 17 ms, elapsed time = 18 ms.
Il punto è che il filtro basato sul confronto binario richiede meno tempo. Pertanto, se è necessario filtrare l'occorrenza di stringhe frequentemente e rapidamente, è possibile memorizzare i dati con COLLATE che termina con BIN. Tuttavia, va notato che tutti i COLLATE binari fanno distinzione tra maiuscole e minuscole.
Stile del codice
Uno stile di codifica è strettamente individuale. Tuttavia, questo codice dovrebbe essere semplicemente mantenuto da altri sviluppatori e soddisfare determinate regole.
Crea un database separato e una tabella all'interno:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_CI_AS
GO
USE test
GO
CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)
Quindi, scrivi la query:
select employeeid from employee
Ora, cambia COLLATE in uno qualsiasi con distinzione tra maiuscole e minuscole:
ALTER DATABASE test COLLATE Latin1_General_CS_AI
Quindi, prova a eseguire nuovamente la query:
Msg 208, Level 16, State 1, Line 19 Invalid object name 'employee'.
Un ottimizzatore utilizza le regole per il COLLATE corrente nella fase di associazione quando controlla tabelle, colonne e altri oggetti e confronta ogni oggetto dell'albero della sintassi con un oggetto reale di un catalogo di sistema.
Se desideri generare query manualmente, devi utilizzare sempre il caso corretto nei nomi degli oggetti.
Per quanto riguarda le variabili, le COLLATE vengono ereditate dal database master. Pertanto, è necessario utilizzare anche il caso corretto per lavorare con loro:
SELECT DATABASEPROPERTYEX('master', 'collation')
DECLARE @EmpID INT = 1
SELECT @empid In questo caso, non riceverai un errore:
----------------------- Cyrillic_General_CI_AS ----------- 1
Tuttavia, è possibile che venga visualizzato un caso di errore su un altro server:
-------------------------- Latin1_General_CS_AS Msg 137, Level 15, State 2, Line 4 Must declare the scalar variable "@empid".
[var]char
Come sai, ci sono fissi (CHAR , NCHAR ) e variabile (VARCHAR , NVARCHAR ) tipi di dati:
DECLARE @a CHAR(20) = 'text'
, @b VARCHAR(20) = 'text'
SELECT LEN(@a)
, LEN(@b)
, DATALENGTH(@a)
, DATALENGTH(@b)
, '"' + @a + '"'
, '"' + @b + '"'
SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE')
, [b = a] = IIF(@b = @a, 'TRUE', 'FALSE')
, [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE')
, [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE') Se una riga ha una lunghezza fissa, diciamo 20 simboli, ma hai scritto solo 4 simboli, SQL Server aggiungerà 16 spazi vuoti a destra per impostazione predefinita:
--- --- ---- ---- ---------------------- ---------------------- 4 4 20 4 "text " "text"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a = b b = a a LIKE b b LIKE a ----- ----- -------- -------- TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1 WHERE 'a ' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a ' -- !!! SELECT 1 WHERE 'a' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL
, @b VARCHAR(10) = '0.1'
, @c SQL_VARIANT
SELECT @a = @b
, @c = @a
SELECT @a
, @c
, SQL_VARIANT_PROPERTY(@c,'BaseType')
, SQL_VARIANT_PROPERTY(@c,'Precision')
, SQL_VARIANT_PROPERTY(@c,'Scale') As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- ----- 0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ---- 40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) = NULL SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL') DECLARE @i INT = NULL SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ---- N NULL ---- ---- 7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3 SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
----------- 0 ----------- 0.333333
Also, let’s consider this particular example:
SELECT COUNT(*)
, COUNT(1)
, COUNT(val)
, COUNT(DISTINCT val)
, SUM(val)
, SUM(DISTINCT val)
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
SELECT AVG(val)
, SUM(val) / COUNT(val)
, AVG(val * 1.)
, AVG(CAST(val AS FLOAT))
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val) This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id] FROM sys.system_objects UNION SELECT [object_id] FROM sys.objects SELECT [object_id] FROM sys.system_objects UNION ALL SELECT [object_id] FROM sys.objects
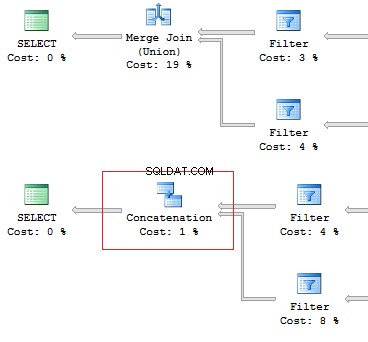
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)
SET @AddressLine = '4775 Kentucky Dr.'
