Gran parte del codice T-SQL di produzione viene scritto con il presupposto implicito che i dati sottostanti non cambieranno durante l'esecuzione. Come abbiamo visto nell'articolo precedente di questa serie, questo è un presupposto non sicuro perché i dati e le voci dell'indice possono spostarsi sotto di noi, anche durante l'esecuzione di una singola istruzione.
Laddove il programmatore T-SQL è a conoscenza dei tipi di problemi di correttezza e integrità dei dati che possono sorgere a causa di modifiche simultanee dei dati da parte di altri processi, la soluzione più comunemente offerta è quella di racchiudere le istruzioni vulnerabili in una transazione. Non è chiaro come lo stesso tipo di ragionamento verrebbe applicato al caso di dichiarazione singola, che per impostazione predefinita è già racchiuso in una transazione con commit automatico.
A parte questo per un secondo, l'idea di proteggere un'area importante del codice T-SQL con una transazione sembra essere basata su un malinteso delle protezioni offerte dalle proprietà della transazione ACID. L'elemento importante di quell'acronimo per la presente discussione è Isolamento proprietà. L'idea è che l'utilizzo di una transazione fornisce automaticamente il completo isolamento dagli effetti di altre attività simultanee.
La verità è che le transazioni inferiori a SERIALIZABLE fornire solo un laurea di isolamento, che dipende dal livello di isolamento delle transazioni attualmente effettivo. Per capire cosa significa tutto questo per il nostro T di tutti i giorni Pratiche di codifica SQL, daremo prima uno sguardo dettagliato al livello di isolamento serializzabile.
Isolamento serializzabile
Serializzabile è il più isolato dei livelli di isolamento delle transazioni standard. È anche l'impostazione predefinita livello di isolamento specificato dallo standard SQL, sebbene SQL Server (come la maggior parte dei sistemi di database commerciali) differisca dallo standard in questo senso. Il livello di isolamento predefinito in SQL Server è read commit, un livello di isolamento inferiore che esploreremo più avanti nella serie.
La definizione del livello di isolamento serializzabile nello standard SQL-92 contiene il seguente testo (enfasi mia):
Un'esecuzione serializzabile è definita come un'esecuzione delle operazioni di esecuzione simultanea di transazioni SQL che produce lo stesso effetto di alcune esecuzioni seriali di quelle stesse transazioni SQL. Un'esecuzione seriale è quella in cui ogni transazione SQL viene eseguita fino al completamento prima dell'inizio della transazione SQL successiva.
C'è un'importante distinzione da fare qui tra veramente serializzato esecuzione (in cui ogni transazione viene effettivamente eseguita esclusivamente fino al completamento prima dell'inizio di quella successiva) e serializzabile isolamento, dove le transazioni devono solo avere gli stessi effetti come se sono stati eseguiti in serie (in un ordine non specificato).
In altre parole, un vero sistema di database può sovrapporre fisicamente l'esecuzione di transazioni serializzabili nel tempo (aumentando così la concorrenza) purché gli effetti di tali transazioni corrispondano ancora a un possibile ordine di esecuzione seriale. In altre parole, le transazioni serializzabili sono potenzialmente serializzabili anziché essere effettivamente serializzato .
Transazioni serializzabili logicamente
Lascia per un momento da parte tutte le considerazioni fisiche (come il blocco) e pensa solo all'elaborazione logica di due transazioni serializzabili simultanee.
Si consideri una tabella che contiene un numero elevato di righe, cinque delle quali soddisfano alcuni predicati di query interessanti. Una transazione serializzabile T1 inizia a contare il numero di righe nella tabella che corrispondono a questo predicato. Qualche tempo dopo T1 inizia, ma prima del commit, una seconda transazione serializzabile T2 inizia. Transazione T2 aggiunge quattro nuove righe che soddisfano anche il predicato della query alla tabella e esegue il commit. Il diagramma seguente mostra la sequenza temporale degli eventi:

La domanda è:quante righe deve contenere la query nella transazione serializzabile T1 contare? Ricorda che qui pensiamo esclusivamente ai requisiti logici, quindi evita di pensare a quali blocchi potrebbero essere presi e così via.
Le due transazioni si sovrappongono fisicamente nel tempo, il che va bene. L'isolamento serializzabile richiede solo che i risultati di queste due transazioni corrispondano a una possibile esecuzione seriale. Ci sono chiaramente due possibilità per una pianificazione seriale logica delle transazioni T1 e T2 :
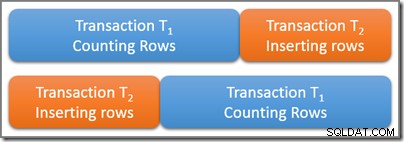
Utilizzando la prima programmazione seriale possibile (T1 quindi T2 ) il T1 la query di conteggio vedrebbe cinque righe , perché la seconda transazione non inizia fino al completamento della prima. Utilizzando il secondo programma logico possibile, il T1 la query conterebbe nove righe , perché l'inserimento a quattro righe è stato completato logicamente prima dell'inizio della transazione di conteggio.
Entrambe le risposte sono logicamente corrette sotto isolamento serializzabile. Inoltre, non è possibile alcuna altra risposta (quindi transazione T1 non poteva contare sette righe, per esempio). Quale dei due possibili risultati viene effettivamente osservato dipende da tempi precisi e da una serie di dettagli di implementazione specifici del motore di database in uso.
Si noti che non stiamo concludendo che le transazioni siano effettivamente in qualche modo riordinate nel tempo. L'esecuzione fisica è libera di sovrapporsi come mostrato nel primo diagramma, a condizione che il motore di database garantisca che i risultati riflettano cosa sarebbe successo se fossero stati eseguiti in una delle due possibili sequenze seriali.
