SQL Server ci fornisce una serie di funzioni della finestra che ci aiutano a eseguire calcoli su un insieme di righe, senza la necessità di ripetere le chiamate al database. A differenza delle funzioni di aggregazione standard, le funzioni di finestra non raggrupperanno le righe in un'unica riga di output, ma restituiranno un unico valore aggregato per ciascuna riga, mantenendo le identità separate per quelle righe. Il termine Window qui non è correlato al sistema operativo Microsoft Windows, descrive l'insieme di righe che la funzione elaborerà.
Uno dei tipi più utili di funzioni della finestra è Classificazione delle funzioni della finestra che vengono utilizzate per classificare valori di campo specifici e categorizzarli in base al rango di ciascuna riga, ottenendo un unico valore aggregato per ogni riga partecipata. Esistono quattro funzioni della finestra di classificazione supportate in SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE(). Tutte queste funzioni vengono utilizzate per calcolare ROWID per la finestra di righe fornita a modo loro.
Quattro funzioni della finestra di classificazione utilizzano la clausola OVER() che definisce un insieme di righe specificato dall'utente all'interno di un insieme di risultati della query. Definendo la clausola OVER(), puoi anche includere la clausola PARTITION BY che determina l'insieme di righe che la funzione window elaborerà, fornendo colonne o colonne separate da virgole per definire la partizione. Inoltre, può essere inclusa la clausola ORDER BY, che definisce i criteri di ordinamento all'interno delle partizioni che la funzione passerà attraverso le righe durante l'elaborazione.
In questo articolo, discuteremo come utilizzare quattro funzioni della finestra di classificazione:ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE() praticamente e la differenza tra loro.
Per servire la nostra demo, creeremo una nuova tabella semplice e inseriremo alcuni record nella tabella usando lo script T-SQL di seguito:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
È possibile verificare che i dati siano stati inseriti correttamente utilizzando la seguente istruzione SELECT:
SELECT * FROM StudentScore ORDER BY Student_ScoreCon il risultato ordinato applicato, il set di risultati è il seguente:

RIGA_NUMERO()
La funzione della finestra di classificazione ROW_NUMBER() restituisce un numero sequenziale univoco per ogni riga all'interno della partizione della finestra specificata, a partire da 1 per la prima riga in ciascuna partizione e senza ripetere o saltare i numeri nel risultato di classificazione di ciascuna partizione. Se sono presenti valori duplicati all'interno del set di righe, i numeri ID classifica verranno assegnati arbitrariamente. Se viene specificata la clausola PARTITION BY, il numero di riga della classifica verrà azzerato per ciascuna partizione. Nella tabella precedentemente creata, la query seguente mostra come utilizzare la funzione della finestra della classifica ROW_NUMBER per classificare le righe della tabella StudentScore in base al punteggio di ogni studente:
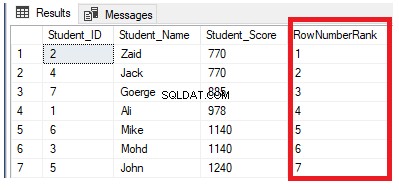
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
È chiaro dal set di risultati di seguito che la funzione della finestra ROW_NUMBER classifica le righe della tabella in base ai valori della colonna Student_Score per ciascuna riga, generando un numero univoco di ciascuna riga che riflette la sua classifica Student_Score a partire dal numero 1 senza duplicati o lacune e gestire tutte le righe come una partizione. Puoi anche vedere che i punteggi duplicati sono assegnati casualmente a diversi gradi:
Se modifichiamo la query precedente includendo la clausola PARTITION BY per avere più di una partizione, come mostrato nella query T-SQL di seguito:
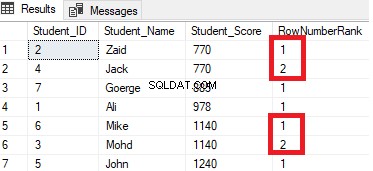
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Il risultato mostrerà che la funzione della finestra ROW_NUMBER classificherà le righe della tabella in base ai valori della colonna Student_Score per ciascuna riga, ma tratterà le righe che hanno lo stesso valore Student_Score di una partizione. Vedrai che verrà generato un numero univoco per ogni riga che riflette la sua classifica Student_Score, a partire dal numero 1 senza duplicati o lacune all'interno della stessa partizione, reimpostando il numero della classifica quando si passa a un valore Student_Score diverso.