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
OR AddressLine2 = @AddressLine As we have OR in the statement, we will receive IndexScan:
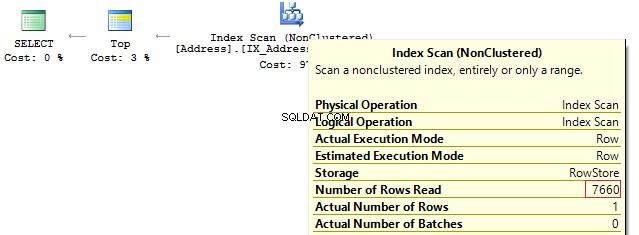
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressID
FROM (
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
UNION ALL
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine2 = @AddressLine
) t When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
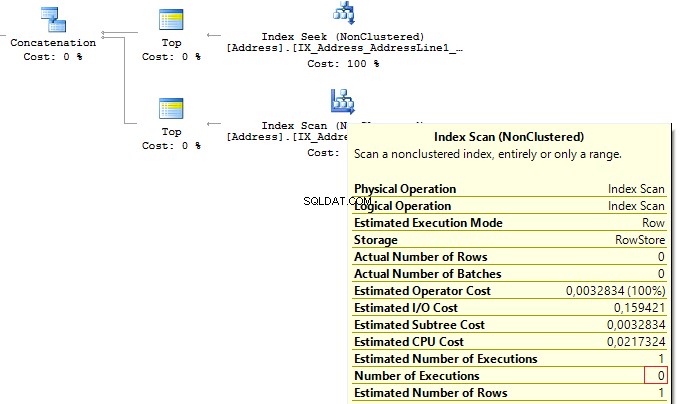
Table 'Worktable'. Scan count 0, logical reads 0, ... Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT e.BusinessEntityID
, (
SELECT p.LastName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
, (
SELECT p.FirstName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
FROM HumanResources.Employee e
SELECT e.BusinessEntityID
, p.LastName
, p.FirstName
FROM HumanResources.Employee e
JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ... Table 'Employee'. Scan count 1, logical reads 2, ... Table 'Person'. Scan count 0, logical reads 888, ... Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT p.BusinessEntityID
, (
SELECT s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
)
FROM Person.Person p However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID
, (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
)
FROM Person.Person p
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
OUTER APPLY (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
) t When executing these queries, we will get the same issue – multiple IndexSeek operators:
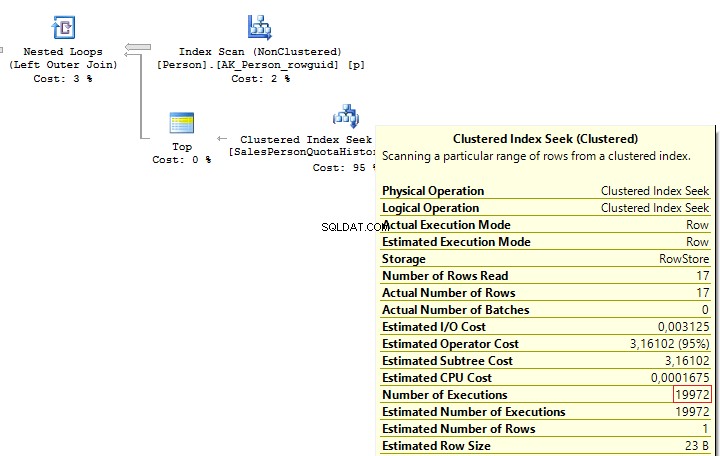
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ... Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
LEFT JOIN (
SELECT s.BusinessEntityID
, s.SalesQuota
, RowNum = ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC)
FROM Sales.SalesPersonQuotaHistory s
) t ON p.BusinessEntityID = t.BusinessEntityID
AND t.RowNum = 1 We get the following result:
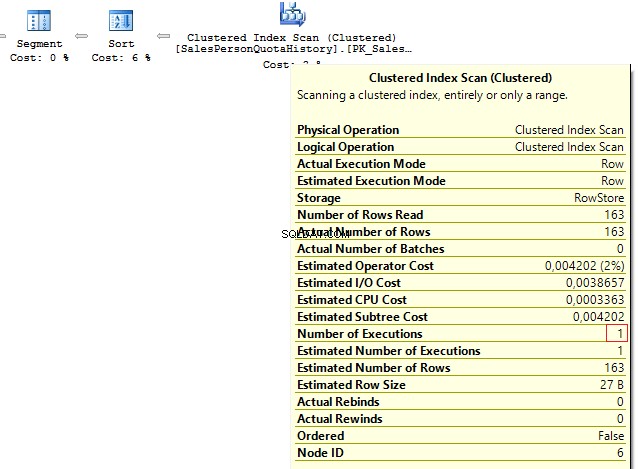
Table 'Person'. Scan count 1, logical reads 67, ... Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014
GO
SELECT BusinessEntityID
, Gender
, Gender =
CASE Gender
WHEN 'M' THEN 'Male'
WHEN 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee SQL Server will decompose the statement to the following:
SELECT BusinessEntityID
, Gender
, Gender =
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL
DROP FUNCTION dbo.GetMailUrl
GO
CREATE FUNCTION dbo.GetMailUrl
(
@Email NVARCHAR(50)
)
RETURNS NVARCHAR(50)
AS BEGIN
RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))
END Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
--WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID
, EmailAddress
, CASE MailUrl
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM (
SELECT TOP(10) EmailAddressID
, EmailAddress
, MailUrl = dbo.GetMailUrl(EmailAddress)
