PostgreSQL 11 è stato rilasciato il 10 ottobre 2018 e nei tempi previsti, in occasione del 23° anniversario del database open source sempre più popolare.
Mentre un elenco completo delle modifiche è disponibile nelle solite Note di rilascio, vale la pena dare un'occhiata alla pagina rinnovata della Matrice delle funzionalità che, proprio come la documentazione ufficiale, ha ricevuto un restyling sin dalla sua prima versione che rende più facile individuare le modifiche prima di immergersi nei dettagli .
Ad esempio, nella pagina Note di rilascio, il "binding del canale per l'autenticazione SCAM" è sepolto sotto il codice sorgente mentre la matrice lo ha nella sezione Sicurezza. Per i curiosi ecco uno screenshot dell'interfaccia:
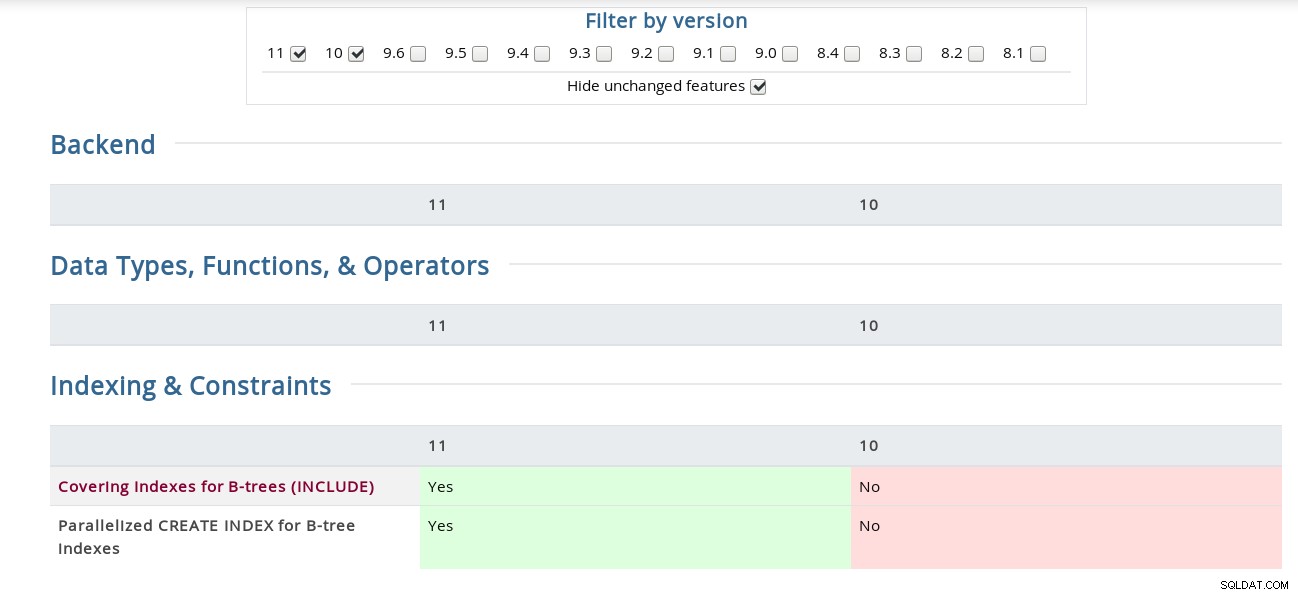 Matrice delle funzionalità PostgreSQL
Matrice delle funzionalità PostgreSQL Inoltre, la pagina delle note sulla versione di Bucardo Postgres collegata sopra è utile a modo suo, rendendo facile la ricerca di una parola chiave in tutte le versioni.
Cosa c'è di nuovo? Con letteralmente centinaia di modifiche, esaminerò le differenze elencate nella Matrice delle funzionalità.
Indici di copertura per alberi B (INCLUDE)
CREATE INDEX ha ricevuto la clausola INCLUDE che consente agli indici di includere colonne non chiave . Il suo caso d'uso per frequenti query identiche è ben descritto nel commit di Tom Lane del 22 novembre, che aggiorna la documentazione di sviluppo (il che significa che l'attuale documentazione di PostgreSQL 11 non l'ha ancora), quindi per il testo completo fare riferimento alla sezione 11.9. Scansioni solo indice e indici di copertura nella versione di sviluppo.
CREA INDICE PARALLELIZZATO per gli indici B-tree
Come accennato nel nome, questa funzionalità è implementata solo per gli indici B-tree e dal log di commit di Robert Haas apprendiamo che l'implementazione potrebbe essere perfezionata in futuro. Come notato dalla documentazione CREATE INDEX, mentre i metodi di creazione dell'indice sia parallela che simultanea sfruttano più CPU, nel caso di CONCURRENT verrà eseguita solo la prima scansione della tabella in parallelo.