Ad esempio, gli studenti con punteggio 770 verranno classificati all'interno di quel punteggio assegnandogli un numero di grado. Tuttavia, quando viene spostato allo studente con punteggio 885, il numero di partenza della classifica verrà ripristinato per ricominciare da 1, come mostrato di seguito:
GRADO()
La funzione della finestra di classificazione RANK() restituisce un numero di rango univoco per ogni riga distinta all'interno della partizione in base a un valore di colonna specificato, a partire da 1 per la prima riga in ogni partizione, con lo stesso rango per valori duplicati e lasciando spazi tra i ranghi; questo spazio appare nella sequenza dopo i valori duplicati. In altre parole, la funzione della finestra di classificazione RANK() si comporta come la funzione ROW_NUMBER() ad eccezione delle righe con valori uguali, dove verrà classificata con lo stesso ID di classificazione e genererà uno spazio vuoto dopo di essa. Se modifichiamo la query di classificazione precedente per utilizzare la funzione di classificazione RANK():
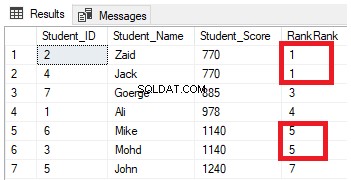
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreVedrai dal risultato che la funzione della finestra RANK classificherà le righe della tabella in base ai valori della colonna Student_Score per ciascuna riga, con un valore di ranking che riflette il suo Student_Score a partire dal numero 1 e classificherà le righe che hanno lo stesso Student_Score con il stesso valore di rango. Puoi anche vedere che due righe con Student_Score uguale a 770 sono classificate con lo stesso valore, lasciando uno spazio, che è il numero mancato 2, dopo la seconda riga in classifica. Lo stesso accade con le righe in cui Student_Score è uguale a 1140 che sono classificate con lo stesso valore, lasciando uno spazio, che è il numero mancante 6, dopo la seconda riga, come mostrato di seguito:
Modifica della query precedente includendo la clausola PARTITION BY per avere più di una partizione, come mostrato nella query T-SQL di seguito:
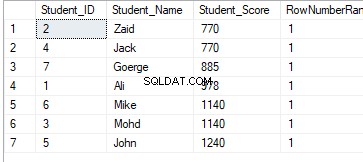
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreIl risultato della classifica non avrà alcun significato, poiché la classifica verrà eseguita in base ai valori Student_Score per ciascuna partizione e i dati verranno partizionati in base ai valori Student_Score. E poiché ogni partizione avrà righe con gli stessi valori Student_Score, le righe con gli stessi valori Student_Score nella stessa partizione verranno classificate con un valore pari a 1. Pertanto, quando si passa alla seconda partizione, la classifica sarà essere azzerato, ricominciando dal numero 1, avendo tutti i valori di classifica uguali a 1 come di seguito indicato:
DENSE_RANK()
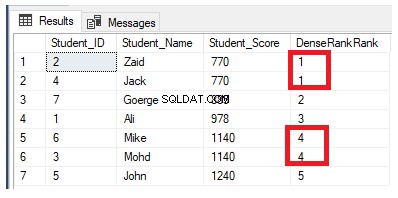
La funzione della finestra di classificazione DENSE_RANK() è simile alla funzione RANK() generando un numero di classifica univoco per ogni riga distinta all'interno della partizione in base a un valore di colonna specificato, a partire da 1 per la prima riga in ogni partizione, classificando le righe con valori uguali con lo stesso numero di rango, tranne per il fatto che non salta alcun rango, senza lasciare spazi tra i ranghi.