Serializzabile e fenomeni di concorrenza
Oltre alla serializzazione logica, lo standard SQL menziona anche che una transazione che opera a livello di isolamento serializzabile non deve presentare determinati fenomeni di concorrenza. Non deve leggere dati non vincolati (nessuna letture sporche ); e una volta letti i dati, una ripetizione della stessa operazione deve restituire esattamente lo stesso insieme di dati (letture ripetibili senza fantasmi ).
Lo standard sottolinea che tali fenomeni di concorrenza sono esclusi a livello di isolamento serializzabile come conseguenza diretta di richiedere che la transazione sia serializzabile logicamente. In altre parole, il requisito di serializzabilità è sufficiente da solo per evitare i fenomeni di lettura sporca, lettura non ripetibile e concorrenza fantasma. Al contrario, evitare i tre fenomeni di concorrenza da soli non è sufficiente per garantire la serializzabilità, come vedremo a breve.
Intuitivamente, le transazioni serializzabili evitano tutti i fenomeni legati alla concorrenza perché devono agire come se fossero state eseguite in completo isolamento. In questo senso, il livello di isolamento della transazione serializzabile corrisponde abbastanza strettamente alle aspettative comuni dei programmatori T-SQL.
Implementazioni serializzabili
SQL Server utilizza un'implementazione di blocco del livello di isolamento serializzabile, in cui i blocchi fisici vengono acquisiti e mantenuti alla fine della transazione (da cui il deprecato suggerimento tabella HOLDLOCK come sinonimo di SERIALIZABLE ).
Questa strategia non è sufficiente a fornire una garanzia tecnica di piena serializzabilità, perché i dati nuovi o modificati potrebbero apparire in un intervallo di righe precedentemente elaborate dalla transazione. Questo fenomeno di concorrenza è noto come phantom e può causare effetti che non si sarebbero verificati in nessun programma seriale.
Per garantire la protezione contro il fenomeno della concorrenza fantasma, i blocchi presi da SQL Server a livello di isolamento serializzabile possono anche incorporare blocco dell'intervallo di chiavi per impedire la visualizzazione di righe nuove o modificate tra i valori della chiave dell'indice esaminati in precedenza. I blocchi dell'intervallo non sono sempre acquisito sotto il livello di isolamento serializzabile; tutto ciò che possiamo dire in generale è che SQL Server acquisisce sempre blocchi sufficienti per soddisfare i requisiti logici del livello di isolamento serializzabile. In effetti, le implementazioni di blocco molto spesso acquisiscono più blocchi, e più severi, di quelli realmente necessari per garantire la serializzabilità, ma sto divagando.
Il blocco è solo una delle possibili implementazioni fisiche del livello di isolamento serializzabile. Dovremmo fare attenzione a separare mentalmente i comportamenti specifici dell'implementazione del blocco di SQL Server dalla definizione logica di serializzabile.
Come esempio di una strategia fisica alternativa, vedere l'implementazione PostgreSQL dell'isolamento degli snapshot serializzabili, sebbene questa sia solo un'alternativa. Ogni diversa implementazione fisica ha ovviamente i suoi punti di forza e di debolezza. Per inciso, si noti che Oracle non fornisce ancora un'implementazione completamente conforme del livello di isolamento serializzabile. Ha un livello di isolamento denominato serializzabile, ma non garantisce veramente che le transazioni verranno eseguite secondo una possibile pianificazione seriale. Oracle fornisce invece isolamento snapshot quando è richiesto serializzabile, più o meno allo stesso modo di PostgreSQL prima dell'isolamento dello snapshot serializzabile (SSI ) è stato implementato.
L'isolamento dello snapshot non impedisce anomalie della concorrenza come l'inclinazione della scrittura, che non è possibile con un isolamento veramente serializzabile. Se sei interessato, puoi trovare esempi di write skew e altri effetti di concorrenza consentiti dall'isolamento dello snapshot al link SSI sopra. Discuteremo anche l'implementazione di SQL Server del livello di isolamento degli snapshot più avanti nella serie.
Una visione puntuale?
Uno dei motivi per cui ho passato del tempo a parlare delle differenze tra serializzabilità logica ed esecuzione serializzata fisicamente è che altrimenti è facile dedurre garanzie che potrebbero non esistere effettivamente. Ad esempio, se pensi alle transazioni serializzabili come effettivamente eseguendo una dopo l'altra, potresti dedurre che una transazione serializzabile vedrà necessariamente il database così com'era all'inizio della transazione, fornendo una vista point-in-time.
In realtà, questo è un dettaglio specifico dell'implementazione. Richiama l'esempio precedente, in cui la transazione serializzabile T1 potrebbe contare legittimamente cinque o nove righe. Se viene restituito un conteggio di nove, la prima transazione vede chiaramente le righe che non esistevano al momento dell'inizio della transazione. Questo risultato è possibile in SQL Server ma non in PostgreSQL SSI, sebbene entrambe le implementazioni siano conformi ai comportamenti logici specificati per il livello di isolamento serializzabile.
In SQL Server, le transazioni serializzabili non vedono necessariamente i dati come esistevano all'inizio della transazione. Piuttosto, i dettagli dell'implementazione di SQL Server indicano che una transazione serializzabile vede gli ultimi dati sottoposti a commit, dal momento in cui i dati sono stati bloccati per l'accesso per la prima volta. Inoltre, è garantito che l'insieme degli ultimi dati impegnati letti alla fine non cambi la sua appartenenza prima della fine della transazione.
La prossima volta
La parte successiva di questa serie esamina il livello di isolamento in lettura ripetibile, che fornisce garanzie di isolamento delle transazioni più deboli rispetto al serializzabile.
[Vedi l'indice per l'intera serie]