Relativi a questa nuova funzionalità sono i parametri di configurazione maintenance_work_mem e maintenance_parallel_maintenance_workers .
Infine, è possibile impostare il numero di lavoratori paralleli per tabella utilizzando il comando ALTER TABLE e specificando un valore per lavoratori_paralleli .
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri ciò che devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperCompilazione Just-In-Time (JIT) per la valutazione delle espressioni e la deformazione delle tuple
Con il proprio capitolo JIT nella documentazione, questa nuova funzionalità si basa sulla compilazione di PostgreSQL con il supporto LLVM (usa pg_config per verificare).
L'argomento JIT in PostgreSQL è abbastanza complesso (vedi il riferimento JIT README nella documentazione) da richiedere un blog dedicato, nel frattempo il blog CitusData su JIT è un'ottima lettura per chi è interessato ad approfondire l'argomento.
Unisci hash paralleli
Questo miglioramento delle prestazioni delle query parallele è il risultato dell'aggiunta di una tabella hash condivisa che, come spiega Thomas Munro nel suo blog Parallel Hash for PostgreSQL, evita di partizionare la tabella hash a condizione che rientri in work_mem , che finora per PostgreSQL sembra essere una soluzione migliore rispetto all'algoritmo partition-first. Lo stesso blog descrive gli ostacoli dell'architettura PostgreSQL che l'autore ha dovuto superare nella sua ricerca per aggiungere parallelizzazione agli hash join che parla della complessità del lavoro necessario per implementare questa funzionalità.
Partizione predefinita
Questa è una partizione catch all per archiviare righe che non corrispondono a nessun'altra partizione definita. Nei casi in cui viene aggiunta una nuova partizione, si consiglia un vincolo CHECK per evitare una scansione della partizione predefinita che può essere lenta quando la partizione predefinita contiene un numero elevato di righe.
Il comportamento della partizione predefinita è spiegato nella documentazione di ALTER TABLE e CREATE TABLE.
Partizionamento tramite una chiave hash
Chiamata anche partizionamento hash e, come sottolineato nel messaggio di commit, la funzione consente il partizionamento delle tabelle in modo tale che le partizioni contengano un numero simile di righe. Ciò si ottiene fornendo un modulo, che nello scenario più semplice è consigliato essere uguale al numero di partizioni e il resto dovrebbe essere diverso per ciascuna partizione.
Per maggiori dettagli e un esempio, vedere la pagina della documentazione CREATE TABLE.
Supporto per CHIAVE PRIMARIA, CHIAVE ESTERA, indici e trigger su tabelle partizionate
Il partizionamento delle tabelle è già un grande passo avanti nel miglioramento delle prestazioni di tabelle di grandi dimensioni e l'aggiunta di queste funzionalità risolve i limiti che le tabelle partizionate hanno avuto da PostgreSQL 10, quando è stato introdotto il "partizionamento dichiarativo" in stile moderno.
È in corso il lavoro di Alvaro Herrera per consentire alle chiavi esterne di fare riferimento alle chiavi primarie ed è previsto per la prossima versione principale di PostgreSQL 12.
AGGIORNAMENTO su una chiave di partizione
Come spiegato nel log del commit della patch, questo aggiornamento impedisce a PostgreSQL di generare un errore quando un aggiornamento della chiave di partizione invalida una riga, e invece la riga verrà spostata in una partizione appropriata.
Associazione del canale per l'autenticazione SCRAM
Questa è una misura di sicurezza volta a prevenire attacchi man-in-the-middle nell'autenticazione SASL ed è dettagliatamente dettagliata nel blog dell'autore. La funzione richiede un minimo di OpenSSL 1.0.2.
CREA PROCEDURE e CALL sintassi per le stored procedure SQL
PostgreSQL ha CREATE FUNCTION dal 1996, con la versione 1.0.1 , tuttavia, le funzioni non possono gestire le transazioni. Come accennato nella documentazione, il comando CREATE PROCEDURE non è completamente compatibile con lo standard SQL.
Nota:resta sintonizzato per un blog in arrivo che approfondisce questa funzione
Conclusione
I principali aggiornamenti di PostgreSQL 11 si concentrano sui miglioramenti delle prestazioni attraverso l'esecuzione parallela, il partizionamento e la compilazione Just-In-Time. Le stored procedure consentono il controllo completo delle transazioni e possono essere scritte in una varietà di linguaggi PL.