FROM Person.EmailAddress
) t In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'M' THEN '...'
WHEN Gender = 'M' THEN '......'
WHEN Gender = 'F' THEN 'Female'
WHEN Gender = 'F' THEN '...'
ELSE 'Unknown'
END
FROM HumanResources.Employee Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE 1/0
END
GO
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE MIN(1/0)
END Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014
GO
UPDATE TOP(1) Person.[Address]
SET AddressLine2 = AddressLine1
GO
IF OBJECT_ID('dbo.isEqual') IS NOT NULL
DROP FUNCTION dbo.isEqual
GO
CREATE FUNCTION dbo.isEqual
(
@val1 NVARCHAR(100),
@val2 NVARCHAR(100)
)
RETURNS BIT
AS BEGIN
RETURN
CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2
THEN 1
ELSE 0
END
END The queries return the identical data:
SET STATISTICS TIME ON
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE dbo.IsEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL)
OR AddressLine1 = AddressLine2
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFF However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times: CPU time = 63 ms, elapsed time = 57 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL
DROP FUNCTION dbo.GetPI
GO
CREATE FUNCTION dbo.GetPI ()
RETURNS FLOAT
WITH SCHEMABINDING
AS BEGIN
RETURN PI()
END
GO
SELECT dbo.GetPI()
FROM Sales.Currency In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (a INT, b INT)
GO
INSERT INTO dbo.tbl VALUES (0, 1)
GO
IF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL
DROP VIEW dbo.vw_tbl
GO
CREATE VIEW dbo.vw_tbl
AS
SELECT * FROM dbo.tbl
GO
SELECT * FROM dbo.vw_tbl As you can see, we get the correct result:
a b ----------- ----------- 0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl
ADD c INT NOT NULL DEFAULT 2
GO
SELECT * FROM dbo.vw_tbl We receive the same result:
a b ----------- ----------- 0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname = N'dbo.vw_tbl' GO SELECT * FROM dbo.vw_tbl
Result:
a b c ----------- ----------- ----------- 0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployee
AS
SELECT e.BusinessEntityID
, p.Title
, p.FirstName
, p.MiddleName
, p.LastName
, p.Suffix
, e.JobTitle
, pp.PhoneNumber
, pnt.[Name] AS PhoneNumberType
, ea.EmailAddress
, p.EmailPromotion
, a.AddressLine1
, a.AddressLine2
, a.City
, sp.[Name] AS StateProvinceName
, a.PostalCode
, cr.[Name] AS CountryRegionName
, p.AdditionalContactInfo
FROM HumanResources.Employee e
JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = e.BusinessEntityID
JOIN Person.[Address] a ON a.AddressID = bea.AddressID
JOIN Person.StateProvince sp ON sp.StateProvinceID = a.StateProvinceID
JOIN Person.CountryRegion cr ON cr.CountryRegionCode = sp.CountryRegionCode
LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID
LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID = pnt.PhoneNumberTypeID
LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID
, FirstName
, LastName
FROM HumanResources.vEmployee
SELECT p.BusinessEntityID
, p.FirstName
, p.LastName
FROM Person.Person p
WHERE p.BusinessEntityID IN (
SELECT e.BusinessEntityID
FROM HumanResources.Employee e
) Look at the execution plan in the case of using a view:
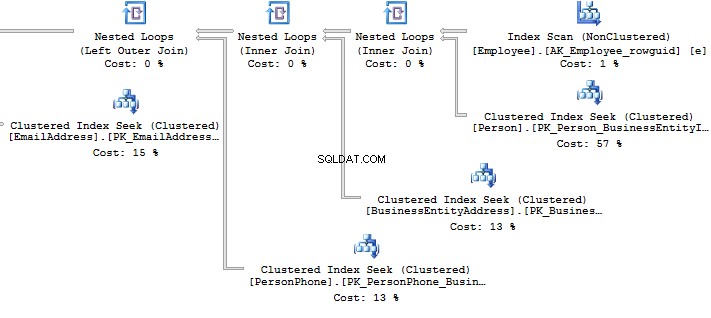
Table 'EmailAddress'. Scan count 290, logical reads 640, ... Table 'PersonPhone'. Scan count 290, logical reads 636, ... Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ... Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
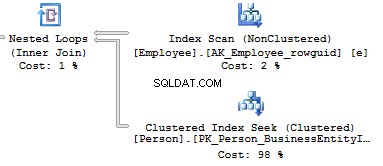
Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INT
DECLARE cur CURSOR FOR
SELECT BusinessEntityID
FROM HumanResources.Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE cur Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.Employee SET VacationHours = 0 WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (i CHAR(1))
INSERT INTO #t
VALUES ('1'), ('2'), ('3') Then, assign values to the variable:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t SELECT @txt -------- 123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t ORDER BY LEN(i) SELECT @txt -------- 3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] = i
FROM #t
FOR XML PATH('')
--------
123 It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
------------------------ ------------------------------------
ScrapReason ScrapReasonID, Name, ModifiedDate
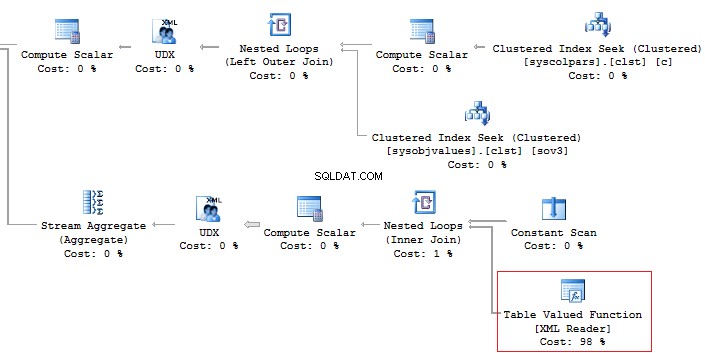
Shift ShiftID, Name, StartTime, EndTime In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U' But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name
, STUFF((
SELECT ', ' + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
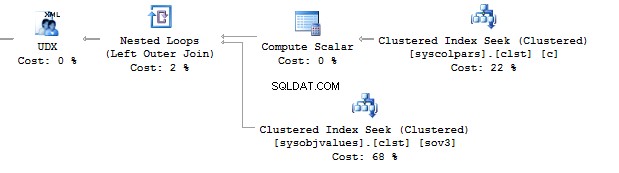
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name
, STUFF((
SELECT ', ' + CHAR(13) + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U' If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX) SET @param = 1 DECLARE @SQL NVARCHAR(MAX) SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = ' + @param PRINT @SQL EXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1
If we add any additional value to the property,
SET @param = '1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id = {0}", value), conn);
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read()) {}
}
} When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)
SET @param = '1; select ''hack'''
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id'
PRINT @SQL
EXEC sys.sp_executesql @SQL
, N'@schema_id INT'
, @schema_id = @param It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
"SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id", conn);
command.Parameters.Add(new SqlParameter("schema_id", value));
...
} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.