Se riscriviamo la query di classificazione precedente per utilizzare la funzione di classificazione DENSE_RANK():
Di nuovo, modifica la query precedente includendo la clausola PARTITION BY per avere più di una partizione, come mostrato nella query T-SQL seguente:
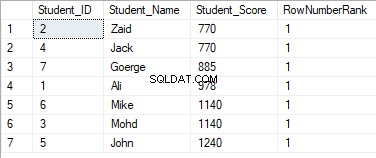
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
I valori della classifica non avranno alcun significato, dove tutte le righe saranno classificate con il valore 1, a causa dell'assegnazione dei valori duplicati allo stesso valore della classifica e della reimpostazione dell'ID iniziale della classifica durante l'elaborazione di una nuova partizione, come mostrato di seguito:
NTILE(N)
La funzione della finestra di classificazione NTILE(N) viene utilizzata per distribuire le righe nelle righe impostate in un numero specificato di gruppi, fornendo a ciascuna riga nella serie di righe un numero di gruppo univoco, a partire dal numero 1 che mostra il gruppo a cui appartiene questa riga a, dove N è un numero positivo, che definisce il numero di gruppi in cui devi distribuire le righe impostate.
In altre parole, se devi dividere righe di dati specifiche della tabella in 3 gruppi, in base a particolari valori di colonna, la funzione della finestra di classificazione NTILE(3) ti aiuterà a raggiungere questo obiettivo facilmente.
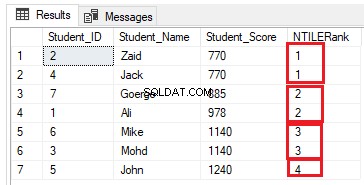
Il numero di righe in ogni gruppo può essere calcolato dividendo il numero di righe nel numero richiesto di gruppi. Se modifichiamo la query di classificazione precedente per utilizzare la funzione finestra di classificazione NTILE(4) per classificare sette righe di tabella in quattro gruppi come query T-SQL di seguito:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Il numero di righe dovrebbe essere (7/4=1,75) righe in ogni gruppo. Utilizzando la funzione NTILE(), SQL Server Engine assegnerà 2 righe ai primi tre gruppi e una riga all'ultimo gruppo, in modo da includere tutte le righe nei gruppi, come mostrato nel set di risultati di seguito:
Modifica della query precedente includendo la clausola PARTITION BY per avere più di una partizione, come mostrato nella query T-SQL di seguito:
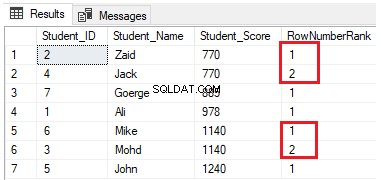
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreLe righe verranno distribuite in quattro gruppi su ciascuna partizione. Ad esempio, le prime due righe con Student_Score uguale a 770 saranno nella stessa partizione, e saranno distribuite all'interno dei gruppi classificati ognuno con un numero univoco, come mostrato nel set di risultati di seguito:
Mettere tutto insieme
Per avere uno scenario di confronto più chiaro, tronchiamo la tabella precedente, aggiungiamo un altro criterio di classificazione, che è la classe degli studenti, e infine inseriamo nuove sette righe utilizzando lo script T-SQL di seguito:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Successivamente, classificheremo sette righe in base al punteggio di ogni studente, suddividendo gli studenti in base alla loro classe. In altre parole, ogni partizione includerà una classe e ogni classe di studenti sarà classificata in base ai punteggi ottenuti all'interno della stessa classe, utilizzando quattro funzioni della finestra di classificazione precedentemente descritte, come mostrato nello script T-SQL di seguito:
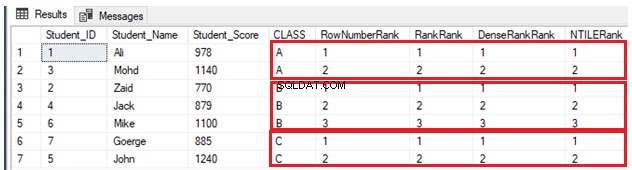
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOA causa del fatto che non ci sono valori duplicati, quattro funzioni della finestra di classificazione funzioneranno allo stesso modo, restituendo lo stesso risultato, come mostrato nel set di risultati di seguito:
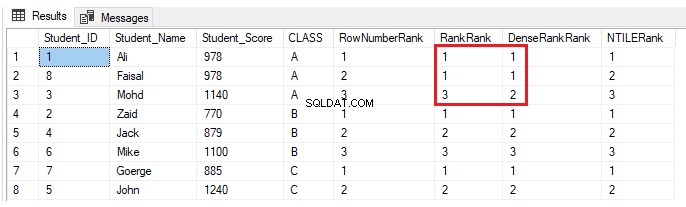
Se un altro studente è inserito nella classe A con un punteggio, che ha già un altro studente della stessa classe, utilizzando la seguente dichiarazione INSERT:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Non cambierà nulla per le funzioni della finestra di classificazione ROW_NUMBER() e NTILE(). Le funzioni RANK e DENSE_RANK() assegneranno lo stesso rango agli studenti con lo stesso punteggio, con uno spazio vuoto nei ranghi dopo i ranghi duplicati quando si utilizza la funzione RANK e nessun gap nei ranghi dopo i ranghi duplicati quando si utilizza DENSE_RANK( ), come mostrato nel risultato di seguito:
Scenario pratico
Le funzioni della finestra di classificazione sono ampiamente utilizzate dagli sviluppatori di SQL Server. Uno degli scenari comuni per l'utilizzo delle funzioni di classificazione, quando si desidera recuperare righe specifiche e saltarne altre, utilizzando la funzione della finestra di classificazione ROW_NUMBER() all'interno di un CTE, come nello script T-SQL riportato di seguito che restituisce gli studenti con posizioni comprese tra 2 e 5 e salta gli altri:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Il risultato mostrerà che verranno restituiti solo gli studenti con rango compreso tra 2 e 5:
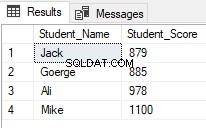
A partire da SQL Server 2012, un nuovo utile comando, OFFSET FETCH è stato introdotto che può essere utilizzato per eseguire la stessa attività precedente recuperando record specifici e saltando gli altri, utilizzando lo script T-SQL di seguito:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Recupero dello stesso risultato precedente come mostrato di seguito:
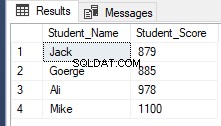
Conclusione
SQL Server ci fornisce quattro funzioni della finestra di classificazione che ci aiutano a classificare le righe fornite impostate in base a valori di colonna specifici. Queste funzioni sono:ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE(). Tutte queste funzioni di classificazione eseguono l'attività di classificazione a modo suo, restituendo lo stesso risultato quando non ci sono valori duplicati nelle righe. Se è presente un valore duplicato all'interno del set di righe, la funzione RANK assegnerà lo stesso ID classifica a tutte le righe con lo stesso valore, lasciando spazi tra i ranghi dopo i duplicati. La funzione DENSE_RANK assegnerà anche lo stesso ID classifica per tutte le righe con lo stesso valore, ma non lascerà alcuno spazio tra le classifiche dopo i duplicati. In questo articolo esamineremo diversi scenari per coprire tutti i possibili casi che ti aiutano a comprendere praticamente le funzioni della finestra di classifica.
Riferimenti:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- Clausola OFFSET FETCH (SQL Server Compact)